¿Qué son las anomalías y cómo detectarlas? ¿Qué impacto tiene en los datos?
Introducción
Las anomalías son los puntos diferentes del estado normal de existencia. Estos son algo que puede surgir debido a diferentes circunstancias en función de los diversos factores que lo impactan. Por ejemplo, los tumores que se desarrollan debido a algunas enfermedades, como cuando a una persona se le diagnostica cáncer, se desarrolla más cantidad de células sin ningún límite.
De la misma forma, cuando obtenemos dichos datos debemos analizar y detectar estas anomalías para que sea más fácil el tratamiento y saber qué acciones tomar. Cuando ocurren tales anomalías en la industria del automóvil, como cuando las ventas de un automóvil en particular u otros vehículos de transporte son altas o bajas. Entonces es una anomalía de todos los datos. Las anomalías no son más que valores atípicos en los datos.
¿Cómo detecta los valores atípicos o cuáles son los métodos utilizados para detectar anomalías?
1. Usar visualización de datos (como hacer uso de diagramas de cajaLos diagramas de caja, también conocidos como diagramas de caja y bigotes, son herramientas estadísticas que representan la distribución de un conjunto de datos. Estos diagramas muestran la mediana, los cuartiles y los valores atípicos, lo que permite visualizar la variabilidad y la simetría de los datos. Son útiles en la comparación entre diferentes grupos y en el análisis exploratorio, facilitando la identificación de tendencias y patrones en los datos...., diagramas de violín, etc.)
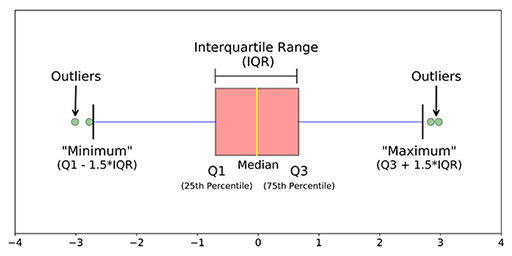
2. Usar métodos estadísticos como los métodos de cuantiles (IQR, Q1, Q3), encontrar el mínimo, el máximo y la medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... de los datos, la puntuación Z, etc.
3. Algoritmos ML como IsolationForest, LocalOutlierFactor, OneClassSVM, Elliptic Envelope… etc.
1. Visualización de datos: Cuando una característica se traza utilizando herramientas de visualización como seaborn, matplotlib, plotly u otro software como tableau, PowerBI, Qlik Sense, Excel, Word, … etc., nos hacemos una idea de los datos y su recuento en los datos y también llegamos a conocer las anomalías principalmente utilizando diagramas de caja, diagramas de violín, diagramas de dispersión.
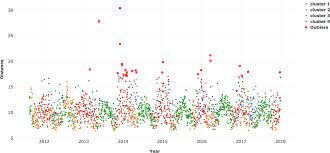
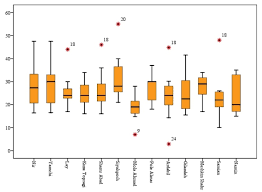
2. Métodos estadísticos: Cuando encuentre la media de los datos, es posible que no proporcione el valor medio correcto cuando hay anomalías en los datos. Cuando existen anomalías en los datos, la mediana da un valor correcto que la media porque la mediana ordena los valores y encuentra la posición intermedia en los datos, mientras que la media solo promedia los valores en los datos. Para encontrar los valores atípicos en el lado derecho e izquierdo de los datos, use Q3 + 1.5 (IQR), Q1-1.5 (IQR). Además, al encontrar el máximo, el mínimo y la mediana de los datos, puede decir si las anomalías están presentes en los datos o no.
3. Algoritmos ML: El beneficio de utilizar los algoritmos no supervisados para la detección de anomalías es que podemos encontrar anomalías para múltiples variables o características o predictores en los datos al mismo tiempo en lugar de por separado para las variables individuales. También se puede realizar de ambas formas, denominadas detección de anomalías univariadas y detección de anomalías multivariadas.
una. Bosque de aislamiento: Esta es una técnica no supervisada para detectar anomalías cuando no hay etiquetas o valores verdaderos. Sería una tarea compleja comprobar cada fila de los datos para detectar esas filas que pueden considerarse anomalías.
Isolation Forest es un modelo basado en árboles. Los árboles formados para esto no son los mismos que se hacen en los árboles de decisión. Los árboles de decisión y los bosques de aislamiento son diferentes formas de construcción. Además, una diferencia principal más es que el árbol de decisiones es un algoritmo de aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en... y el bosque de aislamiento es un algoritmo de aprendizaje no supervisadoEl aprendizaje no supervisado es una técnica de machine learning que permite a los modelos identificar patrones y estructuras en datos sin etiquetas predefinidas. A través de algoritmos como k-means y análisis de componentes principales, este enfoque se utiliza en diversas aplicaciones, como la segmentación de clientes, la detección de anomalías y la compresión de datos. Su capacidad para revelar información oculta lo convierte en una herramienta valiosa en la....
