Este artigo foi publicado como parte do Data Science Blogathon
Introdução
Ola leitores!
O aprendizado profundo é usado em muitos aplicativos, como detecção de objeto, detecção de rosto, tarefas de processamento de linguagem natural e muito mais. Neste blog, vou construir um modelo que será usado para resolver Sudoku não resolvido a partir de uma imagem usando aprendizado profundo, vamos para bibliotecas como OpenCV e TensorFlow. Se você quiser saber mais sobre o OpenCV, verifique isso Ligação. Então vamos começar.
- Se você quiser saber sobre bibliotecas Python para processamento de imagens, então verifique isso Ligação.
- Para mais artigos, Clique aqui.

Imagem Fonte
O blog está dividido em três partes:
Papel 1: Modelo de classificação de dígitos
Vamos primeiro construir e treinar uma rede neural no conjunto de dados de imagem Char74k para dígitos. Este modelo ajudará a classificar os dígitos das imagens.
Papel 2: Leia e detecte o Sudoku a partir de uma imagem
Esta seção contém, identificando o quebra-cabeça a partir de uma imagem com a ajuda do OpenCV, classifique os dígitos no quebra-cabeça Sudoku detectado usando a Parte 1, finalmente obter os valores das células do Sudoku e armazená-los em uma matriz.
Papel 3: Resolvendo o quebra-cabeça
Vamos armazenar a matriz que obtivemos em Pat-2 como uma matriz e, finalmente, executaremos um loop de recursão para resolver o quebra-cabeça.
BIBLIOTECAS IMPORTADORAS
Vamos importar todas as bibliotecas necessárias usando os seguintes comandos:
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import os, random import cv2 from glob import glob import sklearn from sklearn.model_selection import train_test_split import tensorflow as tf from tensorflow import keras from tensorflow.keras.preprocessing.image import ImageDataGenerator from keras.preprocessing.image import ImageDataGenerator, load_img from keras.utils.np_utils import to_categorical from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Activation, Cair fora, Denso, Achatar, BatchNormalization, Conv2D, MaxPooling2D from tensorflow.keras.optimizers import RMSprop from tensorflow.keras import backend as K from tensorflow.keras.preprocessing import image from sklearn.metrics import accuracy_score, classification_report from pathlib import Path from PIL import Image
Papel 1: Modelo de classificação de dígitos
Nesta secção, vamos usar um modelo de classificação de dígitos.
CARREGANDO DADOS
Usaremos um conjunto de dados de imagem para classificar os números em uma imagem.. Os dados são especificados como recursos como imagens e tags como tags.
#Loading the data data = os.listdir("dígitos/dígitos" ) data_X = [] data_y = [] data_classes = len(dados) para eu no alcance (0,data_classes): data_list = os.listdir("dígitos/dígitos" +"/"+str(eu)) para j em data_list: pic = cv2.imread("dígitos/dígitos" +"/"+str(eu)+"/"+j) pic = cv2.resize(Pic,(32,32)) data_X.append(Pic) data_y.append(eu) se len(data_X) == len(data_y) : imprimir("Total de Dataponits = ",len(data_X)) # Labels and images data_X = np.array(data_X) data_y = np.array(data_y)

CONJUNTO DE DADOS SPLIT
Estamos dividindo o conjunto de dados em conjuntos de trens, testes e validação como fazemos em qualquer questão de aprendizado de máquina.
#Spliting the train validation and test sets
train_X, test_X, train_y, test_y = train_test_split(data_X,data_y,test_size = 0,05)
train_X, valid_X, train_y, valid_y = train_test_split(train_X,train_y,test_size = 0.2)
imprimir("Forma do conjunto de treinamento = ",train_X.shape)
imprimir("Forma do conjunto de validação = ",valid_X.shape)
imprimir("Forma do conjunto de teste = ",test_X.shape)

Procesamiento previo de las imágenes para la neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas..
