Este artigo foi publicado como parte do Data Science Blogathon
Introdução
Nós, os humanos, nós lemos textos quase todos os minutos de nossa vida. Não seria ótimo se nossas máquinas ou sistemas também pudessem ler texto como nós fazemos? Mas a questão mais importante é “Como fazemos nossas máquinas lerem”? É aqui que entra o reconhecimento óptico de caracteres. (OCR).
Reconhecimento óptico de caracteres (OCR)
Reconhecimento óptico de caracteres (OCR) é uma técnica de leitura ou captura de texto de fotografias impressas ou digitalizadas, imagens manuscritas e convertendo-as em um formato digital editável e pesquisável.
Formulários
OCR tem muitas aplicações nos negócios de hoje. Alguns deles estão listados abaixo:
- Reconhecimento de passaporte em aeroportos
- Automação de entrada de dados
- Reconhecimento de matrícula
- Extrair informações do cartão de visita de uma lista de contatos
- Conversão de documentos manuscritos em imagens eletrônicas
- Criando PDFs pesquisáveis
- Criar arquivos audíveis (texto para áudio)
Algumas das ferramentas de OCR de código aberto são Tesseract, OCRopus.
Neste artigo, vamos nos concentrar no Tesseract OCR. E para ler as imagens precisamos do OpenCV.
Instalação de Tesseract OCR:
Baixe o instalador mais recente para Windows 10 a partir de “https://github.com/UB-Mannheim/tesseract/wiki“. Execute o arquivo .exe uma vez que ele é baixado.
Observação: Não se esqueça de copiar o caminho de instalação do software de arquivo. Precisaremos dele mais tarde, pois precisamos adicionar o caminho do tesseract executável no código se o diretório de instalação for diferente do padrão.
o caminho típico de instalação em sistemas windows é C: Arquivos do programa.
Então, no meu caso, isto é “C: Archivos de programa Tesseract-OCRtesseract.exe“.
A seguir, para instalar o recipiente Python para Tesseract, abrir o prompt de comando e executar o comando “pip instalar pytesseract“.
OpenCV
OpenCV (Visão de computador de código aberto) é uma biblioteca de código aberto para aplicativos de processamento de imagens, aprendizado de máquina e visão computacional.
OpenCV-Python é a API Python para OpenCV.
Para instalar, abrir o prompt de comando e executar o comando “pip instalar opencv-python“.
Criar script de OCR de exemplo
1. Leia uma imagem de amostra
import cv2
Leia a imagem usando o método cv2.imread () y guárdela en una variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... "img".
img = cv2.imread("imagem.jpg")
Sim é necessário, redimensionar a imagem usando o método cv2.resize ()
img = cv2.resize(img, (400, 400))
Exibir a imagem usando o método cv2.imshow ()
cv2.imshow("Imagem", img)
Exibir a janela infinitamente (para evitar que o kernel caia)
cv2.waitKey(0)
Feche todas as janelas abertas
cv2.destroyAllWindows()
2. Conversão de imagem em cadeia
importação pytesseract
Defina o caminho tesseract no código
pytesseract.pytesseract.tesseract_cmd=r'C:Arquivos do programaTesseract-OCRtesseract.exe'
o seguinte erro ocorre se não definirmos o caminho.

