Este artigo foi publicado como parte do Data Science Blogathon
Visão geral
Este artigo discutirá brevemente a CNN, uma variante especial de redes neurais projetadas especificamente para tarefas relacionadas a imagens. O artigo se concentrará principalmente na parte de implementação da CNN. Todo esforço foi feito para tornar este artigo interativo e direto.. Espero que gostem. Boas aprendizagens !!

Introdução
As redes neurais convolucionais foram introduzidas por Yann LeCun e Yoshua Bengio no ano 1995 que mais tarde foi mostrado para mostrar resultados excepcionais no domínio das imagens. Então, O que os torna especiais em comparação com as redes neurais comuns, quando aplicados no domínio da imagem? Vou explicar uma das razões com um exemplo simples. Observe que você recebeu a tarefa de classificar imagens de dígitos manuscritos e que alguns conjuntos de treinamento de amostra são mostrados abaixo.

Se você observar corretamente, você pode descobrir que todos os dígitos aparecem no centro das respectivas imagens. Treinar um modelo de rede neural normal com essas imagens pode dar um bom resultado se a imagem de teste for de um tipo semelhante. Mas, E se a imagem de teste for como abaixo?

Aqui o número nove aparece no canto da imagem. Se usarmos um modelo de rede neural simples para classificar esta imagem, nosso modelo pode falhar abruptamente. Mas se a mesma imagem de teste for dada a um modelo da CNN, é muito provável que seja classificado corretamente. A razão para o melhor desempenho é que ele procura características espaciais na imagem. Para o caso acima em si, mesmo se o número nove estiver no canto esquerdo do quadro, o modelo treinado da CNN captura os recursos da imagem e provavelmente prevê que o número é o dígito nove. Uma rede neural normal não pode fazer esse tipo de mágica. Agora vamos discutir brevemente os principais blocos de construção da CNN.
Principais componentes da arquitetura de um modelo CNN
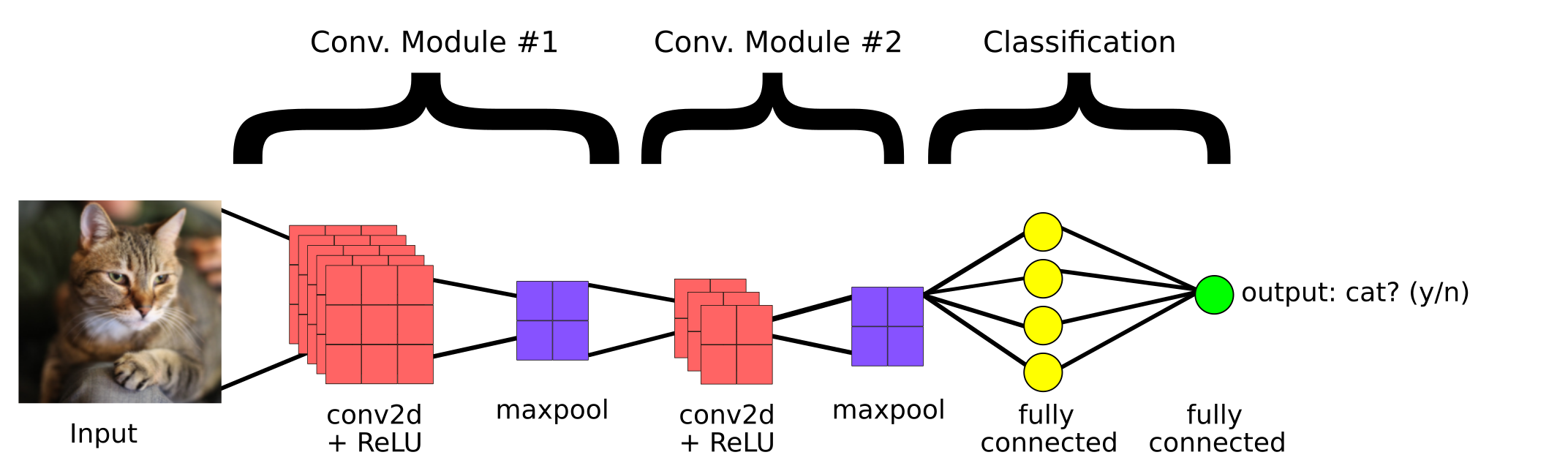
Este é um modelo simples de CNN criado para classificar se a imagem contém um gato ou não. Então, os principais componentes de uma CNN são:
1. Capa convolucional
2. Camada de agrupamento
3.Camada totalmente conectada
Capa convolucional
As camadas convolucionais nos ajudam a extrair os recursos que estão presentes na imagem. Essa extração é realizada com a ajuda de filtros. Observe a seguinte operação.
