Introdução
El apilamiento es una técnica de aprendizaje por conjuntos que usa predicciones para múltiples nodos (por exemplo, kNN, árboles de decisión o SVM) para construir un nuevo modelo. Este modelo final se utiliza para realizar predicciones en el conjunto de datos de prueba.
***Video***
Observação: Se você está mais interessado em aprender conceitos em formato audiovisual, temos esse artigo completo explicado no vídeo abaixo. Sim, não é assim, você pode continuar lendo.
Então, lo que hacemos al apilar es tomar los datos de entrenamiento y ejecutarlos a través de múltiples modelos, M1 a Mn. Y todos estos modelos se conocen normalmente como aprendices básicos o modelos básicos. Y generamos predicciones a partir de estos modelos.
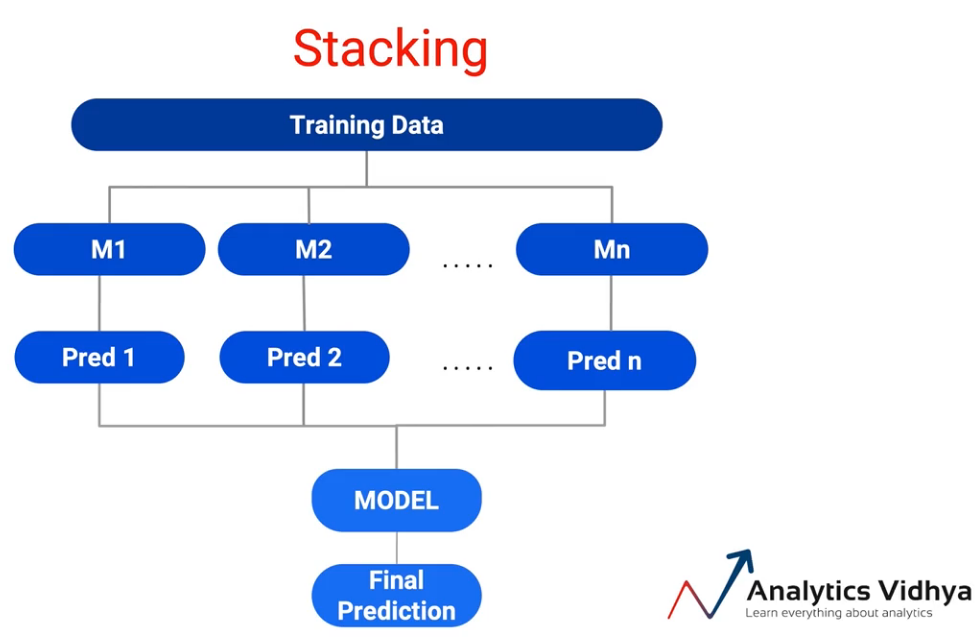
Portanto, Pred 1 a Pred n son las predicciones, y esta entrada se envía al modelo, en lugar de la votación máxima o promediada. Y el modelo los toma como entradas y nos da la predicción final. Y dependiendo de si fue un problema de regresión o un problema de clasificación, puedo elegir cuál es el modelo correcto para hacer esto. Então, el concepto de apilamiento es muy interesante y abre muchas posibilidades.
Pero apilar de esta manera abre un gran peligro de Sobreajuste el modelo porque estoy usando todos mis datos de entrenamiento para crear el modelo y también para crear predicciones en él.
Então, a pergunta é, ¿puedo volverme más inteligente y puedo usar los datos de entrenamiento y los datos de prueba de una manera diferente para reducir el peligro de sobreajuste? Y eso es lo que discutiremos en este artículo en particular. Então, lo que voy a cubrir es una de las formas más populares en las que se usa el apilamiento.