Para converter uma imagem em uma string, usar pytesseract.image_to_string (img) e salvá-lo para uma variável “texto”
texto = pytesseract.image_to_string(img)
imprimir o resultado
imprimir(texto)
Código completo:
import cv2 import pytesseract pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe' img = cv2.imread("imagem.jpg") img = cv2.resize(img, (400, 450)) cv2.imshow("Imagem", img) texto = pytesseract.image_to_string(img) imprimir(texto) cv2.waitKey(0) cv2.destroyAllWindows()
A saída do código anterior:
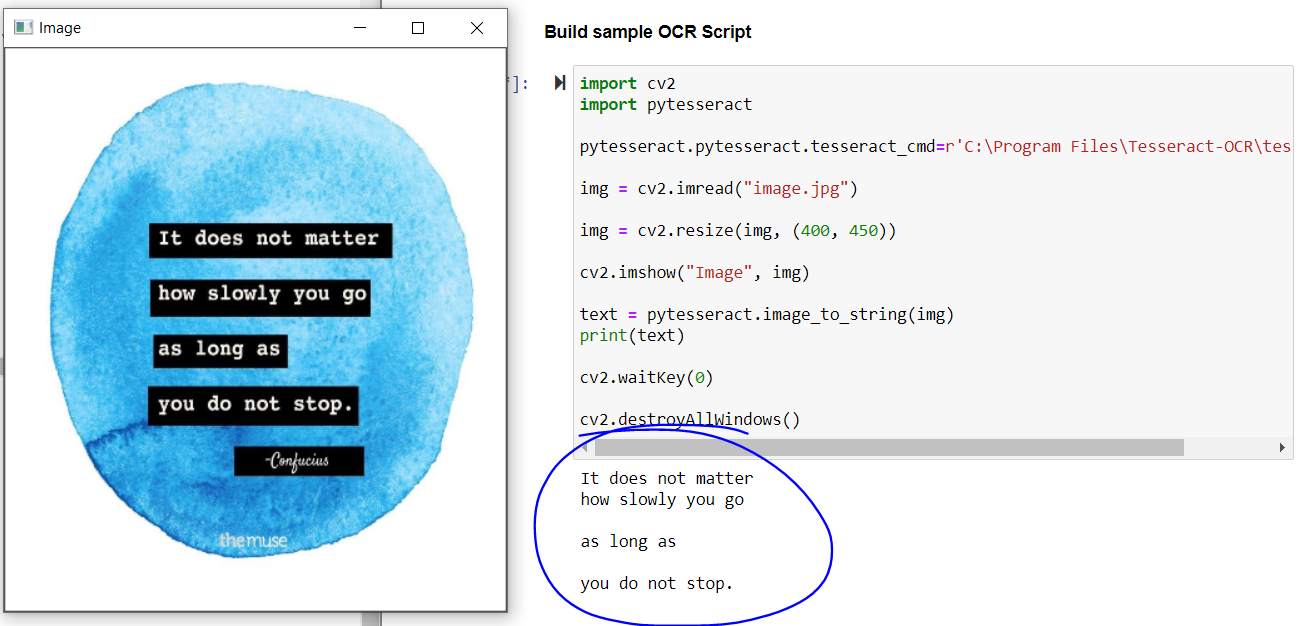
A saída do código anterior
Se olharmos para o resultado, a nomeação principal é extraída perfeitamente, mas você não tem o nome do filósofo eo texto na parte inferior da imagem.
Para extrair o texto com precisão e evitar a queda na precisão, devemos pré-processar a imagem. Eu encontrei este artigo (https://directiondatascience.com/pre-processing-in-ocr-fc231c6035a7) bem útil. Consulte-o para entender melhor as técnicas de pré-processamento.
Perfeito! Agora que temos o básico necessário, vamos dar uma olhada em alguns aplicativos de OCR simples.
1. Criação de nuvens de palavras em imagens de revisão
A nuvem de palavras é uma representação visual da frequência das palavras. Quanto maior a palavra aparece em uma nuvem de palavras, a palavra é mais comumente usada no texto.
Para isto, Eu tirei alguns instantâneos de avaliação da Amazon para o produto Apple iPad 8ª geração.
