Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
VGG- Network es un modelo de red neuronal convolucionalLas redes neuronales convolucionales (CNN) son un tipo de arquitectura de red neuronal diseñadas especialmente para el procesamiento de datos con una estructura de cuadrícula, como imágenes. Utilizan capas de convolución para extraer características jerárquicas, lo que las hace especialmente efectivas en tareas de reconocimiento de patrones y clasificación. Gracias a su capacidad para aprender de grandes volúmenes de datos, las CNN han revolucionado campos como la visión por computadora... propuesto por K. Simonyan y A. Zisserman en el artículo «Redes convolucionales muy profundas para el reconocimiento de imágenes a gran escala» [1]. Esta arquitectura logró una precisión de prueba entre las 5 mejores del 92,7% en ImageNet, que tiene más de 14 millones de imágenes pertenecientes a 1000 clases.
Es una de las arquitecturas famosas en el campo del aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud.... Reemplazar los filtros de tamaño de kernel grandes con 11 y 5 en la primera y segunda capa, respectivamente, mostró la mejora con respecto a la arquitectura AlexNet, con múltiples filtros de tamaño de kernel de 3 × 3 uno tras otro. Fue entrenado durante semanas y estaba usando NVIDIA Titan Black GPU.
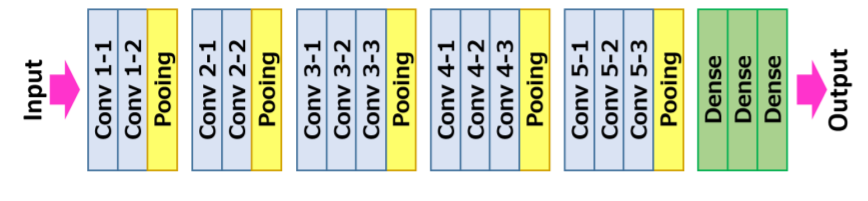
Arquitectura VGG16
La entrada a la red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... de convolución es una imagen RGB de tamaño fijo 224 × 224. El único procesamiento previo que hace es restar los valores RGB medios, que se calculan en el conjunto de datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina...., de cada píxel.
Luego, la imagen se ejecuta a través de una pila de capas convolucionales (Conv.), Donde hay filtros con un campo receptivo muy pequeño que es 3 × 3, que es el tamaño más pequeño para capturar la noción de izquierda / derecha, arriba / abajo, y parte central.
En una de las configuraciones, también utiliza filtros de convolución 1 × 1, que se pueden observar como una transformación lineal de los canales de entrada seguida de no linealidad. Las zancadas convolucionales se fijan en 1 píxel; el relleno espacial de la entrada de la capa convolucionalLa capa convolucional, fundamental en las redes neuronales convolucionales (CNN), se utiliza principalmente para el procesamiento de datos con estructuras en forma de cuadrícula, como imágenes. Esta capa aplica filtros que extraen características relevantes, como bordes y texturas, permitiendo que el modelo reconozca patrones complejos. Su capacidad para reducir la dimensionalidad de los datos y mantener información esencial la convierte en una herramienta clave en tareas de visión por computadora... es tal que la resoluciónLa "resolución" se refiere a la capacidad de tomar decisiones firmes y cumplir con los objetivos establecidos. En contextos personales y profesionales, implica definir metas claras y desarrollar un plan de acción para alcanzarlas. La resolución es fundamental para el crecimiento personal y el éxito en diversas áreas de la vida, ya que permite superar obstáculos y mantener el enfoque en lo que realmente importa.... espacial se mantiene después de la convolución, es decir, el relleno es de 1 píxel para 3 × 3 Conv. capas.
Luego, la agrupación espacial se lleva a cabo mediante cinco capas de agrupación máxima, 16 que siguen algunas de las Conv. capas, pero no todas las Conv. las capas van seguidas de la agrupación máxima. Esta agrupación máxima se realiza en una ventana de 2 × 2 píxeles, con paso 2.
