Para cada recrutamento, empresas veiculam anúncios online, referências e verificá-las manualmente.
As empresas costumam enviar milhares de currículos para cada publicação.
Quando as empresas coletam currículos por meio de anúncios online, classifique-os de acordo com seus requisitos.
Após a coleta de currículos, empresas fecham anúncios e portais de aplicativos online.
Mais tarde, enviar os currículos coletados para a equipe de recrutamento.
Torna-se muito difícil para as equipes de contratação ler o currículo e selecioná-lo com base na exigência, não há problema se houver um ou dois currículos, mas é muito difícil revisar os currículos de 1000 e selecione o melhor.
Para resolver este problema, Hoje, neste artigo, vamos ler e revisar o currículo usando aprendizado de máquina com Python para que possamos completar os dias de trabalho em alguns minutos.
2. O que é avaliação de curriculum vitae?
Escolher as pessoas certas para o trabalho é a maior responsabilidade de todas as empresas, pois escolher o grupo certo de pessoas pode acelerar o crescimento dos negócios exponencialmente.
Vamos analisar aqui um exemplo de empresa deste tipo, o que conhecemos como departamento de TI. Sabemos que o departamento de TI não está acompanhando os mercados em crescimento.
Devido a muitos grandes projetos com grandes empresas, sua equipe não tem tempo para ler currículos e escolher o melhor currículo com base em suas necessidades.
Para resolver esses tipos de problemas, a empresa sempre escolhe um terceiro cujo trabalho é fazer o currículo de acordo com a exigência. Essas empresas são conhecidas como Organização de Serviços de Contratação. Esta é a tela de resumo de informações.
O trabalho de selecionar os melhores talentos, atribuições, concursos de codificação online, entre muitos outros, também conhecido como tela de retomada.
Por falta de tempo, grandes empresas não têm tempo suficiente para abrir currículos, então eles têm que recorrer à ajuda de qualquer outra empresa. Então, eles têm que pagar dinheiro. Que é um problema muito sério.
Para resolver este problema, a empresa deseja iniciar o trabalho da tela de currículo por conta própria, usando um algoritmo de aprendizado de máquina.
3. Retomar a triagem usando aprendizado de máquina
Nesta secção, veremos a implementação passo a passo da triagem de currículo usando python.
