Introdução
A manipulação de dados é uma fase inevitável da modelagem preditiva. Um modelo preditivo robusto não pode ser construído simplesmente usando algoritmos de aprendizado de máquina. Mas, com uma abordagem para entender o problema do negócio, os dados subjacentes, realizar as manipulações de dados necessárias e, em seguida, extrair informações de negócios.
Entre essas várias fases do modelo de construção, na maioria das vezes é gasto entendendo os dados subjacentes e realizando as manipulações necessárias. Este também seria o tema central deste artigo: pacotes para manipulação de dados mais rápida em R.

O que é manipulação de dados?
Se você ainda está confuso com este 'termo', deixe-me explicar para você. Manipulação de dados é um termo que é usado livremente com “Exploração de dados”. Envolve "manipular"’ dados usando um conjunto de variáveis disponíveis. Isso é feito para melhorar a precisão e precisão associadas aos dados..
Na realidade, o processo de coleta de dados pode ter muitas lacunas. Existem vários fatores incontroláveis que levam à imprecisão nos dados, como a situação mental dos entrevistados, vieses pessoais, diferenças / erros nas leituras de máquinas, etc. Para mitigar essas imprecisões, dados são manipulados para aumentar a precisão (máximo) possível nos dados.
As vezes, esta etapa também é conhecida como disputa de dados ou limpeza de dados.
Diferentes formas de manipular / dados de processo:
Não há maneira certa ou errada de manipular os dados, desde que você entendê-los e ter tomado as ações necessárias no final do exercício. Porém, aqui estão algumas maneiras gerais que as pessoas tentam abordar a manipulação de dados. Aqui estão eles.:
- Em geral, iniciantes em R se sentem confortáveis manipular dados usando funções de base R incorporadas. Este é um bom primeiro passo, mas muitas vezes é repetitivo e demorado. Portanto, é uma maneira menos eficiente de resolver o problema.
- Usando pacotes para manipulação de dados. CRAN tem mais do que 7000 pacotes disponíveis hoje. Em palavras simples, esses pacotes não são nada mais do que uma coleção de códigos pré-escritos comumente usados. Ajudá-lo a realizar tarefas repetitivas com o estômago vazio, reduzir erros de codificação e são ajudados por código escrito com especialistas (através do ecossistema de código aberto para R) para tornar seu código mais eficiente. esta é geralmente a maneira mais comum de executar a manipulação de dados.
- Usando algoritmos ML para manipulação de dados. você pode usar algoritmos de reforço baseados em árvores para lidar com dados perdidos e outliers. Enquanto estes definitivamente requerem menos tempo, essas abordagens geralmente deixam você querendo uma melhor compreensão dos dados no final..
Portanto, na maior parte do tempo, o uso de pacotes é o método de fato para a realização da manipulação de dados. Neste artigo, Eu expliquei vários pacotes que tornam a vida mais fácil para 'R’ durante o estágio de manipulação de dados.
Observação: Este artigo é mais adequado para iniciantes em Linguagem R. Você pode instalar um pacote usando:
install.packages('package name')
Lista de pacotes
Para um melhor entendimento, Também demonstrei seu uso ao realizar operações comumente usadas. Abaixo está a lista de pacotes discutidos neste artigo:
- dplyr
- tabela de dados
- ggplot2
- remodelar2
- leitor
- arrumador
- lubrificar
Observação: Eu entendo que ggplot2 é um pacote gráfico. Mas, em geral, ajuda a visualizar dados (distribuições, Correlações) e realizar manipulações de acordo. Portanto, Eu adicionei a esta lista. Em todos os pacotes, Eu cobri apenas os comandos mais usados na manipulação de dados.
pacote dplyr
Esses pacotes são criados e mantidos por Hadley Wickham. Este pacote tem tudo (quase) para acelerar seus esforços de manipulação de dados. É mais conhecido pela exploração e transformação de dados. Sua sintaxe de encadeamento torna-o altamente adaptável ao uso. Inclui 5 principais comandos de manipulação de dados:
- filtro: filtra dados com base em uma condição
- selecionar: usado para selecionar colunas de interesse a partir de um conjunto de dados
- Organizar: é usado para organizar os valores do conjunto de dados em ordem ascendente ou descendente.
