Este artigo foi publicado como parte do Data Science Blogathon
Introdução
VGG- Network es un modelo de convolucional neuronal vermelhoRedes Neurais Convolucionais (CNN) são um tipo de arquitetura de rede neural projetada especialmente para processamento de dados com uma estrutura de grade, como fotos. Eles usam camadas de convolução para extrair recursos hierárquicos, o que os torna especialmente eficazes em tarefas de reconhecimento e classificação de padrões. Graças à sua capacidade de aprender com grandes volumes de dados, As CNNs revolucionaram campos como a visão computacional.. propuesto por K. Simonyan y A. Zisserman no artigo “Redes convolucionais muito profundas para reconhecimento de imagem em grande escala” [1]. Esta arquitetura alcançou precisão de teste entre os 5 melhor de 92,7% na ImageNet, que tem mais que 14 milhões de imagens pertencentes a 1000 aulas.
Es una de las arquitecturas famosas en el campo del aprendizado profundoAqui está o caminho de aprendizado para dominar o aprendizado profundo em, Uma subdisciplina da inteligência artificial, depende de redes neurais artificiais para analisar e processar grandes volumes de dados. Essa técnica permite que as máquinas aprendam padrões e executem tarefas complexas, como reconhecimento de fala e visão computacional. Sua capacidade de melhorar continuamente à medida que mais dados são fornecidos a ele o torna uma ferramenta fundamental em vários setores, da saúde.... Substitua os filtros de kernel grande por 11 e 5 na primeira e segunda camada, respectivamente, mostrou melhorias em relação à arquitetura AlexNet, com vários filtros de tamanho de kernel de 3 × 3 um após o outro. Ele foi treinado por semanas e estava usando a GPU NVIDIA Titan Black.
Arquitetura VGG16
La entrada a la neuronal vermelhoAs redes neurais são modelos computacionais inspirados no funcionamento do cérebro humano. Eles usam estruturas conhecidas como neurônios artificiais para processar e aprender com os dados. Essas redes são fundamentais no campo da inteligência artificial, permitindo avanços significativos em tarefas como reconhecimento de imagem, Processamento de linguagem natural e previsão de séries temporais, entre outros. Sua capacidade de aprender padrões complexos os torna ferramentas poderosas.. de convolución es una imagen RGB de tamaño fijo 224 × 224. O único pré-processamento que faz é subtrair os valores RGB médios, que se calculan en el conjunto de datos de TreinamentoO treinamento é um processo sistemático projetado para melhorar as habilidades, Conhecimento ou habilidades físicas. É aplicado em várias áreas, como esporte, Educação e desenvolvimento profissional. Um programa de treinamento eficaz inclui planejamento de metas, prática regular e avaliação do progresso. A adaptação às necessidades individuais e a motivação são fatores-chave para alcançar resultados bem-sucedidos e sustentáveis em qualquer disciplina...., de cada pixel.
Mais tarde, a imagem passa por uma pilha de camadas convolucionais (Conv.), Onde existem filtros com um campo receptivo muito pequeno que é 3 × 3, qual é o menor tamanho para capturar a noção de esquerda / direito, Acima / baixa, e parte central.
Em uma das configurações, também usa filtros de convolução 1 × 1, que pode ser observada como uma transformação linear dos canais de entrada seguida por não linearidade. Passadas convolucionais são fixadas em 1 pixel; el relleno espacial de la entrada de la capa convolucionalA camada convolucional, Fundamental em redes neurais convolucionais (CNN), É usado principalmente para processamento de dados com estruturas semelhantes a grades, como fotos. Essa camada aplica filtros que extraem recursos relevantes, como bordas e texturas, permitindo que o modelo reconheça padrões complexos. Sua capacidade de reduzir a dimensionalidade dos dados e manter informações essenciais o torna uma ferramenta fundamental nas tarefas de visão computacional.. es tal que la resoluçãoo "resolução" refere-se à capacidade de tomar decisões firmes e atingir metas estabelecidas. Em contextos pessoais e profissionais, Envolve a definição de metas claras e o desenvolvimento de um plano de ação para alcançá-las. A resolução é fundamental para o crescimento pessoal e o sucesso em várias áreas da vida, pois permite superar obstáculos e manter o foco no que realmente importa.... espacial se mantiene después de la convolución, quer dizer, o recheio é 1 pixel para 3 × 3 Conv. capas.
