Este artigo foi publicado como parte do Data Science Blogathon
A imputação é uma técnica usada para substituir os dados ausentes por algum valor substituto para reter a maioria dos dados / informações do conjunto de dados. Essas técnicas são usadas porque remover os dados do conjunto de dados cada vez não é viável e pode levar a uma redução no tamanho do conjunto de dados em grande medida., que não só levanta preocupações sobre distorção do conjunto de dados, também leva a uma análise incorreta.
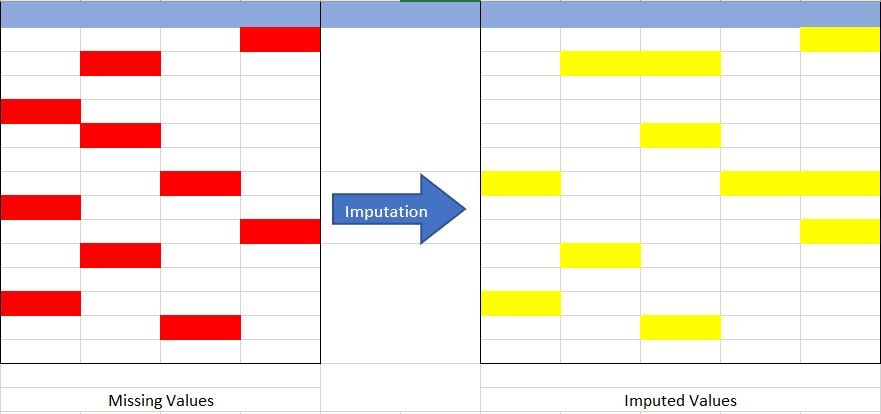
Fonte: criado pelo autor
Não tenho certeza de quais dados estão faltando? Como isso acontece? E seu tipo? Dê uma olhada AQUI para saber mais sobre isso.
Vamos entender o conceito de imputação da Fig. {FIG 1} anterior. Na foto acima, Tentei representar os dados ausentes na tabela à esquerda (marcado em vermelho) e usando técnicas de imputação, completamos o conjunto de dados que faltavam na tabela à direita (marcado em amarelo), sem reduzir o tamanho real do conjunto de dados. Se percebermos aqui, aumentamos o tamanho da coluna, o que é possível na imputação (adicionando a imputação de categoria “Falta”).
Por que a imputação é importante?
Então, depois de conhecer a definição de imputação, a próxima pergunta é por que devemos usá-lo e o que aconteceria se eu não o usasse?
Aqui vamos nós com as respostas às perguntas anteriores.
Usamos imputação porque dados ausentes podem causar os seguintes problemas: –
- Incompatível com a maioria das bibliotecas Python usadas no aprendizado de máquina: – sim, você lê bem. Ao usar as bibliotecas para ML (o mais comum é skLearn), não tem uma disposição para lidar automaticamente com esses dados ausentes e pode gerar erros.
- Distorção no conjunto de dados: – Uma grande quantidade de dados perdidos pode causar distorções na distribuição da variável, quer dizer, pode aumentar ou diminuir o valor de uma determinada categoria no conjunto de dados.
- Afeta o modelo final: – dados ausentes podem causar viés no conjunto de dados e podem levar a análises defeituosas pelo modelo.
Outra e a razão mais importante é “Queremos restaurar o conjunto de dados completo”. Isso ocorre principalmente no caso em que não queremos perder (mais) dados do nosso conjunto de dados, uma vez que todos são importantes e, em segundo lugar, o tamanho do conjunto de dados não é muito grande e a remoção de parte dele pode ter um impacto significativo. no modelo final.
Excelente..!! temos alguns fundamentos de dados ausentes e imputação. Agora, Vamos dar uma olhada nas diferentes técnicas de imputação e compará-las. Mas antes de pular nisso, temos que saber os tipos de dados em nosso conjunto de dados.
Soa estranho..!!! Não se preocupe ... A maioria dos dados é de 4 tipos: – Numérico, Categórico, Data-hora e Misto. Esses nomes são autoexplicativos, então eles não se aprofundam nem os descrevem.