Em uma etapa de pré-processamento, nós pré-processamos as características (imagens) escala de cinza, normalizando e aprimorando-os com equalização de histograma. Depois disso, convertê-los em matrizes NumPp e depois modificá-los e aumentar os dados.
def Prep(img): img = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY) #making image grayscale img = cv2.equalizeHist(img) #Histogram equalization to enhance contrast img = img/255 #normalizing return img train_X = np.array(Lista(mapa(Preparar, train_X))) test_X = np.array(Lista(mapa(Preparar, test_X))) valid_X= np.array(Lista(mapa(Preparar, valid_X))) #Reshaping the images train_X = train_X.reshape(train_X.shape[0], train_X.shape[1], train_X.shape[2],1) test_X = test_X.remodele(test_X.shape[0], test_X.shape[1], test_X.shape[2],1) valid_X = valid_X.remodele(valid_X.shape[0], valid_X.shape[1], valid_X.shape[2],1) #Augmentation datagen = ImageDataGenerator(width_shift_range=0,1, height_shift_range=0,1, zoom_range=0,2, shear_range=0,1, rotation_range=10) datagen.fit(train_X)
Uma codificação quente
Nesta secção, usaremos la codificación um-quente para etiquetar las clases.
train_y = to_categorical(train_y, data_classes) test_y = to_categorical(test_y, data_classes) valid_y = to_categorical(valid_y, data_classes)
CONSTRUCCIÓN DEL MODELO
Estamos utilizando una convolucional neuronal vermelhoRedes Neurais Convolucionais (CNN) são um tipo de arquitetura de rede neural projetada especialmente para processamento de dados com uma estrutura de grade, como fotos. Eles usam camadas de convolução para extrair recursos hierárquicos, o que os torna especialmente eficazes em tarefas de reconhecimento e classificação de padrões. Graças à sua capacidade de aprender com grandes volumes de dados, As CNNs revolucionaram campos como a visão computacional.. para la construcción de modelos. Consta de los siguientes pasos:
#Creating a Neural Network
model = Sequential()
model.add((Conv2D(60,(5,5),input_shape =(32, 32, 1) ,preenchimento = 'Mesmo' ,ativação = 'reler')))
model.add((Conv2D(60, (5,5),preenchimento ="mesmo",ativação = 'reler')))
model.add(MaxPooling2D(pool_size =(2,2)))
#model.add(Cair fora(0.25))
