Visión general
- Comprender la arquitectura de Apache HiveHive es una plataforma de redes sociales descentralizada que permite a sus usuarios compartir contenido y conectar con otros sin la intervención de una autoridad central. Utiliza tecnología blockchain para garantizar la seguridad y la propiedad de los datos. A diferencia de otras redes sociales, Hive permite a los usuarios monetizar su contenido a través de recompensas en criptomonedas, lo que fomenta la creación y el intercambio activo de información.... y su funcionamiento.
- Aprenderemos a realizar algunas operaciones básicas en Apache Hive.
Introducción
La mayoría de los científicos de datos utilizan consultas SQL para explorar los datos y obtener información valiosa de ellos. Ahora, dado que el volumen de datos está creciendo a un ritmo tan alto, necesitamos nuevas herramientas dedicadas para manejar grandes volúmenes de datos.
Inicialmente, surgió Hadoop y se convirtió en una de las herramientas más populares para procesar y almacenar big data. Pero los desarrolladores debían escribir códigos complejos de reducción de mapas para trabajar con Hadoop. Este es el Apache Hive de Facebook que vino a rescatar. Es otra herramienta diseñada para trabajar con Hadoop. Podemos escribir consultas tipo SQL en la colmena y en el backend las convierte en trabajos de reducción de mapas.

En este artículo, veremos la arquitectura de la colmena y su funcionamiento. También aprenderemos cómo realizar operaciones simples como crear una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... y una tabla, cargar datos, modificar la tabla.
Tabla de contenido
- ¿Qué es Apache Hive?
- Arquitectura Apache Hive
- Trabajo de Apache Hive
- Tipos de datos en Apache Hive
- Crear y eliminar base de datos
- Crear y soltar tabla
- Cargar datos en la tabla
- Modificar tabla
- Ventajas / desventajas de Hive
¿Qué es Apache Hive?
![]()
Apache Hive es un sistema de almacenamiento de datos desarrollado por Facebook para procesar una gran cantidad de datos de estructura en Hadoop. Sabemos que para procesar los datos usando Hadoop, necesitamos corregir funciones complejas de reducción de mapas, lo cual no es una tarea fácil para la mayoría de los desarrolladores. Hive hace que este trabajo sea muy fácil para nosotros.
Utiliza un lenguaje de secuencias de comandos llamado HiveQL que es casi similar al SQL. Entonces, solo tenemos que escribir comandos similares a SQL y en el backend de Hive los convertirá automáticamente en trabajos de reducción de mapas.
Arquitectura Apache Hive
Echemos un vistazo al siguiente diagrama que muestra la arquitectura.
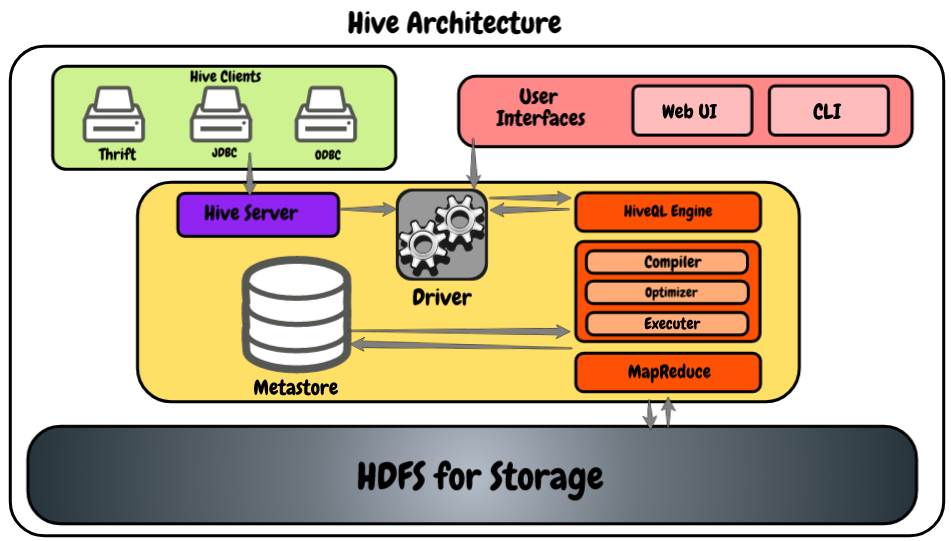
- Clientes de Hive: Nos permite escribir aplicaciones de Hive utilizando diferentes tipos de clientes, como el servidor de ahorro, el controlador JDBC para Java y las aplicaciones de Hive, y también es compatible con las aplicaciones que utilizan el protocolo ODBC.
