
Estágio 1: Qualquer banco global hoje tem mais do que 100 milhões de clientes fazendo bilhões de transações a cada mês.
Estágio 2: Sites de mídia social ou sites de comércio eletrônico rastreiam o comportamento do cliente no site e fornecem informações / produto relevante.
Os sistemas tradicionais lutam para lidar com essa escala na taxa necessária de uma maneira econômica.
É aqui que as plataformas de Big Data vêm para ajudar.. Neste artigo, nós apresentamos a você o fascinante mundo do Hadoop. Hadoop é útil ao lidar com grandes dados. Isso pode não tornar o processo mais rápido, mas nos dá a capacidade de usar poder de processamento paralelo para lidar com big data. Em resumo, Hadoop nos dá a capacidade de lidar com as complexidades de alto volume, velocidade e variedade de dados (popularmente conhecido como 3V).
tenha em conta que, além do Hadoop, existem outras plataformas de big data, por exemplo, NoSQL (MongoDB é o mais popular), nós os veremos mais tarde.
Introdução ao Hadoop
Hadoop é um ecossistema completo de projetos de código aberto que nos fornece a estrutura para lidar com big data. Vamos começar fazendo um brainstorming dos desafios potenciais de lidar com Big Data (em sistemas tradicionais) e então vamos ver a capacidade da solução Hadoop.
A seguir estão os desafios em que posso pensar ao lidar com Big Data:
1. Alto investimento de capital na aquisição de um servidor com alta capacidade de processamento.
2. Muito tempo investido
3. No caso de uma longa consulta, imagine que um erro ocorra na última etapa. Você vai perder muito tempo fazendo essas iterações.
4. Dificuldade em gerar dúvidas sobre o programa
Veja como o Hadoop resolve todos esses problemas:
1. Grande investimento de capital na aquisição de um servidor de alto rendimento: Os clusters do Hadoop são executados em hardware básico normal e mantêm várias cópias para garantir a confiabilidade dos dados. No máximo 4500 máquinas juntas usando Hadoop.
2. Muito tempo investido : O processo é dividido em partes e executado em paralelo, economizando tempo. No máximo 25 Petabytes (1 PB = 1000 tb) dados usando Hadoop.
3. No caso de uma longa consulta, imagine que um erro ocorra na última etapa. Você vai perder muito tempo fazendo essas iterações : Hadoop faz backup de conjuntos de dados em todos os níveis. Também executa consultas em conjuntos de dados duplicados para evitar perda de processo em caso de falha individual. Essas etapas tornam o processamento do Hadoop mais preciso e preciso.
4. Dificuldade em gerar dúvidas sobre o programa : As consultas no Hadoop são tão simples quanto codificar em qualquer linguagem. Você só precisa mudar a maneira como pensa sobre a criação de uma consulta para permitir o processamento paralelo.
Fundo Hadoop
Com um aumento na penetração e no uso da Internet, os dados capturados pelo Google aumentaram exponencialmente ano após ano. Só para dar uma estimativa desse número, sobre 2007 O Google coletou uma média de 270 PB de dados todos os meses. O mesmo número aumentou para 20000 PB todos os dias em 2009. Obviamente, O Google precisava de uma plataforma melhor para processar dados tão grandes. Google implementó un modelo de programación llamado MapReduceO MapReduce é um modelo de programação projetado para processar e gerar grandes conjuntos de dados com eficiência. Desenvolvido pelo Google, Essa abordagem divide o trabalho em tarefas menores, que são distribuídos entre vários nós em um cluster. Cada nó processa sua parte e, em seguida, os resultados são combinados. Esse método permite dimensionar aplicativos e lidar com grandes volumes de informações, sendo fundamental no mundo do Big Data...., quem poderia processar estes 20000 PB por dia. O Google executou essas operações MapReduce em um sistema de arquivos especial chamado Google File System (GFS). Lamentavelmente, GFS não é de código aberto.
Doug Cutting e Yahoo! realizó ingeniería inversa del modelo GFS y construyó un Sistema de arquivos distribuídoUm sistema de arquivos distribuído (DFS) Permite armazenamento e acesso a dados em vários servidores, facilitando o gerenciamento de grandes volumes de informações. Esse tipo de sistema melhora a disponibilidade e a redundância, à medida que os arquivos são replicados para locais diferentes, Reduzindo o risco de perda de dados. O que mais, Permite que os usuários acessem arquivos de diferentes plataformas e dispositivos, promovendo colaboração e... Hadoop (HDFSHDFS, o Sistema de Arquivos Distribuído Hadoop, É uma infraestrutura essencial para armazenar grandes volumes de dados. Projetado para ser executado em hardware comum, O HDFS permite a distribuição de dados em vários nós, garantindo alta disponibilidade e tolerância a falhas. Sua arquitetura é baseada em um modelo mestre-escravo, onde um nó mestre gerencia o sistema e os nós escravos armazenam os dados, facilitando o processamento eficiente de informações..) paralelo. O software ou estrutura que suporta HDFS e MapReduce é conhecido como Hadoop. Hadoop é de código aberto e distribuído pela Apache.
Talvez você esteja interessado: Introdução ao MapReduce
Estrutura de processamento Hadoop
Vamos fazer uma analogia com nossa vida diária para entender como o Hadoop funciona. A base da pirâmide de qualquer empresa são as pessoas que são contribuintes individuais. Eles podem ser analistas, programadores, trabalho manual, chefs, etc. Gerenciar seu trabalho é o gerente de projeto. O gerente de projeto é responsável pela conclusão bem-sucedida da tarefa. Necessidade de distribuição de mão de obra, suavizar a coordenação entre eles, etc. O que mais, a maioria dessas empresas tem um gerente de pessoal, quem está mais preocupado em reter o time.

