Esta postagem foi lançada como parte do Data Science Blogathon.
Introdução

Neste post, intentaremos mitigar eso a través de el uso del Aprendizado por reforçoO aprendizado por reforço é uma técnica de inteligência artificial que permite que um agente aprenda a tomar decisões interagindo com um ambiente. Por meio de feedback na forma de recompensas ou punições, O agente otimiza seu comportamento para maximizar as recompensas acumuladas. Essa abordagem é usada em uma variedade de aplicações, De videogames a robótica e sistemas de recomendação, destacando-se por sua capacidade de aprender estratégias complexas.....
Técnicas que podemos usar para prever os preços das ações
Como é uma previsão de valores contínuos, qualquer tipo de técnica de regressão pode ser usada:
- A regressão linear ajudará você a prever valores contínuos
- Modelos de série temporal são modelos que podem ser usados para dados relacionados ao tempo.
- ARIMA é um daqueles modelos usados para prever previsões futurísticas associadas ao tempo..
- LSTM também é uma daquelas técnicas que tem sido usada para previsões de preços de ações.. LSTM se refere à memória de longo prazo e faz uso de redes neurais para prever valores contínuos. LSTMs são muito poderosos e são conhecidos por reter memória de longo prazo.
Apesar disto, há outra técnica que pode ser usada para previsões de preços de ações e que é o aprendizado de reforço.
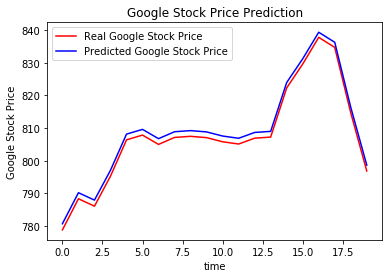
O que é aprendizagem por reforço?
El aprendizaje por refuerzo es otro tipo de aprendizaje automático al mismo tiempo del aprendizagem supervisionadaO aprendizado supervisionado é uma abordagem de aprendizado de máquina em que um modelo é treinado usando um conjunto de dados rotulados. Cada entrada no conjunto de dados está associada a uma saída conhecida, permitindo que o modelo aprenda a prever resultados para novas entradas. Este método é amplamente utilizado em aplicações como classificação de imagens, Reconhecimento de fala e previsão de tendências, destacando sua importância em... e não supervisionado. É um sistema de aprendizagem baseado em agente no qual o agente realiza ações em um ambiente em que o objetivo é maximizar o registro.. Aprendizagem por reforço não requer o uso de dados rotulados, como aprendizagem supervisionada.
O aprendizado por reforço funciona muito bem com menos dados históricos. Ele faz uso da função de valor e o calcula com base na política que é decidida para aquela ação.
A aprendizagem por reforço é modelada como um procedimento de decisão de Markov (MDP):
-
Um ambiente E e estados de agente S
-
Um conjunto de ações A tomadas pelo agente.
-
P (s, s ‘) => P (st + 1 = s’ | st = s, at = a) é a probabilidade de transição de um estado para s ‘
-
R (s, s ‘): recompensa imediata por qualquer ação
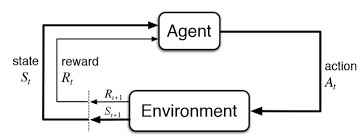
Como podemos prever os preços do mercado de ações usando o aprendizado de reforço?
O conceito de aprendizagem reforçada pode ser aplicado para prever o preço de uma ação específica., uma vez que usa os mesmos princípios fundamentais de exigir dados históricos menores, trabalhar em um sistema baseado em agente para prever retornos mais elevados com base no ambiente atual. Veremos um exemplo de previsão do preço de uma ação para uma determinada ação seguindo o modelo de aprendizagem por reforço. Faz uso do conceito de aprendizagem Q explicado em mais detalhes.
As etapas para projetar um modelo de aprendizagem por reforço são:
- Importação de bibliotecas
- Crie o agente que tomará todas as decisões.
- Defina funções básicas para formatar valores, função sigmóide, ler arquivo de dados, etc.
- Treine o agente
- Examine o desempenho do agente
Estabeleça o Ambiente de Aprendizagem Reforçada
MDP para previsão do preço das ações:
- Agente: um agente A trabalhando no ambiente E
- Açao – Comprar / Mercado / Manter
- Estado: valores de dados
- Recompensas: Lucros / perdas
Papel de Q – Aprendendo
Q-learning é um algoritmo de aprendizado por reforço sem modelo para saber a qualidade das ações e dizer a um agente que ação tomar em quais circunstâncias. O Q-learning encontra uma política ótima no sentido de maximizar o valor esperado da recompensa total em qualquer etapa sucessiva, começando do estado atual.