Imagem de amostra
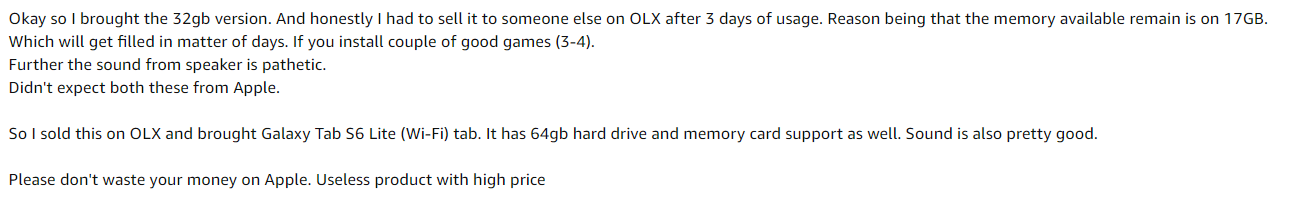
Passos:
- Crie uma lista de todas as imagens de revisão disponíveis
- Sim é necessário, exibir imagens usando o método cv2.imshow ()
- Leia texto de imagens usando pytesseract
- Crie uma estrutura de dados
- Pré-processe o texto: excluir caracteres especiais, parar palavras
- Construa nuvens de palavras positivas e negativas
Paso 1: cria uma lista de todas as imagens de revisão disponíveis
importar os folderPath = "Opiniões" myRevList = os.listdir(folderPath)
Paso 2: Sim é necessário, exibir imagens usando o método cv2.imshow ()
para imagem no myRevList:
img = cv2.imread(f '{folderPath}/{imagem}')
cv2.imshow("Imagem", img)
cv2.waitKey(0)
cv2.destroyAllWindows()
Paso 3: lê texto de imagens usando pytesseract
import cv2 import pytesseract pytesseract.pytesseract.tesseract_cmd=r'C:Program FilesTesseract-OCRtesseract.exe' corpus = [] para imagens no myRevList: img = cv2.imread(f '{folderPath}/{imagens}') se img é Nenhum: corpus.append("Não consegui ler a imagem.") outro: rev = pytesseract.image_to_string(img) corpus.append(rev) Lista(corpus) corpus
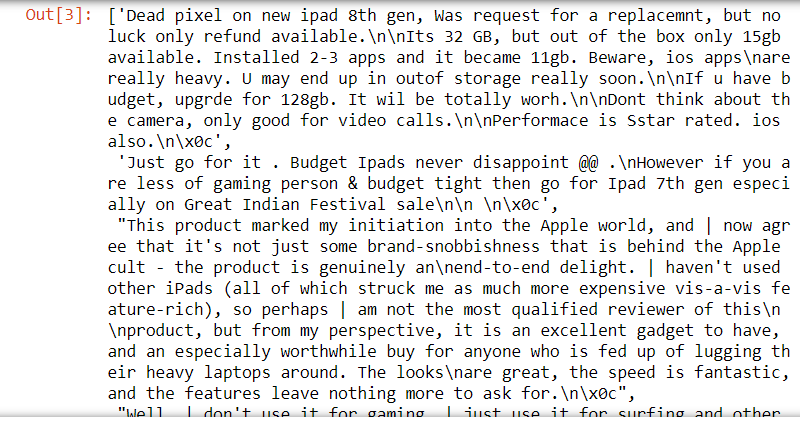
Paso 4: cria uma estrutura de dados
import pandas as pd
data = pd.DataFrame(Lista(corpus), colunas =['Revisão'])
dados

Paso 5: pré-processamento do texto: excluir caracteres especiais, palavras vazias
#removing special characters
import re
def clean(texto):
retorno re.sub('[^A-Za-z0-9" "]+', '', texto)
dados['Revisão Limpa'] = dados['Revisão'].Aplique(limpar)
dados

Removendo palavras vazias do 'Clean Review'’ e adicionando todas as palavras restantes a uma variável de lista “final_list”.
-
# removing stopwords import nltk from nltk.corpus import stopwords nltk.download("Punkt") from nltk import word_tokenize stop_words = stopwords.words('inglês') final_list = [] para coluna em dados[['Revisão Limpa']]: colunaSSÉbj = dados[coluna] all_rev = columnSeriesObj.values for i in range(len(all_rev)): tokens = word_tokenize(all_rev[eu]) por palavra em tokens: se a palavra.baixar() não em stop_words: final_list.append(palavra)
Paso 6: Construa nuvens de palavras positivas e negativas
Instale a biblioteca de nuvem de palavras com o comando “pip instalar wordcloud“.