3.1 Dados usados
Temos dados publicamente disponíveis do Kaggle. Você pode baixar os dados usando o seguinte link.
https://www.kaggle.com/gauravduttakiit/resume-dataset
3.2 Análise exploratória de dados
Vamos dar uma olhada rápida nos dados que temos.
resumeDataSet.head()

Existem apenas duas colunas que temos nos dados. Abaixo está a definição de cada coluna.
Categoria: Tipo de trabalho para o qual o curriculum vitae foi adaptado.
Retomar: CV do candidato
resumeDataSet.shape
Produção:
(962, 2)
Existem 962 observações que temos nos dados. Cada observação representa os detalhes completos de cada candidato, pelo que temos 962 currículos para seleção.
Vamos ver quais categorias diferentes temos nos dados.
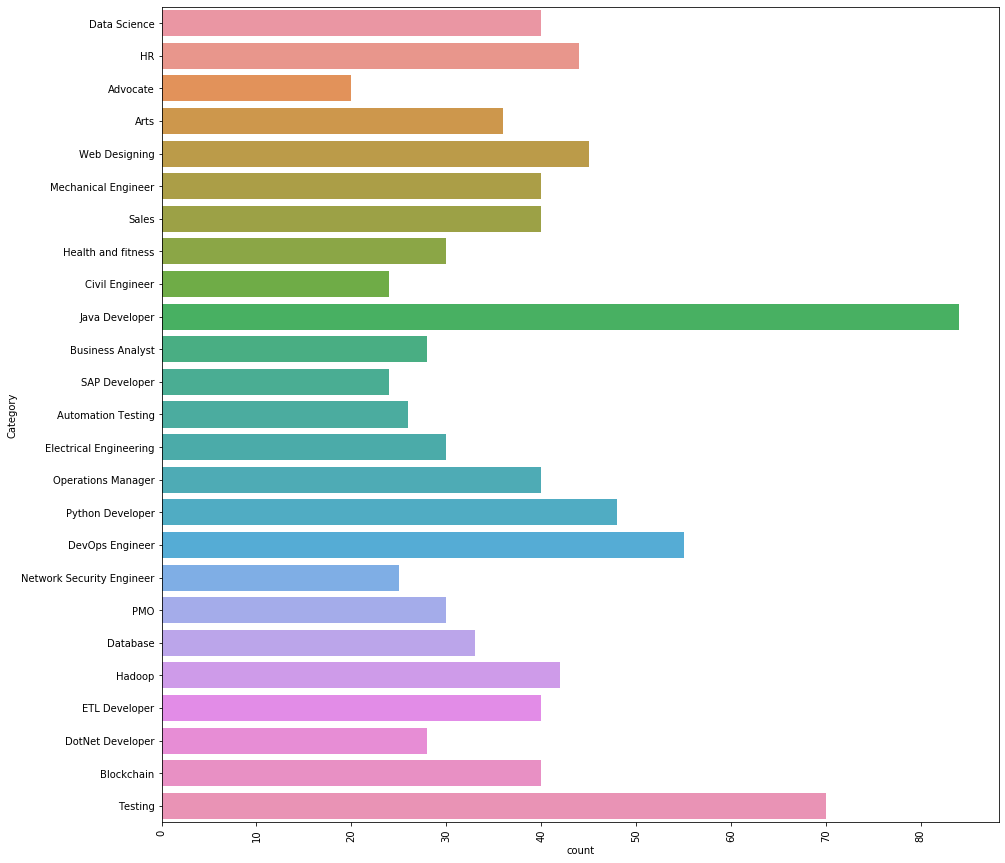
Existem 25 diferentes categorias que temos nos dados. As 3 As principais categorias de trabalho que temos nos dados são as seguintes.
Desenvolvedor de Java, Testing y DevOps Engineer.
Em vez de contagem ou frequência, Também podemos visualizar a distribuição das categorias de trabalho em porcentagem conforme mostrado abaixo:
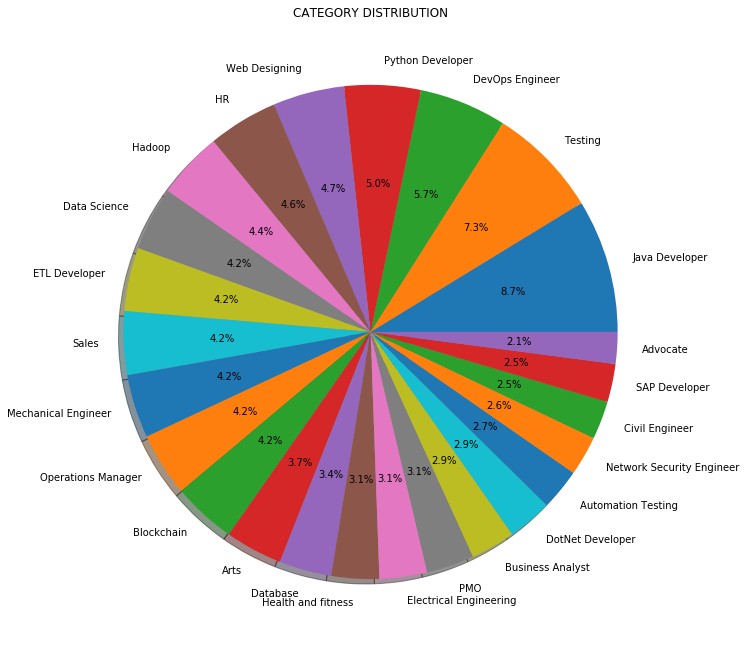
3.3 Pré-processamento de dados
Paso 1: Limpar coluna ‘Retomar’
Nesta etapa, removemos qualquer informação desnecessária de currículos, como URL, hashtags e caracteres especiais.
def cleanResume(resumeText):
resumeText = re.sub('httpS + s *', '', resumeText) # remover URLs
resumeText = re.sub('RT|cc ', '', resumeText) # remover RT e cc
resumeText = re.sub('# S +', '', resumeText) # remover hashtags
resumeText = re.sub('@ S +', '', resumeText) # remover menções
resumeText = re.sub('[%s]' % re.escape("""!"#$%&'()*+,-./:;<=>[e-mail protegido][]^ _`{|}~"""), '', resumeText) # remover pontuações
resumeText = re.sub(r '[^ x00-x7f]',r '', resumeText)
resumeText = re.sub('s +', '', resumeText) # remover espaços em branco extras
retornar resumeText
resumeDataSet['clean_resume'] = resumeDataSet.Resume.apply(lambda x: cleanResume(x))
Paso 2: 'Codificação de categoria’
Agora, iremos codificar a coluna ‘Categoria’ usando LabelEncoding. Embora a coluna ‘Categoria’ são dados ‘nominais’, estamos usando LabelEncong porque a coluna ‘Categoria’ é a nossa coluna 'alvo'. Al realizar LabelEncoding, cada categoria se tornará uma classe e vamos criar um modelo de classificação multiclasse.