- mutar: é usado para criar novas variáveis a partir de variáveis existentes
- resumo (com group_by): é usado para realizar análises usando operações comumente usadas, pelo menos, máximo, contagem média, etc.
Concentre-se nesses comandos e faça um ótimo trabalho na exploração de dados. Vamos entender esses comandos um por um. Eu usei 2 conjuntos de dados R pré-instalados, a saber, mtcars e íris.
> biblioteca(dplyr)
> dados("mtcars")
> dados('íris')
> meus dados <- mtcars
#ler dados > cabeça(meus dados)

#criando um dataframe local. O quadro de dados local é mais fácil de ler > mynewdata <- tbl_df(meus dados) > myirisdata <- tbl_df(íris)
#agora os dados estarão na estrutura tabular > mynewdata> myirisdata
 > myirisdata
> myirisdata
#usar filtro para filtrar dados com as condições necessárias > filtro(mynewdata, Cyl > 4 & engrenagem > 4 )> filtro(mynewdata, Cyl > 4)
> filtro (myirisdata, Espécies% em% c ('sedoso', 'virginica'))
 > filtro(mynewdata, Cyl > 4)
> filtro(mynewdata, Cyl > 4)
 > filtro (myirisdata, Espécies% em% c ('sedoso', 'virginica'))
> filtro (myirisdata, Espécies% em% c ('sedoso', 'virginica'))
#usar selecionarO comando "SELECIONE" é fundamental em SQL, usado para consultar e recuperar dados de um banco de dados. Permite especificar colunas e tabelas, filtrando resultados usando cláusulas como "ONDE" e ordenar com "ORDENAR POR". Sua versatilidade o torna uma ferramenta essencial para manipulação e análise de dados, facilitando a obtenção de informações específicas de forma eficiente.... to pick columns by name > selecionar(mynewdata, Cyl,Mpg,Hp)#aqui você pode usar (-) para esconder colunas > selecionar(mynewdata, -Cyl, -Mpg )
# ocultar un rango de columnas> selecionar (mynewdata, -c (Cyl, Mpg))
 #aqui você pode usar (-) para esconder colunas
> selecionar(mynewdata, -Cyl, -Mpg )
#aqui você pode usar (-) para esconder colunas
> selecionar(mynewdata, -Cyl, -Mpg )
 # ocultar un rango de columnas> selecionar (mynewdata, -c (Cyl, Mpg))
# ocultar un rango de columnas> selecionar (mynewdata, -c (Cyl, Mpg))
#encadeamento ou pipelining - a way to perform multiple operations #in one line > mynewdata %>% selecionar(Cyl, Wt, engrenagem)%>% filtro(Wt > 2)
#organizar pode ser usado para reordenar linhas
> mynewdata%>%
selecionar(Cyl, Wt, engrenagem)%>%
organizar(Wt)

#ou
> mynewdata%>%
selecionar(Cyl, Wt, engrenagem)%>%
organizar(desc(Wt))

#mutação - criar novas variáveis
> mynewdata %>%
selecionar(Mpg, Cyl)%>%
mutação(newvariable = mpg*cyl)

#ou
> newvariável <- mynewdata %>% mutação(newvariable = mpg*cyl)
#resumir - isso é usado para encontrar insights a partir de dados
> myirisdata%>%
group_by(Espécies)%>%
resumir(Média = média(Sepal.Comprimento, na.rm = TRUE))
#ou usar resumo cada
 #ou usar resumo cada
#ou usar resumo cada> myirisdata%>%
group_by(Espécies)%>%
summarise_each(Divertimentos(quer dizer, n()), Sepal.Comprimento, Sepal.Largura)
 #Você pode criar comandos de cadeia complexos usando estes 5 Verbos.
#Você pode criar comandos de cadeia complexos usando estes 5 Verbos.
 #Você pode criar comandos de cadeia complexos usando estes 5 Verbos.
