Este artigo foi publicado como parte do Data Science Blogathon
As máquinas que entendem a linguagem me fascinam, e muitas vezes pondero quais algoritmos Aristóteles teria se acostumado a construir uma máquina de análise retórica se tivesse tido a chance. Se você é novo na ciência de dados, entrar na PNL pode parecer complicado, especialmente porque existem muitos avanços recentes no campo. é difícil entender por onde começar.
Tabela de conteúdo
1. O que as máquinas podem entender?
2.Projeto 1: Palavra nuvem
3.Projeto 2: Detecção de spam
4.Projeto 3: Análise de sentimentos
5. conclusão
O que as máquinas podem entender?
Embora um computador possa ser muito bom em encontrar padrões e resumir documentos, deve transformar palavras em números antes de entendê-las. Essa transformação é muito necessária porque a matemática não funciona muito bem com palavras e máquinas. “eles aprendem” graças a matemática. Antes da transformação de palavras em números, limpeza de dados é necessária. A limpeza de dados inclui a remoção de pontuação e caracteres especiais e sua modificação para torná-los mais consistentes e interpretáveis.
Projeto 1: Palavra nuvem
1.Dependências e importação de dados
Comece importando as dependências e dados. Os dados são armazenados como um arquivo de valores separados por vírgulas (CSV), então eu vou usar pandas ‘ read_csv () função para abri-lo em um DataFrame.
import pandas as pd
import sqlite3
import regex as re
import matplotlib.pyplot as plt
from wordcloud import WordCloud
#create dataframe from csv
df = pd.read_csv('e-mails.csv')
df.head()
df.head()


2.Análise exploratória
Para excluir linhas duplicadas e definir algumas contagens de linha de base, é melhor fazer uma análise rápida dos dados. Aqui usamos pandas drop_duplicates para remover linhas duplicadas.
imprimir("contagem de spam: " +str(len(df.loc[df.spam==1])))
imprimir("não contagem de spam: " +str(len(df.loc[df.spam==0])))
imprimir(df.shape)
df['spam'] = df['spam'].astype(int)
df = df.drop_duplicates()
df = df.reset_index(inplace = Falso)[['texto','spam']]
imprimir(df.shape)
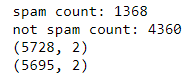
Contagens e forma antes / após a desduplicação
O que é uma nuvem de palavras?
As nuvens de palavras facilitam a compreensão da frequência das palavras, por isso é uma maneira útil de visualizar dados de texto. As palavras que aparecem maiores na nuvem são as que aparecem com mais frequência no texto do e-mail. As nuvens de palavras facilitam a identificação “palavras chave”.
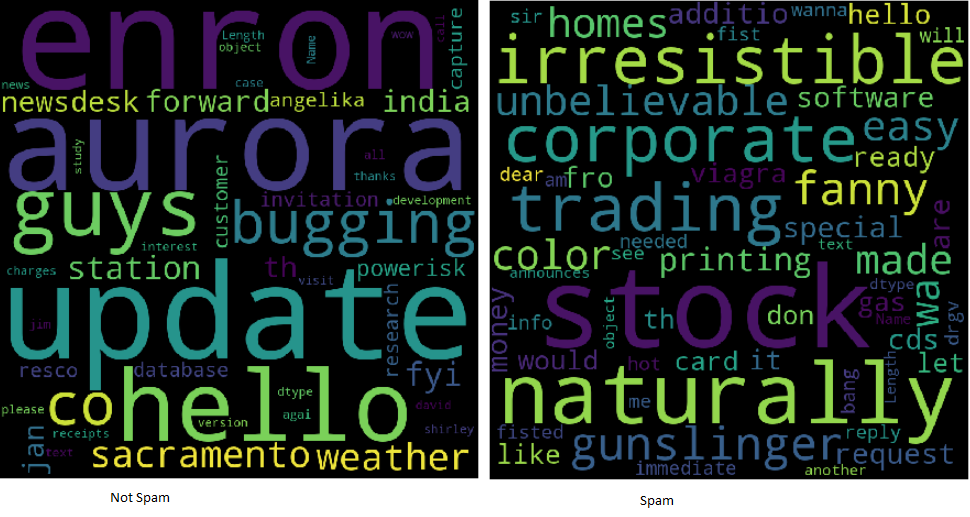
Exemplos de nuvem de palavras
Todo o texto é minúsculo na imagem da palavra nuvem. Não contém marcas de pontuação ou caracteres especiais. O texto agora é chamado de limpo e pronto para análise. Com a ajuda de expressões regulares, é fácil limpar o texto usando um loop:
clean_desc = [] para w no intervalo(len(df.text)): desc = df['texto'][C].diminuir() #remove punctuation desc = re.sub('[^ a-zA-Z]', '', desc) #remove tags desc=re.sub("</?.*?>"," <> ",desc) #remove digits and special chars desc=re.sub("(d|C)+"," ",desc) clean_desc.append(desc) #assign the cleaned descriptions to the data frame df['texto'] = clean_desc df.head(3)

