Introdução: –
Aprendizado de máquina está impulsionando as maravilhas tecnológicas de hoje, como carros sem motorista, voo espacial, acreditação de imagem e voz. Apesar disto, um profissional de ciência de dados precisaria de um grande volume de dados para construir um modelo robusto e confiável de aprendizado de máquina para tais problemas de negócios..

A mineração de dados ou coleta de dados é um passo muito primitivo no ciclo de vida da ciência de dados.. De acordo com as exigências do negócio, você pode precisar coletar dados de fontes como servidores, registros, bases de dados, API, Repositórios on-line ou web SAP ou web.
Ferramentas de raspagem da Web como o Selenium podem raspar um grande volume de dados, como texto e imagens, em um tempo relativamente curto.
Tabela de conteúdo: –
- O que é raspagem de web?
- Por que a raspagem da Web
- Como a raspagem da Web é útil
- O que é selênio?
- Configuração e ferramentas
- Implementação de demolição de imagens da Web usando Selenium Python
- Navegador Chrome sem cabeça
- Colocando-o completamente
- Notas finais
O que é Web Scraping? : –
Eliminação da Web, também chamado “rastreio” o “aranha” é a técnica para coletar automaticamente dados de uma fonte on-line, em geral forma de um portal web. Embora o Web Scrapping seja uma maneira fácil de obter um grande volume de dados em um período relativamente curto de tempo, adiciona estresse ao servidor onde a fonte está hospedada.
Essa também é uma das principais razões pelas quais muitos sites não possibilitam raspar tudo em seu portal web.. Apesar disto, desde que não interrompa a função principal da fonte on-line, é bastante aceitável.
Por que a raspagem da Web? –
Há um grande volume de dados na web que as pessoas podem usar para atender às necessidades dos negócios.. Por isso, alguma ferramenta ou técnica é necessária para coletar essas informações da web. E é aí que entra o conceito de Web-Scrapping..
Qual é o uso da Web Scraping? –
A raspagem da Web pode nos ajudar a extrair uma enorme quantidade de dados do cliente, produtos, pessoas, mercado de ações, etc.
Os dados coletados de um portal web podem ser usados, como um portal de e-commerce, portais de emprego, canais de mídia social para entender padrões de compra de clientes, comportamento de atrito dos trabalhadores e sentimentos do cliente, ea lista continua.
As bibliotecas ou frameworks mais populares usados no Python para Web – Scrapping é BeautifulSoup, Scrappy e Selênio.
Neste post, vamos falar sobre a eliminação da web usando Selênio em Python. E a cereja no topo vamos ver como podemos coletar imagens da web que você pode usar para criar dados de trem para o seu projeto de deep learning..
O que é selênio?
Selênio é uma ferramenta de automação de código aberto baseada na Web. Selênio é usado principalmente para testes na indústria, mas também pode ser usado para raspar o tecido. Usaremos o navegador Chrome, mas você pode experimentá-lo em qualquer navegador, é quase o mesmo.

Agora vamos ver como usar selênio para raspagem da Web.
Configuração e ferramentas: –
- Instalação:
- Instale o selênio usando pip
pip instalar selênio
- Instale o selênio usando pip
- Baixe o driver do Chrome:
Para baixar drivers web, você pode selecionar qualquer um dos seguintes métodos:- Você pode baixar diretamente o driver do Chrome a partir do seguinte link:
https://chromedriver.chromium.org/downloads - Ou você pode baixá-lo diretamente usando a próxima linha de código:motorista = webdriver. Cromar (ChromeDriverManager (). instalar ())
- Você pode baixar diretamente o driver do Chrome a partir do seguinte link:
Você pode encontrar documentação completa sobre selênio aqui. A documentação é autoexplicativa, por isso não deixe de lê-lo para tirar proveito do selênio com Python.
Os seguintes métodos nos ajudarão a encontrar itens em uma página da Web (esses métodos retornarão uma lista):
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
Agora, escrever um código Python para extrair imagens da web.