#Você pode criar comandos de cadeia complexos usando estes 5 Verbos.#você pode renomear as variáveis usando o comando rename > mynewdata %>% renomear(milhas = mpg)
pquete datas.table
este pacote permite que você execute uma manipulação mais rápida em um conjunto de dados. deixe suas formas tradicionais de subconfigurar linhas e colunas e use este pacote. Com codificação mínima, pode fazer muito mais. O uso de data.table ajuda a reduzir o tempo de cálculo em comparação com data.frame. Você vai se surpreender com a simplicidade deste pacote.
Uma tabela de dados tem 3 partes, a saber, DT[eu,j,por]. Você pode entender isso como, podemos dizer r para fazer um subconjunto das linhas usando 'i', para calcular 'j’ que é agrupado por 'by'. A maioria das vezes, “por” se relaciona con una variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... Categórico. No seguinte código, Eu tenho usado 2 conjuntos de dados (qualidade do ar e íris).
#Carregar dados
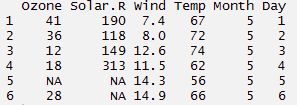
> dados("qualidade do ar")
> meus dados <- qualidade do ar
> cabeça(qualidade do ar,6)

> dados(íris) > myíris <- íris
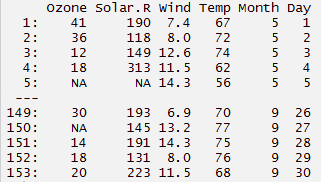
#pacote de carga > biblioteca(data.table)
> meus dados <- data.table(meus dados) > meus dados
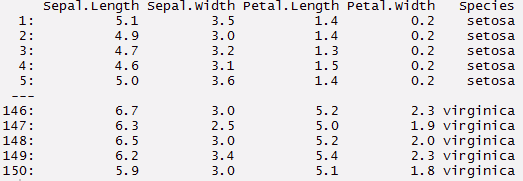
> myíris <- data.table(myíris) > myíris
#linhas subconjunto - selecionar 2ª a 4ª linha > meus dados[2:4,]
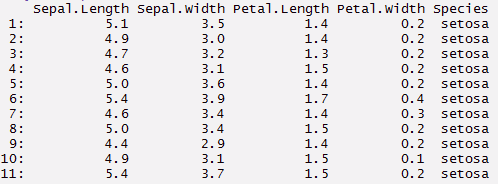
#selecionar colunas com valores específicos > myíris[Espécie == 'setosa']
 #selecionar colunas com valores específicos
> myíris[Espécie == 'setosa']
#selecionar colunas com valores específicos
> myíris[Espécie == 'setosa']
#selecionar colunas com vários valores. This will give you columns with Setosa #and virginica species > myíris[Espécies %em% c('sedoso', 'virginica')] #selecionar colunas. Retorna ao vetor > meus dados[,Temp]

> meus dados[,.(Temp,Mês)]
#soma de retornos da coluna selecionada > meus dados[,soma(Ozono, na.rm = TRUE)] [1]4887
#soma de retornos e desvio padrão > meus dados[,.(soma(Ozono, na.rm = TRUE), SD(Ozono, na.rm = TRUE))]
#impressão e enredo
> myíris[,{imprimir(Sepal.Comprimento)
> enredo(Sepal.Largura)
ZERO}]



#agrupamento por uma variável > myíris[,.(sepalsum = soma(Sepal.Comprimento)), by=Espécies]

#selecionar uma coluna para computação, portanto, precisa definir a chave na coluna
> setkey(myíris, Espécies)
#seleciona todas as linhas associadas a esse ponto de dados
> myíris['sedoso']
> myíris[c('sedoso', 'virginica')]
pacote ggplot2
ggplot oferece um mundo totalmente novo de cores e padrões. Se você é uma alma criativa, você vai adorar este pacote todo o caminho. Mas, se você quiser aprender o que é preciso para começar, siga os códigos abaixo. Você deve aprender as maneiras de traçar pelo menos estes 3 gráficos: Diagrama de dispersãoO gráfico de dispersão é uma ferramenta gráfica usada em estatística para visualizar a relação entre duas variáveis. Consiste em um conjunto de pontos em um plano cartesiano, onde cada ponto representa um par de valores correspondentes às variáveis analisadas. Este tipo de gráfico permite identificar padrões, Tendências e possíveis correlações, facilitando a interpretação dos dados e a tomada de decisão com base nas informações visuais apresentadas...., Gráfico de barras, Histograma.
