Este artigo foi publicado como parte do Data Science Blogathon
Introdução
Recorrente neuronal vermelho (RNN) foi um dos melhores conceitos introduzidos que poderia fazer uso de elementos de memória em nossa rede neural. Antes disso, tínhamos uma rede neural que podia se propagar para frente e para trás para atualizar os pesos e reduzir os erros na rede. Mas, como sabemos, muitos problemas no mundo real são temporários por natureza e altamente dependentes do tempo.
Muitos aplicativos de linguagem são sempre sequenciais e a próxima palavra em uma frase depende da anterior. Esses problemas foram resolvidos por um simples RNN. Mas se entendermos RNN, apreciamos o fato de que mesmo RNN não pode nos ajudar quando queremos rastrear as palavras que foram usadas anteriormente em nossa frase. Neste artigo, Vou discutir algumas das principais desvantagens do RNN e por que usamos um modelo melhor para a maioria dos aplicativos baseados em linguagem.
Compreendendo a retropropagação ao longo do tempo (BPTT)
RNN usa uma técnica chamada Backpropagation ao longo do tempo para backpropagate através da rede para ajustar seus pesos para que possamos reduzir o erro na rede. Tem o nome dele “através do tempo”, já que no RNN lidamos com dados sequenciais e cada vez que voltamos é como voltar no tempo para o passado. Aqui está como funciona o BPTT:
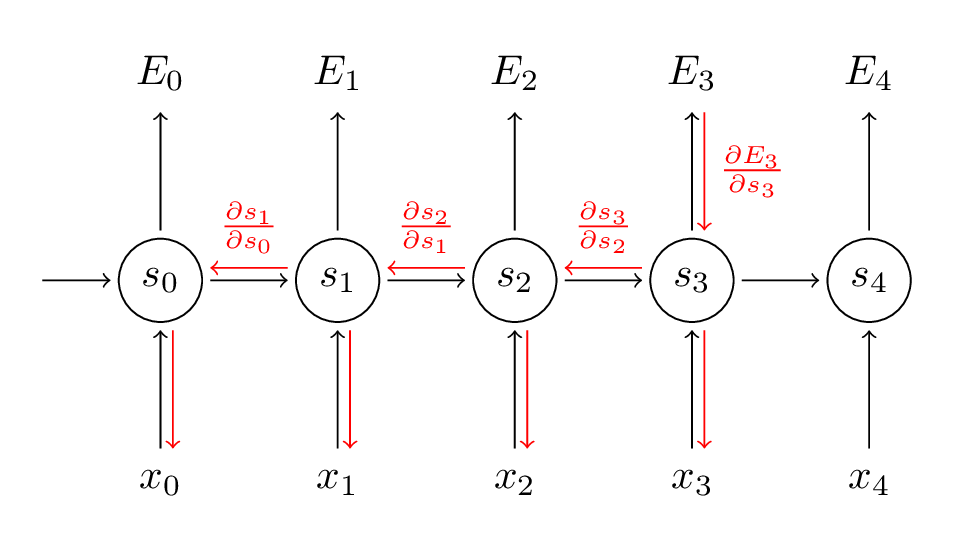
Fonte: (http://www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/)
Na etapa BPTT, calculamos a derivada parcial em cada peso na rede. Então, se estivermos no tempo t = 3, então consideramos a derivada de E3 em relação à de S3. Agora, x3 também está conectado a s3. Então, sua derivada também é considerada. Agora, se vemos que s3 está conectado a s2, então s3 depende do valor de s2 e aqui a derivada de s3 em relação a s2 também é considerada. Isso atua como uma regra da cadeia e nós acumulamos toda a dependência com seus derivados e usamos para calcular o erro.