Coleção de dados
-
Ir a Yahoo Finance
-
Insira o nome da empresa, como um exemplo. Banco HDFC
-
Selecione o período de tempo para, como um exemplo, 5 anos
-
Clique em Download para baixar o arquivo CSV
Vamos implementar nosso modelo em Python
Importação de bibliotecas
Para construir o modelo de aprendizagem por reforço, importe las bibliotecas de Python indispensables para modelar las capas de la neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. y la biblioteca NumPy para algunas operaciones básicas.
import keras
from keras.models import Sequential
from keras.models import load_model
from keras.layers import Dense
from keras.optimizers import Adam
import math
import numpy as np
import random
from collections import deque
Criando o Agente
El código del agente comienza con algunas inicializaciones básicas para los distintos parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto..... Algumas variáveis estáticas são definidas como gama, Épsilon, epsilon_min e epsilon_decay. São valores de limiar constantes que são usados para conduzir todo o procedimento de compra e venda de ações e manter os parâmetros calmos.. Esses valores mínimos e de queda servem como valores limiares na distribuição normal.
Agente projeta modelo de rede neural em camadas para realizar ações de compra, venda ou retenção. Esse tipo de ação é realizada observando sua previsão anterior e também o estado do ambiente atual. O método de ato é usado para prever a próxima ação a ser tomada. Se a memória estiver preenchida, há outro método chamado expreplay projetado para redefinir a memória.
Agente de Classe:
def __init__(auto, state_size, is_eval=Falso, model_name =""):
self.state_size = state_size # normalized previous days
self.action_size = 3 # Sentar, comprar, sell
self.memory = deque(maxlen=1000)
auto.inventário = []
self.model_name = model_name
self.is_eval = is_eval
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
auto.modelo = load_model(model_name) se is_eval mais self._model()
def _model(auto):
modelo = Sequencial()
model.add(Denso(unidades=64, input_dim=self.state_size, ativação ="retomar"))
model.add(Denso(unidades=32, ativação ="retomar"))
model.add(Denso(unidades=8, ativação ="retomar"))
model.add(Denso(self.action_size, ativação ="linear"))
model.compile(perda ="mse", otimizador = Adam(lr=0,001))
return model
def act(auto, Estado):
se não self.is_eval e aleatório.aleatório()<= self.epsilon:
retorno aleatório.randrange(self.action_size)
opções = self.model.predict(Estado)
retorno np.argmax(Opções[0])
def expReplay(auto, tamanho do batch):
mini_batch = []
l = len(auto.memória)
para eu no alcance(eu - tamanho do batch + 1, eu):
mini_batch.append(auto.memória[eu])
para o estado, açao, recompensa, next_state, feito em mini_batch:
target = reward
if not done:
alvo = recompensa + auto.gamma * np.amax(auto.model.predict(next_state)[0])
target_f = auto.model.predict(Estado)
target_f[0][açao] = target
self.model.fit(Estado, target_f, épocas=1, verbose = 0)
se self.epsilon > self.epsilon_min:
auto.epsilon *= self.epsilon_decay
Establecer funciones básicas
El formatprice () é escrito para estruturar o formato da moeda. GetStockDataVec () trará os dados de estoque para Python. Defina a função sigmoide como um cálculo matemático. GetState () é codificado de tal forma que fornece o estado atual dos dados.
formato defPrice(n):
Retorna("-Rs." se n<0 outro "Rs.")+"{0:.2f}".formato(abdômen(n))
def getStockDataVec(chave):
vec = []
linhas = abertas(chave+".csv","r").leitura().linhas de divisão()
para linha em linhas[1:]:
#imprimir(linha)
#imprimir(flutuador(linha.split(",")[4]))
vec.append(flutuador(linha.split(",")[4]))
#imprimir(vec)
return vec
def sigmoid(x):
Retorna 1/(1+math.exp(-x))
def getState(dados, t, n):
d = t - n + 1
bloco = dados[d:t + 1] se d >= 0 outra coisa -d * [dados[0]] + dados[0:t + 1] # pad with t0
res = []
para eu no alcance(n - 1):
res.append(sigmóide(bloquear[eu + 1] - bloquear[eu]))
retorno np.array([res])
Treinando o Agente
Dependendo da ação prevista pelo modelo, a chamada de compra / venda adiciona ou subtrai dinheiro. Se entrena por medio de múltiples episodios que son los mismos que épocas en el aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde.... A seguir, o modelo é salvo mais tarde.
