Este artigo foi publicado como parte do Data Science Blogathon
Introdução
A seleção de recursos é o processo de seleção de recursos relevantes para um modelo de aprendizado de máquina. Isso significa que ele seleciona apenas os atributos que têm um efeito significativo na saída do modelo.
Considere o caso quando você vai a uma loja de departamentos para comprar itens de mercearia. Um produto contém muitas informações, quer dizer, produtos, categoria, data de vencimento, MRP, ingredientes e detalhes de fabricação. Todas essas informações são as características do produto. Normalmente, verifique a marca, MRP e data de validade antes de comprar um produto. Porém, a seção de ingredientes e fabricação não é da sua conta. Portanto, a marca, el mrp, a data de validade são características relevantes e o ingrediente, detalhes de fabricação são irrelevantes. É assim que a seleção de recursos é feita.
No mundo real, um conjunto de dados pode ter milhares de recursos e pode haver chances de alguns recursos serem redundantes, alguns podem estar correlacionados e alguns podem ser irrelevantes para o modelo. Nesta fase, se você usar todas as funções, vai demorar muito para treinar o modelo e a precisão do modelo será reduzida. Portanto, a seleção de recursos torna-se importante na construção do modelo. Existem muitas outras maneiras de selecionar recursos, como eliminação de recursos recursivos, algorítmos genéticos, Árvores de decisão. Porém, Vou te dizer o método mais básico e manual de filtragem usando testes estatísticos.
Agora que você tem uma compreensão básica da seleção de recursos, veremos como implementar vários testes estatísticos nos dados para selecionar características importantes.
objetivo
O objetivo principal deste blog é entender os testes estatísticos e sua implementação em dados reais em Python., que ajudará na seleção de recursos.
Terminologias
Antes de entrar nos tipos de testes estatísticos e sua implementação, é necessário compreender os significados de algumas terminologias.
Testando hipóteses
O teste de hipóteses em estatísticas é um método de testar os resultados de experimentos ou pesquisas para ver se tem resultados significativos.. Útil quando você deseja inferir sobre uma população com base em uma amostra ou correlação entre duas ou mais amostras.
Hipótese nula
Essa hipótese estabelece que não há diferença significativa entre amostra e população ou entre diferentes populações.. Se denota por H0.
Não. Assumimos que a média de 2 samples é o mesmo.
Hipótese alternativa
A afirmação contrária à hipótese nula está incluída na hipótese alternativa. Se denota por H1.
Não. Assumimos que a média do 2 as amostras são irregulares.
Valor crítico
É um ponto na escala da estatística de teste além do qual a hipótese nula é rejeitada.. Quanto maior o valor crítico, quanto menor a probabilidade de que 2 as amostras pertencem à mesma distribuição. O valor crítico para qualquer teste pode
valor p
valor p significa 'valor de probabilidade'; indica a probabilidade de que um resultado tenha ocorrido por acaso. Basicamente, o valor p é usado no teste de hipótese para ajudá-lo a apoiar ou rejeitar a hipótese nula. Quanto menor for o valor p, quanto mais forte a evidência para rejeitar a hipótese nula.
Grau de liberdade
O grau de liberdade é o número de variáveis independentes. Este conceito é usado para calcular a estatística t e a estatística qui-quadrado.
Você pode se referir a statisticswho.com para obter mais informações sobre essas terminologias.
Testes estatísticos
Um teste estatístico é uma forma de determinar se a variável aleatória segue a hipótese nula ou a hipótese alternativa. Basicamente, diz se a amostra e a população ou duas ou mais amostras têm diferenças significativas. Você pode usar várias estatísticas descritivas como média, mediana, caminho, intervalo ou desvio padrão para este propósito. Porém, geralmente usamos a média. O teste estatístico fornece um número que é então comparado com o valor p. Se seu valor for maior que o valor p, aceitar a hipótese nula, pelo contrário, Ela rejeita.
O procedimento para implementar cada teste estatístico será o seguinte:
- Calculamos o valor estatístico usando a fórmula matemática
- Em seguida, calculamos o valor crítico usando tabelas estatísticas.