- Servicios de colmena: Como desarrollador, si deseamos procesar algún dato, necesitamos utilizar los servicios de hive como hive CLI (Interfaz de línea de comandos). Además de esa colmena, también proporciona una interfaz basada en web para ejecutar las aplicaciones de la colmena.
- Conductor de colmena: Es capaz de recibir consultas de múltiples recursos como thrift, JDBC y ODBS utilizando el servidor de hive y directamente desde la CLI de hive y la interfaz de usuario basada en web. Después de recibir las consultas, las transfiere al compilador.
- Motor HiveQL: Recibe la consulta del compilador y convierte la consulta similar a SQL en trabajos de reducción de mapas.
- Meta tienda: Aquí Hive almacena la metainformación sobre las bases de datos como el esquema de la tabla, los tipos de datos de las columnas, la ubicación en el HDFSHDFS, o Sistema de Archivos Distribuido de Hadoop, es una infraestructura clave para el almacenamiento de grandes volúmenes de datos. Diseñado para ejecutarse en hardware común, HDFS permite la distribución de datos en múltiples nodos, garantizando alta disponibilidad y tolerancia a fallos. Su arquitectura se basa en un modelo maestro-esclavo, donde un nodo maestro gestiona el sistema y los nodos esclavos almacenan los datos, facilitando el procesamiento eficiente de información..., etc.
- HDFS: Es simplemente el sistema de archivos distribuidoUn sistema de archivos distribuido (DFS) permite el almacenamiento y acceso a datos en múltiples servidores, facilitando la gestión de grandes volúmenes de información. Este tipo de sistema mejora la disponibilidad y la redundancia, ya que los archivos se replican en diferentes ubicaciones, lo que reduce el riesgo de pérdida de datos. Además, permite a los usuarios acceder a los archivos desde distintas plataformas y dispositivos, promoviendo la colaboración y... de Hadoop que se utiliza para almacenar los datos. Le recomiendo encarecidamente que lea este artículo para obtener más información sobre HDFS: Introducción al ecosistema de Hadoop
Trabajo de Apache Hive
Ahora, echemos un vistazo al funcionamiento de Hive sobre el marco de Hadoop.
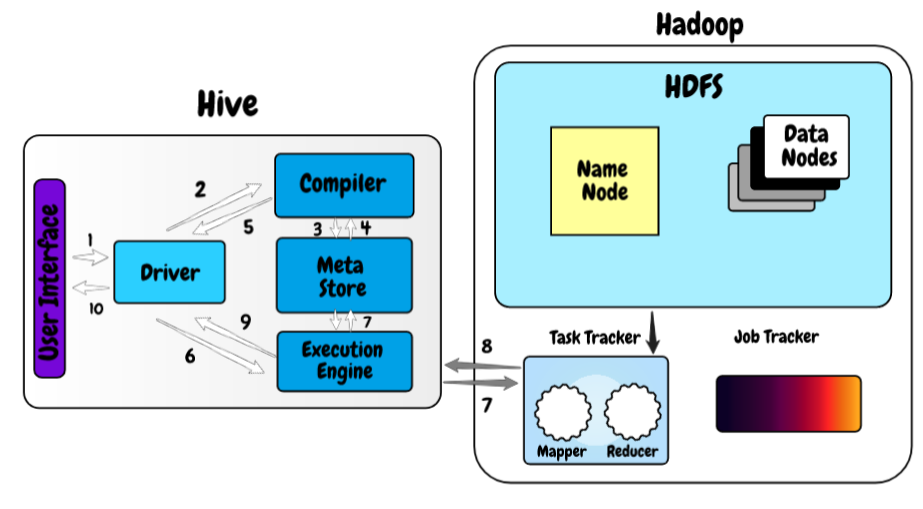
- En el primer paso, escribimos la consulta utilizando la interfaz web o la interfaz de línea de comandos de la colmena. Lo envía al controlador para ejecutar la consulta.