No E3 temos um gradiente que é S3 e sua equação naquele momento é:
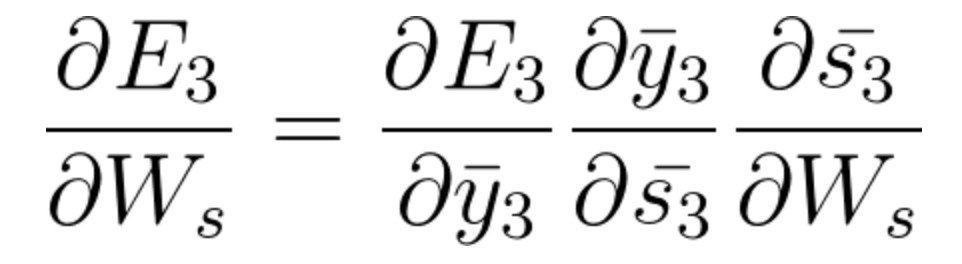
Agora também temos s2 associado a s3, então,
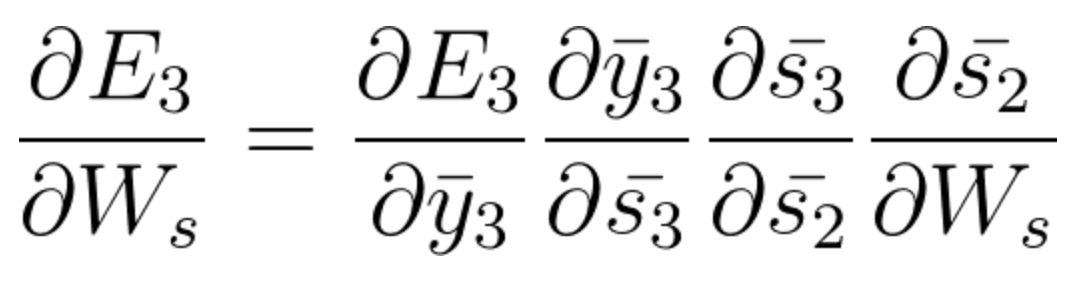
E s1 também está associado a s2 e, portanto, agora tudo s1, s2, s3 e tem efeito no E3,
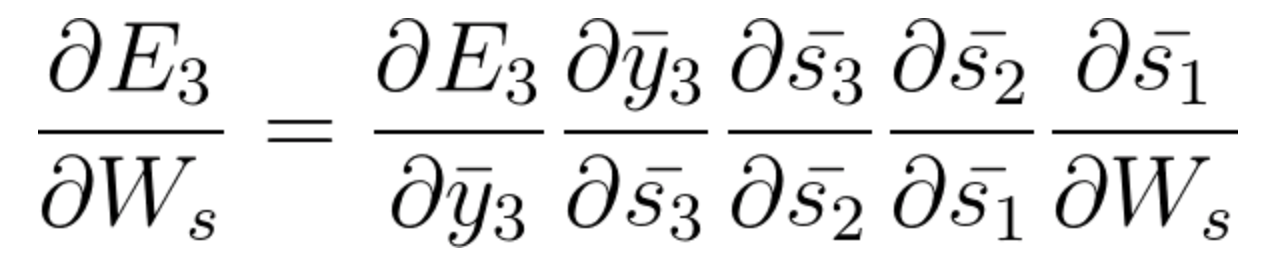
Ao acumular tudo, acabamos obtendo a seguinte equação que contribuiu com Ws para aquela rede no tempo t = 3,
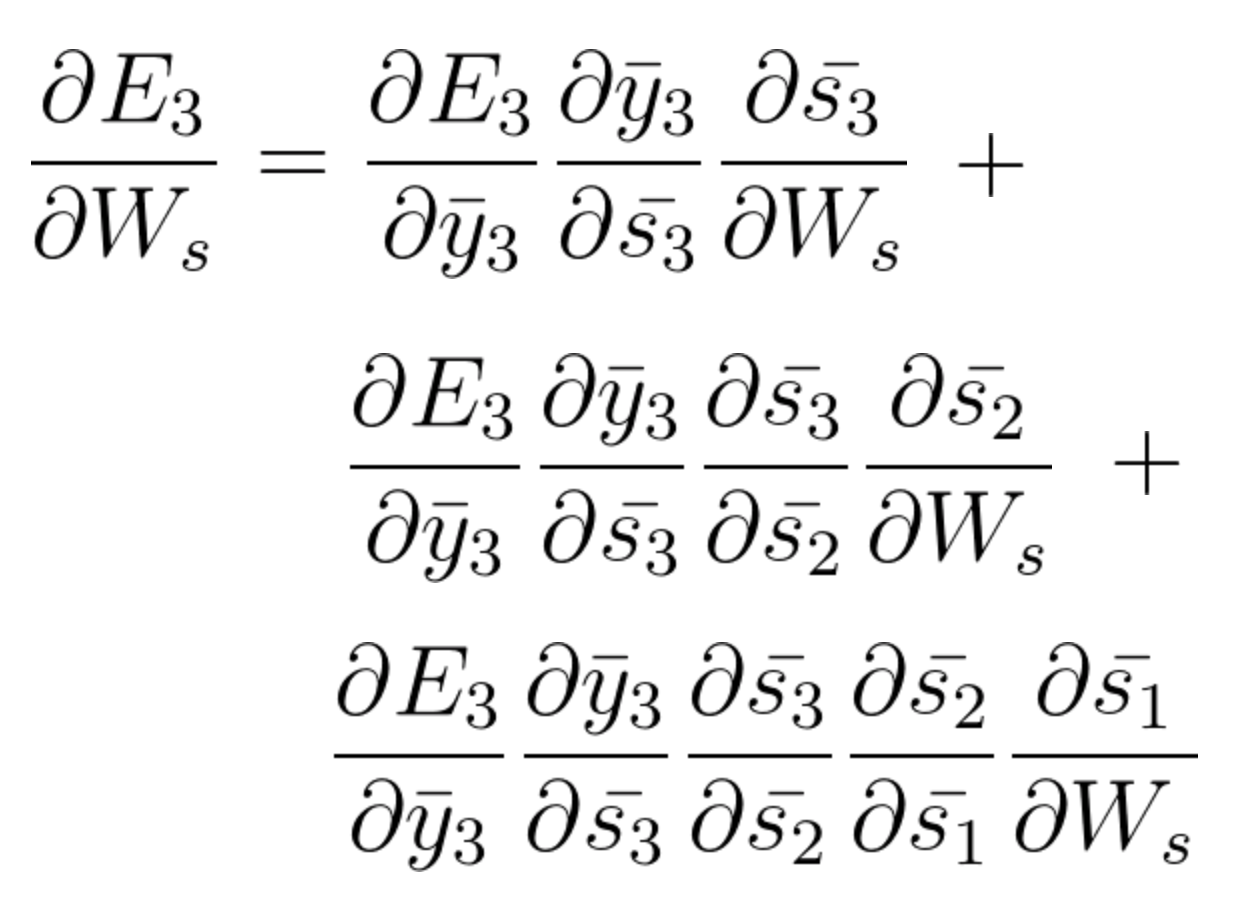
A equação geral para a qual encaixamos Ws em nossa rede BPTT pode ser escrita como,
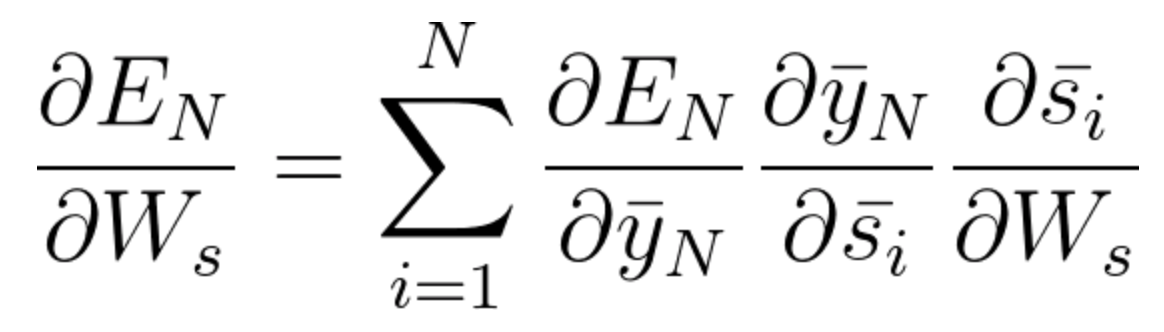
Agora, como temos notado, Wx também está associado à rede. Então, fazendo o mesmo, geralmente podemos escrever,
