Este artigo foi publicado como parte do Data Science Blogathon
Um sistema de recomendação é uma das principais aplicações da ciência de dados. Cada empresa de consumo de Internet requer um sistema de recomendação como o Netflix, Youtube, um serviço de notícias, etc. O que você deseja mostrar em uma ampla variedade de artigos é um sistema de recomendação.

Tabela de conteúdo
- Introdução a um sistema de recomendação
- Tipos de sistema de recomendação
- Sistema de recomendação de livro
- Filtragem baseada em conteúdo
- Filtragem colaborativa
- Filtragem híbrida
- Sistema de recomendações práticas
- Descrição do conjunto de dados
- Dados de pré-processamento
- Executar EDA
- Agrupamento
- Previsões
- Notas finais
O que realmente é o sistema de recomendação?
Um mecanismo de recomendação é uma aula de aprendizado de máquina que oferece sugestões relevantes para o cliente. Antes do sistema de recomendação, a maior tendência de comprar era aceitar sugestões de amigos. Mas agora o Google sabe quais notícias vai ler, O Youtube sabe que tipo de vídeo você verá com base no seu histórico de pesquisa, ver histórico ou histórico de compras.
Um sistema de recomendação ajuda uma organização a construir clientes fiéis e a construir confiança nos produtos e serviços desejados para aqueles que visitam seu site.. O sistema de recomendação atual é tão poderoso que também pode lidar com o novo cliente que visitou o site pela primeira vez.. Eles recomendam produtos que são tendências ou altamente avaliados e também podem recomendar produtos que trazem o máximo de benefício para a empresa.
Tipos de sistema de recomendação
Um sistema de recomendação geralmente é construído usando 3 técnicas de filtragem baseada em conteúdo, filtragem colaborativa e uma combinação de ambos.
1) Filtragem baseada em conteúdo
O algoritmo recomenda um produto semelhante aos usados como olhares. Em palavras simples, neste algoritmo, tentamos encontrar um elemento que se pareça. Por exemplo, uma pessoa gosta de ver fotos de Sachin Tendulkar, então você também pode gostar de ver fotos de Ricky Ponting porque os dois vídeos têm tags e categorias semelhantes.
Só que parece semelhante entre o conteúdo e não se concentra mais na pessoa que está vendo isso. Recomende apenas o produto com a pontuação mais alta com base nas preferências anteriores.
2) Filtragem baseada em colaboração
Os sistemas de recomendação de filtragem baseados em colaboração são baseados em interações anteriores de usuários e elementos de destino. Em palavras simples, Tentamos encontrar clientes semelhantes e oferecer produtos com base no que eles escolheram sua aparência. Vamos entender com um exemplo. X e Y são dois usuários semelhantes e o usuário X assistiu aos filmes A, Por C. E o usuário Y assistiu a filmes B, C y D, então recomendaremos um filme para o usuário Y e um filme D para o usuário X.
O YouTube mudou seu sistema de recomendação de uma técnica de filtragem baseada em conteúdo para uma baseada na colaboração.. Se você já experimentou, também há vídeos que não têm nada a ver com sua história, mas também o recomenda porque outra pessoa semelhante a você o viu.
3) Método de filtragem híbrida
É basicamente uma combinação dos dois métodos anteriores. É um modelo muito complexo que recomenda um produto com base em seu histórico e em usuários semelhantes como você.
Existem algumas organizações que utilizam este método como o Facebook que mostra notícias que são importantes para você e outras também da sua rede e o mesmo é utilizado pelo Linkedin também..
Sistema de recomendação de livro
Um sistema de recomendação de livros é um tipo de sistema de recomendação em que temos que recomendar livros semelhantes ao leitor com base em seu interesse. O sistema de recomendação de livros é usado por sites online que fornecem e-books como o Google Play Livros, biblioteca aberta, boas leituras, etc.