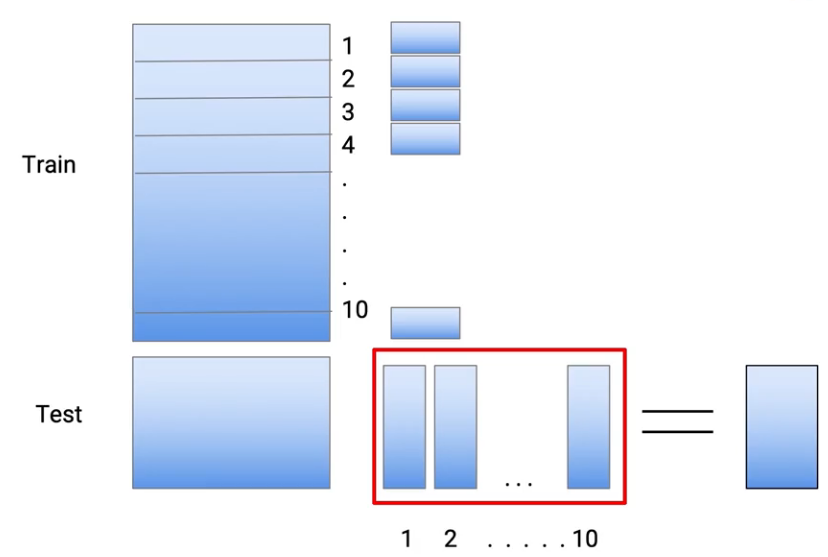
Digamos que tenemos estos conjuntos de datos de entrenamiento y prueba:
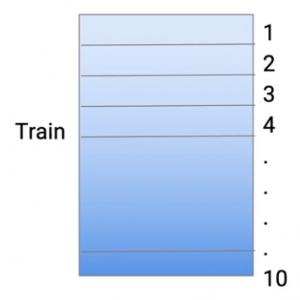
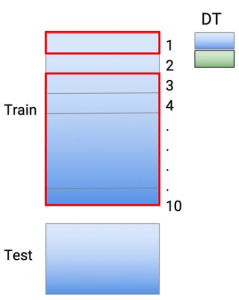
Y para reducir el sobreajuste, tomo los datos de mi tren y los divido en 10 partes. Así que esto se hace al azar. Así que tomo todo el conjunto de datos del tren y lo convierto en 10 conjuntos de datos más pequeños.
E agora, para reducir el sobreajuste, lo que hago es entrenar mi modelo en 9 de estas 10 partes y hago mis predicciones en la décima parte. Então, en este caso particular, hago mi entrenamiento de la parte 2 a la parte 10. Y digamos que estoy usando el árbol de decisiones como mis técnicas de modelado, así que entreno mi modelo y hago mis casos de predicciones, que estaban allí en la parte 1-
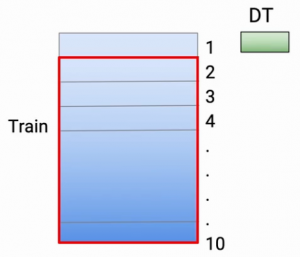
Então, la parte 1 es básicamente predicción. Então, el color verde representa la predicción, que hice en los puntos, que estaban en el conjunto de datos 1, hago el mismo ejercicio para cada una de estas partes. Então, para la parte 2, vuelvo a entrenar mi modelo usando la parte 1 de datos y la parte 3 a la parte 10 De dados. Y hago mis predicciones en la segunda parte.
Então, de esta manera, hago mis predicciones para todas estas 10 partes. Então, em resumo, cada una de estas predicciones proviene de un modelo que no había visto los mismos puntos de datos de trenes. Y para crear un conjunto de datos de prueba, utilizo todos los datos del tren. Assim que, de novo, entreno el modelo, que se realiza en todo el conjunto de datos del tren, y hago predicciones en la prueba.
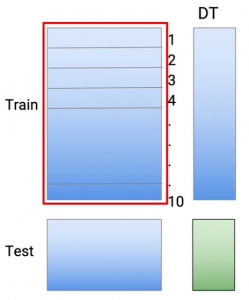
Então, si lo piensa, nós criamos 10 modelos para obtener las predicciones sobre los datos del tren y el undécimo modelo para obtener predicciones sobre los datos de prueba. Y todos estos son modelos de árboles de decisión. Então, esto me da un conjunto de predicciones o el equivalente de las predicciones que provenían del modelo M1.
Hago lo mismo con una segunda técnica de modelado. Digamos KNN. Então, novamente, el mismo concepto de que hago predicciones parte por parte de la parte 1 a la parte 10. Y nuevamente, para obtener predicciones en el conjunto de datos de prueba, ejecuto el undécimo modelo KNN.
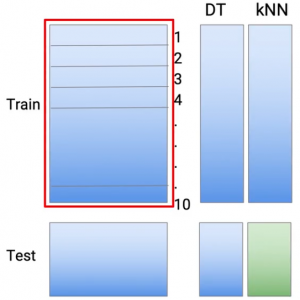
Hago lo mismo con la tercera parte, que podría ser una regresión lineal o logística, según el tipo de problema que esté manejando.