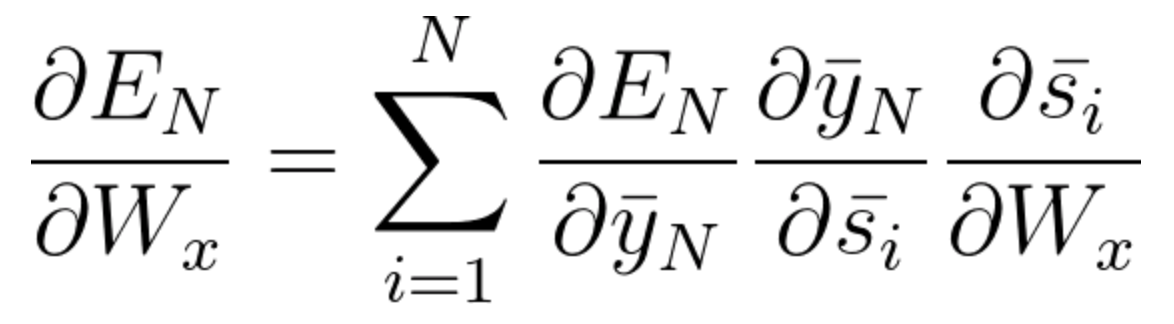
Agora que você entendeu como funciona o BPTT, é basicamente como o RNN ajusta seus pesos e reduz o erro. Agora, a principal falha aqui é que isso é basicamente apenas para uma pequena rede com 4 capas. Mas imagine se tivéssemos centenas de camadas e, de uma vez só, vamos dizer t = 100, acabaríamos calculando todas as derivadas parciais associadas à rede e isso é uma grande multiplicação e isso pode reduzir o valor geral a um valor muito pequeno ou valor minuto que pode ser inútil corrigir o erro. Este problema é chamado Problema de gradiente desaparecendo.