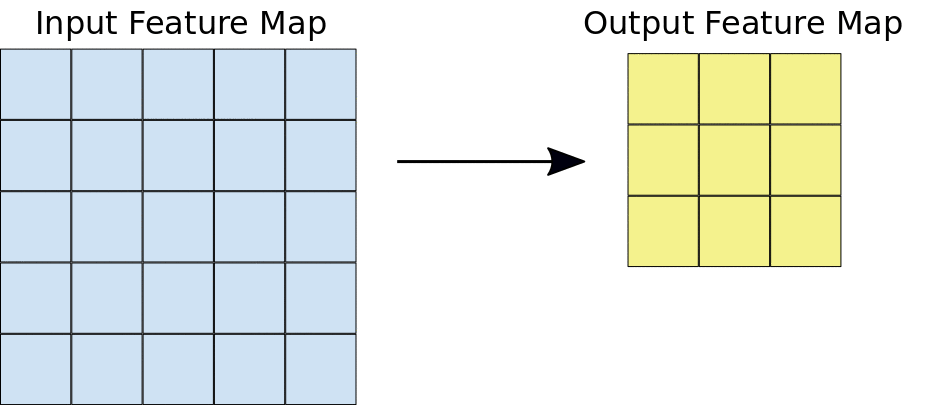
Aqui podemos ver que uma janela desliza sobre a imagem inteira, onde a imagem é renderizada como uma grade (É assim que o computador vê as imagens em que as grades são preenchidas com números!!). Agora vamos ver como os cálculos são realizados na operação de convolução.
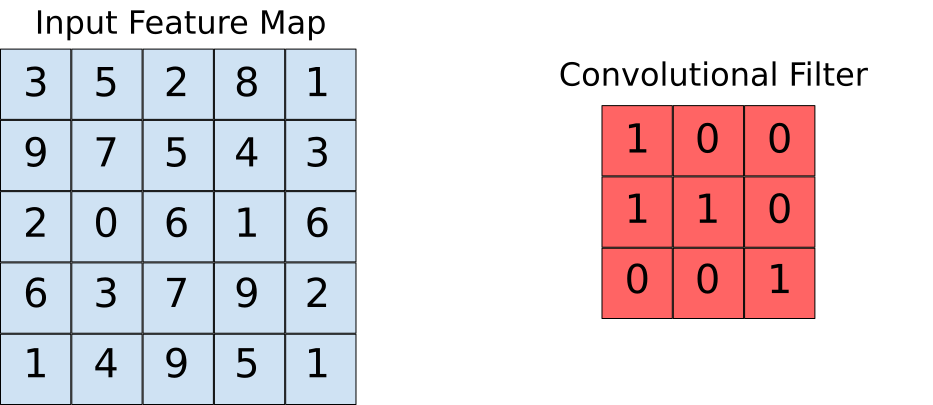
Suponha que o mapa de características de entrada seja a nossa imagem e que o filtro convolucional seja a janela na qual vamos deslizar. Agora vamos dar uma olhada em uma das instâncias da operação de convolução.
