Introducción
Todo entusiasta del aprendizaje automático tiene el sueño de construir / trabajar en un proyecto genial, ¿no es así? La mera comprensión de la teoría no es suficiente, es necesario trabajar en proyectos, intentar implementarlos y aprender de ellos. Además, trabajar en dominios específicos como la PNL le brinda amplias oportunidades y planteamientos de problemas para explorar. A través de este artículo, deseo presentarles un proyecto asombroso, el modelo de detección de lenguaje usando procesamiento de lenguaje natural. Esto lo llevará a través de un ejemplo del mundo real de ML (aplicación para decir). Entonces, no esperemos más.
Sobre el conjunto de datos
Estamos usando el Conjunto de datos de detección de idioma, que contiene detalles de texto para 17 idiomas diferentes.
Los idiomas son:
* Inglés
* Portugués
* Francés
* Griego
* Holandés
* Español
* Japonés
* Ruso
* Danés
* Italiano
* Turco
* Sueco
* Arábica
* Malayalam
* Hindi
* Tamil
* Telugu
Usando el texto tenemos que crear un modelo que podrá predecir el idioma dado. Esta es una solución para muchas aplicaciones de inteligencia artificial y lingüistas computacionales. Este tipo de sistemas de predicción se utilizan ampliamente en dispositivos electrónicos como móviles, portátiles, etc. para traducción automática y también en robots. También ayuda a rastrear e identificar documentos multilingües. El dominio de la PNL sigue siendo un área activa de investigadores.
Implementación
Importación de bibliotecas y conjuntos de datos
Entonces empecemos. En primer lugar, importaremos todas las bibliotecas necesarias.
import pandas as pd
import numpy as np
import re
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.simplefilter("ignore")
Ahora importemos el conjunto de datos de detección de idioma
data = pd.read_csv("Language Detection.csv")
data.head(10)
Como les dije anteriormente, este conjunto de datos contiene detalles de texto para 17 idiomas diferentes. Así que contemos el recuento de valores para cada idioma.
data["Language"].value_counts()
Producción :
English 1385 French 1014 Spanish 819 Portugeese 739 Italian 698 Russian 692 Sweedish 676 Malayalam 594 Dutch 546 Arabic 536 Turkish 474 German 470 Tamil 469 Danish 428 Kannada 369 Greek 365 Hindi 63 Name: Language, dtype: int64
Separación de características independientes y dependientes
Ahora podemos separar las variables dependientes e independientes, aquí los datos de texto son la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... independiente y el nombre del idioma es la variable dependiente.
X = data["Text"] y = data["Language"]
Codificación de etiquetas
Nuestra variable de salida, el nombre de los idiomas, es una variable categórica. Para entrenar el modelo, deberíamos tener que convertirlo en una forma numérica, por lo que estamos realizando la codificación de etiquetas en esa variable de salida. Para este proceso, estamos importando LabelEncoder de sklearn.
from sklearn.preprocessing import LabelEncoder le = LabelEncoder() y = le.fit_transform(y)
Preprocesamiento de texto
Este es un conjunto de datos creado usando el raspado de Wikipedia, por lo que contiene muchos símbolos no deseados, números que afectarán la calidad de nuestro modelo. Entonces deberíamos realizar técnicas de preprocesamiento de texto.
# creating a list for appending the preprocessed text
data_list = []
# iterating through all the text
for text in X:
# removing the symbols and numbers
text = re.sub(r'[[email protected]#$(),n"%^*?:;~`0-9]', ' ', text)
text = re.sub(r'[[]]', ' ', text)
# converting the text to lower case
text = text.lower()
# appending to data_list
data_list.append(text)
Bolsa de palabras
Como todos sabemos, no solo la función de salida, sino también la función de entrada deben ser de forma numérica. Entonces, estamos convirtiendo texto en forma numérica creando un modelo de Bolsa de palabras usando CountVectorizer.
from sklearn.feature_extraction.text import CountVectorizer cv = CountVectorizer() X = cv.fit_transform(data_list).toarray() X.shape # (10337, 39419)
División de prueba de tren
Preprocesamos nuestra variable de entrada y salida. El siguiente paso es crear el conjunto de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina...., para entrenar el modelo y el conjunto de prueba, para evaluar el conjunto de prueba. Para este proceso, estamos usando una división de prueba de tren.