Implementação de demolição de imagens da Web usando Selenium Python: –
Paso 1: – Bibliotecas de importação
import os
import selenium
from selenium import webdriver
import time
from PIL import Image
import io
import requests
from webdriver_manager.chrome import ChromeDriverManager
from selenium.common.exceptions import ElementClickInterceptedException
Paso 2: – Instalar driver
#Instalar driver motorista = webdriver. Cromar(ChromeDriverManager().instalar())
Paso 3: – Especifique a URL de pesquisa
#Especificar URL de pesquisa search_url="https://www.google.com/search?q={q}&tbm=isch&tbs=sul:fc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAAAAAAAAAABAC&biw=1251&bih=568" motorista.obter(search_url.formato(q='Car'))
Eu usei esta URL específica para que você não tenha problemas por usar imagens com direitos autorais ou licenciadas. Caso contrário, você pode usar https://google.com também como uma URL de pesquisa.
Em seguida, procuramos por Carro em nossa URL de pesquisa. Cole o link no driver.obter função (“Seu link aqui”) e executar a célula. Isso abrirá uma nova janela de navegador para esse link.
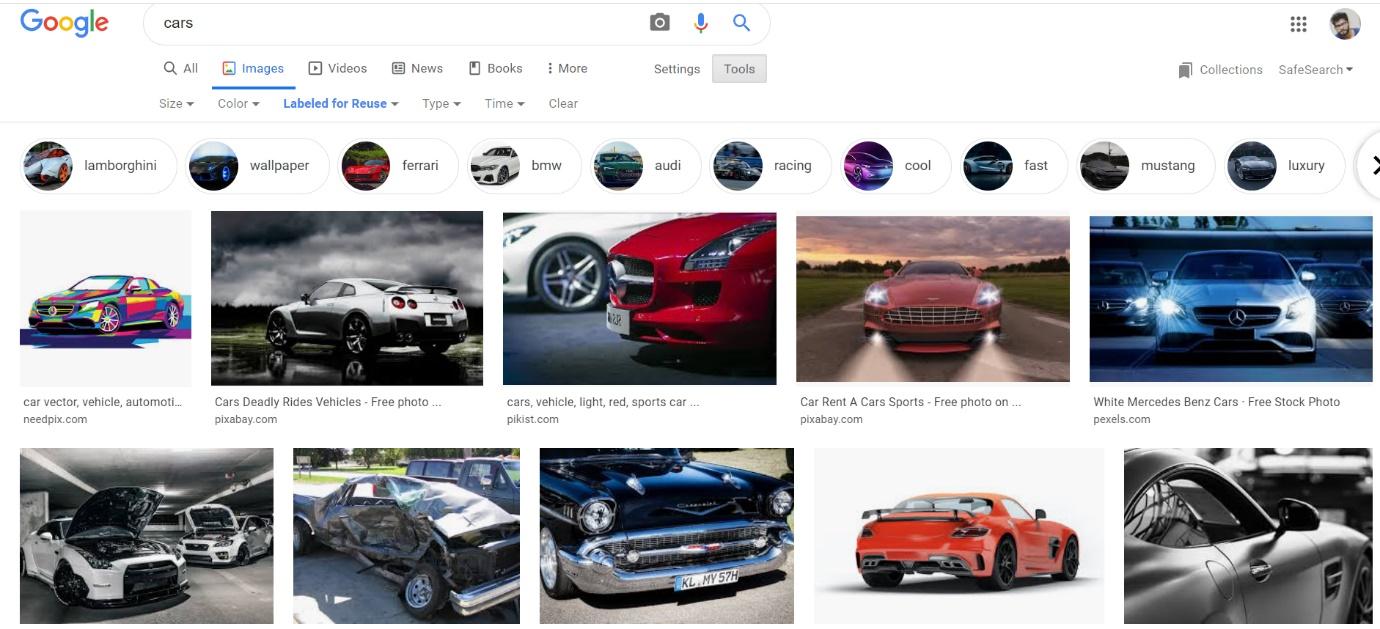
Paso 4: – Role até a parte inferior da página.
#Role até o final da página
driver.execute_script("janela.scrollTo(0, document.body.scrollHeight);")
hora de dormir(5)#sleep_between_interactions
Esta linha de código nos ajudaria a chegar ao fundo da página. E então nós damos a ele um tempo de descanso de 5 segundos para que não tenhamos problemas, onde estamos tentando ler itens da página, que ainda não está carregado.
Paso 5: – Localize as imagens a serem raspadas da página.