- En el siguiente paso, el controlador envía la consulta recibida al compilador donde el compilador verifica la sintaxis.
- Y una vez que se realiza la verificación de sintaxis, solicita metadatos del meta store.
- Ahora, los metadatos proporcionan información como la base de datos, tablas, tipos de datos de la columna en respuesta a la consulta al compilador.
- El compilador nuevamente verifica todos los requisitos recibidos del meta store y envía el plan de ejecución al controlador.
- Ahora, el controlador envía el plan de ejecución al motor de proceso de HiveQL, donde el motor convierte la consulta en el trabajo de reducción de mapas.
- Una vez que la consulta se convierte en el trabajo de reducción de mapas, envía la información de la tarea a Hadoop donde comienza el procesamiento de la consulta y, al mismo tiempo, actualiza los metadatos sobre el trabajo de reducción de mapas en el meta almacén.
- Una vez realizado el procesamiento, el motor de ejecución recibe los resultados de la consulta.
- El motor de ejecución transfiere los resultados al controlador y, finalmente, los envía a la interfaz de usuario de la colmena desde donde podemos ver los resultados.
Tipos de datos en Apache Hive
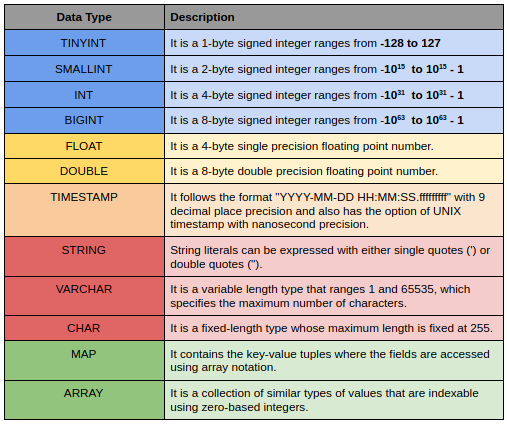
Los tipos de datos de Hive se dividen en las siguientes 5 categorías diferentes:
- Tipo numérico: TINYINT, SMALLINT, INT, BIGINT
- Tipos de fecha / hora: HORA, FECHA, INTERVALO
- Tipos de cuerdas: STRING, VARCHAR, CHAR
- Tipos complejos: ESTRUCTURA, MAPA, UNIÓN, ARRAY
- Tipos misceláneos: BOOLEO, BINARIO
Aquí hay una pequeña descripción de algunos de ellos.
Crear y eliminar base de datos
La creación y eliminación de una base de datos es muy simple y similar a SQL. Necesitamos asignar un nombre único a cada una de las bases de datos de la colmena. Si la base de datos ya existe, mostrará una advertencia y para suprimir esta advertencia puede agregar las palabras clave SI NO EXISTE después de la palabra clave de la base de datos.
CREATE DATABASE <<database_name>> ;
Eliminar una base de datos también es muy simple, solo necesita escribir un eliminar la base de datos y el nombre de la base de datos ser abandonado. Si intenta eliminar la base de datos que no existe, le dará el error SemanticException.
DROP DATABASE <<database_name>> ;
Crear mesa
Usamos la instrucción create table para crear una tabla y la sintaxis completa es la siguiente.