Neste artigo, usaremos o método de filtragem de base colaborativa para criar um sistema de recomendação de livros. Você pode baixar o conjunto de dados em aqui
Implementação prática do sistema de recomendação
Vamos sujar as mãos ao tentar implementar um sistema de recomendação de livros usando filtragem colaborativa.
Descrição do conjunto de dados
tenho 3 arquivos em nosso conjunto de dados retirados de alguns livros que vendem sites.
- Livros: primeiro trata de livros que contêm todas as informações relacionadas aos livros, como o autor, o título, o ano de publicação, etc.
- Comercial: o segundo arquivo contém informações do usuário registrado, como id de usuário, Localização.
- avaliações: notas contêm informações como qual usuário deu a nota para qual livro.
Então, com base nestes três arquivos, podemos construir um poderoso modelo de filtragem colaborativa. Comecemos.
Carregar dados
vamos começar importando bibliotecas e carregando conjuntos de dados. ao carregar o arquivo, temos alguns problemas como.
- Os valores no arquivo CSV são separados por ponto e vírgula, não por círgula.
- Existem algumas linhas que não funcionam como se não pudéssemos importá-las com pandas e isso vomita um erro porque Python é uma linguagem interpretada.
- A codificação de um arquivo está em latim
Então, ao carregar dados, temos que lidar com essas exceções e depois de executar o seguinte código, você vai receber um aviso e ele vai mostrar quais linhas têm um erro que nós pulamos durante o carregamento.
import numpy as np
import pandas as pd
books = pd.read_csv("BX-Books.csv", sep = ';', codificação ="latin-1", error_bad_lines = False)
usuários = pd.read_csv("BX-Usuários.csv", sep = ';', codificação ="latin-1", error_bad_lines = False)
avaliações = pd.read_csv("BX-Book-Ratings.csv", sep = ';', codificação ="latin-1", error_bad_lines = False)
Pré-processamento de dados
Agora, no arquivo do livro, temos algumas colunas extras que não são necessárias para nossa tarefa, como os urls das imagens. E vamos renomear as colunas de cada arquivo, pois o nome da coluna contém espaço e letras maiúsculas para que possamos corrigi-lo e torná-lo fácil de usar.
livros = livros[['ISBN', 'Título do livro', 'Livro-Autor', 'Ano de publicação', 'Editor']]
books.rename(colunas = {'Título do livro':'título', 'Livro-Autor':'autor', 'Ano de publicação':'ano', 'Editor':'editor'}, inplace = True)
users.rename(colunas = {'ID do usuário':'ID do usuário', 'Localização':'localização', 'Era':'era'}, inplace = True)
ratings.rename(colunas = {'ID do usuário':'ID do usuário', 'Classificação do livro':'Avaliação'}, inplace = True)
Agora, se você vir o cabeçalho de cada quadro de dados, você pode ver algo assim.
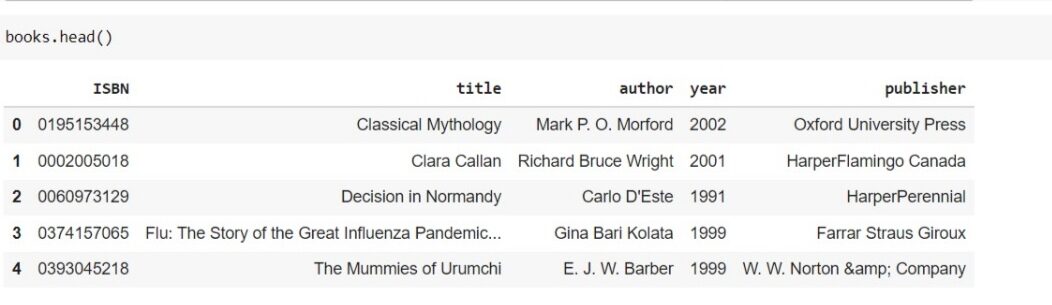
O conjunto de dados é confiável e pode ser considerado um grande conjunto de dados. Tenho 271360 livros de dados e o número total de usuários registrados no site é de aproximadamente 278000 e deram uma classificação de perto de 11 lakh. portanto, podemos dizer que o conjunto de dados que temos é bom e confiável.
