Este artigo foi publicado como parte do Data Science Blogathon.
Entenda o problema de overfitting em árvores de decisão e resolva-o reduzindo a complexidade e o custo mínimo usando Scikit-Learn em Python
A árvore de decisão é uma das ferramentas mais intuitivas e eficazes no kit de ferramentas de um cientista de dados.. Ele tem uma estrutura de árvore invertida que antes era usada apenas na análise de decisão, mas agora também é um algoritmo de aprendizado de máquina brilhante, especialmente quando temos um problema de classificação em nossas mãos.
Essas árvores de decisão são bem conhecidas por sua capacidade de capturar padrões nos dados.. Mas, excesso de qualquer coisa é prejudicial, verdade? As árvores de decisão são infames, pois podem se apegar demais aos dados nos quais são treinadas.
Portanto, nossa árvore dá resultados de implementação ruins porque não pode lidar com um novo conjunto de valores.
Mas não se preocupe! Como um mecânico habilidoso, ele tem chaves de todos os tamanhos disponíveis em sua caixa de ferramentas, um cientista de dados habilidoso também tem seu conjunto de técnicas para lidar com qualquer tipo de problema. E é isso que exploraremos neste artigo..
O papel da poda nas árvores de decisão
A poda é uma das técnicas usadas para superar nosso problema de overfitting. Poda, em seu sentido literal, é uma prática que envolve a remoção seletiva de certas partes de uma árvore (o planta), como ramos, brotos ou raízes, para melhorar a estrutura da árvore e promover um crescimento saudável. Isso é exatamente o que a poda também faz com nossas árvores de decisão. Torna-o versátil para que se possa adaptar se lhe dermos algum tipo de informação nova, resolvendo assim o problema de overfitting.
Reduza o tamanho de uma árvore de decisão, o que pode aumentar ligeiramente o erro de treinamento, mas diminui drasticamente o erro de teste, o que o torna mais adaptável.
Poda de custo e complexidade mínimos é um dos tipos de poda de árvore de decisão.
Este algoritmo é parametrizado por α (≥0) conhecido como o parâmetro de complexidade.
O parâmetro de complexidade é usado para definir a medida de complexidade de custo, Ruma(T) de uma dada árvore T: Ruma(T) = R (T) + uma | T |
Onde | T | é o número de nós terminais em T e R (T) é tradicionalmente definido como a taxa total de classificação incorreta dos nós terminais.
Em sua versão 0.22, Scikit-learn introduziu este parâmetro chamado ccp_alpha (sim! É curto para Remoção de complexidade de custo – Alfa) às árvores de decisão que podem ser usadas para fazer o mesmo.
Construindo a árvore de decisão em Python
Usaremos o conjunto de dados Iris para ajustar a árvore de decisão. Você pode baixar o conjunto de dados aqui.
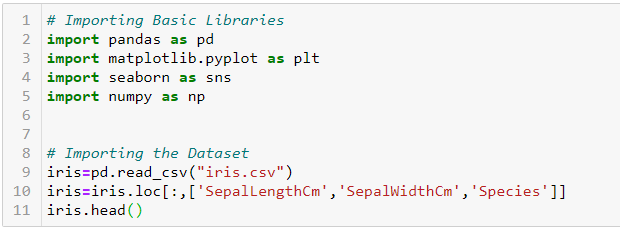
Primeiro, vamos importar as bibliotecas básicas necessárias e conjunto de dados:
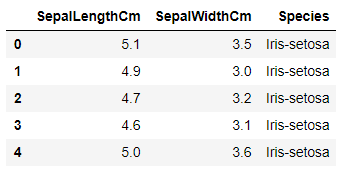
O conjunto de dados se parece com este:
Nosso objetivo é prever as espécies de uma flor com base no comprimento e largura de sua sépala.
Vamos dividir o conjunto de dados em duas partes: treinar e testar. Estamos fazendo isso para que possamos ver como nosso modelo funciona também em dados invisíveis. Nós vamos usar o train_test_split função de sklearn.model_selection dividir o conjunto de dados.

Agora, vamos ajustar uma árvore de decisão para a parte do trem e prever tanto no teste quanto no treinamento. Usaremos DecisionTreeClassifier a partir de sklearn.tree para este propósito.
Por padrão, a função de árvore de decisão não faz nenhuma poda e permite que a árvore cresça o máximo que puder. Obtemos uma pontuação de precisão de 0,95 e 0,63 no trem e na peça de teste, respectivamente, como é mostrado a seguir. Podemos dizer que nosso modelo está superdimensionado, quer dizer, memorizando a parte do trem, mas pode não funcionar tão bem na parte de teste.

Árvore de decisão no sklearn tem uma função chamada cost_complexity_pruning_path, que dá os alfas eficazes das subárvores durante a poda e também as impurezas correspondentes. Em outras palavras, podemos usar esses valores alfa para podar nossa árvore de decisão:
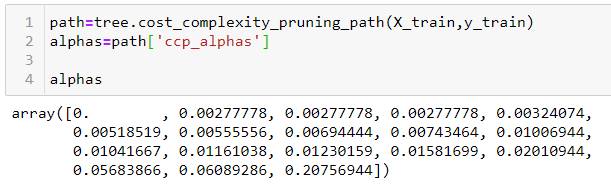
Vamos definir esses valores alfa e passá-los para ccp_alpha parâmetro do nosso DecisionTreeClassifier. Loopando sobre ele alfas matriz, encontraremos a precisão nas partes de treinamento e teste de nosso conjunto de dados.

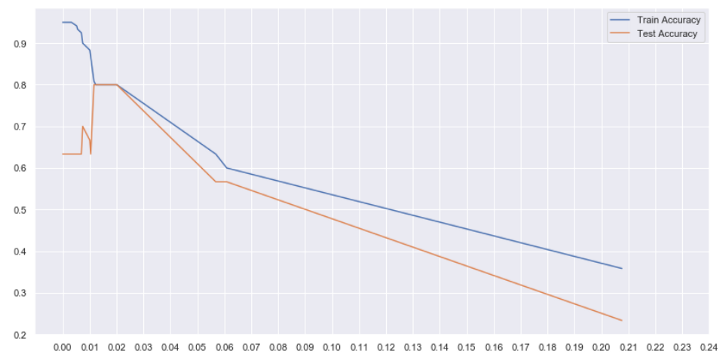
No gráfico acima, podemos ver que entre alfa = 0.01 e 0.02, nós obtemos a mais alta precisão de teste. Embora a precisão do nosso trem tenha diminuído para 0,8, nosso modelo agora é mais generalizado e funcionará melhor com dados invisíveis.