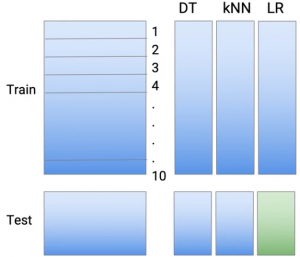
Então, estos son mis nuevos aprendices básicos de alguna manera. Ahora tengo predicciones de tres tipos diferentes de técnicas de modelado, pero he evitado el peligro de sobreajuste.
Agora eu posso perguntar, ¿por qué estoy usando 10? ¿Y qué tiene de sacrosanto este número 10? Así que no hay nada sacrosanto en el número 10. Se basa en el hecho de que si uso algo menos de dos o tres, no me da tanto beneficio. Y si tomo algo más que digamos 15 o 20, entonces mi número de cálculos aumenta. Así que solo una compensación entre reducir el sobreajuste y no aumentar mucho mi complejidad. También puedes seguir adelante con 7 você 8, no hay nada específico que tengas que ver con 10.
Así que siéntete libre de elegir tu propio número. Podrían ser siete, podrían ser ocho, pero normalmente veo personas que usan entre cinco y quizás 11, 12, dependiendo de la situación. Y verá esto una y otra vez en conjunto que hay pautas, pero al final del día, debe tomar decisiones basadas en cuántos recursos tiene, cuánta complejidad hay y cuáles son sus pautas de producción y ¿Qué puedes pagar en producción?
Así que he tomado 10 como exemplo, pero también puedes usar cualquier otro número. Volviendo a apilar. Así que teníamos estas predicciones de tres tipos diferentes de modelos. Así que este se convierte en mi nuevo conjunto de datos de trenes.
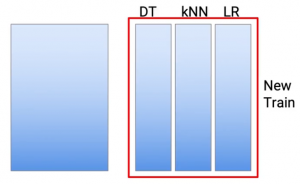
y las predicciones que tenía en mi prueba se convierten en mi nuevo conjunto de datos de prueba. Y ahora creo un modelo en estos conjuntos de datos de prueba y tren para llegar a mis predicciones finales.

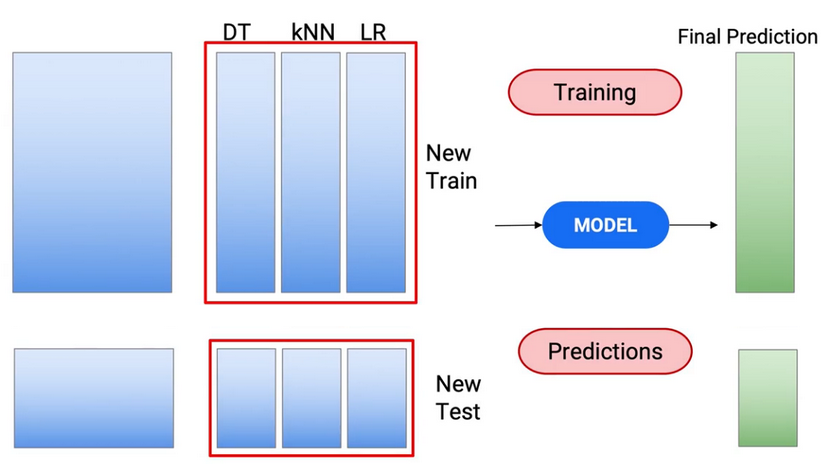
Así que usamos este nuevo tren para crear el modelo de tren y hacer predicciones en mi prueba para obtener mis predicciones finales de prueba.