#Localize as imagens a serem raspadas da página atual
imgResults = driver.find_elements_by_xpath("//img[contém(@class,'Q4LuWd')]")
totalResults=len(imgResults)
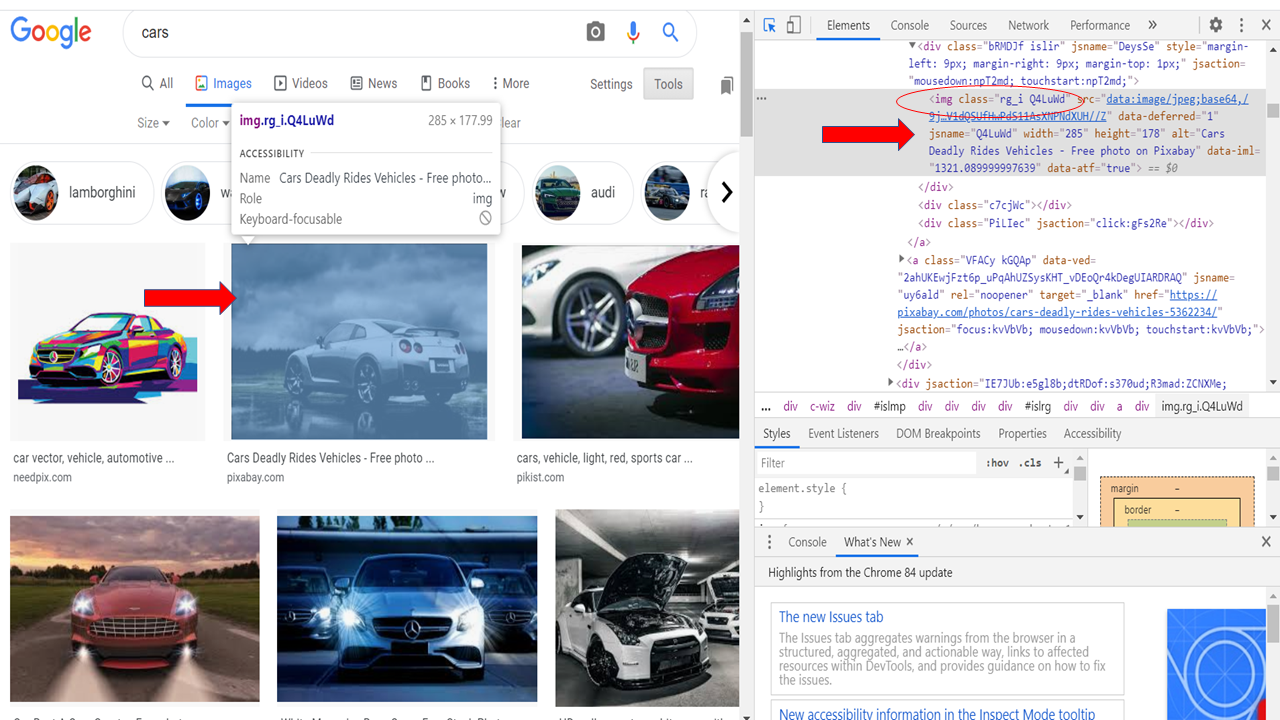
Agora vamos procurar todos os links de imagem presentes nessa página em particular. Vamos criar um “pronto” para salvar esses links. Então, para fazer isso, ir para a janela do navegador, clique com o botão direito do mouse na página e selecione 'inspecionar item'’ ou ativar ferramentas de desenvolvimento usando Ctrl + Mudança + eu.
Agora identifique qualquer atributo como uma classe, Eu iria, etc. O que é comum em todas essas imagens.
No nosso caso, classe = "'Q4LuWd" é comum em todas essas imagens.
Paso 6: – Extrair o respectivo link de cada imagem
Como podemos, as imagens exibidas na página ainda são as miniaturas, não a imagem original. Então, para baixar cada imagem, devemos clicar em cada miniatura e extrair as informações relevantes respectivamente para essa imagem.