- Com a ajuda de valor crítico, nós calculamos o valor p
- Se o valor p> 0.05 nós aceitamos a hipótese nula, caso contrário, nós rejeitamos
Agora que você entende a seleção de recursos e os testes estatísticos, podemos avançar para a implementação de vários testes estatísticos, juntamente com o seu significado. Antes disso, Eu vou te mostrar o conjunto de dados e este conjunto de dados será usado para todos os testes.
Conjunto de dados
O conjunto de dados que irei usar é um conjunto de dados de previsão de empréstimo que foi retirado do concurso de análise Vidhya. Você também pode participar do concurso e baixar o conjunto de dados. aqui.
Primeiro importei todos os módulos python necessários e o conjunto de dados.
importar numpy como np
importar pandas como pd
importado do mar como sb
from numpy import sqrt, abdômen, volta
importar scipy.stats como estatísticas
da norma de importação scipy.stats
df = pd.read_csv('empréstimo.csv')
df.head()

Existem muitas características no conjunto de dados, como gênero, dependentes, Educação, renda do requerente, montante do empréstimo, histórico de crédito. Usaremos esses recursos e verificaremos se um efeito de recurso afeta outros recursos usando vários testes, quer dizer, Teste Z, teste de correlação, Teste ANOVA e teste Qui-quadrado.
Teste Z
Um teste Z é usado para comparar a média de duas amostras fornecidas e inferir se elas pertencem à mesma distribuição ou não.. Não implementamos o teste Z quando o tamanho da amostra é menor que 30.
Um teste Z pode ser um teste Z de uma amostra ou um teste Z de duas amostras.
A amostra única teste t determina se a média da amostra é estatisticamente diferente de uma média populacional conhecida ou hipotética. O teste Z de duas amostras compara 2 variáveis independentes.
Implementaremos um teste Z de duas amostras.
A estatística Z é denotada por
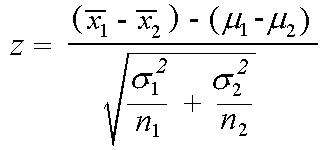
Implementação
Observe que iremos implementar 2 testes z de amostra em que uma variável será categórica com duas categorias e a outra variável será contínua para aplicar o teste z.
Aqui vamos usar o Gênero variável categórica e Renda do Requerente Variável contínua. O gênero tem 2 grupos: masculino e feminino. Portanto, a hipótese será:
Hipótese nula: Não há diferença significativa entre a renda média de homens e mulheres.
Hipótese alternativa: há uma diferença significativa entre a renda média de homens e mulheres.
Código
M_mean = df.loc[df['Gênero']== 'Masculino','Receita do Requerente'].quer dizer() F_mean = df.loc[df['Gênero']== 'Feminino','Receita do Requerente'].quer dizer() M_std = df.loc[df['Gênero']== 'Masculino','Receita do Requerente'].std() F_std = df.loc[df['Gênero']== 'Feminino','Receita do Requerente'].std() no_of_M = df.loc[df['Gênero']== 'Masculino','Receita do Requerente'].contar() no_of_F = df.loc[df['Gênero']== 'Feminino','Receita do Requerente'].contar()
O código acima calcula a renda média de candidatos do sexo masculino, a renda média das candidatas, seu desvio padrão e o número de amostras de homens e mulheres.
twoSampZ A função irá calcular a estatística z e o valor p sem passar pelos parâmetros de entrada calculados anteriormente.
def twoSampZ(X1, X2, mudiff, sd1, sd2, n1, n2):
pooledSE = sqrt(sd1 ** 2 / n1 + sd2 ** 2 / n2)
z = ((X1 - X2) - mudiff)/pooledSE
pval = 2*(1 - norm.cdf(abdômen(Com)))
volta(Com,3), pval
z,p = twoSampZ(M_mean,F_mean,0,M_std,F_std,no_of_M,no_of_F)
imprimir('Z' = z,'p' = p)
Z = 1.828
p = 0.06759726635832197
Se p<0.05:
imprimir("nós rejeitamos a hipótese nula")
outro:
imprimir("nós aceitamos hipótese nula")
nós aceitamos a hipótese nula
Uma vez que o valor p é maior que 0.5 nós aceitamos a hipótese nula. Por tanto, concluímos que não há diferença significativa entre a renda de homens e mulheres.