Problema de gradiente desaparecendo
Como todos sabemos, em RNN para prever uma saída usaremos uma função de ativação sigmóide para que possamos obter a saída de probabilidade para uma classe particular. Como vimos na seção anterior quando se trata de dizer E3, existe uma dependência de longo prazo. O problema ocorre quando tomamos a derivada e a derivada do sigmóide está sempre abaixo 0.25 e, portanto, quando multiplicamos muitos derivados juntos de acordo com a regra da cadeia, acabamos com um valor de vazamento de modo que não podemos usá-los para o cálculo do erro. .
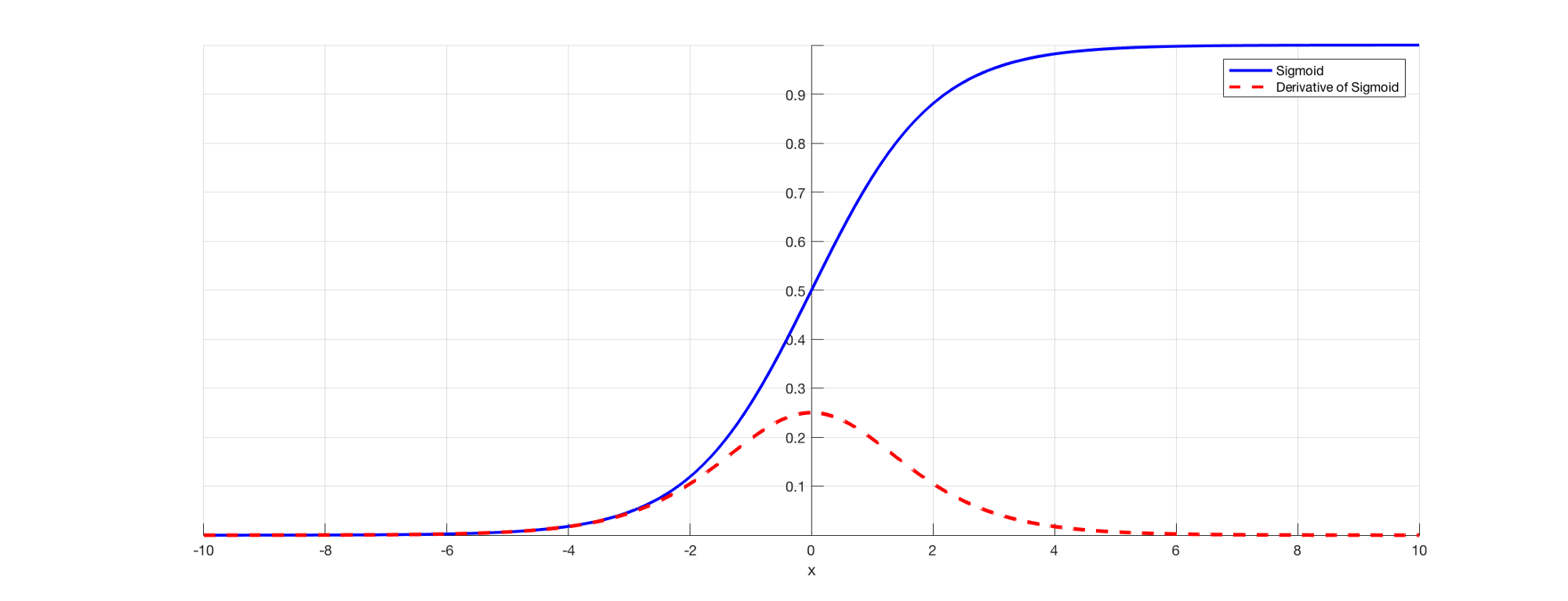
Fonte: (https://directiondatascience.com/the-vanishing-gradient-problem-69bf08b15484)
Portanto, pesos e vieses não serão atualizados corretamente e, conforme as camadas continuam a aumentar, caímos ainda mais nisso e nosso modelo não funciona corretamente e gera imprecisões em toda a rede.