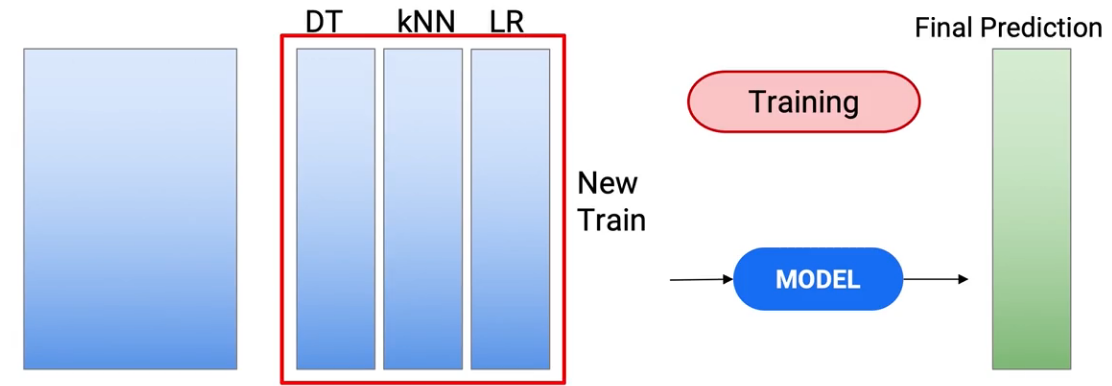

Então, esta es la variante más popular de apilamiento, que se usa en la industria. Veamos algunas variaciones más, que se pueden utilizar:
1. Utilice las funciones proporcionadas junto con las nuevas predicciones.
Así que actualmente, si lo piensas bien, solo hemos utilizado las nuevas predicciones como características de nuestro modelo final. Lo que también puedo hacer es incluir las funciones originales junto con la nueva función. Então, en lugar de usar este recuadro rojo para entrenar y probar,
Puedo usar la función completa para entrenar mi modelo, las funciones que estaban allí originalmente y las predicciones que salieron. Así que estoy abriendo mi conjunto de datos de trenes para incluir más funciones.
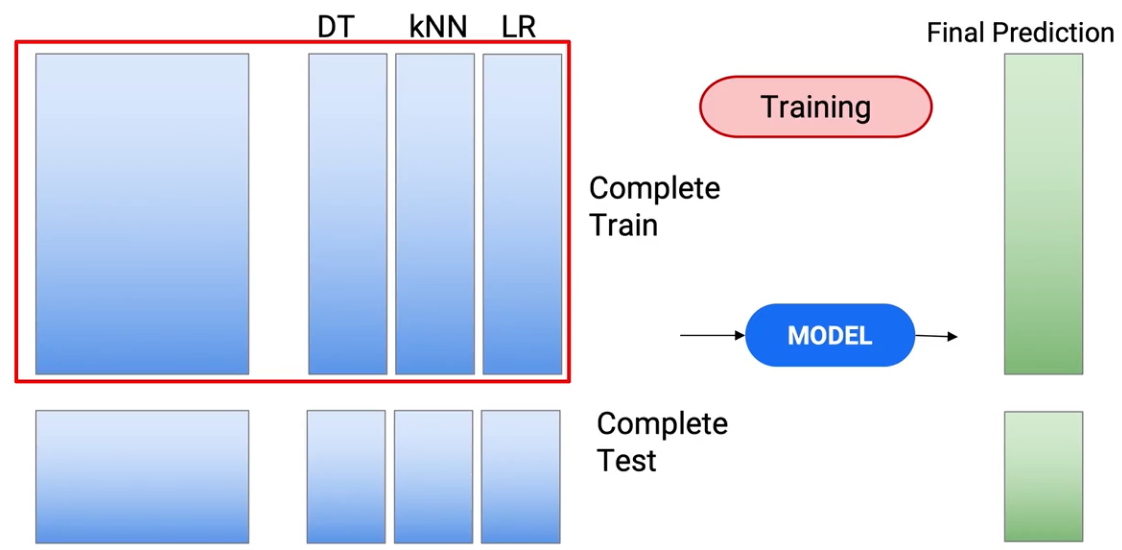
Y hago lo mismo con las pruebas. Y esto me da un nuevo conjunto de predicciones.

Así que esa es una forma en la que también se implementa el apilamiento.
2. Genere múltiples predicciones para probarlas y agréguelas
La segunda forma de implementar el apilamiento es hacer múltiples predicciones en el conjunto de datos de prueba y agregarlas. De novo, si recuerdas lo que hicimos, creamos estas 10 predicciones para cada uno de estos archivos de tren y usamos uno de los modelos completos para crear las predicciones del conjunto de datos de prueba. Agora, lo que también podría hacer es hacer esto para 10, cada uno de estos 10 Modelos, que fueron creados, y luego agregarlos en lugar de hacerlo en todo el modelo.
Então, novamente, los mismos modelos que estaba usando para hacer las predicciones para 1, 2 y cada uno de estos conjuntos de datos, utilizo el mismo modelo para crear mis predicciones para la prueba. Y luego los promedié para llegar a mi prueba final, que usaré para el modelo final.
