Requisitos previos: lenguaje de programación R básico y conocimiento básico de clasificación
Mientras que el enfoque del conjunto de validación funciona dividiendo el conjunto de datos una vez, k-Fold lo hace cinco o diez veces. Imagine que está haciendo el enfoque del conjunto de validación diez veces utilizando un grupo de datos diferente.
Digamos que tenemos 100 filas de datos. Los dividimos aleatoriamente en diez grupos de pliegues. Cada pliegue constará de alrededor de 10 filas de datos. El primer pliegue se utilizará como conjunto de validación y el resto es para el conjunto de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina..... Luego entrenamos nuestro modelo usando este conjunto de datos y calculamos la precisión o pérdida. Luego repetimos este proceso pero usando un pliegue diferente para el conjunto de validación. Vea la imagen a continuación.
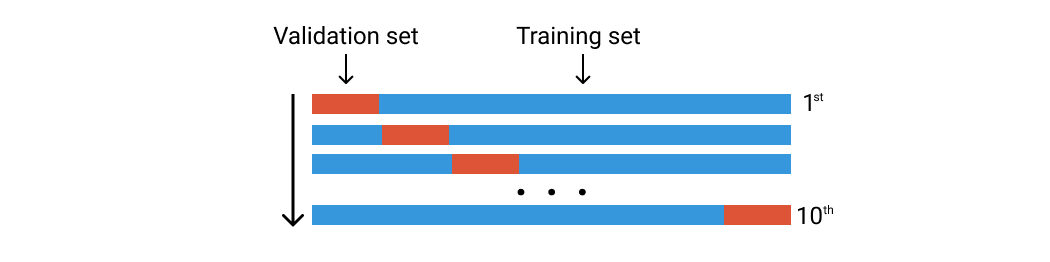
Validación cruzada de K-Fold. Imagen del autor
Saltemos al código
Las bibliotecas que usamos son estas dos:
library(tidyverse) library(caret)
Los datos utilizados aquí son datos de enfermedades cardíacas de la UCI que se pueden descargar en Kaggle. También puede utilizar cualquier dato de clasificación para este experimento.
data <- read.csv("../input/heart-disease-uci/heart.csv")
head(data)
Aquí están las seis filas superiores de los datos cargados. Tiene trece predictores y la última columna es la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... de respuesta. También puede verificar las últimas filas usando la función tail ().
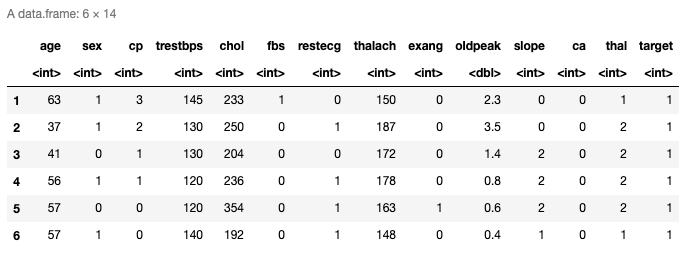
La distribución de datos
Aquí queremos confirmar que la distribución entre los datos de dos etiquetas no es muy diferente. Porque los conjuntos de datos desequilibrados pueden conducir a una precisión desequilibrada. Esto significa que su modelo siempre predecirá hacia una sola etiqueta, o siempre predecirá 0 o 1.
hist(data$target,col="coral") prop.table(table(data$target))
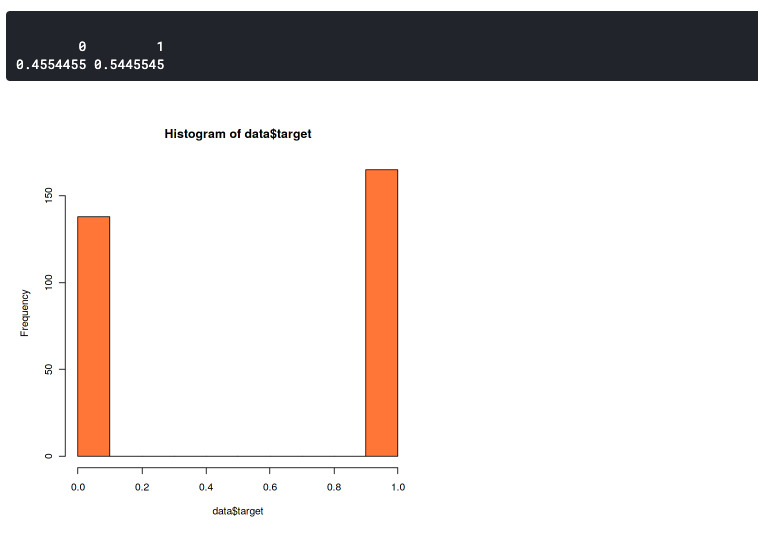
Este gráfico muestra que nuestro conjunto de datos está ligeramente desequilibrado pero aún lo suficientemente bueno. Tiene una proporción de 46:54. Debería empezar a preocuparse si su conjunto de datos tiene más del 60% de los datos en una clase. En ese caso, puede usar SMOTE para manejar un conjunto de datos desequilibrado.