model.add((Conv2D(30, (3,3),preenchimento ="mesmo", ativação = 'reler')))
model.add((Conv2D(30, (3,3), preenchimento ="mesmo", ativação = 'reler')))
model.add(MaxPooling2D(pool_size =(2,2), passos=(2,2)))
model.add(Cair fora(0.5))
model.add(Achatar())
model.add(Denso(500,ativação = 'reler'))
model.add(Cair fora(0.5))
model.add(Denso(10, ativação = 'softmax'))
model.summary()
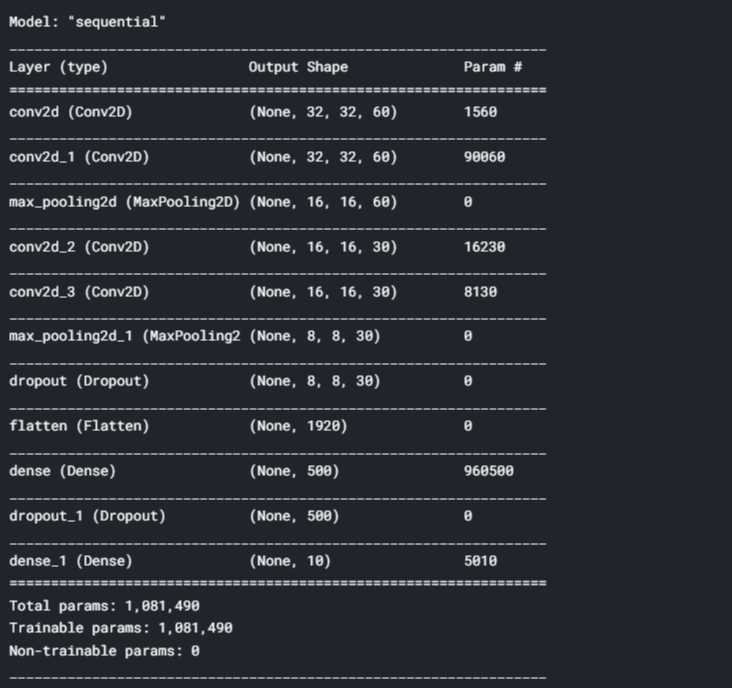
Nesta etapa, compilaremos el modelo y probaremos el modelo en el conjunto de prueba como se muestra a continuación:
#Compiling the model optimizer = RMSprop(lr=0,001, rho=0,9, epsilon = 1e-08, decadência=0,0) model.compile(otimizador=otimizador,perda ="categorical_crossentropy",metrics =['precisão']) #Fit the model history = model.fit(datagen.flow(train_X, train_y, batch_size = 32), épocas = 30, validação_data = (valid_X, valid_y), verboso = 2, steps_per_epoch= 200) # Testing the model on the test set score = model.evaluate(test_X, test_y, verbose = 0) imprimir('Pontuação do teste=",pontuação[0]) imprimir("Precisão do teste =', pontuação[1])

Papel 2: Leia e detecte o Sudoku a partir de uma imagem
LEER EL ROMPECABEZAS SUDOKU
Leer un Sudoku usando OpenCv usando el siguiente código:
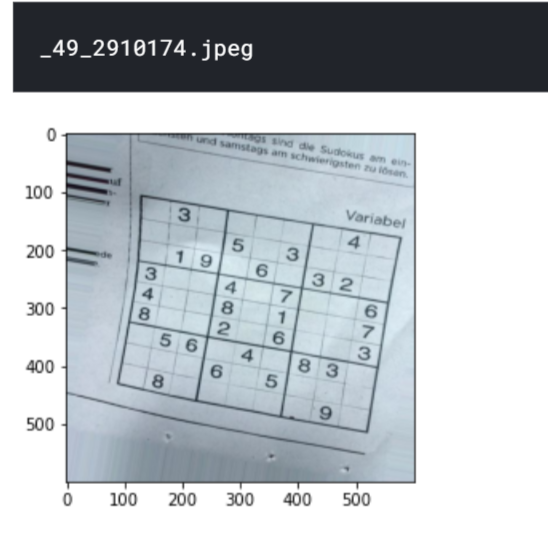
# Randomly select an image from the dataset
folder="sudoku-box-detecção/ago"
a=random.choice(os.listdir(pasta))
imprimir(uma)
sudoku_a = cv2.imread(pasta+'/'+a)
plt.figure()
plt.imshow(sudoku_a)
plt.show()
Preprocese la imagen para un análisis más detallado utilizando el siguiente código;
#Preprocessing image to be read sudoku_a = cv2.resize(sudoku_a, (450,450)) # função para escala de cinza, blur and change the receptive threshold of image def preprocess(imagem): cinza = cv2.cvtColor(imagem, cv2.COLOR_BGR2GRAY) borrão = cv2. GaussianBlur(cinza, (3,3),6) #desfoque = cv2.bilateralFilter(cinza,9,75,75) threshold_img = cv2.adaptiveThreshold(borrão,255,1,1,11,2) return threshold_img threshold = preprocess(sudoku_a) #let's look at what we have got plt.figure() plt.imshow(limiar) plt.show()
DETECTANDO CONTORNO
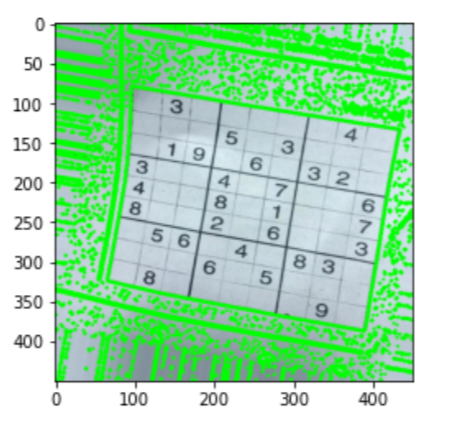
Nesta secção, vamos a detectar el contorno. Seguimos detectando el contorno más grande de la imagen.