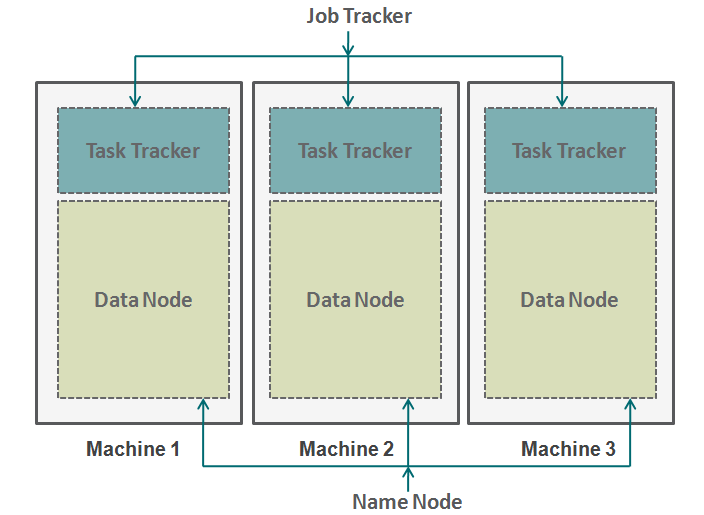
O Hadoop funciona em um formato semelhante. Na parte inferior, temos as máquinas dispostas em paralelo. Essas máquinas são análogas ao contribuinte individual em nossa analogia. Cada máquina tiene un nóO Nodo é uma plataforma digital que facilita a conexão entre profissionais e empresas em busca de talentos. Através de um sistema intuitivo, permite que os usuários criem perfis, Compartilhar experiências e acessar oportunidades de trabalho. Seu foco em colaboração e networking torna o Nodo uma ferramenta valiosa para quem deseja expandir sua rede profissional e encontrar projetos que se alinhem com suas habilidades e objetivos.... de datos y un rastreador de tareas. O nó de dados também é conhecido como HDFS (Sistema de arquivos distribuídos HadoopEl Sistema de Archivos Distribuido de Hadoop (HDFS) es una parte fundamental del ecosistema Hadoop, diseñado para almacenar grandes volúmenes de datos de manera distribuida. HDFS permite el almacenamiento escalable y la gestión eficiente de datos, dividiendo archivos en bloques que se replican en diferentes nodos. Esto asegura la disponibilidad y la resistencia ante fallos, facilitando el procesamiento de datos masivos en entornos de big data....) e o rastreador de tarefas também é conhecido como redutores de mapa.
O nó de dados contém todo o conjunto de dados e o rastreador de tarefas executa todas as operações. Você pode imaginar o rastreador de tarefas como seus braços e pernas, permitindo que você execute uma tarefa e um nó de dados como seu cérebro, contendo todas as informações que você deseja processar. Essas máquinas estão trabalhando em silos e é muito importante coordená-las. Rastreadores de tarefas (gerente de projeto em nossa analogia) em máquinas diferentes são coordenadas por um rastreador de trabalho. Rastreador de trabalho**Rastreador de trabalho: Una Herramienta Esencial para la Búsqueda de Empleo** Job Tracker es una plataforma diseñada para facilitar la búsqueda de empleo, permitiendo a los usuarios organizar y seguir sus solicitudes de trabajo. Con características como la gestión de currículums, alertas de nuevas ofertas y análisis de tendencias laborales, Job Tracker ayuda a los solicitantes a optimizar su proceso de búsqueda y aumentar sus posibilidades de éxito en el competitivo... se asegura de que cada operación se complete y si hay una falla en el proceso en cualquier nodo, você precisa atribuir uma tarefa duplicada a algum rastreador de tarefas. O rastreador de trabalho também distribui a tarefa inteira para todas as máquinas.
Por outro lado, um nó nomeado coordena todos os nós de dados. Ele governa a distribuição de dados que vão para cada máquina. Ele também verifica qualquer tipo de purga que ocorreu em uma máquina. Se essa depuração ocorrer, encontra dados duplicados que foram enviados para outro nó de dados e os duplica novamente. Você pode pensar neste nó de nome como o gerente de pessoas em nossa analogia, quem se preocupa mais com a retenção de todo o conjunto de dados.
Quando não usar o Hadoop?
Até agora, vimos como o Hadoop tornou possível o manuseio de big data. Mas, em alguns cenários, a implementação do Hadoop não é recomendada. Abaixo estão alguns desses cenários:
- Acesso a dados de baixa latência: acesso rápido a pequenos pedaços de dados
- Modificação de vários dados: O Hadoop é mais adequado apenas se estivermos principalmente preocupados com a leitura de dados e não com a gravação de dados.
- Muitos arquivos pequenos: Hadoop se encaixa melhor em cenários, onde temos poucos, mas grandes arquivos.
Notas finais
Este artigo fornece uma visão de como o Hadoop vem para o resgate ao lidar com dados enormes. Entender como o Hadoop funciona é muito essencial antes de começar a codificá-lo. Isso ocorre porque você precisa mudar a maneira como você pensa em um código. Agora você precisa começar a pensar em habilitar o processamento paralelo. Você pode executar muitos tipos diferentes de processos no Hadoop, mas você precisa converter todos esses códigos em uma função de redução de mapa. Nos próximos artigos, explicaremos como você pode converter sua lógica simples em lógica Map-Reduce baseada em Hadoop. Também faremos estudos de caso específicos da linguagem R para construir uma compreensão sólida do aplicativo Hadoop..
O artigo foi útil para você? Compartilhe conosco todos os aplicativos Hadoop práticos que encontrar no trabalho. Deixe-nos saber sua opinião sobre este item na caixa abaixo..