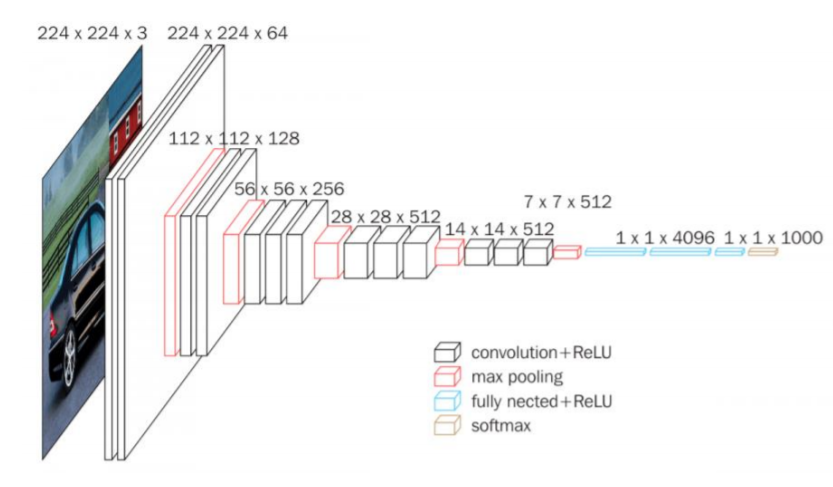
La arquitectura contiene una pila de capas convolucionales que tienen una profundidad diferente en diferentes arquitecturas que son seguidas por tres capas Fully-Connected (FC): las dos primeras FC tienen 4096 canales cada una y la tercera FC realiza una clasificación de 1000 vías y por lo tanto contiene 1000 canales que es uno para cada clase.
La última capa es la capa soft-max. La configuración de las capas completamente conectadas es similar en todas las redes.
Todas las capas ocultas están equipadas con rectificación (ReLULa función de activación ReLU (Rectified Linear Unit) es ampliamente utilizada en redes neuronales debido a su simplicidad y eficacia. Definida como ( f(x) = max(0, x) ), ReLU permite que las neuronas se activen solo cuando la entrada es positiva, lo que contribuye a mitigar el problema del desvanecimiento del gradiente. Su uso ha demostrado mejorar el rendimiento en diversas tareas de aprendizaje profundo, haciendo de ReLU una opción...) no lineal. Además, aquí una de las redes contiene NormalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.... de respuesta local (LRN), dicha normalización no mejora el rendimiento en el conjunto de datos entrenado, pero su uso conduce a un mayor consumo de memoria y tiempo de cálculo.
Resumen de arquitectura:
• La entrada al modelo es una imagen RGB de tamaño fijo 224 × 224224 × 224
• El preprocesamiento consiste en restar la media del valor RGB del conjunto de entrenamiento de cada píxel
• Capas convolucionales 17
– Zancada fija a 1 píxel
– el relleno es de 1 píxel para 3 × 33 × 3
• Capas de agrupación espacial
– Esta capa no cuenta para la profundidad de la red por convención
– La agrupación espacial se realiza mediante capas de agrupación máxima
– el tamaño de la ventana es 2 × 22 × 2
– Zancada fijada a 2
– Convnets utilizó 5 capas de agrupación máxima
• Capas completamente conectadas:
• 1º: 4096 (ReLU).
▪ 2do: 4096 (ReLU).
▪ 3º: 1000 (Softmax).
Configuración de la arquitectura
La siguiente figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... contiene la configuración de la red neuronal de convolución de la red VGG con el
siguientes capas:
• VGG-11
• VGG-11 (LRN)
• VGG-13
• VGG-16 (Conv1)
• VGG-16
• VGG-19
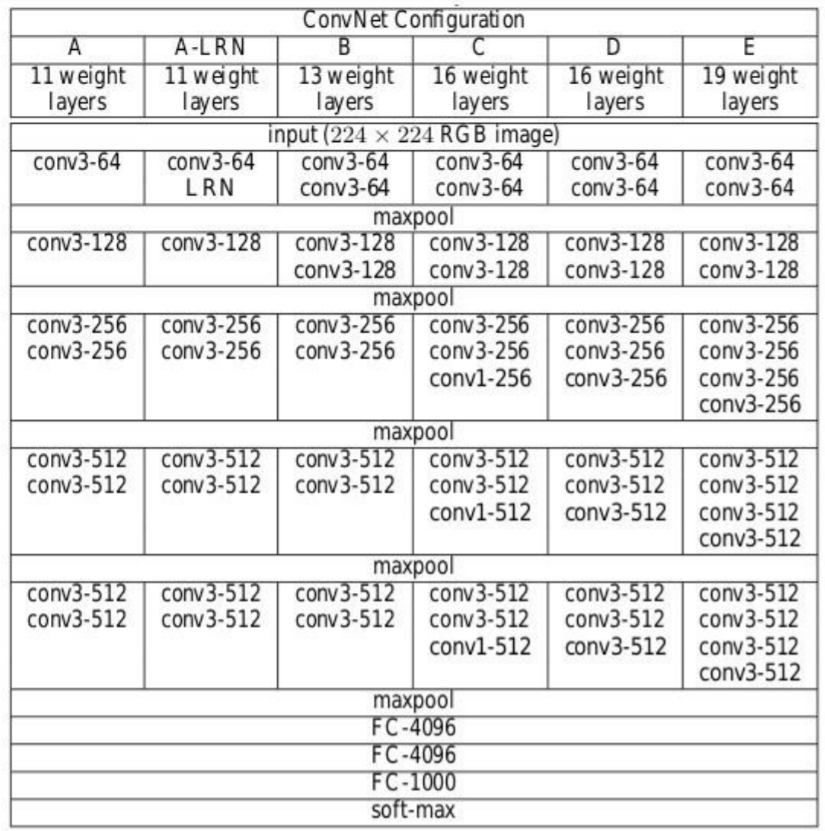
Fuente: «Redes convolucionales muy profundas para el reconocimiento de imágenes a gran escala»
Las configuraciones de la red neuronal convolucional se mencionan arriba una por columna.
