Visão geral:
- Aprenda o que é Big Data e como ele é relevante no mundo de hoje
- Conheça as características do Big Data
Introdução
O fim “Big Data” é um nome impróprio, pois implica que os dados pré-existentes são de alguma forma pequenos (não são) ou que o único desafio é seu grande tamanho (o tamanho é um deles, mas geralmente há mais ).
Em resumo, o termo Big Data se aplica a informações que não podem ser processadas ou analisadas usando processos ou ferramentas tradicionais.

Cada vez mais, as organizações de hoje enfrentam cada vez mais desafios de Big Data. Eles têm acesso a uma grande quantidade de informações, mas eles não sabem como extrair valor disso porque está em sua forma mais tosca ou em um formato semiestruturado ou não estruturado; e como resultado, eles nem sabem se vale a pena manter (ou mesmo se eles podem mantê-lo).
Neste artigo, analisamos o conceito de big data e do que se trata.
Tabela de conteúdo
- O que é Big Data?
- Características do Big Data
- Volume de dados
- A variedade de dados
- Velocidade de dados
O que é Big Data?
Nós fazemos parte disso, todos os dias!
Uma pesquisa da IBM descobriu que mais da metade dos líderes de negócios de hoje percebem que não têm acesso às informações de que precisam para fazer seu trabalho. As empresas enfrentam esses desafios em um clima em que têm a capacidade de armazenar qualquer coisa e geram dados como nunca antes na história.; combinado, isso apresenta um verdadeiro desafio de informação.

É um enigma: as empresas de hoje têm mais acesso a informações potenciais do que nunca, porém, à medida que esta potencial mina de ouro de dados se acumula, a porcentagem de dados que a empresa pode processar é rapidamente reduzida. Em poucas palavras, a era do Big Data está em pleno vigor hoje porque o mundo está mudando.
Por meio de instrumentação, podemos sentir mais coisas e, se podemos sentir isso, tendemos a tentar armazená-lo (ou pelo menos parte dele). Por meio de avanços na tecnologia de comunicação, pessoas e coisas estão cada vez mais interconectadas, e não só às vezes, mas o tempo todo. Esta taxa de interconectividade é um trem desgovernado. Geralmente conhecido como máquina para máquina (M2M), a interconectividade é responsável por taxas de crescimento de dados de dois dígitos ano após ano (YoY).
Finalmente, porque pequenos ICs agora são muito baratos, podemos adicionar inteligência a quase tudo. Mesmo algo tão mundano como um vagão de trem tem centenas de sensores. Em um vagão de trem, esses sensores rastreiam coisas como as condições vividas pelo vagão, o status de peças individuais e dados baseados em GPS para rastreamento e logística de transporte. Após descarrilamentos de trens que causaram grande perda de vidas, Os governos introduziram regulamentos para este tipo de dados a serem armazenados e analisados para prevenir futuros desastres.
Os vagões também estão ficando mais inteligentes: processadores foram adicionados para interpretar dados de sensores em peças sujeitas a desgaste, como rolamentos, para identificar as peças que precisam de reparo antes que falhem e causem mais danos, ou ainda pior, um desastre. Mas não são apenas os vagões que são inteligentes, trilhos reais têm sensores a cada poucos metros. O que mais, os requisitos de armazenamento de dados são para todo o ecossistema: automóveis, trilhos, sensores de travessia de ferrovia, padrões climáticos causando movimentos ferroviários, etc.
Agora adicione isso para rastrear a carga de um vagão de trem, horas de chegada e partida, e você pode ver rapidamente que tem um problema de Big Data em suas mãos. Mesmo que cada bit desses dados fosse relacional (e não é), eles serão todos brutos e terão formatos muito diferentes, o que torna o processamento deles em um sistema relacional tradicional impraticável ou impossível. Os vagões são apenas um exemplo, mas para onde quer que olhemos, nós vemos domínios com velocidade, volume e variedade que se combinam para criar o problema de big data.
Quais são as características do Big Data?
Três características definem Big Data: volume, variedade e velocidade.
Juntas, essas características definem “Big Data”. Eles criaram a necessidade de uma nova classe de recursos para aumentar a maneira como as coisas são feitas hoje para fornecer uma melhor linha de visão e controle sobre nossos domínios de conhecimento existentes e a capacidade de agir sobre eles..