Observe aqui que criamos uma lista vazia clean_desc, então usamos um em laço para verificar o texto linha por linha, configurando para minúsculas, remover pontuação e caracteres especiais e adicioná-los à lista. Em seguida, substituímos a coluna de texto pelos dados da lista clean_desc.
Por palavras
Palavras irrelevantes são as palavras mais comuns, como “a” e “a partir de”. Removê-los do texto do e-mail permite que as palavras frequentes mais relevantes sejam quadradas. Eliminar palavras irrelevantes pode ser uma técnica comum!! Algumas bibliotecas Python, como NLTK, vêm pré-carregadas com uma lista de palavras de interrupção, mas é fácil formar um do zero.
stop_words = ['é','tu','sua','e', 'a', 'para', 'a partir de', 'ou', 'EU', 'para', 'Faz', 'pegue', 'não', 'aqui', 'no', 'Eu estou', 'tenho', 'sobre', 'ré', 'novo', 'sujeito']
Observe que incluo algumas palavras relacionadas ao e-mail, O que “ré” e “caso”. Cabe ao analista ver quais palavras devem ser incluídas ou excluídas. Às vezes, é benéfico incorporar todas as palavras!
Construir a palavra poderia
Convenientemente, há uma biblioteca Python para criar nuvens de palavras. Ele será instalado usando pip.
pip instalar wordcloud
Ao construir a nuvem de palavras, es posible alinear varios parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... como alto y ancho, palavras vazias e palavras máximas. é até possível moldá-lo em vez de exibir o retângulo padrão.
wordcloud = WordCloud(largura = 800, altura = 800, background_color ="Preto", stopwords = stop_words, max_words = 1000
, min_font_size = 20).gerar(str(df1['texto']))
#plot the word cloud
fig = plt.figure(figsize = (8,8), facecolor = Nenhum)
plt.imshow(palavra nuvem)
plt.axis('desligado')
plt.show()
Para salvar e exibir a nuvem de palavras. Matplotlib e show são usados (). Independentemente de ser spam, é o resultado de todos os registros.

Empurre o exercício ainda mais longe, dividindo o quadro de informações e criando nuvens de duas palavras para ajudar a analisar a diferença entre as palavras-chave usadas no spam e não no spam..
Projeto 2: Detecção de spam
Pense nisso como um problema de classificação binária, já que um e-mail pode ser spam indicado por “1” o no spam indicado por “0”. Gostaria de criar um modelo de aprendizado de máquina que possa identificar se um e-mail pode ser spam ou não. Estou visitando a biblioteca Python Scikit-Learn para explorar os algoritmos de tokenização, vetorização e classificação estatística.