Estes 3 padrões gráficos abrangem quase todos os tipos de representação de dados, exceto mapas. ggplot é enriquecido com recursos personalizados para tornar sua visualização melhor e melhor. Torna-se ainda mais poderoso quando agrupado com outros pacotes como cowplot, gridExtra. De fato, há muitas funções. Portanto, você deve se concentrar em alguns comandos e desenvolver sua experiência neles. Eu também mostrei o método para comparar gráficos em uma janela. Requer pacote 'gridExtra'. Portanto, você deve instalá-lo. Usei conjuntos de dados R pré-instalados.
> biblioteca(ggplot2) > biblioteca(gridExtra) > df <- Dente-de-dente
> df$dose <- as.fator(df$dose) > cabeça(df)
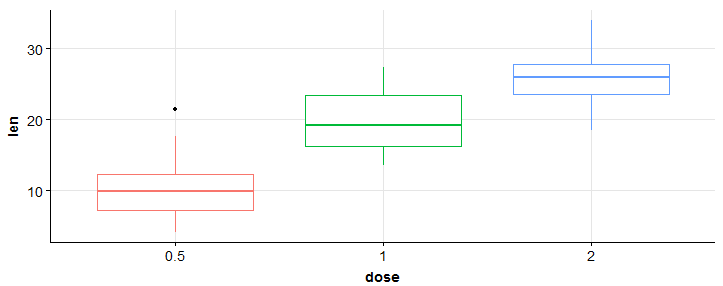
#boxplot > bp <- ggplot(df, aes(x = dose, y = len, cor = dose)) + geom_boxplot() + tema(legend.position = 'nenhum') > bp
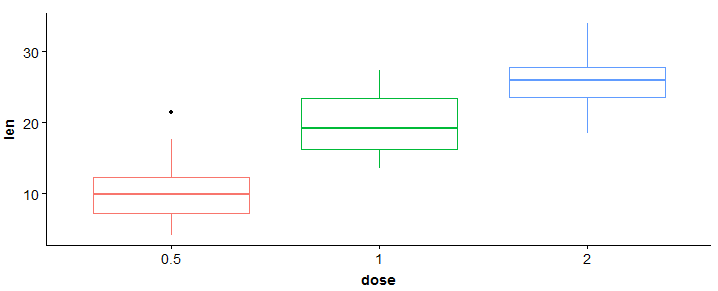
#adicionar linhas de grade > bp + background_grid(maior = "xy", menor="Nenhum")
#dispersão > Sp <- ggplot(Mpg, aes(x = cty, y = hwy, cor = fator(Cyl)))+geom_point(tamanho = 2.5) > Sp
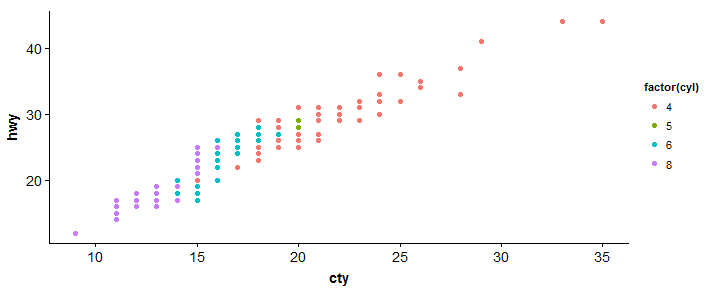
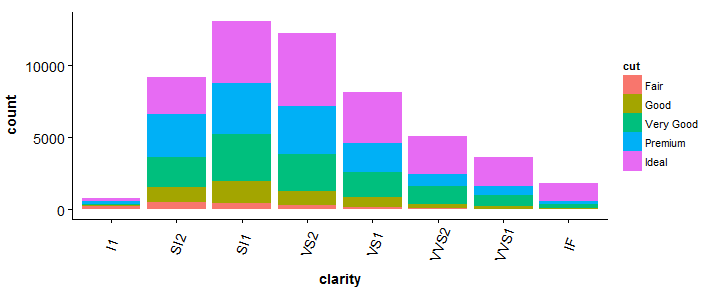
#barplot > bp <- ggplot(ouros, aes(clareza, preenchimento = corte)) + geom_bar() +tema(axis.text.x = element_text(ângulo = 70, vjust = 0.5)) > bp
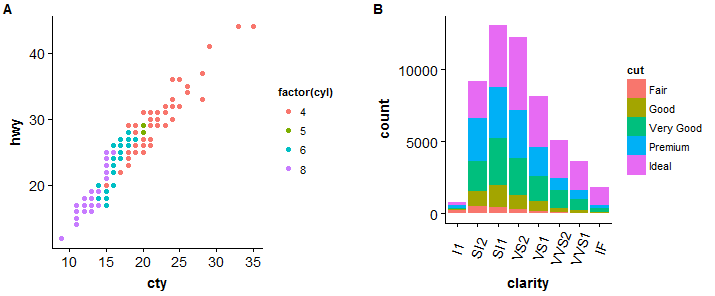
#comparar dois lotes
> plot_grid(Sp, bp, rótulos = c("UMA","B"), ncol = 2, nrow = 1)
 #histograma
> ggplot(ouros, aes(x = quilate)) + geom_histogram(binwidth = 0.25, preenchimento="steelblue")+scale_x_continuous(quebra=seq(0,3, by=0.5))