# Finding the outline of the sudoku puzzle in the image contour_1 = sudoku_a.copy() contour_2 = sudoku_a.copy() contorno, hierarquia = cv2.findContours(limiar,cv2. RETR_EXTERNAL,cv2. CHAIN_APPROX_SIMPLE) cv2.drawContours(contour_1, contorno,-1,(0,255,0),3) #let's see what we got plt.figure() plt.imshow(contour_1) plt.show()
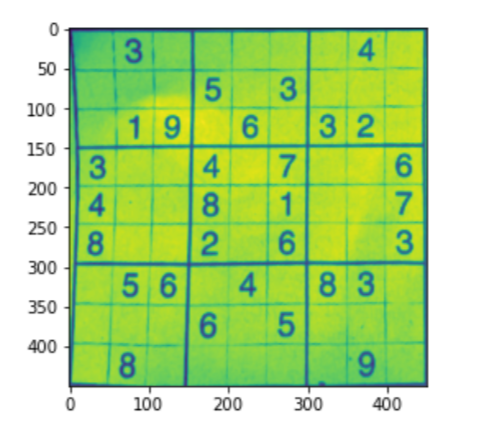
El siguiente código se usa para obtener el Sudoku recortado y bien alineado al remodelarlo.
def main_outline(contorno):
maior = np.array([])
max_area = 0
para i em contorno:
área = cv2.contornoArea(eu)
se área >50:
peri = cv2.arcLength(eu, Verdade)
aproximadamente = cv2.aproxPolyDP(eu , 0.02* peri, Verdade)
se área > max_area e len(aprox.) ==4:
biggest = approx
max_area = area
return biggest ,max_area
def reframe(Pontos):
pontos = pontos.remodelar((4, 2))
points_new = np.zeros((4,1,2),dtype = np.int32)
adicionar = pontos.soma(1)
points_new[0] = pontos[np.argmin(adicionar)]
points_new[3] = pontos[np.argmax(adicionar)]
diff = np.diff(Pontos, eixo =1)
points_new[1] = pontos[np.argmin(diferença)]
points_new[2] = pontos[np.argmax(diferença)]
return points_new
def splitcells(img):
linhas = np.vsplit(img,9)
caixas = []
para r em linhas:
cols = np.hsplit(r,9)
para caixa em cols:
boxes.append(caixa)
return boxes
black_img = np.zeros((450,450,3), por exemplo, uint8)
maior, maxArea = main_outline(contorno)
se maior.tamanho != 0:
maior = reenquadrado(maior)
cv2.drawContours(contour_2, maior,-1, (0,255,0),10)
pts1 = np.float32(maior)
pts2 = np.float32([[0,0],[450,0],[0,450],[450,450]])
matriz = cv2.getPerspectiveTransform(pts1,pts2)