Teste T
Um teste t também é usado para comparar a média de duas amostras fornecidas., como o teste Z. Porém, é implementado quando o tamanho da amostra é menor que 30. Uma distribuição normal da amostra é assumida. Também pode ser uma ou duas amostras. O grau de liberdade é calculado por n-1, onde n é o número de amostras.
É denotado por

Implementação
Será implementado da mesma forma que o teste Z. A única condição é que o tamanho da amostra seja menor que 30. Eu mostrei a você a implementação do teste Z. Agora, você pode tentar o T-Test.
Teste de Correlação
Um teste de correlação é uma métrica para avaliar até que ponto as variáveis estão associadas entre si.
Observe que as variáveis devem ser contínuas para aplicar o teste de correlação.
Existem vários métodos para teste de correlação, quer dizer, Covarianza, Coeficiente de correlação de Pearson, Coeficiente de correlação de classificação de Spearman, etc.
Usaremos o coeficiente de correlação de pessoas, pois é independente dos valores das variáveis.
Coeficiente de correlação de Pearson
É usado para medir a correlação linear entre 2 variáveis. É denotado por

imagem do Google
Seus valores estão entre -1 e 1.
Se o valor de r for 0, significa que não há relação entre as variáveis X e Y.
Se o valor de r estiver entre 0 e 1, significa que há uma relação positiva entre X e Y, e sua força aumenta de 0 uma 1. Relação positiva significa que se o valor de X aumentar, o valor de Y também aumenta.
Se o valor de r estiver entre -1 e 0, significa que há uma relação negativa entre X e Y, e sua força diminui de -1 uma 0. Relação negativa significa que se o valor de X aumentar, o valor de Y diminui.
Implementação
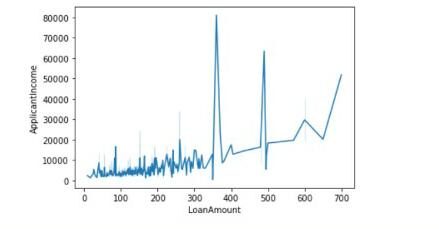
Aqui, usaremos duas variáveis ou características contínuas: Montante do empréstimo e Renda do requerente. Concluiremos se existe uma relação linear entre o valor do empréstimo e a renda do solicitante com o valor do coeficiente de correlação de Pearson e também traçaremos o gráfico entre eles.
Código
Existem alguns valores ausentes na coluna LoanAmount, primeiro, nós o preenchemos com o valor médio. Então ele calculou o valor do coeficiente de correlação.
df['Montante do empréstimo']= df['Montante do empréstimo'].Fillna (df['Montante do empréstimo'].significar())
pcc = por exemplo, corrcoef (df.ApplicantIncome, df.LoanAmount)
imprimir (pcc)
[[1. 0.56562046] [0.56562046 1. ]]
Os valores das diagonais indicam a correlação das características com elas mesmas. 0.56 representam que há alguma correlação entre as duas características.
Também podemos desenhar o gráfico da seguinte maneira:
sns.lineplot(data = df,x = 'LoanAmount',y = 'ApplicantIncome')
Teste ANOVA
ANOVA significa análise de variância. Como o nome sugere, usa a variância como parâmetro para comparar vários grupos independentes. ANOVA pode ser ANOVA unidirecional ou ANOVA bidirecional. ANOVA unilateral é aplicada quando há três ou mais grupos independentes de uma variável. Vamos implementar o mesmo em Python.
A estatística F pode ser calculada por

Implementação
Aqui vamos usar o Dependentes variável categórica e Renda do Requerente Variável contínua. Os dependentes têm 4 grupos: 0,1,2,3+. Portanto, a hipótese será:
Hipótese nula: Não há diferença significativa entre a renda média entre os diferentes grupos de dependentes.
Hipótese alternativa: existe uma diferença significativa entre a renda média entre os diferentes grupos de dependentes.