var_mod = ['Categoria']
le = LabelEncoder()
para i em var_mod:
resumeDataSet[eu] = le.fit_transform(resumeDataSet[eu])
Paso 3: coluna de pré-processamento 'clean_resume’
Aqui iremos pré-processar e converter a coluna ‘clean_resume’ em vetores. Hay muchas formas de hacerlo, como ‘Bolsa de palabras’, ‘Tf-Idf’, ‘Word2Vec’ y una combinación de estos métodos.
Usaremos el método ‘Tf-Idf’ para obtener los vectores en este enfoque.
requiredText = resumeDataSet['clean_resume'].values requiredTarget = resumeDataSet['Categoria'].values word_vectorizer = TfidfVectorizer( sublinear_tf=True, stop_words="english", max_features=1500) word_vectorizer.fit(requiredText) WordFeatures = word_vectorizer.transform(requiredText)
Temos 'WordFeatures’ como vetores e 'requiredTarget’ e almeje após esta etapa.
3.4 Construção de maquete
Usaremos o método ‘One vs Rest’ com 'KNeighboursClassifier’ para construir este modelo de classificação multiclasse.
Usaremos 80% de datos para TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina.... e 20% dados para validação. Vamos dividir os dados agora em treinamento e conjunto de teste.
X_train,X_test,y_train,y_test = train_test_split(WordFeatures,requiredTarget,random_state = 0, test_size = 0.2) imprimir(X_train.shape) imprimir(X_test.shape)
Produção:
(769, 1500) (193, 1500)
Como agora temos dados de teste e treinamento, vamos construir o modelo.
clf = OneVsRestClassifier(KNeighboursClassifier())
clf.fit(X_train, y_train)
prediction = clf.predict(X_test)
3.5 Resultados
Veamos los resultados que tenemos.
imprimir('Accuracy of KNeighbors Classifier on training set: {:.2f}'.formato(clf.score(X_train, y_train)))
imprimir('Precisão do classificador KNeighbors no conjunto de teste: {:.2f}'.formato(clf.score(X_test, y_test)))
Produção:
Precisão do classificador KNeighbors no conjunto de treinamento: 0.99 Precisão do classificador KNeighbors no conjunto de teste: 0.99
Podemos ver que os resultados são incríveis. Podemos classificar cada categoria de um determinado currículo com um 99% precisão.
Também podemos verificar o relatório de classificação detalhado para cada classe ou categoria.
imprimir(metrics.classification_report(y_test, predição))
Produção:
suporte para recordação de precisão f1-score
0 1.00 1.00 1.00 3
1 1.00 1.00 1.00 3
2 1.00 0.80 0.89 5
3 1.00 1.00 1.00 9
4 1.00 1.00 1.00 6
5 0.83 1.00 0.91 5
6 1.00 1.00 1.00 9
7 1.00 1.00 1.00 7
8 1.00 0.91 0.95 11
9 1.00 1.00 1.00 9
10 1.00 1.00 1.00 8
11 0.90 1.00 0.95 9
12 1.00 1.00 1.00 5
13 1.00 1.00 1.00 9
14 1.00 1.00 1.00 7
15 1.00 1.00 1.00 19
16 1.00 1.00 1.00 3
17 1.00 1.00 1.00 4
18 1.00 1.00 1.00 5
19 1.00 1.00 1.00 6
20 1.00 1.00 1.00 11
21 1.00 1.00 1.00 4
22 1.00 1.00 1.00 13
23 1.00 1.00 1.00 15
24 1.00 1.00 1.00 8
precisão 0.99 193
macro avg 0.99 0.99 0.99 193
média ponderada 0.99 0.99 0.99 193
Onde, 0, 1, 2…. são as categorias de trabalho. Pegamos as tags reais do codificador de tag que usamos.