import sys stock_name = input("Digite stock_name, window_size, Episode_count") window_size = entrada() episode_count = entrada() stock_name = str(stock_name) window_size = int(window_size) episode_count = int(episode_count) agente = Agente(window_size) dados = getStockDataVec(stock_name) l = len(dados) - 1 batch_size = 32 para e no intervalo(episode_count + 1): imprimir("Episódio " + str(e) + "/" + str(episode_count)) estado = getState(dados, 0, window_size + 1) total_profit = 0 agente.inventário = [] para t no intervalo(eu): ação = agente.act(Estado) # sit next_state = getState(dados, t + 1, window_size + 1) recompensa = 0 se a ação == 1: # buy agent.inventory.append(dados[t]) imprimir("Comprar: " + formatPrice(dados[t])) elif ação == 2 e len(agente.inventário) > 0: # sell bought_price = window_size_price = agent.inventory.pop(0) recompensa = max(dados[t] - bought_price, 0) total_profit += dados[t] - bought_price print("Vender: " + formatPrice(dados[t]) + " | Lucro: " + formatPrice(dados[t] - bought_price)) feito = Verdadeiro se t == l - 1 else False agent.memory.append((Estado, açao, recompensa, next_state, terminado)) state = next_state if done: imprimir("--------------------------------") imprimir("Lucro Total: " + formatPrice(total_profit)) imprimir("--------------------------------") se len(agente.memória) > tamanho do batch: agent.expReplay(tamanho do batch) se e % 10 == 0: agent.model.save(str(e))
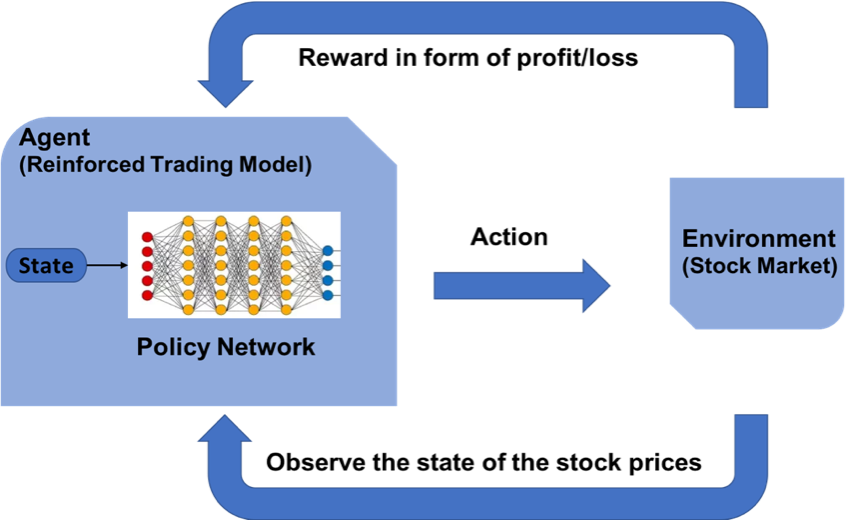
Salida de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... al final del primer episodio:
Lucro Total: Rs.340.03
Avaliação de modelo
Uma vez que o modelo tenha sido treinado com base nos novos dados, você será capaz de testar o modelo para definir os lucros / perdas oferecidas. Em consequência, pode examinar a credibilidade do modelo.
stock_name = entrada("Digite Stock_name, Model_name")
model_name = entrada()
modelo = load_model(model_name)
window_size = modelo.camadas[0].input.shape.as_list()[1]
agente = Agente(window_size, Verdade, model_name)
dados = getStockDataVec(stock_name)
imprimir(dados)
l = len(dados) - 1
batch_size = 32
estado = getState(dados, 0, window_size + 1)
imprimir(Estado)
total_profit = 0
agente.inventário = []
imprimir(eu)
para t no intervalo(eu):
ação = agente.act(Estado)
imprimir(açao)
# sit
next_state = getState(dados, t + 1, window_size + 1)
recompensa = 0
se a ação == 1: # buy
agent.inventory.append(dados[t])
imprimir("Comprar: " + formatPrice(dados[t]))
elif ação == 2 e len(agente.inventário) > 0: # sell
bought_price = agent.inventory.pop(0)
recompensa = max(dados[t] - bought_price, 0)
total_profit += dados[t] - bought_price
print("Vender: " + formatPrice(dados[t]) + " | Lucro: " + formatPrice(dados[t] - bought_price))
feito = Verdadeiro se t == l - 1 else False
agent.memory.append((Estado, açao, recompensa, next_state, terminado))
state = next_state
if done:
imprimir("--------------------------------")
imprimir(stock_name + " Lucro Total: " + formatPrice(total_profit))
imprimir("--------------------------------")
imprimir ("O lucro total é:",formatPrice(total_profit))
Notas finais
Aprendizagem por reforço dá resultados positivos para previsões de valor. Através do uso de Q learning, diferentes experimentos podem ser realizados. Mais pesquisas sobre aprendizagem por reforço permitirão que a aprendizagem por reforço seja aplicada em um estágio mais seguro.
Você pode se comunicar com