imagewrap = cv2.warpPerspective(sudoku_a,matriz,(450,450))
imagewrap =cv2.cvtColor(imagewrap, cv2.COLOR_BGR2GRAY)
plt.figure()
plt.imshow(imagewrap)
plt.show()
# Importing puzzle to be solved puzzle = cv2.imread("su-puzzle/su.jpg") #let's see what we got plt.figure() plt.imshow(enigma) plt.show()
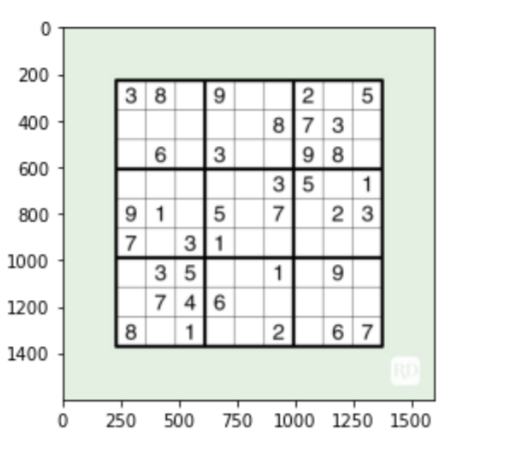
# Finding the outline of the sudoku puzzle in the image
su_contour_1= su_puzzle.copy()
su_contour_2= sudoku_a.copy()
su_contour, hierarquia = cv2.findContours(su_puzzle,cv2. RETR_EXTERNAL,cv2. CHAIN_APPROX_SIMPLE)
cv2.drawContours(su_contour_1, su_contour,-1,(0,255,0),3)
black_img = np.zeros((450,450,3), por exemplo, uint8)
su_biggest, su_maxArea = main_outline(su_contour)
se su_biggest.size != 0:
su_biggest = reenquadrado(su_biggest)
cv2.drawContours(su_contour_2 su_biggest,-1, (0,255,0),10)
su_pts1 = np.float32(su_biggest)
su_pts2 = np.float32([[0,0],[450,0],[0,450],[450,450]])
su_matrix = cv2.getPerspectiveTransform(su_pts1, su_pts2)
su_imagewrap = cv2.warpPerspective(enigma,su_matrix,(450,450))
su_imagewrap = cv2.cvtColor(su_imagewrap, cv2.COLOR_BGR2GRAY)
plt.figure()
plt.imshow(su_imagewrap)
plt.show()
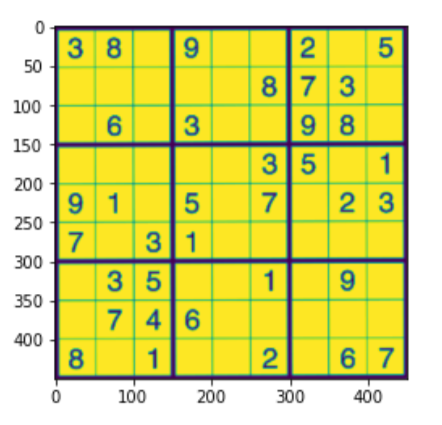
DIVIDIR AS CÉLULAS E CLASSIFICAR OS DÍGITOS
Nesta secção, vamos dividir as células e classificar os dígitos.
- Primeiro divida o Sudoku em 81 células com dígitos vazios ou espaços
- Recortando as células
- Use o modelo para classificar os dígitos nas células para que as células vazias sejam classificadas como zero
- Finalmente, detectar a saída em uma matriz de 81 dígitos.
