Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
Muchas empresas todavía creen en la creación de su propio marco para la canalización de datos y no utilizan las herramientas existentes a pesar de que eso requiere una amplia gama de habilidades. La forma tradicional de realizar ETL es hacerlo manualmente con código y no es un trabajo de una sola persona. El ETL tradicional puede considerarse un cuello de botella, pero eso no significa que sea invaluable.. ¡Entendamos el escenario actual aquí!
ETL en pocas palabras
Como entusiastas de los datos, todos debemos habernos encontrado con frecuencia con este término al tratar con datos todos los días, ¿verdad? Por lo general, los ingenieros de datos se encargan de todo este trabajo, pero incluso los analistas de datos, los científicos de datos y los ingenieros de inteligencia empresarial deben tener experiencia práctica.. No todas las empresas proporcionarán datos limpios para realizar análisis e informes directamente; algunas esperarán trabajar en colaboración con los ingenieros de datos para crear canalizaciones de datos finales escalables y eficientes.
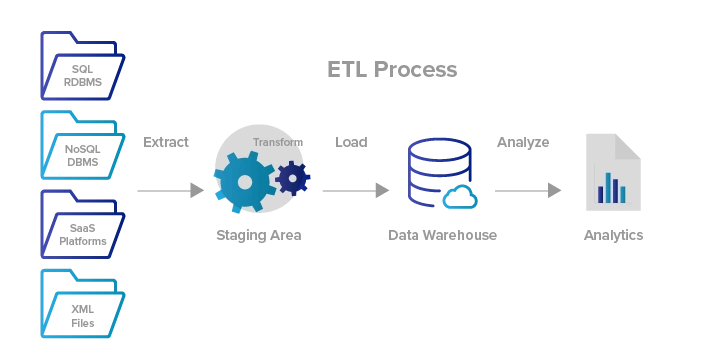
¿Por qué está tan publicitado?
Las grandes empresas contratan especialmente a desarrolladores ETL, especialistas en ETL que solo gestionan la integración de datos y diseñan el almacenamiento de datos para ellos. El proceso de 3 pasos parece simple, pero detrás de escena, hay cientos de cosas extremadamente engorrosas para manejar la extracción de datos de varias fuentes, especialmente los datos en sí se han vuelto mucho más grandes y desordenados.
Es la parte más desafiante de todo el flujo de datos y no puede permitirse el lujo de manejar mal información crucial antes de pasar al siguiente paso. Después de transformar los datos limpios y validados en la forma deseada, es seguro almacenarlos en el almacén de datos para fines de análisis y modelado de datos. Varios riesgos están involucrados durante las etapas iniciales de la fase de producción y es por eso que se pagan más. Conocer la entrada y salida de datos es la base básica para cualquier función relacionada con los datos y es obligatorio tener una idea básica de cómo utilizar los datos de forma inteligente con los recursos disponibles..
¿Cómo realizar ETL?
Hay diferentes flujos de trabajo en la canalización de datos y se pueden realizar de 2 formas:
- Talend
- Informatica
- Alteryx
- SSIS
- Amazon Redshift
- Xplenty
- QlikSense
- Pitón
- R
- SQL
- Java
- Cerdo apache
ETL sin código frente a ETL manual
Una plataforma ETL sin código requiere poca o ninguna codificación. Las herramientas proporcionan GUI fáciles de usar con varias funcionalidades para crear un mapa de datos. Una vez que el mapa de datos está completo, los equipos solo tienen que ejecutar el proceso y el servidor hará su trabajo. El proceso es fácil de entender por los clientes y fácil de mantener. Es escalable y ahorra mucho tiempo y dinero a las empresas que manejan conjuntos de datos en tiempo real. La lógica es reutilizable para cualquier fuente de datosUna "fuente de datos" se refiere a cualquier lugar o medio donde se puede obtener información. Estas fuentes pueden ser tanto primarias, como encuestas y experimentos, como secundarias, como bases de datos, artículos académicos o informes estadísticos. La elección adecuada de una fuente de datos es crucial para garantizar la validez y la fiabilidad de la información en investigaciones y análisis.... y existen funciones personalizadas de manipulación de datos. Hay suscripciones y servicios ETL de pago por uso que se ejecutan en un servidor en la nube con millones de datos. Por lo tanto, la empresa debe elegir la herramienta sabiamente de acuerdo con el caso de uso y los requisitos del cliente.