Na língua inglesa, temos um conjunto predefinido de palavras positivas e negativas chamada Opinião Lexicons. Esses arquivos podem ser baixados a partir de Ligação ou diretamente de mim Repositório GitHub.
Uma vez que os arquivos são baixados, ler esses arquivos no código e criar uma lista de palavras positivas e negativas.
com aberto(r"opinião-léxico-inglês-palavras positivas.txt","r") como pos:
poswords = pos.read().dividir("n")
com aberto(r"opinião-léxico-inglês-palavras-tivas.txt","r") como neg:
negwords = neg.read().dividir("n")
Importando bibliotecas para gerar e exibir nuvens de palavras.
import matplotlib.pyplot as plt
from wordcloud import WordCloud
Nuvem de palavras positivas
# Choosing the only words which are present in poswords
pos_in_pos = " ".Junte([w para w em final_list se w em poswords])
wordcloud_pos = WordCloud(
background_color ="Preto",
largura=1800,
altura=1400
).gerar(pos_in_pos)
plt.imshow(wordcloud_pos)

A palavra "bom" é a palavra mais usada que chama a nossa atenção. Se olharmos para trás em avaliações, as pessoas escreveram críticas dizendo que o iPad tem uma boa tela, bom som, bom software e hardware.
Nuvem de palavras negativa
# Choosing the only words which are present in negwords
neg_in_neg = " ".Junte([w para w em final_list se w em negwords])
wordcloud_neg = WordCloud(
background_color ="Preto",
largura=1800,
altura=1400
).gerar(neg_in_neg)
plt.imshow(wordcloud_neg)

Palavras caras, preso, Espancado, Decepção se destacou na nuvem de palavras negativas. Se olharmos para o contexto da palavra presa, dados “Embora tenha apenas 3 GB de RAM, nunca fica preso”, que é uma coisa positiva sobre o dispositivo.
Portanto, é bom criar nuvens bigrama palavra / trigram para que você não perca o contexto.
2. Criar arquivos audíveis (texto para áudio)
gTTS é uma biblioteca Python com a API texto-a-fala do Google Translate.
Para instalar, executar o comando “pip instalar gtts"No prompt de comando.