Abordagem para apresentar um problema
Não queremos encontrar semelhanças entre usuários ou livros. queremos fazer isso se houver um usuário A que leu e gostou dos livros x e y, e o usuário B também gostou desses dois livros e agora o usuário A leu e gostou de algum livro z que não foi lido por B, então temos que recomendar z book para o usuário B. Isso é o que é filtragem colaborativa.
Então, isso é conseguido usando fatoração de matriz, vamos criar uma matriz onde as colunas serão os usuários e os índices serão os livros e o valor será a nota. Como se tivéssemos que criar uma tabela dinâmica.
Uma grande falha com uma declaração de problema no conjunto de dados.
Se pegarmos todos os livros e todos os usuários para modelar, Você não acha que isso vai criar um problema? Então o que temos que fazer é reduzir o número de usuários e livros porque não podemos considerar um usuário que só se cadastrou no site ou que só leu um ou dois livros. Em tal usuário, não podemos confiar na recomendação de livros para outras pessoas porque temos que extrair conhecimento dos dados. Então, vamos limitar esse número e pegar um usuário que avaliou pelo menos 200 livros e também limitaremos os livros e levaremos apenas os livros que receberam pelo menos 50 avaliações do usuário.
Análise exploratória de dados
Então, vamos começar com a análise e preparar o conjunto de dados conforme discutimos para a modelagem. Vamos ver quantos usuários deram avaliações e extrair aqueles usuários que deram mais de 200 avaliações.
avaliações['ID do usuário'].valor_contas()
Paso 1) Extrair usuários e avaliações de mais de 200
quando você executa o código acima, podemos ver que só 105283 as pessoas deram uma classificação entre 278000. Agora vamos extrair os identificadores de usuário que concederam mais do que 200 classificações e quando tivermos os identificadores de usuário, extrairemos as classificações apenas deste identificador de usuário a partir da estrutura de dados de classificação.
x = classificações['ID do usuário'].valor_contas() > 200
y = x[x].index #user_ids
print(y.shape)
classificações = classificações[avaliações['ID do usuário'].raio(e)]
passo-2) Mesclar classificações com livros
Então há 900 usuários que deram uma avaliação de 5.2 lakh e isso é o que nós queremos. Agora, mesclaremos as classificações com os livros com base no ISBN para obtermos a classificação de cada usuário em cada ID de livro e do usuário que não classificou esse ID de livro, o valor será zero.
rating_with_books = ratings.merge(livros, on = 'ISBN') rating_with_books.head()

paso-3) Confira os livros que receberam mais de 50 avaliações.
Agora, o tamanho do quadro de dados diminuiu e temos 4.8 lakh porque quando mesclamos o quadro de dados, não tínhamos todos os dados de identificação do livro. Agora vamos contar a classificação de cada livro, por isso vamos agrupar os dados de acordo com o título e os dados agregados de acordo com a classificação.
number_rating = rating_with_books.groupby('título')['Avaliação'].contar().reset_index()
number_rating.renome(colunas = {'Avaliação':'number_of_ratings'}, inplace = True)
final_rating = rating_with_books.mesclam(number_rating, on='title')
final_rating.shape
final_rating = final_rating[final_rating['number_of_ratings'] >= 50]
final_rating.drop_duplicatas(['ID do usuário','título'], inplace = True)
temos que remover valores duplicados porque se o mesmo usuário avaliou o mesmo livro várias vezes, vai criar um problema. Finalmente, temos um conjunto de dados com aquele usuário que avaliou mais de 200 livros e livros que receberam mais de 50 avaliações. a forma do quadro de dados final é 59850 linhas e 8 colunas.