#histograma
> ggplot(ouros, aes(x = quilate)) + geom_histogram(binwidth = 0.25, preenchimento="steelblue")+scale_x_continuous(quebra=seq(0,3, by=0.5))

 #histograma
> ggplot(ouros, aes(x = quilate)) + geom_histogram(binwidth = 0.25, preenchimento="steelblue")+scale_x_continuous(quebra=seq(0,3, by=0.5))
#histograma
> ggplot(ouros, aes(x = quilate)) + geom_histogram(binwidth = 0.25, preenchimento="steelblue")+scale_x_continuous(quebra=seq(0,3, by=0.5))
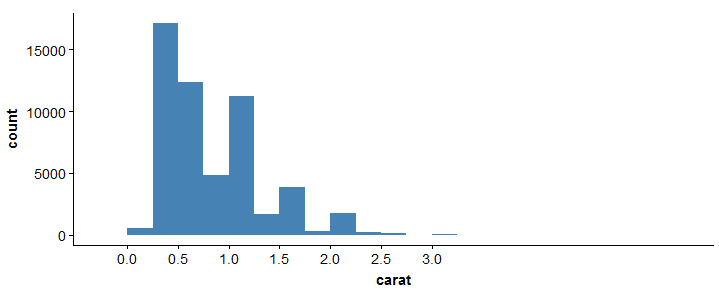
Para obter mais informações sobre este pacote, ver a folha de referência aqui: folha de referência ggplot2
reformular2 pacote
Como o próprio nome sugere, este pacote é útil para remodelar dados. Todos sabemos que os dados vêm de muitas formas.. Portanto, somos obrigados a domá-lo de acordo com nossas necessidades. Em geral, o processo de remodelação de dados em R é tedioso e preocupante. as funções base de r consistem na opção 'agregação’ pelos quais os dados podem ser reduzidos e reorganizados em formas menores, mas com uma redução na quantidade de informações. A agregação inclui funções base tapply, por e acrescentou. O pacote de remodelação resolve esses problemas. Aqui tentamos combinar recursos que têm valores únicos. Tenho 2 funções para saber derreter e questão.
derreter : Esse recurso converte dados de formato amplo em formato longo. É uma forma de reestruturação na qual múltiplas colunas categóricas se fundem’ em linhas únicas. Vamos entender usando o código abaixo.