sudoku_cell = splitcells(su_imagewrap)
#Let's have alook at the last cell
plt.figure()
plt.imshow(sudoku_cell[58])
plt.show()
def CropCell(células):
Cells_croped = []
para imagem em células:
img = np.array(imagem)
img = img[4:46, 6:46]
img = Imagem.fromarray(img)
Cells_croped.append(img)
return Cells_croped
sudoku_cell_croped= CropCell(sudoku_cell)
#Let's have alook at the last cell
plt.figure()
plt.imshow(sudoku_cell_croped[58])
plt.show()
Papel 3: RESOLVER EL SODOKU
En esta sección vamos a realizar das operaciones:
- Remodelando la matriz en una matriz de 9 x 9
- Resolver la matriz usando recursividad
# Reshaping the grid to a 9x9 matrix
grid = np.reshape(rede,(9,9))
rede
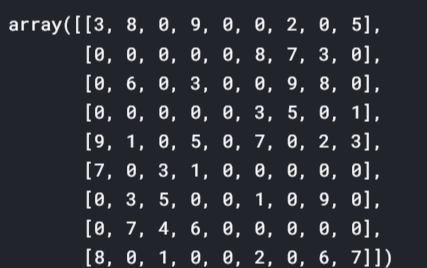
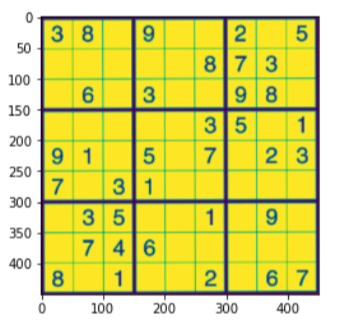
#For compairing
plt.figure()
plt.imshow(su_imagewrap)
plt.show()
Verifique el siguiente código para resolver aún más el sudoku:
def next_box(quiz):
para linha no intervalo(9):
para col no intervalo(9):
se quiz[fileira][col] == 0:
Retorna (fileira, col)
return False
#Function to fill in the possible values by evaluating rows collumns and smaller cells
def possible (quiz,fileira, col, n):
#global quiz
for i in range (0,9):
se quiz[fileira][eu] == n e linha != i:
return False
for i in range (0,9):
se quiz[eu][col] == n e col != i:
return False
row0 = (fileira)//3
col0 = (col)//3
para eu no alcance(linha0 *3, linha0 *3 + 3):
para j no intervalo(col0 *3, col0 *3 + 3):
se quiz[eu][j]==n e (eu,j) != (fileira, col):
return False
return True
#Recursion function to loop over untill a valid answer is found.
def resolver(quiz):
val = next_box(quiz)
se val é Falso:
retornar verdadeiro
outro:
fileira, col = val
for n in range(1,10): #n is the possible solution
if possible(quiz,fileira, col, n):
quiz[fileira][col]=n
if solve(quiz):
return True
else:
quiz[fileira][col]=0
return
def Solved(quiz):
para linha no intervalo(9):
se linha % 3 == 0 e linha != 0:
imprimir("....................")
para col no intervalo(9):
se col % 3 == 0 e col != 0:
imprimir("|", fim =" ")
se col == 8:
imprimir(quiz[fileira][col])
outro:
imprimir(str(quiz[fileira][col]) + " ", fim ="")
resolver(rede)

Verifique el siguiente código para obtener el resultado final:
se resolver(rede):
Resolvido(rede)
outro:
imprimir("Solução não existe. Dígitos de leitura incorreta do modelo.")
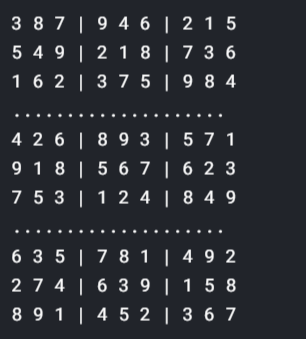
Viva!! Ele terminado com la resoluçãoo "resolução" refere-se à capacidade de tomar decisões firmes e atingir metas estabelecidas. Em contextos pessoais e profissionais, Envolve a definição de metas claras e o desenvolvimento de um plano de ação para alcançá-las. A resolução é fundamental para o crescimento pessoal e o sucesso em várias áreas da vida, pois permite superar obstáculos e manter o foco no que realmente importa.... de sudoku mediante el aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde.... Se você quiser mais informações, veja os links abaixo:
https://www.youtube.com/watch?v=G_UYXzGuqvM
https://www.kaggle.com/yashchoudhary/deep-sudoku-solver-multiple-approaches
https://www.youtube.com/watch?v = QR66rMS_ZfA
Notas finais
Então, neste artigo, tivemos uma discussão detalhada sobre Resolva Sudoku usando aprendizado profundo. Espero que você aprenda algo com este blog e o ajude no futuro. Obrigado pela leitura e sua paciência. Boa sorte!
Você pode verificar meus artigos aqui: Artigos
Identificação de e-mail: [e-mail protegido]
Conecte-se comigo no LinkedIn: LinkedIn.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





