¡Este artículo pasó por una serie de cambios!
Inicialmente estaba escribiendo sobre un tema diferente (relacionado con la analíticaLa analítica se refiere al proceso de recopilar, medir y analizar datos para obtener información valiosa que facilite la toma de decisiones. En diversos campos, como los negocios, la salud y el deporte, la analítica permite identificar patrones y tendencias, optimizar procesos y mejorar resultados. El uso de herramientas avanzadas y técnicas estadísticas es fundamental para transformar datos en conocimiento aplicable y estratégico....). Casi había terminado de escribirlo. Había invertido aproximadamente 2 horas y escrito un artículo promedio. Si lo hubiera hecho en vivo, ¡lo habría hecho bien! Pero algo en mí me impidió hacerlo vivir. Simplemente no estaba satisfecho con el resultado. El artículo no transmite cómo me siento acerca de 2015 y cuán útil podría ser DataPeaker para su aprendizaje de analítica este año.
Entonces, puse ese artículo en la Papelera y comencé a repensar qué tema haría justicia. Esto es lo que terminé con: déjame escribir artículos y guías increíbles sobre lo que fue mi mayor aprendizaje en 2014: la biblioteca Scikit-learn o sklearn en Python. Este fue mi mayor aprendizaje porque ahora es la herramienta que uso para cualquier proyecto de aprendizaje automático en el que trabajo.
La creación de estos artículos no solo sería inmensamente útil para los lectores del blog, sino que también me desafiaría a escribir sobre algo en lo que todavía soy relativamente nuevo. También me encantaría saber de ti sobre lo mismo: ¿cuál fue tu mayor aprendizaje en 2014 y te gustaría compartirlo con los lectores de este blog?
¿Qué es scikit-learn o sklearn?
Scikit-learn es probablemente la biblioteca más útil para el aprendizaje automático en Python. La biblioteca sklearn contiene muchas herramientas eficientes para el aprendizaje automático y el modelado estadístico, que incluyen clasificación, regresión, agrupación y reducción de dimensionalidad.
Tenga en cuenta que sklearn se utiliza para crear modelos de aprendizaje automático. No debe usarse para leer los datos, manipularlos y resumirlos. Hay mejores bibliotecas para eso (por ejemplo, NumPy, Pandas, etc.)
![]()
Componentes de scikit-learn:
Scikit-learn viene cargado con muchas funciones. Éstos son algunos de ellos para ayudarlo a comprender la propagación:
- Algoritmos de aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en...: Piense en cualquier algoritmo de aprendizaje automático supervisado del que haya oído hablar y existe una gran posibilidad de que sea parte de scikit-learn. A partir de modelos lineales generalizados (por ejemplo, regresión lineal), máquinas de vectores de soporte (SVM), árboles de decisión y métodos bayesianos, todos ellos forman parte de la caja de herramientas de scikit-learn. La difusión de los algoritmos de aprendizaje automático es una de las principales razones del alto uso de scikit-learn. Comencé a usar scikit para resolver problemas de aprendizaje supervisado y también se lo recomendaría a personas nuevas en scikit / aprendizaje automático.
- Validación cruzada: Existen varios métodos para verificar la precisión de los modelos supervisados en datos no vistos usando sklearn.
- Algoritmos de aprendizaje no supervisados: Nuevamente, hay una gran variedad de algoritmos de aprendizaje automático en la oferta, desde la agrupación, el análisis de factores, el análisis de componentes principales hasta las redes neuronales no supervisadas.
- Varios conjuntos de datos de juguetes: Esto fue útil mientras aprendía scikit-learn. Había aprendido SAS usando varios conjuntos de datos académicos (por ejemplo, el conjunto de datos IRIS, el conjunto de datos de precios de la vivienda de Boston). Tenerlos a mano mientras aprende una nueva biblioteca ayudó mucho.
- Extracción de características: Scikit-learn para extraer características de imágenes y texto (por ejemplo, bolsa de palabras)
Comunidad / organizaciones que utilizan scikit-learn:
Una de las principales razones detrás del uso de herramientas de código abierto es la gran comunidad que tiene. Lo mismo ocurre con sklearn también. Hay alrededor de 35 colaboradores de scikit-learn hasta la fecha, el más notable es Andreas Mueller (PS Andy hoja de trucos de aprendizaje automático es una de las mejores visualizaciones para comprender el espectro de algoritmos de aprendizaje automático).