El k-Fold
set.seed(100) trctrl <- trainControl(method = "cv", number = 10, savePredictions=TRUE) nb_fit <- train(factor(target) ~., data = data, method = "naive_bayes", trControl=trctrl, tuneLength = 0) nb_fit
La primera línea es establecer la semilla del pseudoaleatorio para que se pueda reproducir el mismo resultado. Puede utilizar cualquier número para el valor inicial.
A continuación, podemos establecer la configuración de k-Fold en la función trainControl (). Establezca el parámetro del método en “cv” y el parámetro numérico en 10. Significa que establecemos la validación cruzada con diez pliegues. Podemos establecer el número de pliegue con cualquier número, pero la forma más común es establecerlo en cinco o diez.
La función train () se usa para determinar el método que usamos. Aquí usamos el método Naive Bayes y establecemos tuneLength en cero porque nos enfocamos en evaluar el método en cada pliegue. También podemos establecer tuneLength si queremos hacer el ajuste de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... durante la validación cruzada. Por ejemplo, si usamos el método K-NN y queremos analizar cuántos K son los mejores para nuestro modelo.
Puede ver el método admitido en Documentación R.
Tenga en cuenta que la validación cruzada de k-Fold puede tardar un poco porque ejecuta el proceso de formación diez veces.
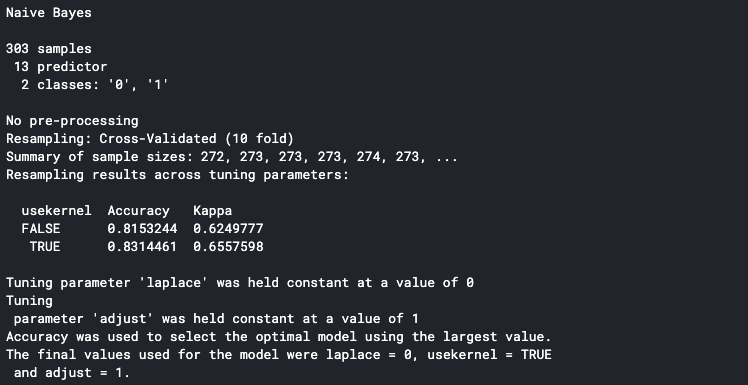
Imprimirá el detalle en la consola una vez que esté terminado. La precisión que se muestra en la consola es la precisión promedio de todos los pliegues de entrenamiento. Podemos ver que nuestro modelo tiene una precisión promedio del 83%.
Despliegue el k-Fold
Podemos determinar que nuestro modelo está funcionando bien en cada pliegue si observamos la precisión de cada pliegue. Para hacer esto, asegúrese de configurar el savePredictions parámetro a TRUE en la función trainControl ().
pred <- nb_fit$pred pred$equal <- ifelse(pred$pred == pred$obs, 1,0)
eachfold <- pred %>%
group_by(Resample) %>%
summarise_at(vars(equal),
list(Accuracy = mean))
eachfold
Aquí está la tabla de precisión en cada pliegue.

También podemos trazarlo en el gráfico para que sea más fácil de analizar. En este caso, usamos la gráfica de caja para representar nuestras precisiones.
ggplot(data=eachfold, aes(x=Resample, y=Accuracy, group=1)) + geom_boxplot(color="maroon") + geom_point() + theme_minimal()
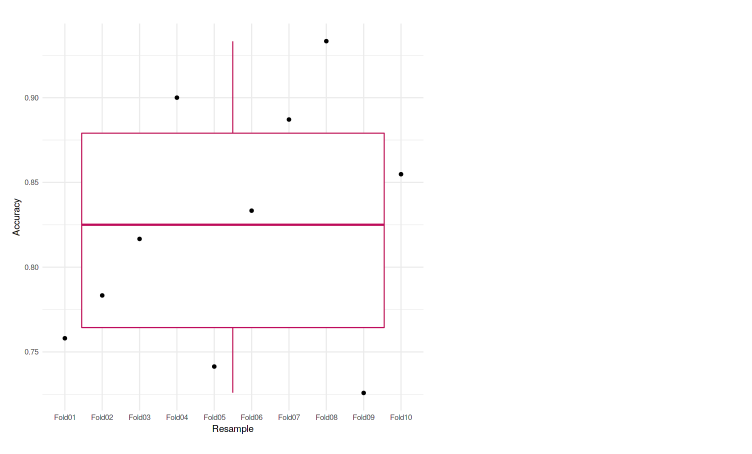
Podemos ver que cada uno de los pliegues logra una precisión que no se diferencia mucho entre sí. La precisión más baja es 72,58%, y también en el diagrama de caja, no vemos valores atípicos. Lo que significa que nuestro modelo estaba funcionando bien en la validación cruzada de k veces.
Que sigue
- Prueba con un número diferente de pliegues
- Hacer un ajuste de parámetros
- Utilice otros conjuntos de datos y métodos
Breve biografía del autor
Me llamo Muhammad Arnaldo, un entusiasta del aprendizaje automático y la ciencia de datos. Actualmente estudiante de maestría en ciencias de la computación en Indonesia.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