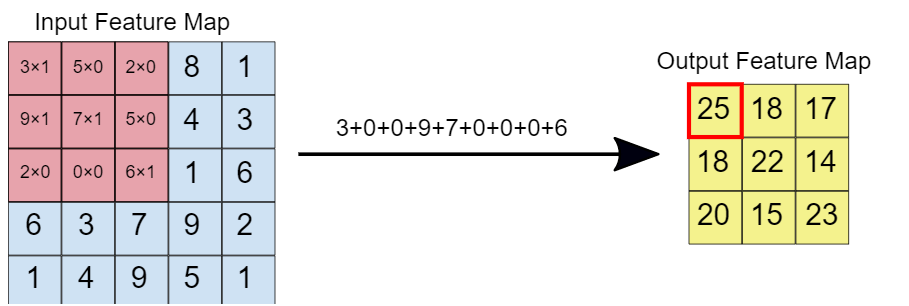
Quando o filtro de convolução é sobreposto na imagem, os respectivos elementos são multiplicados. Mais tarde, os valores multiplicados são adicionados para obter um único valor que é preenchido no mapa de recursos de saída. Esta operação continua até que deslizemos a janela pelo mapa de características de entrada., preenchendo assim o mapa de características de saída.
Camada de agrupamento
A ideia por trás do uso de uma camada de agrupamento é reduzir a dimensão do mapa de feições. Para a representação dada abaixo, usamos uma camada de agrupamento máximo de 2 * 2. Cada vez que a janela desliza sobre a imagem, pegamos o valor máximo presente na janela.
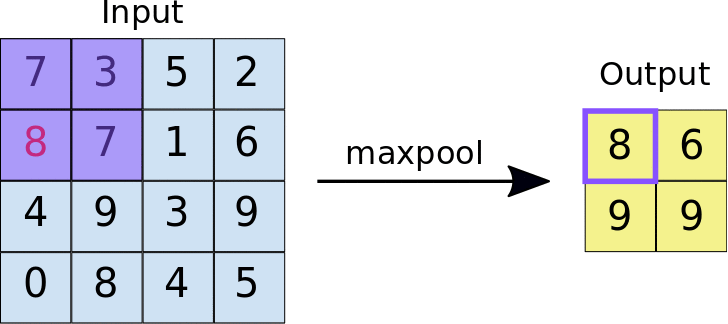
Finalmente, após operação máxima do grupo, podemos ver aqui que a dimensão da entrada, quer dizer, 4 * 4, foi reduzido a 2 * 2.
Camada totalmente conectada
Esta camada está presente na seção final da arquitetura do modelo CNN, como visto antes. A entrada para a camada totalmente conectada são os ricos recursos que foram extraídos por filtros convolucionais. Isso então se propaga para a camada de saída, onde obtemos a probabilidade de que a imagem de entrada pertença a diferentes classes. O resultado previsto é a classe com a maior probabilidade de que o modelo tenha previsto.
Implementação de código
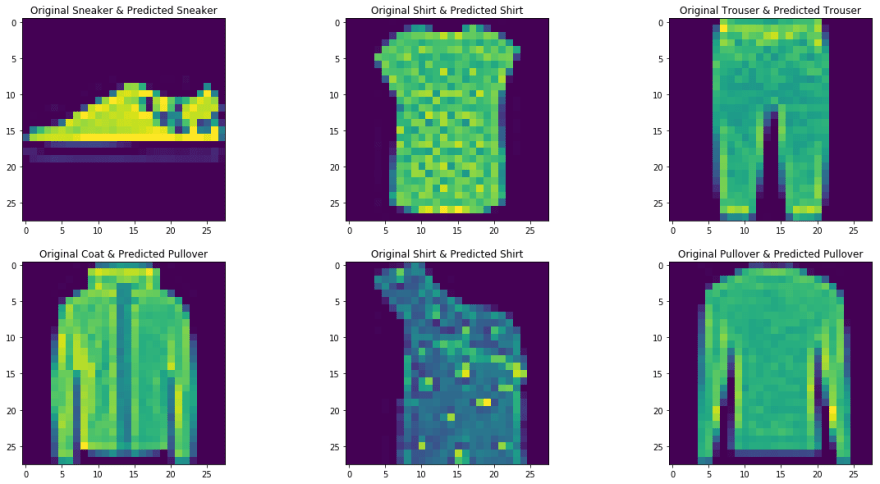
Aqui, consideramos o Fashion MNIST como nosso conjunto de dados de problemas. O conjunto de dados contém camisetas, calça, agasalho, vestidos, casacos, sandálias de dedo, camisas, sapatos, bolsas e sapatinhos. A tarefa é classificar uma determinada imagem nas classes acima mencionadas após treinar o modelo.