Algumas maneiras de resolver este problema são inicializar a matriz de peso corretamente ou ir para algo como um ReLU em vez de funções sigmóides ou tanh.
Problema de gradiente explosivo
A explosão de gradiente é um problema onde o valor do gradiente se torna muito grande e isso acontece frequentemente quando inicializamos pesos maiores e podemos acabar com NaN. Se nosso modelo sofreu com este problema, não podemos atualizar os pesos de forma alguma. Mas felizmente, corte gradiente é um processo que podemos usar para este. Em um valor limite predefinido, nós cortamos o gradiente. Isso evitará que o valor do gradiente exceda o limite e nunca acabaremos com números grandes ou NaN.
Dependência de longo prazo das palavras
Agora, vamos considerar uma frase como, "As nuvens estão no ____". Nosso modelo RNN pode prever facilmente 'Sky’ aqui e isso é devido ao contexto das nuvens e logo vem como uma entrada para sua camada anterior. Mas pode não ser sempre assim.
Imagine se tivéssemos uma frase como: "Jane nasceu em Kerala. Jane costumava jogar pelo time de futebol feminino e também foi campeã nos exames estaduais. Jane fala ____ fluentemente “.
Esta é uma frase muito longa e o problema aqui é que, como humano, eu posso dizer isso, desde que Jane nasceu em Kerala e passou no exame do estado, é óbvio que você deve dominar o “malayalam” muito fluentemente. Mas, Como nossa máquina sabe sobre isso? No ponto em que o modelo deseja prever palavras, você pode ter esquecido o contexto de Kerala e mais sobre outra coisa. Este é o problema da dependência de longo prazo do RNN.
Unidirecional em RNN
Como comentamos anteriormente, RNN coleta dados sequencialmente e palavra por palavra ou letra por letra. Agora, quando tentamos prever uma palavra particular, não estamos pensando em seu contexto futuro. Quer dizer, digamos que temos algo como: "O mouse é muito bom. O mouse é usado para ____ para facilitar o uso de computadores “. Agora, se podemos viajar bidirecionalmente e também podemos ver o contexto futuro, podemos dizer que ‘Deslocamento’ é a palavra apropriada aqui. Mas, se for unidirecional, nosso modelo nunca viu computadores, então, Como você sabe se estamos falando sobre o mouse animal ou o mouse do computador?
Esses problemas são resolvidos posteriormente usando modelos de linguagem como BERT, onde podemos inserir frases completas e usar o mecanismo de autoatenção para entender o contexto do texto.
Use a memória de curto prazo de longo prazo (LSTM)
Uma maneira de resolver o problema de gradiente de vazamento e dependência de longo prazo de RNN é optar por redes LSTM. LSTM tem uma introdução a três portas chamadas portas de entrada, saída e esquecimento. Em que as portas do esquecimento se encarregam das informações que precisam passar pela rede. Desta forma, podemos ter memória de curto e longo prazo. Podemos passar as informações pela rede e recuperá-las mesmo em um estágio muito posterior para identificar o contexto de previsão. O diagrama a seguir mostra a rede LSTM.