Mais tarde, o agrupamento espacial é realizado por cinco camadas de agrupamento máximo, 16 que seguem algumas das Conv. capas, mas nem todas as conv. camadas são seguidas por agrupamento máximo. Este agrupamento máximo é feito em uma janela de 2 × 2 píxeis, com passo 2.
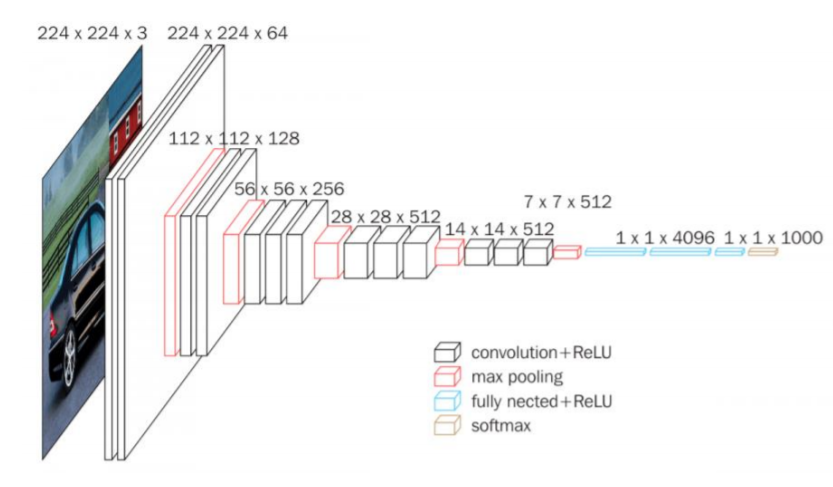
A arquitetura contém uma pilha de camadas convolucionais que têm uma profundidade diferente em diferentes arquiteturas que são seguidas por três camadas Fully-Connected (FC): os dois primeiros FC têm 4096 canais, cada um e o terceiro FC realiza uma classificação de 1000 rotas e, portanto, contém 1000 canais que é um para cada classe.
A última camada é a camada soft-max. A configuração das camadas totalmente conectadas é semelhante em todas as redes.
Todas as camadas ocultas são equipadas com retificação (retomarA função de ativação do ReLU (Unidade linear retificada) É amplamente utilizado em redes neurais devido à sua simplicidade e eficácia. Definido como ( f(x) = máx.(0, x) ), O ReLU permite que os neurônios disparem apenas quando a entrada é positiva, o que ajuda a mitigar o problema do desbotamento do gradiente. Seu uso demonstrou melhorar o desempenho em várias tarefas de aprendizado profundo, tornando o ReLU uma opção...) não linear. O que mais, aquí una de las redes contiene NormalizaçãoA padronização é um processo fundamental em várias disciplinas, que busca estabelecer padrões e critérios uniformes para melhorar a qualidade e a eficiência. Em contextos como engenharia, Educação e administração, A padronização facilita a comparação, Interoperabilidade e compreensão mútua. Ao implementar normas, a coesão é promovida e os recursos são otimizados, que contribui para o desenvolvimento sustentável e a melhoria contínua dos processos.... de respuesta local (LRN), tal normalização não melhora o desempenho no conjunto de dados treinado, mas seu uso leva a um maior consumo de memória e tempo de cálculo.
Resumo da Arquitetura:
• A entrada para o modelo é uma imagem RGB de tamanho fixo 224 × 224224 × 224
• O pré-processamento consiste em subtrair a média do valor RGB do conjunto de treinamento de cada pixel
• Camadas convolucionais 17
– Passo fixo para 1 pixel
– o recheio é 1 pixel para 3 × 33 × 3
• Camadas de agrupamento espacial
– Esta camada não conta para a profundidade da web por convenção
– O agrupamento espacial é feito usando camadas máximas de agrupamento
– o tamanho da janela é 2 × 22 × 2
– Stride definido para 2
– Convnets usados 5 camadas máximas de agrupamento
• Camadas totalmente conectadas:
• 1º: 4096 (retomar).