#criar um dado
> EU IRIA <- c(1,2,3,4,5)
> Nomes <- c('Joseph','Matrin','Joseph','James','Matrin')
> DateofBirth <- c(1993,1992,1993,1994,1992)
> Assunto<- c('Matemáticas','Biologia','Ciência','Psycologia','Física')
> estadados <- quadro de dados(EU IRIA, Nomes, DateofBirth, Assunto) > data.table(estadados)
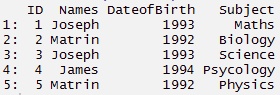
#pacote de carga
> install.packages('remodelar2')
> biblioteca(remodelar2)
#Derreter
> Mt <- Derreter(estadados, id =(c('ID','Nomes')))
> Mt

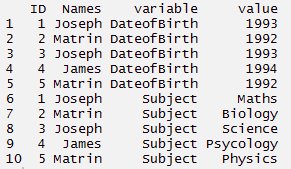
questão : Esse recurso converte dados de formato longo para formato amplo. Começa com dados desbotados e muda para formato longo. É apenas o inverso de derreter Função. Ele tem duas funções ou seja, dcast e um molde. dcast retorna um quadro de dados como saída. acast retorna um vetor / matriz / matriz como saída. Vamos entender usando o código abaixo.
#elenco > mcast <- dcast(Mt, DateofBirth + Assunto ~ variável) > mcast
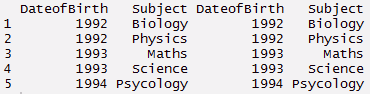
Observação: Enquanto pesquisava, Eu encontrei esta imagem que descreve adequadamente o pacote de remodelação.
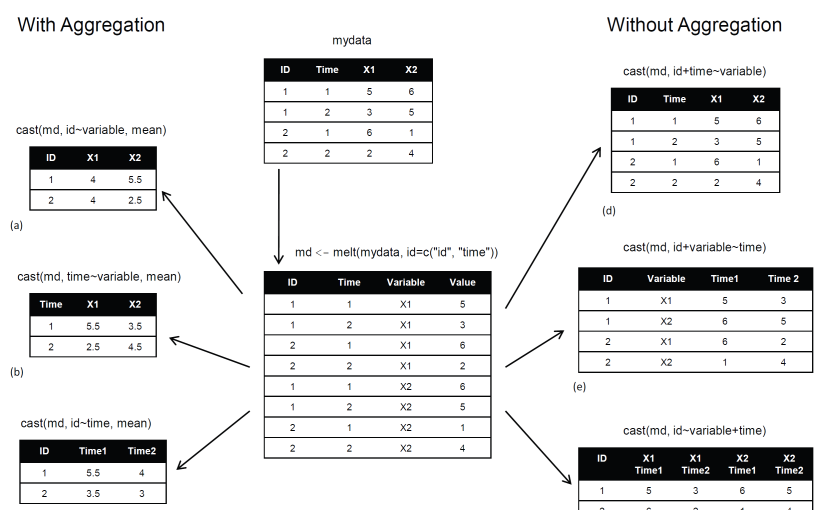 fonte: r-estatísticas
fonte: r-estatísticas
pacote de leitura
Como o nome sugere, 'readr’ ajuda a ler várias formas de dados em R. Com uma velocidade 10 vezes mais rápido. Aqui, personagens nunca se tornam fatores (para que não mais stringAsFactors = FALSE). Este pacote pode substituir as funções tradicionais da leitura base R.csv () e ler.tabela (). Ajuda a ler os dados a seguir:
- Arquivos delimitados com
read_delim(),read_csv(),read_tsv(), eread_csv2(). - Arquivos de largura fixa com
read_fwf(), eread_table(). - Arquivos de log da Web com
read_log()
Se o tempo de carga de dados for maior do que 5 segundos, este recurso também mostrará uma barra de progresso. você pode suprimir a barra de progresso marcando-a como FALSA. Vamos ver o seguinte código:
> install.packages('Readr')
> biblioteca(readr)
> read_csv('test.csv',col_names = TRUE)
você também pode especificar o tipo de dados de cada coluna carregada nos dados usando o seguinte código:
> read_csv("íris.csv", col_types = lista(
Sepal.Comprimento = col_double(),
Sepal.Largura = col_double(),
Pétala.Comprimento = col_double(),
Pétala.Largura = col_double(),
Espécies = col_factor(c("setosa", "Versicolor", "virginica"))
))
Porém, se você optar por pular colunas sem importância, vai lidar com isso automaticamente. Então, o código acima também pode ser reescrito como:
> read_csv("íris.csv", col_types = lista(
Espécies = col_factor(c("setosa", "Versicolor", "virginica"))
)
PS – readr tem muitas funções auxiliares. Então, quando você digita um arquivo csv, usar write_csv em vez. É muito mais rápido do que escrever.csv.