Importar bibliotecas necessárias
import cv2
import pytesseract
from gtts import gTTS
import os
Definir o caminho tesseract
pytesseract.pytesseract.tesseract_cmd=r'C:Arquivos do programaTesseract-OCRtesseract.exe'
Leia a imagem usando cv2.imread () e tirar o texto da imagem usando pytesseract e salvá-lo em uma variável.
rev = cv2.imread("Comentários15.PNG")
# exibir a imagem usando cv2.imshow() método
# cv2.imshow("Imagem", rev)
# cv2.waitKey(0)
# cv2.destroyAllWindows()
# grab the text from image using pytesseract
txt = pytesseract.image_to_string(rev)
imprimir(Txt)
Defina o idioma e crie uma conversão de texto para áudio usando gTTS sem passar pelo texto, a língua
linguagem ="sobre" outObj = gTTS(text=txt, lang=linguagem, slow=False)
Salve o arquivo de áudio como “rev.mp3”
outObj.save("rev.mp3")
reproduzir o arquivo de áudio
os.system('rev.mp3')
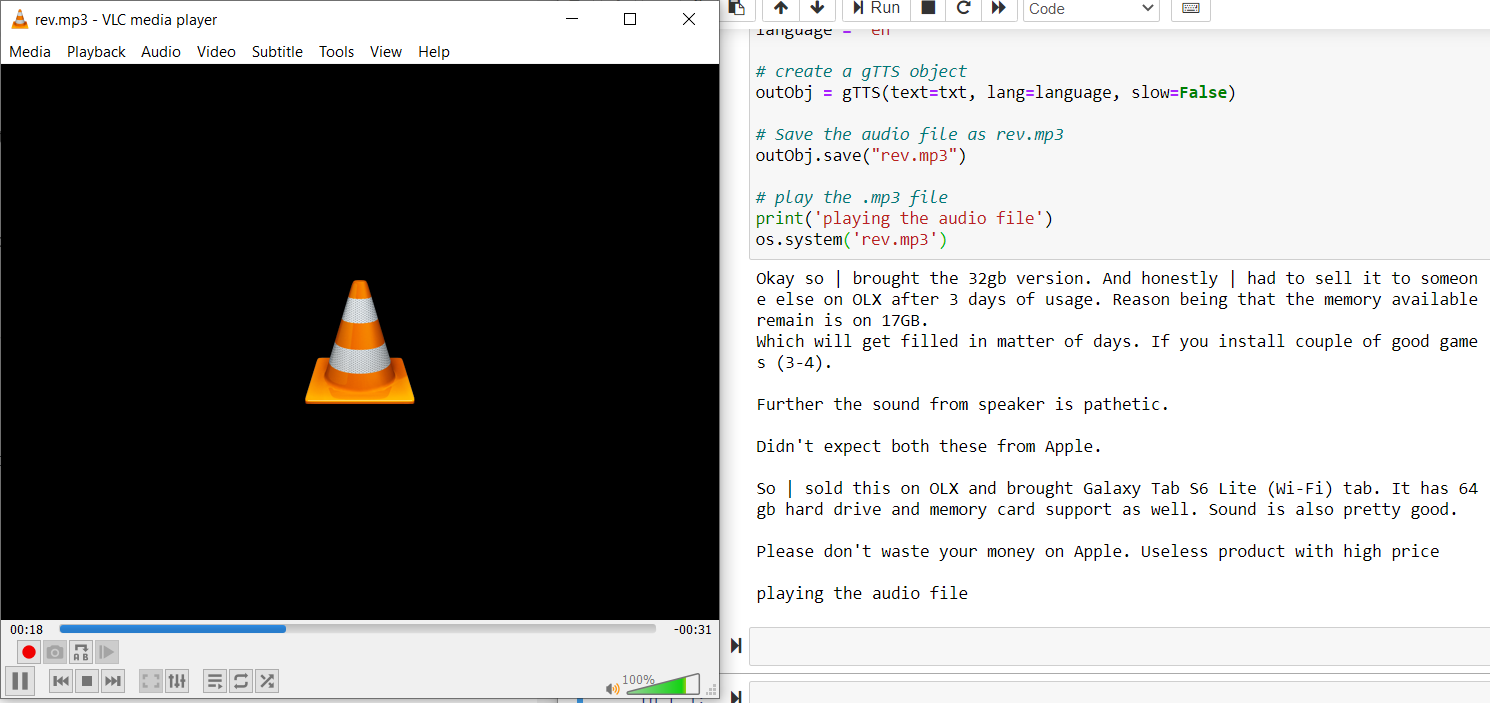
Código completo:
-
import cv2 import pytesseract from gtts import gTTS import os rev = cv2.imread("Comentários15.PNG") # cv2.imshow("Imagem", rev) # cv2.waitKey(0) # cv2.destroyAllWindows() txt = pytesseract.image_to_string(rev) imprimir(Txt) linguagem ="sobre" outObj = gTTS(text=txt, lang=linguagem, slow=False) outObj.save("rev.mp3") imprimir('reproduzindo o arquivo de áudio') os.system('rev.mp3')
Notas finais
No final deste artigo, entendemos o conceito de reconhecimento óptico de caracteres (OCR) e estamos familiarizados com a leitura de imagens com OpenCV e captura de texto de imagens com pytesseract. Vimos dois aplicativos OCR básicos: construir nuvens de palavras, crie arquivos audíveis convertendo texto em fala usando gTTS.
Referências:
Espero que este artigo seja informativo e, por favor, deixe-me saber se você tem alguma dúvida ou comentário relacionado a este artigo na seção de comentários. Boa aprendizagem 😊
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