as classes_
Produção:
['Advogado', 'Artes', 'Teste de Automação', 'Blockchain','Analista de negócios', 'Engenheiro civil', 'Ciência de Dados', 'Base de dados','DevOps Engineer', 'DotNet Developer', 'Desenvolvedor ETL','Engenharia elétrica', 'RH', 'Hadoop', 'Saúde e fitness','Desenvolvedor de Java', 'Engenheiro mecânico','Engenheiro de Segurança de Rede', 'Gerente de Operações', 'PMO','Desenvolvedor Python', 'SAP Developer', 'Vendas', 'Testando','Web Designing']
Aqui ‘Advogado’ É a aula 0, ‘Artes’ É a aula 1, e assim por diante …
4. Código
Aquí puedes ver la implementación completa….
#Loading Libraries import warnings warnings.filterwarnings('ignorar') import numpy as np import pandas as pd import matplotlib.pyplot as plt import seaborn as sns from matplotlib.gridspec import GridSpec import re from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from scipy.sparse import hstack from sklearn.multiclass import OneVsRestClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn import metrics
#Loading Data resumeDataSet = pd.read_csv('../input/ResumeScreeningDataSet.csv' ,codificação = 'utf-8')
#EDA plt.figure(figsize =(15,15)) plt.xticks(rotação=90) sns.countplot(y ="Categoria", data=resumeDataSet) plt.savefig('../output/jobcategory_details.png') #Pie-chart targetCounts = resumeDataSet['Categoria'].valor_contas().reset_index()['Categoria'] targetLabels = resumeDataSet['Categoria'].valor_contas().reset_index()['índice'] # Make square figures and axes plt.figure(1, figsize =(25,25)) the_grid = GridSpec(2, 2) plt.subplot(the_grid[0, 1], aspect=1, título ="CATEGORY DISTRIBUTION") source_pie = plt.pie(targetCounts, labels=targetLabels, autopct ="%1.1f %%", shadow = True, ) plt.savefig('../output/category_dist.png')
#Data Preprocessing def cleanResume(resumeText): resumeText = re.sub('httpS + s *', '', resumeText) # remover URLs resumeText = re.sub('RT|cc ', '', resumeText) # remover RT e cc resumeText = re.sub('# S +', '', resumeText) # remover hashtags resumeText = re.sub('@ S +', '', resumeText) # remover menções resumeText = re.sub('[%s]' % re.escape("""!"#$%&'()*+,-./:;<=>[e-mail protegido][]^ _`{|}~"""), '', resumeText) # remover pontuações resumeText = re.sub(r '[^ x00-x7f]',r '', resumeText) resumeText = re.sub('s +', '', resumeText) # remover espaços em branco extras retornar resumeText resumeDataSet['clean_resume'] = resumeDataSet.Resume.apply(lambda x: cleanResume(x)) var_mod = ['Categoria'] le = LabelEncoder() para i em var_mod: resumeDataSet[eu] = le.fit_transform(resumeDataSet[eu]) requiredText = resumeDataSet['clean_resume'].values requiredTarget = resumeDataSet['Categoria'].values word_vectorizer = TfidfVectorizer( sublinear_tf=True, stop_words="english", max_features=1500) word_vectorizer.fit(requiredText) WordFeatures = word_vectorizer.transform(requiredText)
#Model Building X_train,X_test,y_train,y_test = train_test_split(WordFeatures,requiredTarget,random_state = 0, test_size = 0.2) imprimir(X_train.shape) imprimir(X_test.shape) clf = OneVsRestClassifier(KNeighboursClassifier()) clf.fit(X_train, y_train) prediction = clf.predict(X_test)
#Results print('Accuracy of KNeighbors Classifier on training set: {:.2f}'.formato(clf.score(X_train, y_train))) imprimir('Precisão do classificador KNeighbors no conjunto de teste: {:.2f}'.formato(clf.score(X_test, y_test))) imprimir("n Relatório de classificação para o classificador% s:n% sn" % (clf, metrics.classification_report(y_test, predição)))
5. conclusão
Neste artigo, Aprendemos como o aprendizado de máquina e o processamento de linguagem natural podem ser aplicados para melhorar nossas vidas diárias por meio do exemplo de detecção de currículo. Acabamos de resolver quase 1000 retoma em alguns minutos em suas respectivas categorias com um 99% precisão.
Entre em contato na seção de comentários se tiver alguma dúvida.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