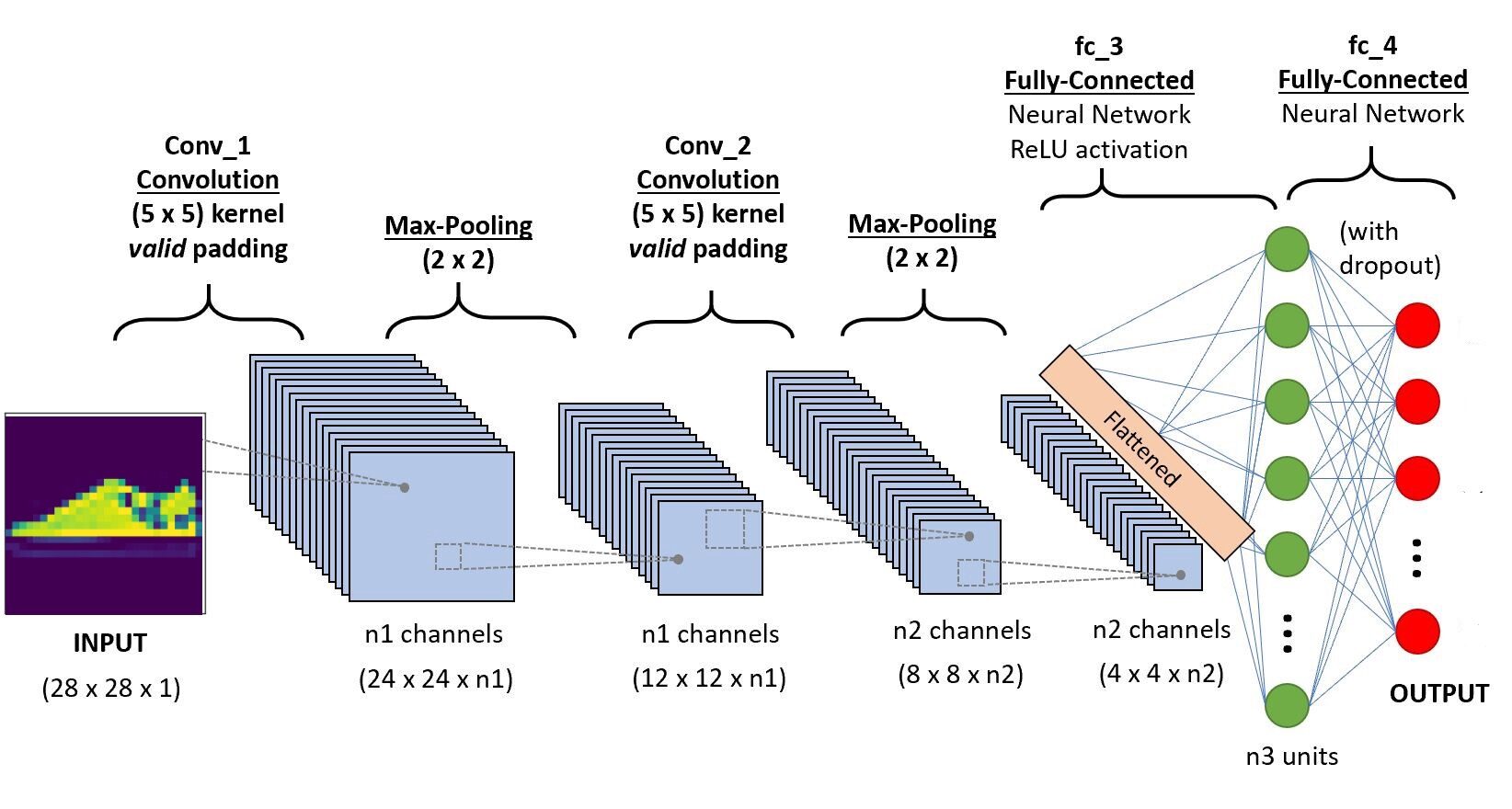
Vamos implementar o código no Google Colab, uma vez que fornecem o uso de recursos GPU gratuitos por um período fixo de tempo. Se você é novo no ambiente Colab e GPUs, verifique este blog para ter uma ideia melhor. Abaixo está a arquitetura da CNN que iremos construir.