Hay varias organizaciones como Evernote, Inria y AWeber que se muestran en página de inicio de scikit learn como usuarios. Pero realmente creo que el uso real es mucho más.
Además de estas comunidades, hay varias reuniones en todo el mundo. También hubo un Concurso de conocimientos de Kaggle, que terminó recientemente, pero aún podría ser uno de los mejores lugares para comenzar a jugar con la biblioteca.
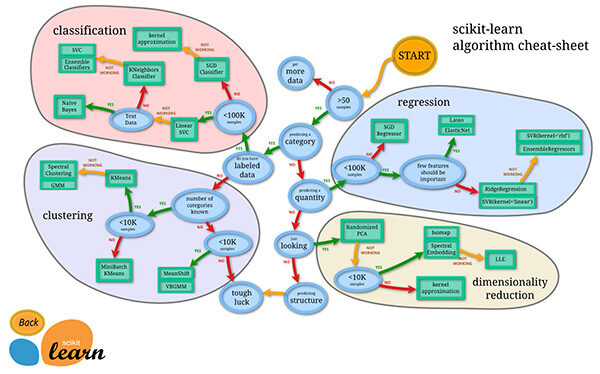
Hoja de referencia de aprendizaje automático: consulte la imagen original para obtener una mejor resoluciónLa "resolución" se refiere a la capacidad de tomar decisiones firmes y cumplir con los objetivos establecidos. En contextos personales y profesionales, implica definir metas claras y desarrollar un plan de acción para alcanzarlas. La resolución es fundamental para el crecimiento personal y el éxito en diversas áreas de la vida, ya que permite superar obstáculos y mantener el enfoque en lo que realmente importa....
Ejemplo rápido:
Ahora que comprende el ecosistema a un alto nivel, permítame ilustrar el uso de sklearn con un ejemplo. La idea es simplemente ilustrar la simplicidad de uso de sklearn. Veremos varios algoritmos y las mejores formas de usarlos en uno de los artículos que siguen.
Construiremos una regresión logística en el conjunto de datos de IRIS:
Paso 1: importar las bibliotecas relevantes y leer el conjunto de datos
importar numpy como np
importar matplotlib como plt
desde sklearn importar conjuntos de datos
de las métricas de importación de sklearn
de sklearn.linear_model import LogisticRegression
Hemos importado todas las bibliotecas. A continuación, leemos el conjunto de datos:
conjunto de datos = conjuntos de datos.load_iris ()
Paso 2: Comprenda el conjunto de datos observando distribuciones y diagramas
Me estoy saltando estos pasos por ahora. Puede leer este artículo si desea aprender análisis exploratorio.
Paso 3: construir un modelo de regresión logística en el conjunto de datos y hacer predicciones
model.fit (datasetUn "dataset" o conjunto de datos es una colección estructurada de información, que puede ser utilizada para análisis estadísticos, machine learning o investigación. Los datasets pueden incluir variables numéricas, categóricas o textuales, y su calidad es crucial para obtener resultados fiables. Su uso se extiende a diversas disciplinas, como la medicina, la economía y la ciencia social, facilitando la toma de decisiones informadas y el desarrollo de modelos predictivos.....data, dataset.target)
esperado = dataset.target
predicted = model.predict (dataset.data)
Paso 4: Imprima la matriz de confusión
print (metrics.classification_report (esperado, predicho))
print (metrics.confusion_matrix (esperado, predicho))
Notas finales:
Esta fue una descripción general de una de las bibliotecas de aprendizaje automático más potentes y versátiles de Python. También fue el mayor aprendizaje que hice en 2014. ¿Cuál fue su mayor aprendizaje en 2014? Compártelo con el grupo a través de los comentarios a continuación.
¿Estás emocionado de aprender y usar Scikit-learn? En caso afirmativo, permanezca atento a los artículos restantes de esta serie.
Un recordatorio rápido: si no ha realizado el check out Analítica Vidhya Discutir sin embargo, deberías hacerlo ahora. Los usuarios se están uniendo rápidamente, así que tome el nombre de usuario que desea antes de que alguien más lo recoja.