pacote arrumador
Este pacote pode tornar seus dados visíveis “organizado”. Tenho 4 principais funções para executar esta tarefa. Desnecessário dizer, se você se encontrar preso na fase de exploração de dados, você pode usá-los a qualquer momento (juntamente com dplyr). Esta dupla forma uma equipe formidável. Eles são fáceis de aprender, código e implementar. Estão 4 funções são:
- não importa o nível de granularidade que você tem na tabela dinâmica () – 'reúne’ várias colunas. Mais tarde, faz deles pares-chave: valor. esta função será transformada amplamente de dados para uma forma longa. Você pode usá-lo como uma alternativa para 'derreter'’ no pacote de remodelação.
- Espalhar (): é invertido de coletar. Pegue um par de chaves: valor e converte-o em colunas separadas.
- separar (): divide uma coluna em várias colunas.
- unir (): é invertido ou separado. Junte várias colunas em uma única coluna
Vamos entender de perto usando o seguinte código:
#pacote de carga > biblioteca(arrumador)
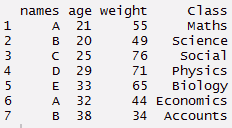
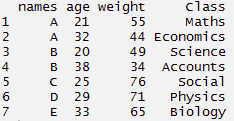
#criar um conjunto de dados falso
> nomes <- c('UMA','B','C','D','E','UMA','B')
> peso <- c(55,49,76,71,65,44,34)
> era <- c(21,20,25,29,33,32,38)
> Classe <- c('Matemáticas','Ciência','Social','Física','Biologia','Economia','Contas')
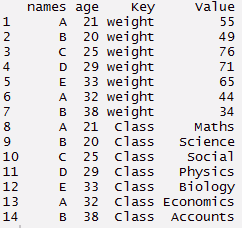
#criar quadro de dados > tdata <- quadro de dados(nomes, era, peso, Classe) > tdata#usando a função de reunir > long_t <- tdata %>% reunir(Chave, Eu usei a técnica abordada neste post do blog aqui para participar do, peso:Classe) > long_t

 #usando a função de reunir
> long_t <- tdata %>% reunir(Chave, Eu usei a técnica abordada neste post do blog aqui para participar do, peso:Classe)
> long_t
#usando a função de reunir
> long_t <- tdata %>% reunir(Chave, Eu usei a técnica abordada neste post do blog aqui para participar do, peso:Classe)
> long_t
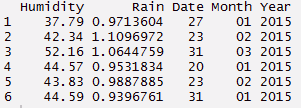
A função separada é melhor usada quando somos fornecidos com uma variável de data e hora no conjunto de dados. Porque a coluna contém várias informações, faz sentido dividi-lo e usar esses valores individualmente.. Usando o código abaixo, Eu separei uma coluna em data, mês e ano.