Paso 1: Importe as bibliotecas necessárias
importar os importar tocha importar torchvision importar tarfile de transformações de importação de torchvision de torch.utils.data import random_split de torch.utils.data.dataloader import DataLoader import torch.nn as nn de torch.nn importar funcional como F da cadeia de importação de itertools
Paso -2: Baixando o conjunto de dados de teste e treinamento
train_set = torchvision.datasets.FashionMNIST("/usr", download = True, transformar =
transforms.Compose([transforms.ToTensor()]))
test_set = torchvision.datasets.FashionMNIST("./dados", download = True, train = False, transformar =
transforms.Compose([transforms.ToTensor()]))
Paso 3 Divisão do conjunto de treinamento para treinamento e validação
train_size = 48000 val_size = 60000 - train_size train_ds,val_ds = random_split(conjunto de trem,[train_size,val_size])
Paso 4 Carregue o conjunto de dados na memória usando o Dataloader
train_dl = DataLoader(train_ds,batch_size = 20, shuffle = True) val_dl = DataLoader(val_ds,batch_size = 20, shuffle = True) classes = train_set.classes
Agora vamos visualizar os dados carregados,
para imgs,rótulos em train_dl:
para img em imgs:
arr_ = np.squeeze(img)
plt.show()
pausa
pausa
Paso -5 Definindo a arquitetura
import torch.nn as nn
import torch.nn.functional as F
# definir a arquitetura CNN
classe Net(nn.Module):
def __init__(auto):
super(Internet, auto).__iniciar__()
#camada convolucional-1
self.conv1 = nn.Conv2d(1,6,5, preenchimento = 0)
#camada convolucional-2
self.conv2 = nn.Conv2d(6,10,5,preenchimento = 0)
# camada de pooling máxima
self.pool = nn.MaxPool2d(2, 2)
# Camada totalmente conectada 1
self.ff1 = nn.Linear(4*4*10,56)
# Camada totalmente conectada 2
self.ff2 = nn.Linear(56,10)
def frente(auto, x):
# adição de sequência de camadas convolucionais e de pooling máximo
#input dim-28 * 28 * 1
x = self.conv1(x)
# Após a operação de convolução, saída dim - 24*24*6
x = self.pool(x)
# Após a saída máxima da operação da piscina dim - 12*12*6
x = self.conv2(x)
# Após a saída da operação de convolução dim - 8*8*10
x = self.pool(x)
# saída máxima da piscina dim 4*4*10
x = x.view(-1,4*4*10) # Remodelar os valores para uma forma apropriada para a entrada da camada totalmente conectada
x = F.relu(self.ff1(x)) # Aplicando Relu à saída da primeira camada
x = F.sigmoid(self.ff2(x)) # Aplicando sigmóide à saída da segunda camada
retornar x