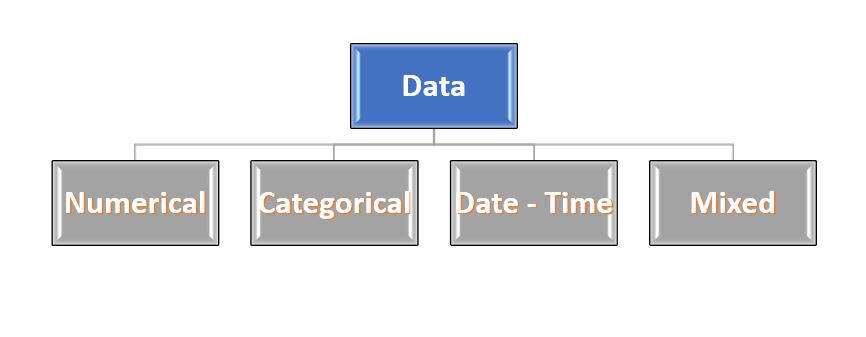
FIG 2: – Tipo de dados
Fonte: criado pelo autor
Técnicas de imputação
Passando para os destaques deste artigo … Técnicas usadas na imputação …
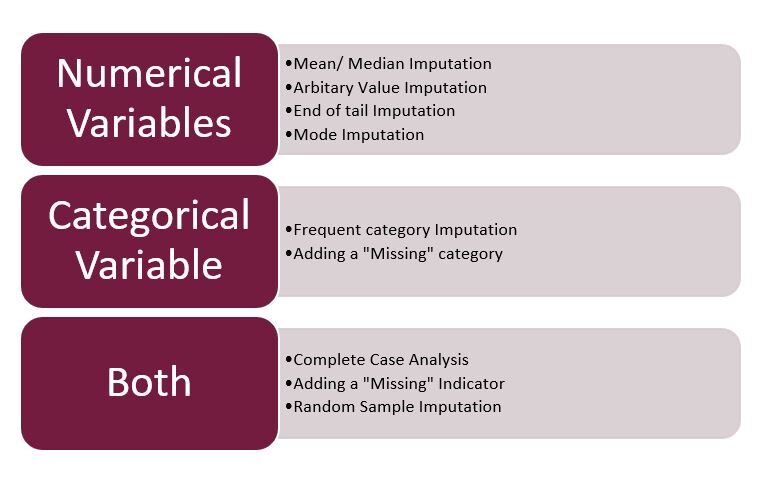
FIG 3: – Técnicas de imputação
Fonte: criado pelo autor
Observação: – Aqui, vou me concentrar exclusivamente na imputação mista, numérico e categórico. A data e hora farão parte do próximo artigo.
1. Análise completa do caso (CCA): –
Este é um método bastante simples para lidar com dados ausentes, que remove diretamente as linhas que contêm dados ausentes, quer dizer, consideramos apenas as linhas em que temos dados completos, quer dizer, sem dados perdidos. Este método também é conhecido popularmente como “deletar por lista”.
- Premissas: –
- Dados aleatórios em falta (MAR).
- Os dados ausentes são completamente removidos da tabela.
- Vantagem: –
- Fácil de implementar.
- Nenhuma manipulação de dados necessária.
- Limitações: –
- Os dados excluídos podem ser informativos.
- Isso pode levar à exclusão de muitos dos dados.
- Você pode criar um viés no conjunto de dados, se uma grande quantidade de um determinado tipo de variável for removida.
- O modelo de produção não saberá o que fazer com os dados ausentes.
- Quando usar:-
- Os dados são MAR (Faltando ao acaso).
- Bom para dados mistos, numérico e categórico.
- Os dados ausentes não são mais do que 5% a 6% do conjunto de dados.
- Os dados não contêm muitas informações e não distorcerão o conjunto de dados.