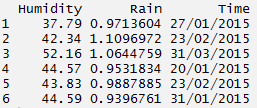
#criar um conjunto de dados
> Humidade <- c(37.79, 42.34, 52.16, 44.57, 43.83, 44.59)
> Chuva <- c(0.971360441, 1.10969716, 1.064475853, 0.953183435, 0.98878849, 0.939676146)
> Tempo <- c("27/01/2015 15:44","23/02/2015 23:24", "31/03/2015 19:15", "20/01/2015 20:52", "23/02/2015 07:46", "31/01/2015 01:55")
#construir um quadro de dados
> d_set <- quadro de dados(Humidade, Chuva, Tempo)
#usando função separada podemos separar data, mês, ano
> separate_d <- d_set%>% separar(Tempo, c('Encontro', 'Mês','Ano'))
> separate_d
 #usando a função unir - reverter de separado
> unite_d <- separate_d%>% unir(Tempo, c(Encontro, Mês, Ano), set = "/")
> unite_d
#usando a função unir - reverter de separado
> unite_d <- separate_d%>% unir(Tempo, c(Encontro, Mês, Ano), set = "/")
> unite_d
 #usando a função de propagação - coleção inversa> wide_t % Espalhar (chave, valor)> wide_t
#usando a função de propagação - coleção inversa> wide_t % Espalhar (chave, valor)> wide_t
 #usando a função unir - reverter de separado
> unite_d <- separate_d%>% unir(Tempo, c(Encontro, Mês, Ano), set = "/")
> unite_d
#usando a função unir - reverter de separado
> unite_d <- separate_d%>% unir(Tempo, c(Encontro, Mês, Ano), set = "/")
> unite_d
 #usando a função de propagação - coleção inversa> wide_t % Espalhar (chave, valor)> wide_t
#usando a função de propagação - coleção inversa> wide_t % Espalhar (chave, valor)> wide_t
Pacote lubrificante
Pacote lubrificado reduz o incômodo de trabalhar com a variável tempo de dados em R. A função incorporada deste pacote oferece uma boa maneira de facilitar a análise de datas e horários. este pacote é frequentemente usado com dados que compreendem dados point-in-time. Aqui eu cobri três tarefas básicas realizadas com Lubridate.
Isso inclui a função de atualização, função de extração de duração e data. Como um iniciante, sei que estes 3 recursos lhe darão experiência suficiente para lidar com variáveis de tempo. Embora, R tem funções incorporadas para lidar com datas, mas isso é muito mais rápido. Vamos entender usando o seguinte código:
> install.packages('lubrificante')
> biblioteca(lubrificar)
#data e hora atuais > agora() [1] "2015-12-11 13:23:48 IST"
#atribuindo data e tempo atuais a n_time variável > n_time <- agora()
#usando a função atualização > n_update <- atualizar(n_time, ano = 2013, mês = 10) > n_update [1] "2013-10-11 13:24:28 IST"
#adicionar dias, meses, ano, Segundos > d_time <- agora() > d_time + ddays(1) [1] "2015-12-12 13:24:54 IST" > d_time + dweeks(2) [1] "2015-12-12 13:24:54 IST" > d_time + dyears(3) [1] "2018-12-10 13:24:54 IST" > d_time + dhours(2) [1] "2015-12-11 15:24:54 IST" > d_time + dminutes(50) [1] "2015-12-11 14:14:54 IST" > d_time + dseconds(60) [1] "2015-12-11 13:25:54 IST"
#data do extrato,Tempo
> n_time$hora <- hora(agora()) > n_time$minuto <- Minuto(agora()) > n_time$segundo <- segundo(agora()) > n_time$mês <- mês(agora()) > n_time$anos <- ano(agora())
#verificar as datas extraídas em colunas separadas > new_data <- quadro de dados(n_time$hora, n_time$minuto, n_time$segundo, n_time$mês, n_time$anos) > new_data
Observação: O melhor uso desses pacotes não é isoladamente, mas como um todo.. Você pode usar facilmente este pacote com dplyr, onde você pode facilmente selecionar uma variável de dados e extrair os dados úteis dele usando o comando string.
Notas finais
Esses pacotes não só melhorariam sua experiência de manipulação de dados., eles também lhe dariam razões para explorar R em profundidade. Agora que vimos, esses pacotes facilitam a codificação R. Não precisa mais escrever códigos longos. Em seu lugar, escrever códigos curtos e fazer mais.
Cada pacote tem recursos multitarefa. Portanto, Sugiro que você obtenha um recurso importante que pode ser usado com frequência. E, uma vez que você se familiarizar com eles, você será capaz de ir mais fundo. Inicialmente cometi este erro.. Eu tentei explorar todas as características do ggplot2 e acabei em confusão. Sugiro que pratique esses códigos durante a leitura. Isso ajudaria você a construir confiança no uso desses pacotes..
Neste artigo, Eu expliquei o uso de 7 R que pode tornar a exploração de dados mais fácil e rápida. R conhecido por suas incríveis características estatísticas, com pacotes recentemente atualizados, também faz dele uma ferramenta favorita dos cientistas de dados.