Código
Primeiro, lidamos com os valores ausentes na função Dependentes.
df['Dependentes'].é nulo().soma()
df['Dependentes']= df['Dependentes'].Fillna('0')
Depois disso, criamos um quadro de dados com as características Dependents e ApplicantIncome. Mais tarde, com a ajuda da biblioteca scipy.stats, calculamos a estatística F e o valor p.
df_anova = df[['total_bill','dia']]
grps = pd.unique(df.day.values)
d_data = {grp:df_anova['total_bill'][df_anova.day == grp] para grp em grps}
F, p = stats.f_oneway(d_data['Sol'], d_data['Sentado'], d_data['Qui'],d_data['Sex'])
imprimir('F ={},p ={}'.formato(F,p))
F = 5,955112389949444, p = 0,0005260114222572804
e P <0,05:
imprimir (“rejeitar hipótese nula”)
o resto:
imprimir (“aceitar hipótese nula”)
Rejeitar hipótese nula.
Uma vez que o valor p é menor que 0.5 rejeitamos a hipótese nula. Por tanto, concluímos que há uma diferença significativa entre a renda de vários grupos de dependentes.
Teste qui-quadrado
Este teste é aplicado quando você tem duas variáveis categóricas de uma população. É usado para determinar se existe uma associação ou relação significativa entre as duas variáveis.
Existem 2 tipos de testes qui-quadrado: Qualidade de ajuste do qui-quadrado e teste do qui-quadrado para independência, vamos implementar o último.
O grau de liberdade no teste do qui-quadrado é calculado por (n-1) * (m-1) onde n e m são números de linhas e colunas, respectivamente.
É denotado por:

Implementação
Usaremos dos características categóricas Gênero e Status do empréstimo e descobrir se há uma associação entre eles usando o teste do qui-quadrado.
Hipótese nula: não há associação significativa entre as características de gênero e a situação do empréstimo.
Hipótese alternativa: há uma associação significativa entre as características de gênero e a situação do empréstimo.
Código
Primeiro, recuperamos a coluna Gender e LoanStatus e formamos um array.
dataset_table = pd.crosstab(conjunto de dados['sexo'],conjunto de dados['fumante']) dataset_table
Loan_Status N Y
Gender
Female 37 75
Masculino 33 339
Mais tarde, calculamos os valores observados e esperados usando a tabela acima.
observado = dataset_table.values val2 = stats.chi2_contingency(dataset_table) esperado = val2[3]
Em seguida, calculamos a estatística qui-quadrado e o valor p usando o seguinte código:
de scipy.stats import chi2 chi_square = sum([(o-e)**2./e para o,e em zip(observado,esperado)]) chi_square_statistic = chi_square[0]+chi_square[1] p_value = 1-chi2.cdf(x = chi_square_statistic,df = ddof)
imprimir("estatística qui-quadrado:-",chi_square_statistic)
imprimir('Nível de significância: ',alfa)
imprimir('Grau de liberdade: ',eu vou vir)
imprimir('p-valor:',p_value)
estatística qui-quadrado:- 0.23697508750826923 Nível de significância: 0.05 Grau de liberdade: 1 valor p: 0.6263994534115932
if p_value<= alfa:
imprimir("Rejeitar hipótese nula")
outro:
imprimir("Aceitar hipótese nula")
Aceitar hipótese nula
Uma vez que o valor p é maior que 0.05, nós aceitamos a hipótese nula. Concluímos que não há associação significativa entre as duas características.
Resumo
Primeiro, nós discutimos a seleção de recursos. Em seguida, passamos para os testes estatísticos e várias terminologias relacionadas a ele.. Por último, vimos a aplicação de testes estatísticos, quer dizer, Teste Z, Teste t, teste de correlação, ANOVA e teste de qui-quadrado junto com sua implementação em Python.
Referências
Excelente imagem – imagem do Google
Estatisticas – statisticswho.com
Sobre mim
Olá! Soy Ashish Choudhary. Estou estudando B.Tech da Universidade de Ciência e Tecnologia JC Bose. Ciência de dados é minha paixão e tenho orgulho de escrever blogs interessantes relacionados a ela. Sinta-se à vontade para entrar em contato comigo no LinkedIn.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