Novamente, como dije, todos estos son modelos diferentes y diferentes formas de implementar el apilamiento y el ensamblaje. Tiene total libertad para ser creativo y encontrar nuevas formas de reducir el sobreajuste. Por tanto, los objetivos generales son asegurarse de que:
- Nuestra precisión aumenta
- La complejidad permanece lo más baja posible
- Y evitamos el sobreajuste
Siempre que hagas algo para lograr estos tres objetivos, sería una estrategia válida, verdade?
3. Aumentar el número de niveles para apilar modelos.
Então, la tercera variante de apilamiento es donde, en lugar de mantener un solo modelo en todas las predicciones, terminé creando capas de modelos. Então, por exemplo, en este caso particular-
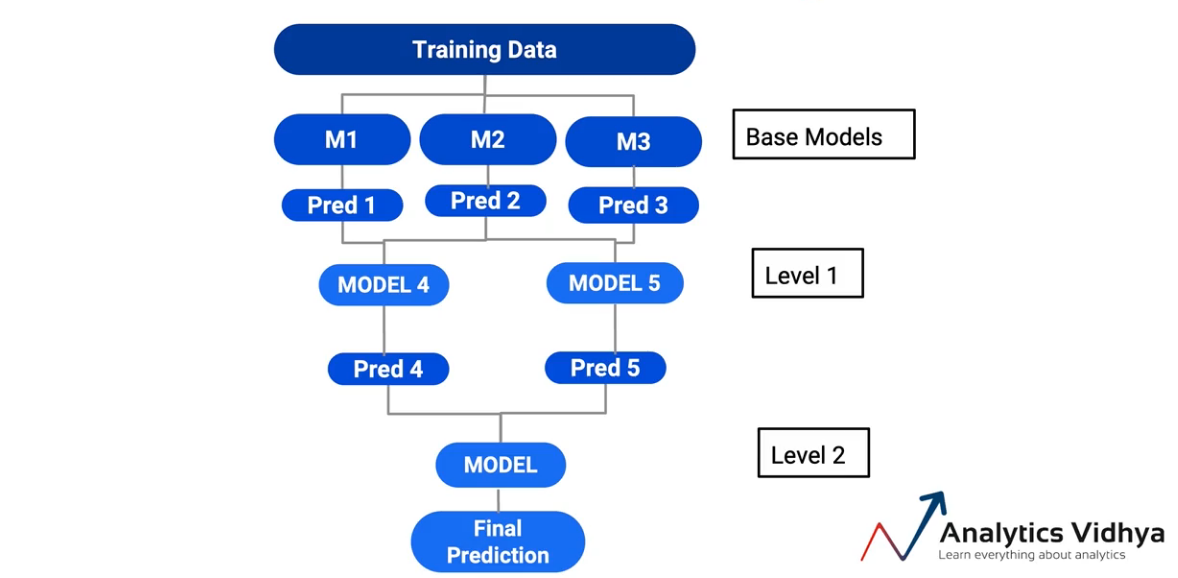
Tomé predicciones de M1 y M2 y las pasé a otro modelo, M4. de forma similar, tomó predicciones del Modelo 2 y el Modelo 3 y las alimentó al Modelo 5. Y el modelo final era en realidad un modelo en el Modelo 4 y el Modelo 5. Así que terminé creando dos niveles de modelos en mis modelos base. Y de nuevo, es una forma válida de apilar. Y dependiendo de la situación, puede elegir estos.
Así que estas eran las variantes de apilamiento, como dije, siempre y cuando se asegure de que se cumpla con los tres requisitos del ensamble, lo cual nosotros: asegurándonos de que no sobreajuste sus modelos, asegurándose de mantener los modelos como simple como sea posible, y aumenta su precisión. Recuerde que puede ser lo más creativo posible con el apilado o cualquier otro modelado de conjuntos si solo tiene en cuenta estos tres puntos.
Notas finais
He cubierto algunas variantes para apilar. Así que siéntete libre de usarlos. Y con esas tres limitaciones o con esos pensamientos, cualquier variación que se te ocurra sería una variación válida.
Se você está procurando iniciar sua jornada de ciência de dados e deseja todos os tópicos sob o mesmo teto, sua busca para aqui. Dê uma olhada no AI e ML BlackBelt certificados da DataPeaker Mais Programa
Se você tiver alguma dúvida, deixe-me saber na seção de comentários!