A continuación, se hace referencia a las redes por sus nombres (A – E). Todas las configuraciones siguen el diseño tradicional y difieren solo en la profundidad: de 11 capas de peso en la red A que son 8 Conv. y 3 capas FC a 19 capas de peso en la red E que es 16 Conv. y 3 capas FC. El ancho de cada conv. layer es el número de canales es bastante pequeño, que comienza desde 64 en la primera capa y luego continúa aumentando en un factor de 2 después de cada capa de agrupación máxima hasta llegar a 512.
El número de parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... para cada configuración se describe a continuación. Aunque tiene una gran profundidad, el número de pesos en las redes no es mayor que el número de pesos en una red menos profunda con mayor conv. anchos de capa y campos receptivos

Capacitación
• La función de pérdidaLa función de pérdida es una herramienta fundamental en el aprendizaje automático que cuantifica la discrepancia entre las predicciones del modelo y los valores reales. Su objetivo es guiar el proceso de entrenamiento al minimizar esta diferencia, permitiendo así que el modelo aprenda de manera más efectiva. Existen diferentes tipos de funciones de pérdida, como el error cuadrático medio y la entropía cruzada, cada una adecuada para distintas tareas y... es una regresión logística multinomial
• El algoritmo de aprendizaje es un descenso de gradienteGradiente es un término utilizado en diversos campos, como la matemática y la informática, para describir una variación continua de valores. En matemáticas, se refiere a la tasa de cambio de una función, mientras que en diseño gráfico, se aplica a la transición de colores. Este concepto es esencial para entender fenómenos como la optimización en algoritmos y la representación visual de datos, permitiendo una mejor interpretación y análisis en... estocástico (SGD) de mini lotes basado en la propagación hacia atrás con impulso.
· El tamaño del lote era 256
· El impulso fue 0,9
• RegularizaciónLa regularización es un proceso administrativo que busca formalizar la situación de personas o entidades que operan fuera del marco legal. Este procedimiento es fundamental para garantizar derechos y deberes, así como para fomentar la inclusión social y económica. En muchos países, la regularización se aplica en contextos migratorios, laborales y fiscales, permitiendo a quienes se encuentran en situaciones irregulares acceder a beneficios y protegerse de posibles sanciones....
· Decaimiento de peso L2 (el multiplicador de penalización fue 0,0005)
· La deserción para las dos primeras capas completamente conectadas se establece en 0.5
• Tasa de aprendizaje
· Inicial: 0.01
· Cuando la precisión del conjunto de validación dejó de mejorar, se reduce a 10.
• Aunque tiene una mayor cantidad de parámetros y también profundidad en comparación con Alexnet, la CNN requirió menos épocas para que la función de pérdida converja debido a
· Pequeños granos convolucionales y más regularización por gran profundidad.
· Preinicialización de determinadas capas.
• Tamaño de la imagen de entrenamiento
· S es el lado más pequeño de la imagen reescalada isotópicamente
· Dos enfoques para establecer S
▪ Fix S, conocido como entrenamiento de escala única
▪ Aquí S = 256 y S = 384
▪ Vary S, conocido como entrenamiento de múltiples escalas
▪ S de [Smin, Smax] donde Smin = 256, Smáx = 512
– Luego 224 × 224224 × 224
la imagen se recortó aleatoriamente de la imagen reescalada por iteración SGD.