CREATE TABLE IF NOT EXISTS <<database_name.>><<table_name>>
(column_name_1 data_type_1,
column_name_2 data_type_2,
.
.
column_name_n data_type_n)
ROW FORMAT DELIMITED FIELDS
TERMINATED BY 't'
LINES TERMINATED BY 'n'
STORED AS TEXTFILE;
Si ya está utilizando la base de datos, no es necesario que escriba nombre_base_datos.nombre_tabla. En ese caso, solo puede escribir el nombre de la tabla. En el caso de Big Data, la mayoría de las veces importamos los datos de archivos externos por lo que aquí podemos predefinir el delimitador utilizado en el archivo, terminador de línea y también podemos definir cómo queremos almacenar la tabla.
Hay 2 tipos diferentes de tablas de colmena Tablas internas y externas. Consulte este artículo para conocer más sobre el concepto: Tipos de tablas en Apache Hive: una descripción general rápida
Cargar datos en la tabla
Ahora, se han creado las tablas. Es hora de cargar los datos en él. Podemos cargar los datos de cualquier archivo local en nuestro sistema usando la siguiente sintaxis.
LOAD DATA LOCAL INPATH <<path of file on your local system>>
INTO TABLE
<<database_name.>><<table_name>> ;
Cuando trabajamos con una gran cantidad de datos, existe la posibilidad de tener tipos de datos inigualables en algunas de las filas. En ese caso, la colmena no arrojará ningún error, sino que completará valores nulos en su lugar. Esta es una característica muy útil, ya que cargar archivos de big data en la colmena es un proceso costoso y no queremos cargar el conjunto de datos completo solo por tener pocos archivos.
Modificar tabla
En la colmena, podemos hacer varias modificaciones a las tablas existentes, como cambiar el nombre de las tablas, agregar más columnas a la tabla. Los comandos para modificar la tabla son muy similares a los comandos SQL.
Aquí está la sintaxis para cambiar el nombre de la tabla:
ALTER TABLE <<table_name>> RENAME TO <<new_name>> ;
Sintaxis para agregar más columnas de la tabla:
## to add more columns
ALTER TABLE <<table_name>> ADD COLUMNS
(new_column_name_1 data_type_1,
new_column_name_2 data_type_2,
.
.
new_column_name_n data_type_n) ;
Ventajas / desventajas de Apache Hive
- Utiliza SQL como lenguaje de consulta que ya es familiar para la mayoría de los desarrolladores, por lo que facilita su uso.
- Es altamente escalable, puede usarlo para procesar cualquier tamaño de datos.
- Admite múltiples bases de datos como MySQL, derby, Postgres y Oracle para su tienda de metadatos.
- Admite múltiples formatos de datos y también permite indexar, particionar y agrupar para optimizar las consultas.
- Solo puede manejar datos fríos y es inútil cuando se trata de procesar datos en tiempo real.
- Es comparativamente más lento que algunos de sus competidores. Si su caso de uso se trata principalmente de procesamiento por lotes, Hive está bien.
Notas finales
En este artículo, hemos visto la arquitectura de Apache Hive y su funcionamiento y algunas de las operaciones básicas para comenzar. En el próximo artículo de esta serie, veremos algunos de los conceptos más complejos e importantes de partición y agrupamientoEl "agrupamiento" es un concepto que se refiere a la organización de elementos o individuos en grupos con características o objetivos comunes. Este proceso se utiliza en diversas disciplinas, incluyendo la psicología, la educación y la biología, para facilitar el análisis y la comprensión de comportamientos o fenómenos. En el ámbito educativo, por ejemplo, el agrupamiento puede mejorar la interacción y el aprendizaje entre los estudiantes al fomentar el trabajo... en una colmena.
Si tiene alguna pregunta relacionada con este artículo, hágamelo saber en la sección de comentarios a continuación.