Incluso los empleadores no técnicos deben estar capacitados para programar los flujos de trabajo, los trabajos y las tareas a fin de familiarizarse con la herramienta. Hay empresas que fomentan las prácticas sin código para desarrollar varios productos..
“Según la firma de investigación de TI Forrester, el mercado de plataformas de desarrollo de código bajo alcanzará un valor de $ 21,2 mil millones para 2022, creciendo a una tasa anual del 40 por ciento. Además, el 45 por ciento de los desarrolladores ya ha utilizado una plataforma de código bajo o espera hacerlo en un futuro próximo «. [1]
Codificar su propia tubería de extracción es tentador pero difícil al mismo tiempo. Muchas empresas adaptan la escritura de scripts de Python para extraer, transformar y cargar datos incluso en un entorno de nube. Se puede realizar cualquier tipo de personalización del código si algo no está disponible en la solución ETL existente. Codificar nuestro propio ETL puede ser un gran beneficio en términos de flexibilidad y optimización del rendimiento. Si hay un ingeniero de datos experto a bordo que conoce los procesos ETL, es posible ajustar el proceso ETL para que se ejecute de la manera más fluida posible. La codificación tediosa es útil en autoservicios donde uno puede realizar el preprocesamiento de datos de forma independiente.
¿Cuestiones? Cambiar el código y mantener los scripts puede ser un gran problema si ETL no funciona bien para esquemas complejos. La automatización del ETL manual requiere otras herramientas como Selenium, el programador de tareas de Windows para ejecutar automáticamente scripts de forma diaria o semanal para almacenar datos en Excel o en una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos..... Por lo tanto, están diseñados para un conjunto específico de usuarios y operaciones de datos.
¿Te encanta jugar con datos sucios y limpiarlos?
Si le gusta experimentar con datos manualmente verificando todos los errores y normalizando los datos, entonces implementar varios paquetes de Python y R es una buena manera de hacerlo. Incluso escribir consultas SQL puede ser interesante y desafiante para extraer información de datos desordenados. Esto puede ayudar a comprender en profundidad la lógica detrás de la gestión de datos desde cero en lugar de comenzar primero con una herramienta.
Línea de fondo: Todo depende de varios parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... como el tamaño de los datos, la memoria y el presupuesto para elegir la solución óptima para los problemas comerciales. Además, la elección del enfoque ETL varía según el nivel de experiencia técnica y no técnica de una empresa.
Pensamientos finales
Este es un tema bastante debatible y ambos tienen sus ventajas y desventajas. Las herramientas ETL no están muertas, pero tampoco son preferibles por todos. Uno podría terminar ahora con una sobrecarga innecesaria de usar una herramienta ETL donde no es necesaria, que también aloja lógica comercial que no es transferible fuera de la herramienta ETL.. Pero las habilidades desarrolladas al crear canalizaciones ETL usando Python o SQL siempre se mantendrán juntas en los próximos años.
Las herramientas ETL actuales pueden pasar de moda y adaptarse a las nuevas puede resultar difícil para algunas personas. Por lo tanto, incluso las herramientas pueden convertirse en una molestia para una empresa si no se utilizan correctamente. Independientemente del ETL manual o sin código, todo el proceso en sí es complicado pero también muy interesante de aprender.
CUAL es tu favoritO? ¡Házmelo saber en los comentarios!
Gracias por leer este artículo.
Referencia
[1] Cómo las plataformas low-code están transformando el desarrollo de software
Sobre el Autor:
Saloni Somaiya trabaja como científica de datos en una startup de atención médica en los Estados Unidos. Obtuvo una maestría en sistemas de información de la Northeastern University, Boston. Le gusta leer artículos y explorar nuevas tecnologías. Ella está dispuesta a contribuir más al campo de la ciencia y el análisis de datos.
LinkedIn: https://www.linkedin.com/in/saloni-somaiya/
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