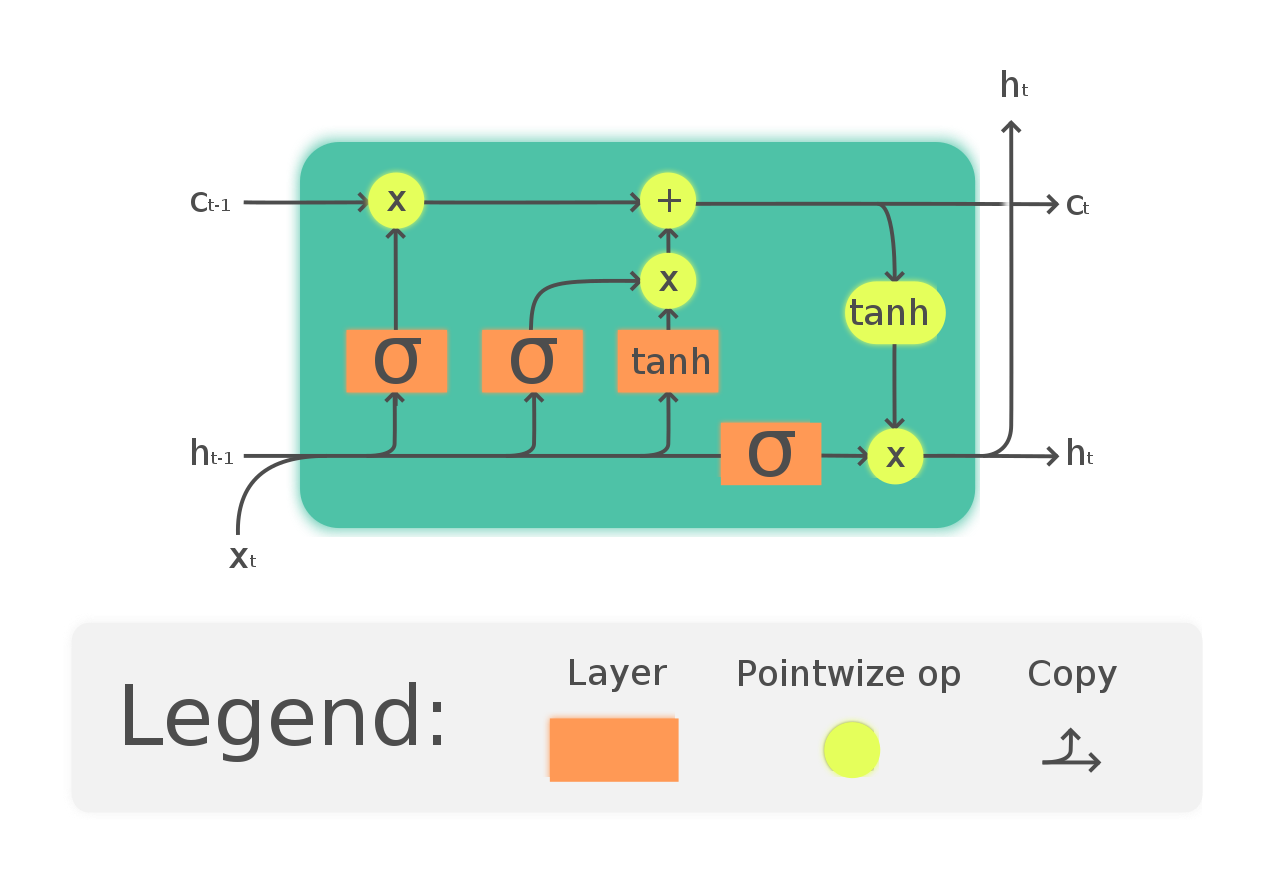
(https://en.wikipedia.org/wiki/Long_short-term_memory#/media/File:The_LSTM_Cell.svg)
Siga este tutorial para uma melhor compreensão e um exemplo intuitivo de LSTM: https://directiondatascience.com/illustrated-guide-to-lstms-and-gru-sa-step-by-step-explanation-44e9eb85bf21
Com sorte, agora você entendeu os problemas de usar um RNN e por que optamos por redes mais complexas como LSTM.
Referências
1.http: //www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/
2. https://analyticsindiamag.com/what-are-the-challenges-of-training-recurrent-neural-networks/
3. https://directiondatascience.com/the-vanishing-gradient-problem-69bf08b15484
4. https://en.wikipedia.org/wiki/Long_short-term_memory
5. https://www.udacity.com/course/deep-learning-nanodegree–nd101
6. Imagem de visualização: https://unsplash.com/photos/Sot0f3hQQ4Y
conclusão
Sinta-se à vontade para se conectar comigo em:
1. https://www.linkedin.com/in/siddharth-m-426a9614a/
2. https://github.com/Siddharth1698
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