- Código:-
## Para verificar a forma do conjunto de dados original
train_df.shape
## Saída (614 filas & 13 colunas) (614,13)
## Encontrar as colunas com valores nulos(Dados ausentes) ## Estamos usando um loop for para todas as colunas presentes no conjunto de dados com valores nulos médios maiores que 0
na_variables = [ var para var em train_df.columns if train_df[Onde].é nulo().quer dizer() > 0 ]
## Saída de nomes de coluna com valores nulos ['Gênero','Casado','Dependentes','Trabalhadores por conta própria','Montante do empréstimo','Loan_Amount_Term','Histórico de crédito']
## Também podemos ver os valores nulos médios presentes nessas colunas {Mostrado na imagem abaixo}
data_na = trainf_df[na_variables].é nulo (). quer dizer ()
## Implementar as técnicas de CCA para remover dados ausentes data_cca = train_df(eixo = 0) ### eixo = 0 é usado para especificar linhas
## Verificando a forma final do conjunto de dados restante data_cca.shape
## Saída (480 filas & 13 Colunas) (480,13)
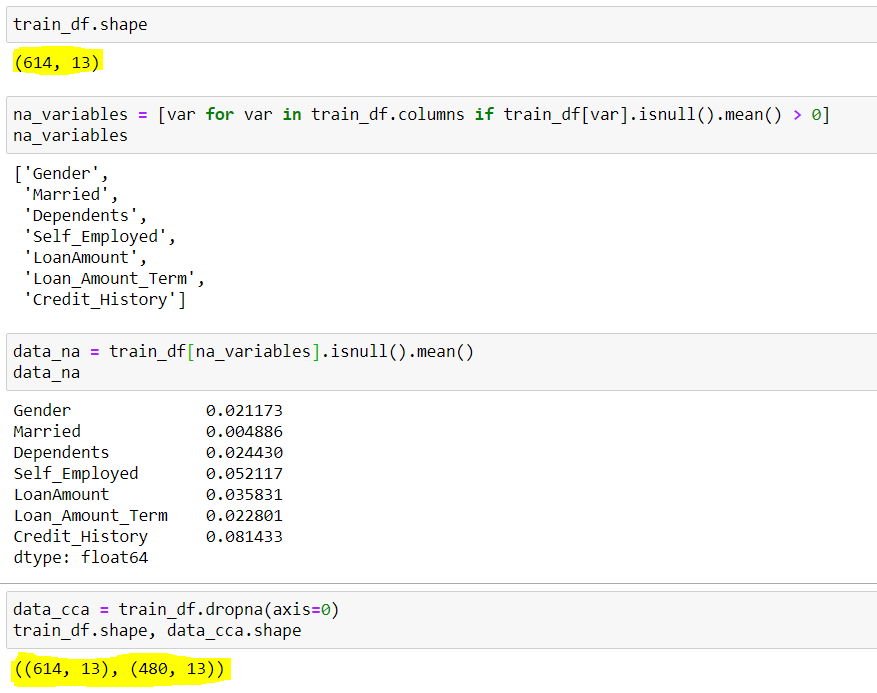
Figura 3: – CCA
Fonte: Criado pelo autor
Aqui podemos ver, o conjunto de dados inicialmente tinha 614 linhas e 13 colunas, das quais 7 linhas tinham dados ausentes(variáveis_variaveis), suas linhas intermediárias ausentes são mostradas por data_na. Nós observamos que, além de e , todos têm uma média inferior a 5%. Então, de acordo com CCA, removemos as linhas com dados ausentes, que resultou em um conjunto de dados com apenas 480 filas. Aqui você pode ver ao redor do 20% de redução de dados, o que pode causar muitos problemas no futuro.
2. Imputação de valor arbitrário
Esta é uma técnica importante usada na imputação, uma vez que pode lidar com variáveis numéricas e categóricas. Esta técnica afirma que agrupamos os valores ausentes em uma coluna e os atribuímos a um novo valor que está longe do intervalo dessa coluna. Em geral, nós usamos valores como 99999999 o -9999999 o “Falta” o “Indefinido” para variáveis numéricas e categóricas.
- Premissas: –
- Dados não faltam aleatoriamente.
- Dados ausentes são imputados com um valor arbitrário que não faz parte do conjunto de dados ou a média / mediana / moda de dados.
- Vantagem: –
- Fácil de implementar.
- Podemos usá-lo na produção.
- Preserva a importância de “valores ausentes” sim existe.
- Desvantagens: –
- Você pode distorcer a distribuição da variável original.
- Valores arbitrários podem criar outliers.
- Cuidado extra é necessário ao selecionar o valor arbitrário.
- Quando usar:-
- Quando os dados não são MAR (Faltando ao acaso).
- Apto para todos.