Importar dependências
Importe a funcionalidade do Scikit-Learn que gostaríamos de modificar e modele as informações. Vou usar CountVectorizer, train_test_split, modelos de conjunto e algumas métricas.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn import ensemble
from sklearn.metrics import classification_report, precisão_pontuação
Transforme texto em números
No projeto 1, texto limpo. uma vez que você dar uma olhada em uma nuvem de palavras, note que estas são principalmente palavras únicas. Quanto maior a palavra, maior sua frequência. Para evitar que a nuvem de palavras gere sentenças, o texto passa por um processo chamado tokenização. é o método de dividir uma frase em palavras individuais. Palavras individuais são chamadas de tokens.
Com CountVectorizer () de SciKit-Learn, fácil de retrabalhar o texto do corpo em uma matriz esparsa de números que pode ser passada para algoritmos de aprendizado de máquina por computador. Para simplificar o conceito de contagem de vetorização, imagine que você tem duas frases:
O cachorro é branco
O gato é preto
Converter as frases em um modelo de espaço vetorial as transformaria de tal forma que ela olhasse para as palavras em todas as frases e, em seguida, representasse as palavras na frase com um número..
O cão gato é branco preto
O cachorro é branco = [1,1,0,1,1,0] O gato é preto = [1,0,1,1,0,1] Podemos mostrar isso usando código também. Vou adicionar uma terceira frase para mostrar que conta os tokens. #list of sentences text = ["o cão é branco", "o gato é preto", "o gato eo cão são amigos"] #instantiate the class cv = CountVectorizer() #tokenize and build vocab cv.fit(texto) imprimir(cv.vocabulary_) #transform the text vector = cv.transform(texto) imprimir(vetor.toarray())
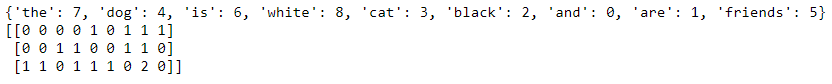
A matriz esparsa da palavra conta.
Observe que dentro do último vetor, você será capaz de ver um 2 desde a palavra “a” aparece duas vezes. CountVectorizer conta os tokens e me permite construir a matriz esparsa que contém as palavras transformadas em números.
Método do saco de palavras
Porque o modelo não leva em conta a localização das palavras e, em seu lugar, ele os mistura como fichas em um jogo de scrabble, isso geralmente é chamado de método do saco de palavras. Estou visitando para criar a matriz esparsa, em seguida, divida as informações usando SK-learn train_test_split ().
text_vec = CountVectorizer().fit_transform(df['texto']) X_train, X_test, y_train, y_test = train_test_split(text_vec, df['spam'], test_size = 0.45, random_state = 42, shuffle = True)
Observe que defini a matriz esparsa text_vec para X e o df['Spam'] coluna para Y. Eu embaralho e faço um teste de tamanho do 45%.
O classificador
é altamente recomendado experimentar com vários classificadores e determinar qual funciona melhor para este cenário. durante este exemplo, Estou usando o modelo GradientBoostingClassifier () da coleção Scikit-Learn Ensemble.
classificador = conjunto. GradientBoostingClassifier( n_estimators = 100, #how many decision trees to build learning_rate = 0.5, #learning rate max_depth = 6 )
Cada algoritmo terá seu próprio conjunto de parâmetros que você pode modificar. que é chamado de ajuste hiperparâmetro. submeter à documentação para saber mais sobre cada um dos parâmetros usados nos modelos.
Gerar previsões
Finalmente, nós ajustamos as informações, chamamos de prever e gerar o relatório de classificação. Ao usar classificação_report (), fácil de criar um relatório de texto mostrando a maioria das métricas de classificação.
classifier.fit(X_train, y_train) predictions = classifier.predict(X_test) imprimir(classificação_report(y_test, previsões))
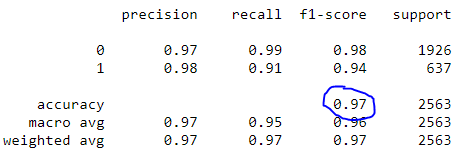
Relatório de classificação
Observe que nosso modelo alcançou uma precisão de 97%.
Projeto 3: Análise de sentimentos
A análise de sentimento é, O que mais, tipo de problema de classificação. O texto é basicamente uma visita para refletir um sentimento positivo, neutral o negativo. isso é perceptível devido à polaridade do texto. Também é possível determinar e dar conta da subjetividade do texto! Existem muitos recursos excelentes cobrindo a especulação por trás da análise de sentimento..
Em vez de construir outro modelo, este projeto usa uma ferramenta simples e pronta para uso para investigar o sentimento chamado TextBlob. Usarei o TextBlob para apresentar colunas de opinião no DataFrame para que sejam analisadas com frequência.

O que é TextBlob?
Construído sobre NLTK e padrão, a biblioteca TextBlob para Python 2 e três tentativas de simplificar várias tarefas de processamento de texto. Fornece ferramentas para classificação, rotulagem de parte do discurso, extração de sentença, análise sentimento e mais. Instale-o usando pip.
pip install -U textblob
python -m textblob.download_corpora
Sentimento textblob
Usando a propriedade sentimento, textblob retorna uma tupla nomeada da forma de sentimento (polaridade, subjetividade). Polaridade pode flutuar dentro do alcance [-1.0, 1.0] Onde -1 é o mais negativo e 1 é o mais positivo. A subjetividade pode flutuar dentro do alcance [0.0, 1.0] Onde 0.0 é extremamente objetivo e 1.0 é extremamente subjetivo.
blob = TextBlob("Este é um bom exemplo de um TextBlob")
imprimir(bolha)blob.sentiment
#Sentiment(polaridade=0,7, subjetividade=0,600000000000000000001)
Aplicar textblob
Ao usar listas de compreensão, é fácil carregar a coluna de texto como TextBlob, então crie duas novas colunas para armazenar polaridade e subjetividade.
#load the descriptions into textblob email_blob = [TextBlob(texto) para texto no DF['texto']] #add the sentiment metrics to the dataframe df['tb_Pol'] = [b.sentiment.polaridade para b em email_blob] df['tb_Subj'] = [b.sentiment.subjetividade para b em email_blob] #show dataframe df.head(3)

TextBlob torna muito simples chegar a uma pontuação de sentimento de referência para polaridade e subjetividade. Para impulsionar ainda mais esse usuário, veja se você pode adicionar esses novos recursos ao modelo de detecção de spam para aumentar a precisão.
conclusão:
Embora o processamento da comunicação linguística possa parecer um tópico intimidante, as peças fundamentais não parecem ser tão difíceis de entender. Muitas bibliotecas tornam mais fácil começar a explorar a ciência de dados e PNL. Concluindo esses três projetos:
Palavra nuvem
Detecção de spam
Análise de sentimentos
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