# criar uma CNN completa model_scratch = Net() imprimir(modelo)
# mover tensores para GPU se CUDA estiver disponível
se use_cuda:
model_scratch.cuda()
Paso 6: definição de função de perda
# Função de perda
import torch.nn as nn
import torch.optim as optim
criterion_scratch = nn.CrossEntropyLoss()
def get_optimizer_scratch(modelo):
optimizer = optim.SGD(model.parameters(),lr = 0.04)
otimizador de retorno
Paso 7: implementação do algoritmo de treinamento e validação
# Implementando o algoritmo de treinamento
trem def(n_epochs, carregadores, modelo, otimizador, critério, use_cuda, save_path):
"""devolve modelo treinado"""
# inicializar rastreador para perda mínima de validação
valid_loss_min = np.Inf
para época no intervalo(1, n_epochs + 1):
# inicializar variáveis para monitorar a perda de treinamento e validação
train_loss = 0.0
valid_loss = 0.0
# fase de trem #
# configurando o módulo para o modo de treinamento
model.train()
para batch_idx, (dados, alvo) em enumerar(carregadores['Comboio']):
# mover para GPU
se use_cuda:
dados, target = data.cuda(), target.cuda()
optimizer.zero_grad()
output = model(dados)
perda = critério(saída, alvo)
loss.backward()
optimizer.step()
train_loss = train_loss + ((1 / (batch_idx + 1)) * (loss.data.item() - perda de trem))
# validar o modelo #
# defina o modelo para o modo de avaliação
model.eval()
para batch_idx, (dados, alvo) em enumerar(carregadores['válido']):
# mover para GPU
se use_cuda:
dados, target = data.cuda(), target.cuda()
output = model(dados)
perda = critério(saída, alvo)
valid_loss = valid_loss + ((1 / (batch_idx + 1)) * (loss.data.item() - valid_loss))
# imprimir estatísticas de treinamento / validação
imprimir('Época: {} t Perda de treinamento: {:.6f} tValidation Loss: {:.6f}'.formato(
época,
perda de trem,
valid_loss
))
## Se a perda de valiação diminuiu, então salvando o modelo
if valid_loss <= valid_loss_min:
imprimir('Perda de validação diminuída ({:.6f} --> {:.6f}). Salvando modelo ... '. Formato(
valid_loss_min,
valid_loss))
torch.save(model.state_dict(), save_path)
valid_loss_min = valid_loss
modelo de retorno
Paso 8: Fase de treinamento e avaliação
num_epochs = 15
model_scratch = train(num_epochs, loaders_scratch, model_scratch, get_optimizer_scratch(model_scratch),
criterion_scratch, use_cuda, 'model_scratch.pt')
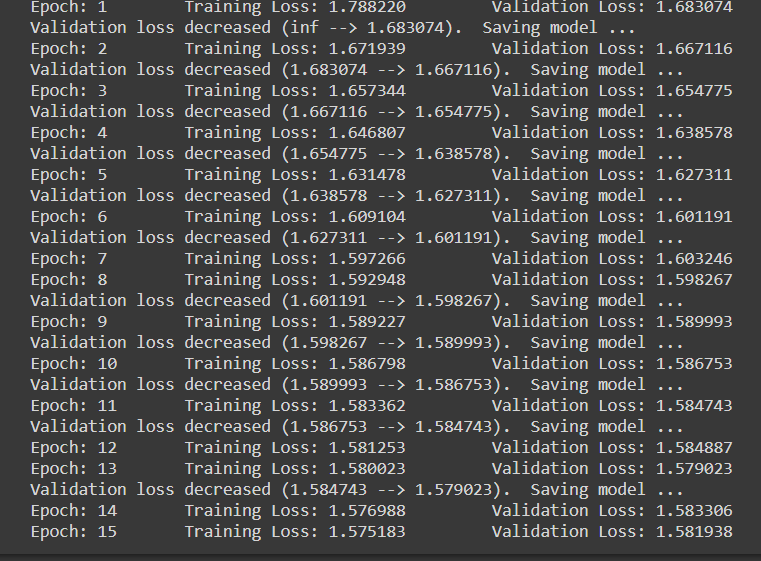
Observe que, a cada vez que a perda de validação diminui, estamos salvando o estado do modelo.