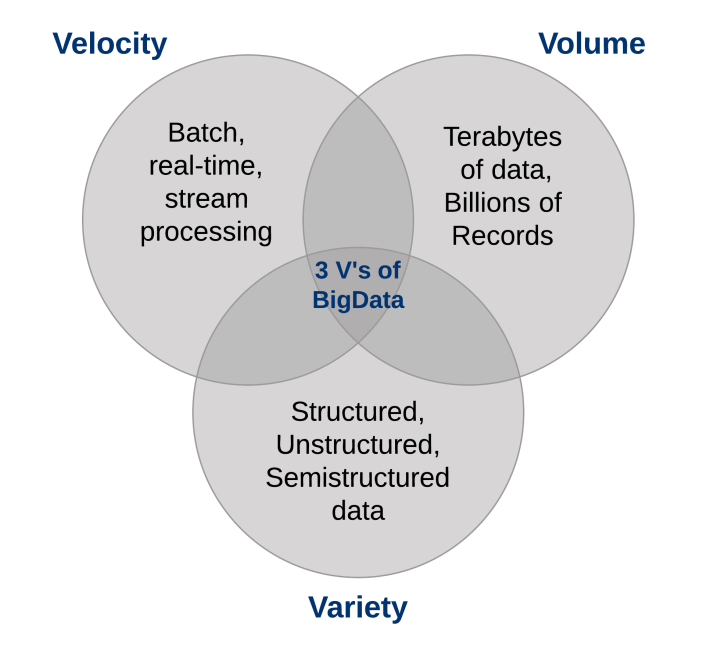
1. Volume de dados
O grande volume de dados armazenados hoje está disparando. No ano 2000, eles foram armazenados 800.000 petabytes (PB) de dados no mundo. Claro, muitos dos dados que são criados hoje não são analisados de todo e essa é outra questão que precisa ser levada em consideração. Espera-se que esse número alcance 35 zetabytes (Por exemplo.) para 2020. Twitter só gera mais do que 7 terabytes (tb) de dados todos os dias, Facebook 10 TB e algumas empresas geram terabytes de dados a cada hora de todos os dias do ano. Não é mais incomum que empresas individuais tenham clusters de armazenamento contendo petabytes de dados.

Quando você para e pensa sobre isso, é meio estranho que estejamos nos afogando em dados. Nós armazenamos tudo: dados ambientais, dados financeiros, dados médicos, dados de vigilância e a lista continua indefinidamente. Por exemplo, tirar o smartphone da capa gera um evento; quando a porta do seu trem abre para embarcar, É um evento; registre-se para pegar um avião, entrar no trabalho, compre uma música no iTunes, mudar de canal de tv, pegue uma rota de pedágio eletrônico: cada uma dessas ações gera dados.
De acordo, você entendeu: há mais dados do que nunca e tudo que você precisa fazer é olhar para a taxa de penetração de terabytes para computadores pessoais domésticos como um sinal revelador. Costumávamos manter uma lista de todos os armazenamentos de dados que conhecíamos que ultrapassavam um terabyte há quase uma década; basta dizer que as coisas mudaram quando se trata de volume.
Como o termo implica “Big Data”, as organizações enfrentam grandes volumes de dados. Organizações que não sabem como gerenciar esses dados ficam sobrecarregadas com eles. Mas a oportunidade existe, com a plataforma tecnológica certa, para analisar quase todos os dados (ou pelo menos mais deles identificando os dados que são úteis para você) para entender melhor o seu negócio, seus clientes e o mercado. E isso leva ao dilema atual enfrentado pelas empresas de hoje em todos os setores..
Conforme a quantidade de dados disponíveis para a empresa aumenta, a porcentagem de dados que pode processar, entender e analisar está diminuindo, criando assim a zona cega.
O que há nessa zona cega?
Você não sabe: pode ser algo ótimo ou talvez nada, mas o "não sei" é o problema (ou a oportunidade, dependendo de como você olha para isso). A conversa sobre os volumes de dados mudou de terabytes para petabytes, com uma mudança inevitável para zetabytes, e todos esses dados não podem ser armazenados em seus sistemas tradicionais.
2. A variedade de dados
O volume associado ao fenômeno Big Data traz consigo novos desafios para os data centers que tentam lidar com ele: sua variedade.
Com a explosão de sensores e dispositivos inteligentes, bem como tecnologias de colaboração social, os dados de uma empresa tornaram-se complexos, porque incluem não apenas dados relacionais tradicionais, mas também dados brutos, páginas da web semiestruturadas e não estruturadas, arquivos de weblog (incluindo dados de clickstream), índices de pesquisa, fóruns de mídia social, Correio eletrônico, documentos, dados do sensor de sistemas ativos e passivos, etc.
O que mais, Os sistemas tradicionais podem ter dificuldade em armazenar e realizar as análises necessárias para entender o conteúdo desses registros porque muitas das informações geradas não se prestam às tecnologias tradicionais de banco de dados.. Em minha experiência, embora algumas empresas estejam avançando ao longo do caminho, em geral, a maioria está apenas começando a entender as oportunidades de big data.
Em poucas palavras, a variedade representa todos os tipos de dados: uma mudança fundamental dos requisitos tradicionais de análise de dados estruturados para incluir dados brutos, semiestruturado e não estruturado como parte do processo de conhecimento e tomada de decisão. As plataformas analíticas tradicionais não suportam variedade. Porém, o sucesso de uma organização dependerá de sua capacidade de extrair conhecimento dos vários tipos de dados disponíveis, que incluem tradicionais e não tradicionais.