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)
Entrenamiento y predicción de modelos
Y ya casi llegamos, la parte de creación del modelo. Estamos utilizando el algoritmo naive_bayes para la creación de nuestro modelo. Posteriormente estamos entrenando el modelo usando el conjunto de entrenamiento.
from sklearn.naive_bayes import MultinomialNB model = MultinomialNB() model.fit(x_train, y_train)
Por eso, hemos entrenado nuestro modelo con el conjunto de entrenamiento. Ahora vamos a predecir la salida del conjunto de prueba.
y_pred = model.predict(x_test)
Evaluación del modelo
Ahora podemos evaluar nuestro modelo
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
ac = accuracy_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
print("Accuracy is :",ac)
# Accuracy is : 0.9772727272727273
La precisión del modelo es 0,97, lo cual es muy bueno y nuestro modelo está funcionando bien. Ahora tracemos la matriz de confusión usando el mapa de calorUn "mapa de calor" es una representación gráfica que utiliza colores para mostrar la densidad de datos en un área específica. Comúnmente utilizado en análisis de datos, marketing y estudios de comportamiento, este tipo de visualización permite identificar patrones y tendencias rápidamente. A través de variaciones cromáticas, los mapas de calor facilitan la interpretación de grandes volúmenes de información, ayudando a la toma de decisiones informadas.... de seaborn.
plt.figure(figsize=(15,10)) sns.heatmap(cm, annot = True) plt.show()
El gráfico se verá así:

Al analizar cada idioma, casi todas las predicciones son correctas. Y si !! ya casi has llegado !!
Predecir con más datos
Ahora probemos la predicción del modelo usando texto en diferentes idiomas.
def predict(text):
x = cv.transform([text]).toarray() # converting text to bag of words model (Vector)
lang = model.predict(x) # predicting the language
lang = le.inverse_transform(lang) # finding the language corresponding the the predicted value
print("The langauge is in",lang[0]) # printing the language
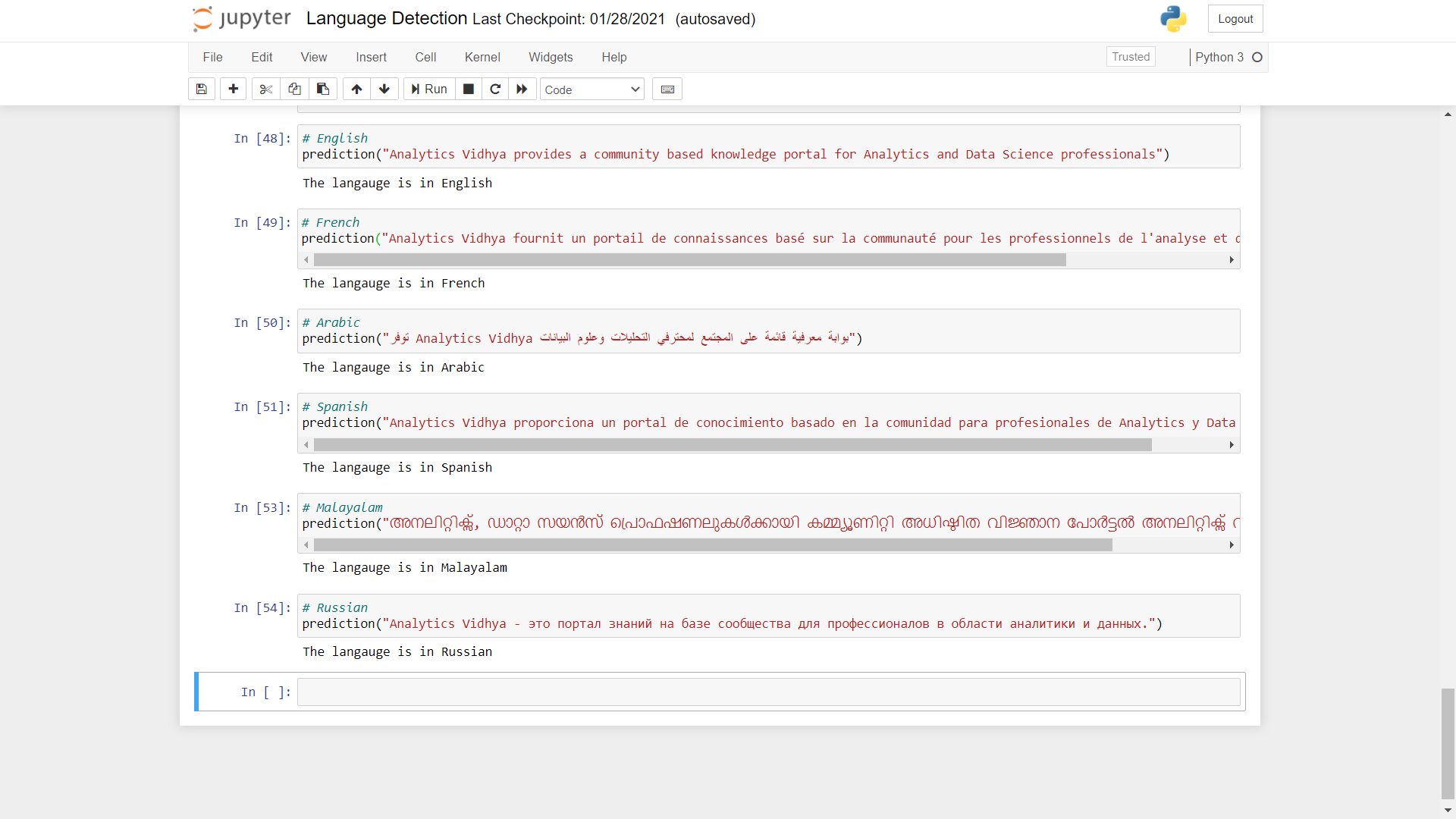
Como puede ver, las predicciones realizadas por el modelo son muy precisas. Puede realizar la prueba utilizando otros idiomas diferentes.