En estos árboles de aislamiento, las particiones se crean seleccionando primero aleatoriamente una característica o variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... y luego seleccionando un valor de división aleatoria entre el valor mínimo y máximo de la característica seleccionada. Nuevamente, el nodoNodo es una plataforma digital que facilita la conexión entre profesionales y empresas en busca de talento. A través de un sistema intuitivo, permite a los usuarios crear perfiles, compartir experiencias y acceder a oportunidades laborales. Su enfoque en la colaboración y el networking hace de Nodo una herramienta valiosa para quienes desean expandir su red profesional y encontrar proyectos que se alineen con sus habilidades y objetivos.... raíz se selecciona aleatoriamente sin ninguna condición para ser un nodo raíz como ocurre en el árbol de decisiones. El nodo raíz se selecciona aleatoriamente de las variables en los datos, luego se toma algún valor aleatorio que se encuentra entre el máximo y el mínimo de esa característica en particular.
La puntuación de anomalía de una muestra de entrada se calcula como la puntuación media de anomalía de los árboles en el bosque de Aislamiento. Luego, se calcula la puntuación de anomalía para cada variable después de ajustar todos los datos al modelo. Cuando la puntuación de anomalía aumenta, hay una alta probabilidad de que sea una anomalía que la fila que tiene menos puntuación de anomalía. Hay tres funciones en este algoritmo que simplifican la visualización y el almacenamiento de las puntuaciones fácilmente utilizando las pocas líneas de código que se proporcionan a continuación:
from sklearn.ensemble import IsolationForest isolation_forest = IsolationForest(n_estimators=1000, contamination=0.08) isolation_forest.fit(df['Rate'].values.reshape(-1, 1)) df['anomaly_score_rate'] = isolation_forest.decision_function(df['rate'].values.reshape(-1, 1)) df['outlier_univariate_rate'] = isolation_forest.predict(df['rate'].values.reshape(-1, 1))
Aquí, el parámetro de contaminación juega un papel importante en la detección de más anomalías. La contaminación es el porcentaje de valores que le está dando al algoritmo que hay tanto porcentaje de anomalías en los datos. Por ejemplo: cuando dio 0,10 como valor de contaminación, los algoritmos consideran que hay un 10% de anomalías en los datos. Al encontrar la contaminación óptima, podrá detectar anomalías con un buen número.
Cuando desee realizar una detección de anomalías multivariante, primero debe normalizar los valores en los datos para que el algoritmo pueda dar predicciones correctas. La normalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos.... o estandarización es esencial cuando se trata de valores continuos.
minmax = MinMaxScaler(feature_range=(0, 1)) X = minmax.fit_transform(df[['rate','scores']]) clf = IsolationForest(n_estimators=100, contamination=0.01, random_state=0) clf.fit(X) df['multivariate_anomaly_score'] = clf.decision_function(X) df['multivariate_outlier'] = clf.predict(X)
Para saber más ve a bosque de aislamiento sklearn
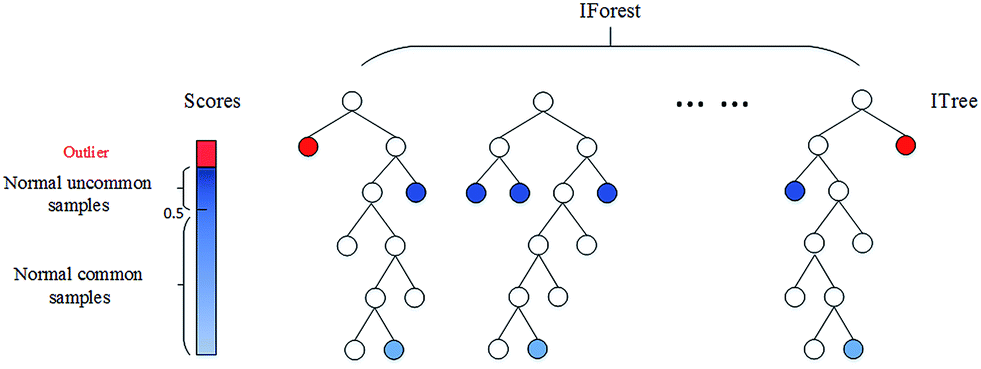
La imagen de arriba corresponde a: https://pubs.rsc.org/en/content/articlelanding/2016/ay/c6ay01574c#!divAbstract
B. LocalOutlierFactor: Este también es un algoritmo no supervisado y no está basado en árboles sino en un algoritmo basado en densidad como KNN, Kmeans. Cuando cualquier punto de datos se tiene en cuenta como un valor atípico dependiendo de su vecindario local, es un valor atípico local. LOF identificará un valor atípico considerando la densidad del vecino. LOF funciona bien cuando la densidad del punto de datos no es constante en todo el conjunto de datos.