- Código:-
## Encontrar as colunas com valores nulos(Dados ausentes) ## Estamos usando um loop for para todas as colunas presentes no conjunto de dados com valores nulos médios maiores que 0
na_variables = [ var para var em train_df.columns if train_df[Onde].é nulo().quer dizer() > 0 ]
## Saída de nomes de coluna com valores nulos ['Gênero','Casado','Dependentes','Trabalhadores por conta própria','Montante do empréstimo','Loan_Amount_Term','Histórico de crédito']
## Use a coluna Gênero para encontrar os valores únicos na coluna train_df['Gênero'].exclusivo()
## Saída variedade(['Masculino','Fêmea',no])
## Aqui nan representa dados ausentes
## Usando a técnica de Imputação Arbitária, vamos imputar gênero ausente com "Ausente" {Você pode usar qualquer outro valor também}
arb_impute = train_df['Gênero'].Fillna('Ausente')
impute.arb exclusivo()
## Saída variedade(['Masculino','Fêmea','Ausente'])
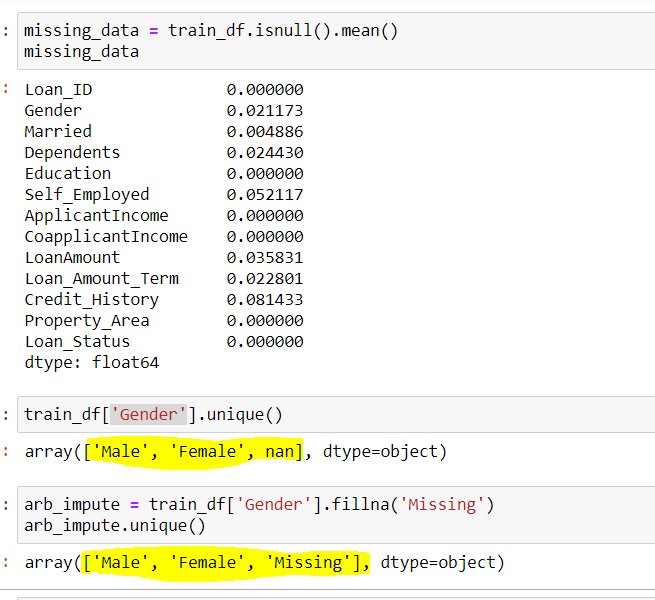
FIG 4: – Imputação arbitrária
Fonte: criado pelo autor
Podemos ver aqui a coluna Gênero eu tive 2 valores únicos {'Masculino feminino'} e poucos valores ausentes {no}. Ao usar imputação arbitrária, nós preenchemos os valores de {no} nesta coluna com {ausente}, pelo que você ganha 3 valores únicos para a variável ‘Gênero’.
3. Imputação de categoria frequente
Esta técnica diz para substituir o valor ausente pela variável com a maior frequência ou em palavras simples, substituindo os valores pelo Modo dessa coluna. Esta técnica também é conhecida como Imputação de modo.
- Premissas: –
- Dados aleatórios em falta.
- Há uma grande probabilidade de que os dados ausentes se pareçam com a maioria dos dados.
- Vantagem: –
- A implementação é simples.
- Podemos obter um conjunto de dados completo em um tempo muito curto.
- Podemos usar essa técnica no modelo de produção.
- Desvantagens: –
- Quanto maior a porcentagem de valores ausentes, quanto maior a distorção.
- Pode levar à super-representação de uma categoria específica.
- Você pode distorcer a distribuição da variável original.
- Quando usar:-
- Dados aleatórios em falta (MAR)
- Os dados ausentes não são mais do que 5% a 6% do conjunto de dados.
- Código:-
## encontrar a contagem de valores únicos em Gênero train_df['Gênero'].groupby(train_df['Gênero']).contar()
## Saída (489 Masculino & 112 Fêmea) Masculino 489 Fêmea 112
## Masculino tem maior frequência. Também podemos fazer isso verificando o modo train_df['Gênero'].modo()
## Saída Masculino
## Usando o Imputador de Categoria Freqüente
frq_impute = train_df['Gênero'].Fillna('Masculino')
frq_impute.unique()
## Saída variedade(['Masculino','Fêmea'])
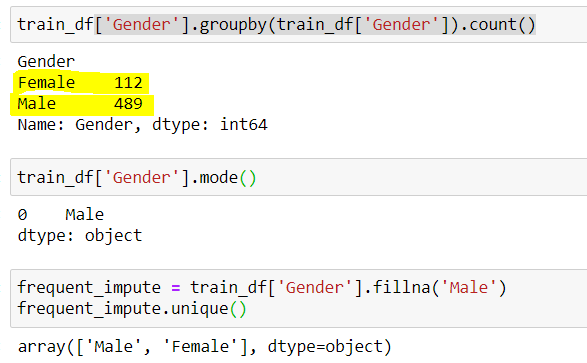
FIG 4: – Imputação de categoria frequente
Fonte: criado pelo autor
Aqui notamos que “Masculino” foi a categoria mais frequente, então nós o usamos para substituir os dados ausentes. Agora estamos sozinhos 2 categorias, quer dizer, masculino e feminino.
Portanto, podemos ver que cada técnica tem suas vantagens e desvantagens, e depende do conjunto de dados e da situação para a qual as diferentes técnicas que vamos usar.
É tudo daqui …
Até então, este es Shashank Singhal, um entusiasta de Big Data e ciência de dados.
Bom aprendizado ...
Se você gostou do meu artigo você pode me seguir AQUI
Perfil do linkedIn:- www.linkedin.com/in/shashank-singhal-1806
Observação: – Todas as imagens usadas acima foram criadas por mim (Autor).
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