Quando olhamos para trás em nossas carreiras de banco de dados, às vezes é humilhante ver que passamos mais do nosso tempo apenas no 20 porcentagem de dados: o tipo relacional que está perfeitamente formatado e se encaixa perfeitamente em nossos esquemas estritos. Mas a verdade da questão é que o 80 por cento dos dados do mundo (e cada vez mais desses dados são responsáveis por estabelecer novos recordes de velocidade e volume) não são estruturados ou, no melhor dos casos, semiestructurados. Se você olhar para um feed do Twitter, verás la estructura en su formato JSONJSON, o Notação de objeto JavaScript, É um formato leve de troca de dados que é fácil para os humanos lerem e escreverem, e fácil para as máquinas analisarem e gerarem. É comumente usado em aplicativos da web para enviar e receber informações entre um servidor e um cliente. Sua estrutura é baseada em pares de valores-chave, tornando-o versátil e amplamente adotado no desenvolvimento de software.., mas o texto real não é estruturado e tem compreensão que pode ser gratificante.
Las imágenes de video e imágenes no se almacenan fácil o eficientemente en una base de dadosUm banco de dados é um conjunto organizado de informações que permite armazenar, Gerencie e recupere dados com eficiência. Usado em várias aplicações, De sistemas corporativos a plataformas online, Os bancos de dados podem ser relacionais ou não relacionais. O design adequado é fundamental para otimizar o desempenho e garantir a integridade das informações, facilitando assim a tomada de decisão informada em diferentes contextos.... relacional, certas informações de eventos podem mudar dinamicamente (como padrões climáticos), que não é adequado para esquemas estritos, e mais. Para capitalizar a oportunidade de Big Data, as empresas devem ser capazes de analisar todos os tipos de dados, relacional e não relacional: texto, dados do sensor, audio, vídeo, transacional e mais.
3. Velocidade de dados
Assim como o volume e a variedade de dados que coletamos mudaram e o armazenamento, A velocidade com que são gerados e devem ser tratados também mudou.. Uma compreensão convencional de velocidade geralmente considera a rapidez com que os dados chegam e são armazenados, e suas taxas de recuperação associadas. Embora gerenciar tudo isso rapidamente seja bom, e os volumes de dados que estamos vendo são uma consequência da velocidade com que os dados chegam.
Para se adaptar à velocidade, uma nova maneira de pensar sobre um problema deve começar no ponto de partida dos dados. Em vez de limitar a ideia de velocidade às taxas de crescimento associadas aos seus repositórios de dados, sugerimos que você aplique esta definição aos dados em movimento: a velocidade com que os dados fluem.
Depois de tudo, concordamos que as empresas de hoje lidam com petabytes de dados em vez de terabytes, e o aumento de sensores RFID e outros fluxos de informação levou a um fluxo constante de dados a uma taxa que tornou impossível para os sistemas tradicionais. lidar. As vezes, Ganhar uma vantagem sobre a concorrência pode significar detectar uma tendência, problema ou oportunidade em apenas alguns segundos, ou mesmo microssegundos, antes de outra pessoa.
O que mais, mais e mais dados produzidos hoje têm uma vida útil muito curta, portanto, as organizações devem ser capazes de analisar esses dados quase em tempo real se esperam encontrar insights valiosos nesses dados. No processamento tradicional, você pode pensar em executar consultas com dados relativamente estáticos: por exemplo, consulta “Mostre-me todas as pessoas que vivem na zona de inundação do ABC” resultaria em um único conjunto de resultados que seria usado como uma lista de entrada de aviso do tempo. Padrão. Com computação de fluxo, você pode executar um processo semelhante a uma consulta contínua que identifica as pessoas que estão “nas zonas de inundação ABC”, mas você obtém resultados continuamente atualizados porque as informações de localização dos dados de GPS são atualizadas em tempo real.
Lidar com Big Data de forma eficaz requer que você execute análises em relação ao volume e à variedade de dados enquanto eles ainda estão em movimento., não só depois que eles estão em repouso. Considere exemplos de rastreamento de saúde neonatal a mercados financeiros; em todos os casos, exigem o manuseio do volume e variedade de dados de novas maneiras.
Notas finais
Você não pode se dar ao luxo de examinar todos os dados que estão disponíveis para você em seus processos tradicionais; são muitos dados com muito pouco valor conhecido e muito custo apostado. As plataformas de Big Data oferecem uma maneira de armazenar e processar de forma econômica todos os dados e descobrir o que é valioso e o que vale a pena explorar. O que mais, já que estamos falando sobre análise de dados em repouso e dados em movimento, os dados reais a partir dos quais você pode encontrar valor não são apenas mais amplos, eles também podem usá-los e analisá-los mais rapidamente em tempo real.
Recomendo que você leia estes artigos para se familiarizar com as ferramentas para Big Data:
Deixe-nos saber seus pensamentos nos comentários abaixo..
Referência
Compreendendo Big Data: Análise para Hadoop de classe empresarial e dados de streaming.