▪ 2do: 4096 (retomar).
▪ 3º: 1000 (Softmax).
Configuração de arquitetura
O seguinte figura"Figura" é um termo usado em vários contextos, Da arte à anatomia. No campo artístico, refere-se à representação de formas humanas ou animais em esculturas e pinturas. Em anatomia, designa a forma e a estrutura do corpo. O que mais, em matemática, "figura" está relacionado a formas geométricas. Sua versatilidade o torna um conceito fundamental em várias disciplinas.... contiene la configuración de la red neuronal de convolución de la red VGG con el
próximas camadas:
• VGG-11
• VGG-11 (LRN)
• VGG-13
• VGG-16 (Conv1)
• VGG-16
• VGG-19
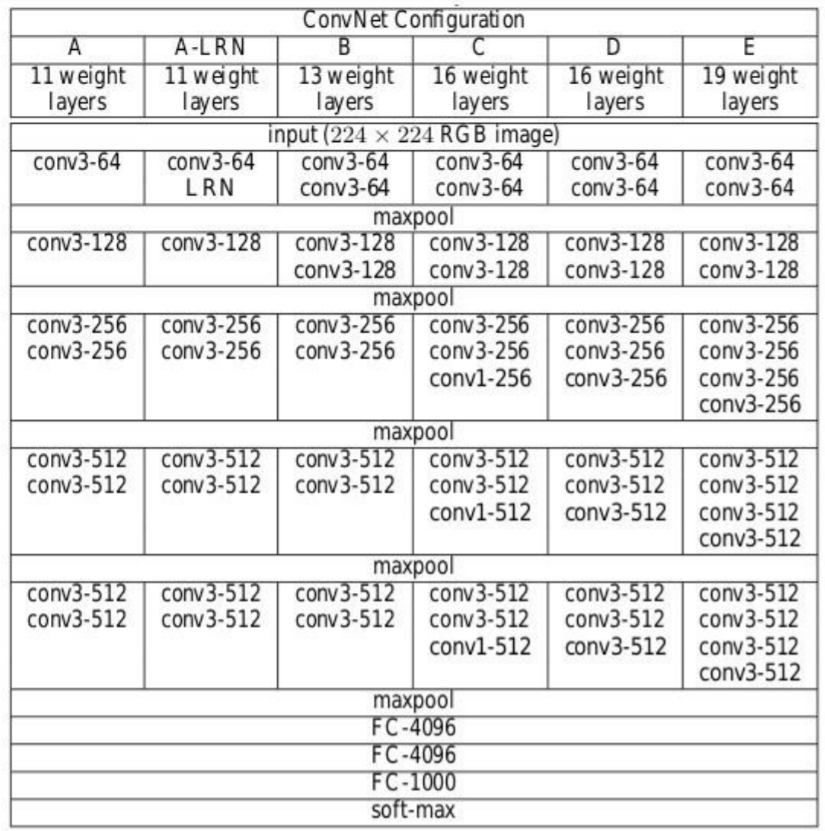
Fonte: “Redes convolucionais muito profundas para reconhecimento de imagem em grande escala”
As configurações de rede neural convolucional são mencionadas acima, uma por coluna.
A seguir, as redes são chamadas por seus nomes (A - E). Todas as configurações seguem o design tradicional e diferem apenas em profundidade: a partir de 11 camadas de peso na rede A que são 8 Conv. e 3 camadas FC a 19 camadas de peso na rede E que é 16 Conv. e 3 Camadas FC. A largura de cada conv. camada é o número de canais é bem pequeno, que começa de 64 na primeira camada e, em seguida, continua a aumentar por um fator de 2 após cada camada de agrupamento máximo até atingir 512.