Hay dos tipos de detección que se realizan con este algoritmo. Son detección de valores atípicos y detección de novedades, donde la detección de valores atípicos no está supervisada y la detección de novedades está semi-supervisada, ya que utiliza los datos del tren para hacer sus predicciones sobre los datos de prueba, aunque los datos del tren no contienen predicciones exactas.
Incluso LocalOutlierFactor usa el mismo código, entonces el código se usa solo para la detección de novedades cuando el parámetro de novedad es True en este modelo. Cuando su valor predeterminado False, la detección de valores atípicos se usaría donde funcionaría el único fit_predict. Cuando novedad = Verdadero, esta función está desactivada.
A continuación se muestra el código para encontrar anomalías utilizando el algoritmo de factor atípico local
minmax = MinMaxScaler(feature_range=(0, 1)) X = minmax.fit_transform(df[['rate','scores']]) # Novelty detection clf = LocalOutlierFactor(n_neighbors=100, contamination=0.01,novelty=True) #when novelty = True clf.fit(X_train) df['multivariate_anomaly_score'] = clf.decision_function(X_test) df['multivariate_outlier'] = clf.predict(X_test) # Outlier detection local_outlier_factor_multi=LocalOutlierFactor(n_neighbors=15,contamination=0.20,n_jobs=-1) # when novelty = False multi_pred=local_outlier_factor_multi.fit_predict(X) df1['Multivariate_pred']=multi_pred
Para saber más sobre esto, consulte Factor de valor atípico local de sklearn
C. SVM de una clase: Existe una SVM supervisada que se ocupa de las tareas de regresión y clasificación. Aquí hay una SVM de clase única sin supervisión, ya que se desconocen las etiquetas. Las SVM de una clase son un tipo especial de máquina de vectores de soporte. Primero, se modelan los datos y se entrena el algoritmo. Luego, cuando se encuentran nuevos datos, su posición relativa a los datos normales (o inliers) del entrenamiento se puede usar para determinar si está fuera de clase o no. Como se pueden entrenar con datos sin etiquetar o sin variables de destino, son un ejemplo de sin supervisión aprendizaje automático.
Tiene solo unas pocas líneas de código como otros algoritmos:
from sklearn.svm import OneClassSVM pred=clf.predict(X) anomaly_score=clf.score_samples(X) clf = OneClassSVM(gamma="auto",nu=0.04,gamma=0.0004).fit(X)
Para saber más, consulte este sitio de sklearn para SVM de una clase
D. Algoritmo de envolvente elíptica: Este algoritmo se utiliza cuando los datos tienen una distribución gaussiana. En esto es como este modelo convierte los datos en forma elíptica y los puntos que están lejos de las coordenadas de esta forma se consideran valores atípicos y para este determinante de mínima covarianza se encuentra. Es como cuando se encuentra la covarianza en el conjunto de datos, de modo que se excluye el mínimo y cuál es mayor, esos puntos se consideran anomalías. La siguiente imagen muestra la explicación de esta detección de algoritmo.
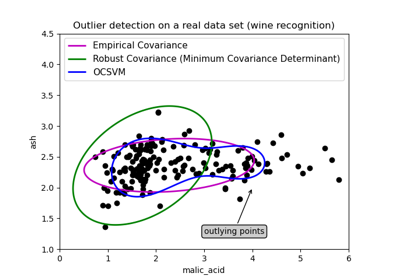
Tiene la misma línea de código que solo para ajustar los datos y predecir en el mismo que identifica las anomalías en los datos donde se asigna -1 para anomalías y +1 para datos normales o in-liers.
from sklearn.covariance import EllipticEnvelope model1 = EllipticEnvelope(contamination = 0.1) # fit model model1.fit(X_train) model1.predict(X_test)
Para obtener más información sobre los parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... y la tabla de comparación, consulte Sobre elíptico sklearn
Estas son algunas de las técnicas utilizadas en la detección de anomalías que ayudan a conocer los puntos que están lejos de lo normal y que traen muchos cambios inesperados en los datos. Según el lugar o el tipo de datos, tiene diversos efectos y se utiliza en muchos lugares e industrias como la industria médica, la industria del automóvil, la industria de la construcción, la industria alimentaria (anomalías que son diferentes de los estándares prescritos), la industria de defensa, etc.
Déjeme saber si usted tiene cualquier pregunta. Gracias por leer. 👩🕵️♀️👩🎓 Que tengas un buen día.😊
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