Características clave
• VGG16 tiene un total de 16 capas que tienen algunos pesos.
• Solo se utilizan capas de convolución y agrupación.
• Utiliza siempre un núcleo de 3 x 3 para la convolución. 20
• Tamaño 2 × 2 de la piscina máxima.
• 138 millones de parámetros.
• Capacitado en datos de ImageNet.
• Tiene una precisión del 92,7%.
• Otra versión que es VGG 19, tiene un total de 19 capas con pesos.
• Es una muy buena arquitectura de aprendizaje profundo para realizar evaluaciones comparativas en cualquier tarea en particular.
• Las redes pre-entrenadas para VGG son de código abierto, por lo que se pueden usar comúnmente para varios tipos de aplicaciones.
Implementemos VGG Net
Primero, creemos el mapeo de filtros para cada versión de la red VGG. Consulte la imagen de configuración anterior para conocer la cantidad de filtros. Es decir, crear un diccionario para la versión con una clave denominada VGG11, VGG13, VGG16, VGG19 y crear una lista de acuerdo con la cantidad de filtros en cada versión respectivamente. Aquí «M» en la lista se conoce como operación Maxpool.
import torch import torch.nn as nn
VGG_types = {
"VGG11": [64, "M", 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"VGG13": [64, 64, "M", 128, 128, "M", 256, 256, "M", 512, 512, "M", 512, 512, "M"],
"VGG16": [64,64,"M",128,128,"M",256,256,256,"M",512,512,512,"M",512,512,512,"M",],
"VGG19": [64,64,"M",128,128,"M",256,256,256,256,"M",512,512,512,512,
"M",512,512,512,512,"M",],}
Cree una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... global para mencionar la versión de la arquitectura. Luego cree una clase llamada VGG_net con entradas como in_channels y num_classes. Toma entradas como una cantidad de canales de imagen y la cantidad de clases de salida.
Inicialice las capas secuenciales, es decir, en la secuencia, Capa lineal–> ReLU–> Omitir.
Luego cree una función llamada create_conv_layers que toma la configuración de la arquitectura VGGnet como entrada, que es la lista que creamos anteriormente para diferentes versiones. Cuando se encuentra con la letra «M» de la lista anterior, realiza la operación MaxPool2d.
VGGType = "VGG16"
class VGGnet(nn.Module):
def __init__(self, in_channels=3, num_classes=1000):
super(VGGnet, self).__init__()
self.in_channels = in_channels
self.conv_layers = self.create_conv_layers(VGG_types[VGGType])
self.fcs = nn.Sequential( nn.Linear(512 * 7 * 7, 4096), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(4096, 4096), nn.ReLU(), nn.Dropout(p=0.5), nn.Linear(4096, num_classes), ) def forward(self, x): x = self.conv_layers(x) x = x.reshape(x.shape[0], -1) x = self.fcs(x) return x def create_conv_layers(self, architecture): layers = [] in_channels = self.in_channels for x in architecture: if type(x) == int: out_channels = x layers += [ nn.Conv2d( in_channels=in_channels, out_channels=out_channels, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), ), nn.BatchNorm2d(x), nn.ReLU(), ] in_channels = x elif x == "M": layers += [nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))] return nn.Sequential(*layers)
Una vez hecho esto, escriba un pequeño código de prueba para verificar si nuestra implementación está funcionando bien.
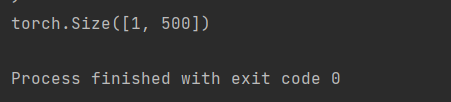
En el siguiente código de prueba, el número de clases dadas es 500.
if __name__ == "__main__":
device = "cuda" if torch.cuda.is_available() else "cpu"
model = VGGnet(in_channels=3, num_classes=500).to(device)
# print(model)
x = torch.randn(1, 3, 224, 224).to(device)
print(model(x).shape)
La salida debería ser así:
Si desea ver la arquitectura de la red, puede descomentar la imprimir (modelo) declaración del código anterior. También puede probar con diferentes versiones cambiando las versiones de VGG en la variable VGGType.
Se puede acceder al código completo aquí:
https://github.com/BakingBrains/Deep_Learning_models_implementation_from-scratch_using_pytorch_/blob/main/VGG.py
[1]. K. Simonyan y A. Zisserman: Redes convolucionales muy profundas para el reconocimiento de imágenes a gran escala, abril de 2015, DOI: https://arxiv.org/pdf/1409.1556.pdf
Gracias
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