Código completo
import pandas as pd
import numpy as np
import re
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
warnings.simplefilter("ignore")
# Loading the dataset
data = pd.read_csv("Language Detection.csv")
# value count for each language
data["Language"].value_counts()
# separating the independent and dependant features
X = data["Text"]
y = data["Language"]
# converting categorical variables to numerical
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
y = le.fit_transform(y)
# creating a list for appending the preprocessed text
data_list = []
# iterating through all the text
for text in X:
# removing the symbols and numbers
text = re.sub(r'[[email protected]#$(),n"%^*?:;~`0-9]', ' ', text)
text = re.sub(r'[[]]', ' ', text)
# converting the text to lower case
text = text.lower()
# appending to data_list
data_list.append(text)
# creating bag of words using countvectorizer
from sklearn.feature_extraction.text import CountVectorizer
cv = CountVectorizer()
X = cv.fit_transform(data_list).toarray()
#train test splitting
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size = 0.20)
#model creation and prediction
from sklearn.naive_bayes import MultinomialNB
model = MultinomialNB()
model.fit(x_train, y_train)
# prediction
y_pred = model.predict(x_test)
# model evaluation
from sklearn.metrics import accuracy_score, confusion_matrix
ac = accuracy_score(y_test, y_pred)
cm = confusion_matrix(y_test, y_pred)
# visualising the confusion matrix
plt.figure(figsize=(15,10))
sns.heatmap(cm, annot = True)
plt.show()
# function for predicting language
def predict(text):
x = cv.transform([text]).toarray()
lang = model.predict(x)
lang = le.inverse_transform(lang)
print("The langauge is in",lang[0])
# English
prediction("DataPeaker provides a community based knowledge portal for Analytics and Data Science professionals")
# French
prediction("DataPeaker fournit un portail de connaissances basé sur la communauté pour les professionnels de l'analyse et de la science des données")
# Arabic
prediction("توفر DataPeaker بوابة معرفية قائمة على المجتمع لمحترفي التحليلات وعلوم البيانات")
# Spanish
prediction("DataPeaker proporciona un portal de conocimiento basado en la comunidad para profesionales de Analytics y Data Science.")
# Malayalam
prediction("അനലിറ്റിക്സ്, ഡാറ്റാ സയൻസ് പ്രൊഫഷണലുകൾക്കായി കമ്മ്യൂണിറ്റി അധിഷ്ഠിത വിജ്ഞാന പോർട്ടൽ അനലിറ്റിക്സ് വിദ്യ നൽകുന്നു")
# Russian
prediction("DataPeaker - это портал знаний на базе сообщества для профессионалов в области аналитики и данных.")
Conclusión
Ese fue un proyecto interesante, ¿verdad? Espero que haya tenido una intuición sobre cómo se resuelven estos proyectos. Esto definitivamente le habría dado un diagrama de programas básicos de PNL. Debe analizar los datos y preprocesarlos en consecuencia. Un modelo de bolsa de palabras se convierte en una forma de representar sus datos de texto. La extracción de texto y la vectorización son pasos importantes para realizar buenas predicciones en PNL. Naive Bayes siempre demuestra ser un mejor modelo en tales problemas de clasificación de texto, por lo que obtenemos resultados más precisos.
También puede encontrar el proyecto completo de principio a fin para el modelo de detección de idioma anterior en mi Github
Gracias por mostrar interés en el proyecto, espero que continúe con proyectos más sorprendentes y se familiarice con las declaraciones de problemas de la vida real. Siéntete libre de conectarte conmigo en LinkedIn.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