Paso 4) Criar tabela dinâmica
Como discutimos anteriormente, vamos criar uma tabela dinâmica na qual as colunas serão os identificadores do usuário, o índice será o título do livro e o valor das notas. E o ID do usuário que não classificou nenhum livro terá valor como NAN, então impute-o com zero.
book_pivot = final_rating.pivot_table(colunas ="ID do usuário", índice = 'título', valores ="Avaliação") book_pivot.fillna(0, inplace = True)
Podemos ver que mais do que 11 Os usuários foram removidos porque suas notas estavam nos livros que não recebem mais do que 50 avaliações, então eles são removidos da imagem.
Modelagem
Preparamos nosso conjunto de dados para modelar. Usaremos o algoritmo de vizinhos mais próximos, que é o mesmo que o K mais próximo, usado para agrupamento baseado em distância euclidiano.
Mas aqui, na Tabela Dinâmica, temos muitos valores zero e no agrupamento, esse poder de computação aumentará para calcular a distância de valores zero, então vamos converter o pivô na matriz esparsa e, em seguida, alimentá-lo para o modelo.
from scipy.sparse import csr_matrix
book_sparse = csr_matrix(book_pivot)
Agora vamos treinar o algoritmo dos vizinhos mais próximos. aqui temos que especificar um algoritmo que é meios brutos para encontrar a distância de cada ponto para todos os outros pontos.
from sklearn.neighbors import NearestNeighbors
model = NearestNeighbors(algoritmo = 'bruto')
model.fit(book_sparse)
Vamos fazer uma previsão e ver se sugere livros ou não.. vamos encontrar os vizinhos mais próximos do id do livro de entrada e depois disso, vamos encontrar os vizinhos mais próximos do id do livro de entrada e depois disso 5 vamos encontrar os vizinhos mais próximos do id do livro de entrada e depois disso. Isso nos dará a distância e a identificação do livro a essa distância. vamos passar para Harry Potter, o que tem 237 índices.
distâncias, sugestões = model.kneighbors(book_pivot.iloc[237, :].values.reshape(1, -1))
vamos imprimir todos os livros sugeridos.
para eu no alcance(len(sugestões)): imprimir(book_pivot.index[sugestões[eu]])
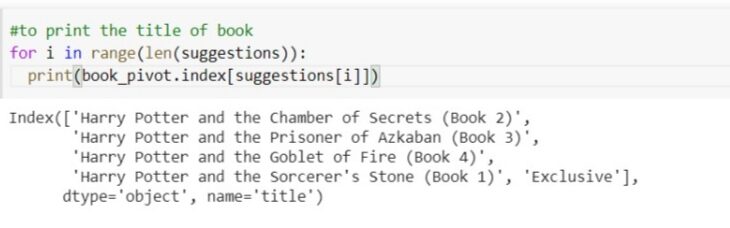
portanto, construímos com sucesso um sistema de recomendação de livros.
Notas finais
Viva! Temos que construir um sistema confiável de recomendação de livros e você pode modificá-lo e transformá-lo em um projeto final. Este é um projeto de aprendizagem não supervisionado maravilhoso, onde fizemos muito pré-processamento e você pode explorar o conjunto de dados mais a fundo e, se você encontrar algo mais interessante, compartilhe na caixa de comentários.
Espero que tenha sido fácil acompanhar cada método e seguir o artigo. Se você tiver alguma dúvida, poste na seção de comentários abaixo. Ficarei feliz em ajudá-lo com qualquer dúvida.
Sobre o autor
Raghav Agrawal
Estou buscando meu diploma em ciência da computação. Eu realmente gosto de ciência de dados e big data. Adoro trabalhar com dados e aprender novas tecnologias. Por favor, sinta-se à vontade para se conectar comigo no Linkedin.
Se você gosta do meu artigo, por favor, leia também para os outros. Ligação
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