Paso 9 Fase de teste
teste de def(carregadores, modelo, critério, use_cuda):
# monitorar a perda e a precisão do teste
test_loss = 0.
correto = 0.
total = 0.
# defina o módulo para o modo de avaliação
model.eval()
para batch_idx, (dados, alvo) em enumerar(carregadores['teste']):
# mover para GPU
se use_cuda:
dados, target = data.cuda(), target.cuda()
# Passar para a frente: computar saídas previstas passando entradas para o modelo
output = model(dados)
# calcular a perda
perda = critério(saída, alvo)
# atualizar perda média de teste
test_loss = test_loss + ((1 / (batch_idx + 1)) * (loss.data.item() - test_loss))
# converter probabilidades de saída em classe prevista
pred = output.data.max(1, keepdim = True)[1]
# compare as previsões com o rótulo verdadeiro
correto + = np.sum(np.squeeze(pred.eq(target.data.view_as(pred)),eixo = 1).CPU().entorpecido())
total + = data.size(0)
imprimir('Perda de teste: {:.6f}n'.format(test_loss))
imprimir(Precisão do 'nTest: %2d %% (%2d/-)' % (
100. * correto / total, correto, total))
# carregue o modelo que obteve a melhor precisão de validação
model_scratch.load_state_dict(torch.load('model_scratch.pt'))
teste(loaders_scratch, model_scratch, criterion_scratch, use_cuda)

Paso 10 Teste com uma amostra
A função definida para testar o modelo com uma única imagem.
def Predict_image(img, modelo):
# Converter para um lote de 1
xb = img.unsqueeze(0)
# Obtenha previsões do modelo
yb = modelo(xb)
# Escolha o índice com maior probabilidade
_, preds = tocch.max(yb, dim = 1)
# imprimindo a imagem
plt.imshow(img.squeeze( ))
#retornando o rótulo da classe relacionado à imagem
return train_set.classes[preds[0].item()]
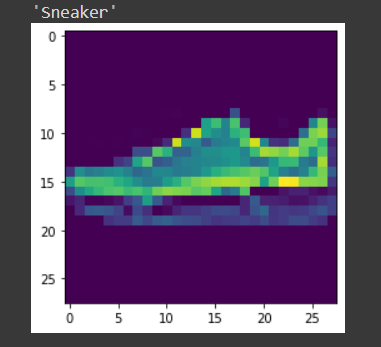
img,label = test_set[9] Predict_image(img,model_scratch)
conclusão
Aqui, discutimos brevemente as principais operações em uma rede neural convolucional e sua arquitetura. Um modelo de rede neural convolucional simples também foi implementado para dar uma ideia melhor do caso de uso prático. Você pode encontrar o código implementado em meu Repositório GitHub. O que mais, você pode melhorar o desempenho do modelo implantado aumentando o conjunto de dados, usando técnicas de regularização, como normalização em lote e abandono em camadas totalmente conectadas da arquitetura. O que mais, observe que modelos CNN pré-treinados também estão disponíveis, que foram treinados com grandes conjuntos de dados. Usando esses modelos de última geração, você sem dúvida alcançará as melhores pontuações métricas para um determinado problema.
Referências
- https://www.youtube.com/watch?v = EHuACSjijbI – Jovian
- https://www.youtube.com/watch?v = 2-Ol7ZB0MmU&t = 1503s- Uma introdução amigável a redes neurais convolucionais e reconhecimento de imagem
Sobre o autor
Meu nome é adwait dathan, Atualmente, estou cursando meu mestrado em Inteligência Artificial e Ciência de Dados. Sinta-se à vontade para se conectar comigo por meio Linkedin.
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