El número de parametroso "parametros" são variáveis ou critérios usados para definir, medir ou avaliar um fenômeno ou sistema. Em vários domínios, como a estatística, Ciência da Computação e Pesquisa Científica, Os parâmetros são essenciais para estabelecer normas e padrões que orientam a análise e interpretação dos dados. Sua seleção e manuseio adequados são cruciais para obter resultados precisos e relevantes em qualquer estudo ou projeto.... para cada configuración se describe a continuación. Embora tenha grande profundidade, o número de pesos nas redes não é maior do que o número de pesos em uma rede mais rasa com maior conv. larguras de camada e campos receptivos

Treinamento
• La Função de perdaA função de perda é uma ferramenta fundamental no aprendizado de máquina que quantifica a discrepância entre as previsões do modelo e os valores reais. Seu objetivo é orientar o processo de treinamento, minimizando essa diferença, permitindo assim que o modelo aprenda de forma mais eficaz. Existem diferentes tipos de funções de perda, como erro quadrático médio e entropia cruzada, cada um adequado para diferentes tarefas e... es una regresión logística multinomial
• El algoritmo de aprendizaje es un descenso de gradienteGradiente é um termo usado em vários campos, como matemática e ciência da computação, descrever uma variação contínua de valores. Na matemática, refere-se à taxa de variação de uma função, enquanto em design gráfico, Aplica-se à transição de cores. Esse conceito é essencial para entender fenômenos como otimização em algoritmos e representação visual de dados, permitindo uma melhor interpretação e análise em... estocástico (SGD) minilote com base no espalhamento de impulso.
· O tamanho do lote era 256
· O impulso foi 0,9
• RegularizaçãoA regularização é um processo administrativo que busca formalizar a situação de pessoas ou entidades que atuam fora do marco legal. Esse procedimento é essencial para garantir direitos e deveres, bem como promover a inclusão social e econômica. Em muitos países, A regularização é aplicada em contextos migratórios, Trabalhista e Tributário, permitindo que aqueles que estão em situação irregular tenham acesso a benefícios e se protejam de possíveis sanções....
· Decadência de peso L2 (o multiplicador de penalidade era 0,0005)
· A exclusão para as duas primeiras camadas totalmente conectadas é definida como 0.5
• Taxa de Aprendizagem
· Inicial: 0.01
· Quando a precisão do conjunto de validação parou de melhorar, se reduzir a 10.
• Embora tenha um maior número de parâmetros e também profundidade em relação ao Alexnet, A CNN exigiu menos vezes para a função de perda convergir devido a
· Pequenos grãos convolucionais e maior regularização devido à grande profundidade.
· Pré-inicialização de certas camadas.
• Tamanho da imagem de treinamento
· S é o menor lado da imagem reescalada isotopicamente
· Duas abordagens para estabelecer S
▪ Fix S, conhecido como treinamento em escala única
▪ Aqui S = 256 y S = 384
▪ Variar S, conhecido como treinamento multi-escala
▪ S de [Smin, Smax] onde Smin = 256, Smax = 512
– Mais tarde 224 × 224224 × 224
A imagem foi cortada aleatoriamente a partir da imagem redimensionada da iteração SGD.
Características principais
• VGG16 tem um total de 16 camadas que têm alguns pesos.
• Apenas camadas de convolução e agrupamento são usadas.
• Sempre use um núcleo de 3 x 3 para convolução. 20
• Tamanho 2 × 2 piscina máxima.
• 138 milhões de parâmetros.
• Treinado em dados ImageNet.
• Tem uma precisão de 92,7%.
• Outra versão que é VGG 19, tem um total de 19 camadas com pesos.
• É uma arquitetura de aprendizado profundo muito boa para benchmarking em qualquer tarefa específica.
• Redes pré-treinadas para VGG são de código aberto, para que eles possam ser comumente usados para vários tipos de aplicações.