#Clique em cada imagem para extrair seu link correspondente para baixar
img_urls = conjunto()
para eu no faixa(0,len(imgResults)):
img=imgResults[eu]
Experimente:
img.click()
hora de dormir(2)
actual_images = driver.find_elements_by_css_selector('img.n3VNCb')
para actual_image no actual_images:
E se actual_image.get_attribute('src') e 'https' no actual_image.get_attribute('src'):
img_urls.add(actual_image.get_attribute('src'))
exceto ElementClickInterceptedException ou ElementNotInteractableException Como errar:
imprimir(errar)
Então, no trecho de código acima, estamos executando as seguintes tarefas:
- repetir cada miniatura e, em seguida, clicar nele.
- Faça nosso navegador dormir durante 2 segundos (: P).
- Encontre a tag HTML exclusiva correspondente a essa imagem para colocá-la na página
- Ainda temos mais de um resultado para uma imagem em particular. Mas estamos todos interessados no link para baixar essa imagem.
- Então, nós iterar através de cada resultado para essa imagem e extrair o atributo 'src’ dele e, em seguida, vemos se “https” está presente no 'src’ ou não. Uma vez que regularmente o link da web começa com 'https'.
Paso 7: – Baixe e salve cada imagem para o diretório de destino
os.chdir('C:/Qurantine/Blog/WebScrapping/Dataset1')
baseDir=os.getcwd()
para eu, url no enumerar(img_urls):
file_name = f"{eu:150}.jpg"
Experimente:
image_content = requests.get(url).conteúdo
exceto Exceção Como e:
imprimir(f"ERRO - NÃO FOI POSSÍVEL BAIXAR {url} - {e}")
Experimente:
image_file = io. BytesIO(image_content)
imagem = Imagem.open(image_file).converter('RGB')
file_path = os.path.join(baseDir, nome do arquivo)
com abrir(file_path, 'wb') Como f:
imagem.salvar(f, "JPEG", qualidade=85)
imprimir(f"SALVOU - {url} - Em: {file_path}")
exceto Exceção Como e:
imprimir(f"ERRO - NÃO PODERIA SALVAR {url} - {e}")
Agora, em resumo, você extraiu a imagem para o seu projeto 😀
Observação: – Uma vez que você tenha escrito o código certo, o navegador não é essencial, pode coletar dados sem um navegador, o que é chamado de janela de navegador sem cabeça, por isso, substituir o código a seguir com o anterior.
Navegador Chrome sem cabeça
#Navegador cromado sem cabeça
a partir de selénio importar webdriver
opts = webdriver.ChromeOptions()
opts.headless =Verdade
driver =webdriver. Cromar(ChromeDriverManager().instalar())
Para este caso, o navegador não será executado em segundo plano, o que é muito útil na implementação de uma solução na produção.
Vamos colocar todo esse código em uma função para torná-lo mais organizacável e implementar a mesma ideia para baixar. 100 imagens para cada categoria (como um exemplo, Automóveis, Cavalos).
E desta vez escreveríamos nosso código usando a ideia de cromo sem cabeça..
Juntando tudo:
Paso 1: importar todas as bibliotecas indispensáveis
importar os
importar selénio
a partir de selénio importar webdriver
importar Tempo
a partir de PIL importar Imagem
importar Io
importar Solicitações
a partir de webdriver_manager.cromado importar ChromeDriverManager
os.chdir('C:/Qurantine/Blog/WebScrapping')
Paso 2: instalar o driver Chrome
#Instalar o driver opts=webdriver. Opções de Chrome() opta.headless=Verdade motorista = webdriver. Cromar(ChromeDriverManager().instalar() ,opções=opts)
Nesta etapa, instalamos um driver Chrome e usamos um navegador sem cabeça para raspar a web.
Paso 3: especificar a URL de pesquisa
search_url = "https://www.google.com/search?q={q}&tbm=isch&tbs=sul:fc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAAAAAAAAAABAC&biw=1251&bih=568" motorista.obter(search_url.formato(q='Car'))
Usei esta URL específica para extrair imagens livres de royalties.
Paso 4: escreve uma função para trazer o cursor para a parte inferior da página
def scroll_to_end(motorista):
driver.execute_script("janela.scrollTo(0, document.body.scrollHeight);")
hora de dormir(5)#sleep_between_interactions
Este trecho de código irá rolar para baixo da página.
Paso 5. Digite uma função para obter a URL de cada imagem.