Vamos implementar o VGG Net
Primeiro, criar mapeamento de filtro para cada versão da rede VGG. Consulte a imagem de configuração acima para o número de filtros. Quer dizer, criar um dicionário para a versão com uma tecla chamada vgg11, VGG13, VGG16, VGG19 e criar uma lista de acordo com o número de filtros em cada versão, respectivamente. Aqui “M” na lista é conhecido como operação maxpool.
import torch
import torch.nn as nn
VGG_types = {
"VGG11": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"VGG13": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"VGG16": [64,64,"M",128,128,"M",256,256,256,"M",512,512,512,"M",512,512,512,"M",],
"VGG19": [64,64,"M",128,128,"M",256,256,256,256,"M",512,512,512,512,
"M",512,512,512,512,"M",],}
Cree una variávelEm estatística e matemática, uma "variável" é um símbolo que representa um valor que pode mudar ou variar. Existem diferentes tipos de variáveis, e qualitativo, que descrevem características não numéricas, e quantitativo, representando quantidades numéricas. Variáveis são fundamentais em experimentos e estudos, uma vez que permitem a análise de relações e padrões entre diferentes elementos, facilitando a compreensão de fenômenos complexos.... global para mencionar la versión de la arquitectura. Em seguida, crie uma classe chamada VGG_net com entradas como in_channels e num_classes. Aceita entradas como uma série de canais de imagem e o número de classes de saída.
Inicializar camadas sequenciais, quer dizer, na sequência, Camada linear -> ReLU–> Pular.
Em seguida, crie uma função chamada create_conv_layers que leva a configuração da arquitetura VGGnet como entrada, que é a lista que criamos anteriormente para diferentes versões. Quando você encontra a carta “M” da lista acima, realiza a operação MaxPool2d.
VGGType = "VGG16"
Classe VGGnet(nn.Module):
def __init__(auto, in_channels=3, num_classes = 1000):
super(VGGnet, auto).__iniciar__()
self.in_channels = in_channels
self.conv_layers = self.create_conv_layers(VGG_types[VGGType])
self.fcs = nn. Sequencial( nn. Linear(512 * 7 * 7, 4096), nn. ReLU(), nn. Abandono escolar(p=0,5), nn. Linear(4096, 4096), nn. ReLU(), nn. Abandono escolar(p=0,5), nn. Linear(4096, num_classes), ) def frente(auto, x): x = self.conv_layers(x) x = x.remodelar(x.shape[0], -1) x = self.fcs(x) return x def create_conv_layers(auto, arquitetura): camadas = [] in_channels = self.in_channels for x in architecture: se tipo(x) == int: out_channels = x layers += [ nn. Conv2d( in_channels=in_channels, out_channels=out_channels, kernel_size=(3, 3), passo=(1, 1), preenchimento =(1, 1), ), nn. BatchNorm2d(x), nn. ReLU(), ] in_channels = x elif x == "M": camadas += [nn. MaxPool2d(kernel_size=(2, 2), passo=(2, 2))] retorno nn. Sequencial(*camadas)
Uma vez feito isso, escrever um pequeno código de teste para verificar se nossa implementação está funcionando bem.
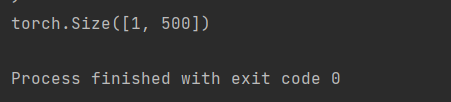
No seguinte código de teste, o número de classes dadas é 500.
if __name__ == "__a Principal__":
dispositivo = "milagres" se torch.cuda.is_available() outro "CPU"
modelo = VGGnet(in_channels=3, num_classes=500).para(dispositivo)
# imprimir(modelo)
x = tocha.randn(1, 3, 224, 224).para(dispositivo)
imprimir(modelo(x).forma)
A saída deve ser assim.:
Se você quiser ver a arquitetura de rede, você pode descompactá-lo imprimir (modelo) declaração de código anterior. Você também pode tentar versões diferentes alterando as versões do VGG na variável VGGType.
O código completo pode ser acessado aqui:
https://github.com/BakingBrains/Deep_Learning_models_implementation_from-scratch_using_pytorch_/blob/main/VGG.py
[1]. K. Simonyan y A. Zisserman: Redes convolucionais muito profundas para reconhecimento de imagem em grande escala, abril de 2015, DOI: https://arxiv.org/pdf/1409.1556.pdf
Obrigado
A mídia mostrada neste artigo não é propriedade da DataPeaker e é usada a critério do autor.