#sem problemas de licença
def getImageUrls(nome,totalImgs,motorista):
search_url = "https://www.google.com/search?q={q}&tbm=isch&tbs=sul:fc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAAAAAAAAAABAC&biw=1251&bih=568"
motorista.obter(search_url.formato(q=nome))
img_urls = conjunto()
img_count = 0
results_start = 0
enquanto(img_count<totalImgs): #Extrair imagens reais agora
scroll_to_end(motorista)
thumbnail_results = driver.find_elements_by_xpath("//img[contém(@class,'Q4LuWd')]")
totalResults=len(thumbnail_results)
imprimir(f"Fundar: {totalResults} resultados de pesquisa. Extração de links de{results_start}:{totalResults}")
para img no thumbnail_results[results_start:totalResults]:
img.click()
hora de dormir(2)
actual_images = driver.find_elements_by_css_selector('img.n3VNCb')
para actual_image no actual_images:
E se actual_image.get_attribute('src') e 'https' no actual_image.get_attribute('src'):
img_urls.add(actual_image.get_attribute('src'))
img_count=len(img_urls)
E se img_count >= totalImgs:
imprimir(f"Fundar: {img_count} links de imagem")
pausa
outro:
imprimir("Fundar:", img_count, "procurando mais links de imagem ...")
load_more_button = driver.find_element_by_css_selector(".mye4qd")
driver.execute_script("document.querySelector('.mye4qd').clique();")
results_start = len(thumbnail_results)
Retorna img_urls
esta função retornaria uma lista de urls para cada categoria (como um exemplo, Carros, Cavalos, etc.)
Paso 6: digitar uma função para baixar cada imagem
def downloadImages(folder_path,nome do arquivo,url):
Experimente:
image_content = requests.get(url).conteúdo
exceto Exceção Como e:
imprimir(f"ERRO - NÃO FOI POSSÍVEL BAIXAR {url} - {e}")
Experimente:
image_file = io. BytesIO(image_content)
imagem = Imagem.open(image_file).converter('RGB')
file_path = os.path.join(folder_path, nome do arquivo)
com abrir(file_path, 'wb') Como f:
imagem.salvar(f, "JPEG", qualidade=85)
imprimir(f"SALVOU - {url} - Em: {file_path}")
exceto Exceção Como e:
imprimir(f"ERRO - NÃO PODERIA SALVAR {url} - {e}")
Este trecho de código baixará a imagem de cada URL.
Paso 7: – digitar uma função para salvar cada imagem para o diretório de destino
def salvarInDestFolder(googleNames,destDir,totalImgs,motorista):
para nome no Lista(googleNames):
path=os.path.join(destDir,nome)
E se não os.path.isdir(caminho):
os.mkdir(caminho)
imprimir('Caminho atual',caminho)
totalLinks=getImageUrls(nome,totalImgs,motorista)
imprimir('TotalLinks',totalLinks)
E se totalLinks é Nenhum:
imprimir('imagens não encontradas para :',nome)
Prosseguir
outro:
para eu, ligação no enumerar(totalLinks):
file_name = f"{eu:150}.jpg"
downloadImages(caminho,nome do arquivo,ligação)
googleNames=['Carro','cavalos']
destDir=f'./Dataset2/'
totalImgs=5
saveInDestFolder(googleNames,destDir,totalImgs,motorista)
este trecho de código salvará cada imagem para o diretório de destino.
Notas finais
Tentei explicar a web scraping usando Selênio com Python da maneira mais simples possível.. Sinta-se livre para comentar sobre suas consultas. Ficarei mais do que feliz em responder a você..
Você pode clonar meu repositório github para baixar todos os códigos e dados, Clique aqui!!
Sobre o autor

Praveen Kumar Anwla
Trabalhei como cientista de dados com empresas de auditoria baseadas em produtos e Big 4 para quase 5 anos. Eu tenho trabalhado em várias estruturas NLP, aprendizado de máquina de ponta e aprendizado profundo para resolver problemas de negócios. Por favor, sinta-se livre para verificar meu blog pessoal, onde eu suto tópicos de aprendizado de máquina: inteligência artificial, chatbots para ferramentas de visualização (Borda, QlikView, etc.) e várias plataformas de nuvem, como o Azure, IBM e a Nuvem AWS.





