Introducción
Hola a todos por esta práctica introducción al aprendizaje automático mediante regresión lineal simple. Entonces empecemos:
Entonces, familiaricémonos con los términos que se utilizarán:
Aprendizaje automático (ML): ML es una aplicación de Inteligencia Artificial (IA) que brinda a los sistemas la capacidad de aprender automáticamente y mejorar a partir de la experiencia sin ser programados explícitamente. ML se centra en el desarrollo de programas informáticos que pueden acceder a los datos y utilizarlos para aprender por sí mismos.
Conjunto de datos: Colección de conjuntos de información relacionados que se compone de elementos separados pero que una computadora puede manipular como una unidad.
Visualización de datos: Es una representación de datos o información en un gráfico, cuadro u otros formatos visuales que es útil para realizar análisis, como el análisis predictivo, que puede servir como visualización útil para presentar.
Limpieza de datos: Es el proceso de corregir o eliminar datos incorrectos, corruptos, formateados incorrectamente, duplicados o incompletos dentro de un conjunto de datos.
Aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en...: El modelo se entrena utilizando ‘datos etiquetados’. Se dice que los conjuntos de datos contienen etiquetas que contienen parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... de entrada y salida. Para simplificar: ‘Los datos ya están etiquetados con la respuesta correcta’.
Regresión lineal simple: Es un Modelo de Regresión que estima la relación entre la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... independiente y la variable dependiente usando una línea recta [y = mx + c], donde ambas variables deben ser cuantitativas.
Modelos: Los resultados se obtienen mediante algoritmos y se componen de datos del modelo y un algoritmo de predicción.
Modelo de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina....: En el aprendizaje supervisado, un algoritmo ML crea un modelo examinando muchos ejemplos e intentando encontrar un modelo que minimice la pérdida y mejore la precisión de la predicción.
Estos son los pocos términos que se utilizan en este artículo y con los que familiarizarse. Ahora comencemos con el análisis y la predicción del modelo. En este tutorial, usaré datos supervisados y regresión lineal simple para análisis y predicción. El objetivo final es predecir la altura de una persona y proporcionar su edad utilizando el modelo entrenado con la mayor precisión posible utilizando los datos disponibles. He usado el lenguaje de programación favorito universal para ML, es decir. Pitón para construir y entrenar el modelo ML y el entorno de Google Colab.
Los pasos involucrados son:
1. Importación del conjunto de datos.
2. Visualización de los datos
3. Limpieza de datos
4. Construya el modelo y entrénelo
5.Haga predicciones sobre datos invisibles
———————————————————————————————————————————————— ——————————
1. Importación de conjunto de datos:
Lo primero y más importante que debemos hacer es importar el conjunto de datos. Tenemos varios sitios web que tienen estos conjuntos de datos para ser utilizados por cualquier persona. De manera similar, comencemos a cómo importar el conjunto de datos que vamos a usar en este tutorial.

Esta única línea de código nos ayuda a obtener los datos utilizados para el tutorial directamente desde la URL.
Conjunto de datos <- Haga clic en el enlace para obtener el conjunto de datos que es la URL mencionada anteriormente.
2. Visualización de los datos:
En este paso, después de importar los datos y montarlos con Colab, tengamos una descripción general del conjunto de datos mediante la importación de un módulo llamado pandas. Dado que el conjunto de datos que tenemos tiene una extensión de .pkl, simplemente lo vemos por la función disponible en la biblioteca de pandas.

Importamos la biblioteca para leer el conjunto de datos y lo almacenamos en una variable llamada raw_data. Luego mostramos el contenido de raw_data que está en formato tabulado.
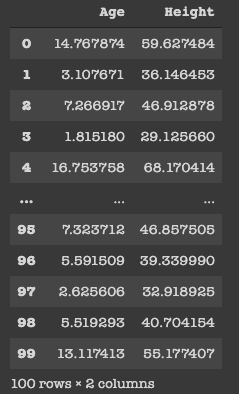
Podemos ver los datos que tenemos y contiene solo 2 columnas, a saber, Edad (en años) y Altura (en pulgadas) y 100 filas, que en realidad es la representación de una persona.
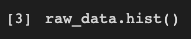
Esta única línea de código tiene un gran impacto en la forma en que miramos el conjunto de datos. Solo teníamos una vista numérica del conjunto de datos, pero ahora podemos ejecutar esta celda para obtener una vista de histograma del conjunto de datos, lo cual es muy útil. Representa los datos presentes en las columnas individuales como gráficos individuales.
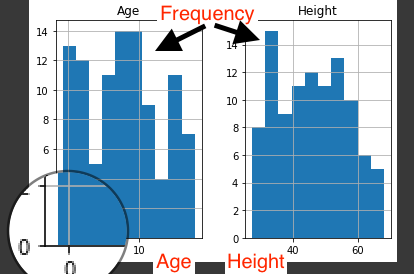
El eje Y en ambos gráficos se refiere a la frecuencia y el eje X representa Edad y Altura respectivamente.
3. Limpieza de datos:
Tenemos que construir el modelo usando conjuntos de datos válidos y limpiar los datos que no se deben rendir cuentas. En la imagen de arriba, podemos saber que hay algunas entradas que tienen una edad menor a cero, lo cual no tiene sentido. Por lo tanto, necesitamos limpiar esos datos para obtener una mayor precisión.

Yo uso variable datos_limpiados para almacenar los valores de edad válidos y mostrarlos al usuario.
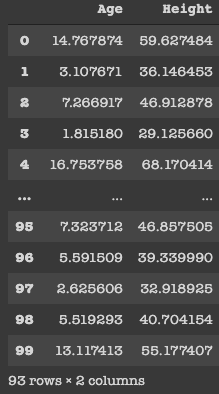
Inicialmente, teníamos 100 filas, pero después de realizar la limpieza de datos, está bastante claro que hay siete filas que tenían una edad <0 y las hemos eliminado. Como profesional, se supone que no debemos eliminar los datos, ya que los estamos reduciendo y, por lo tanto, la precisión de nuestro modelo se reduce. Para hacerlo simple, los acabo de eliminar.
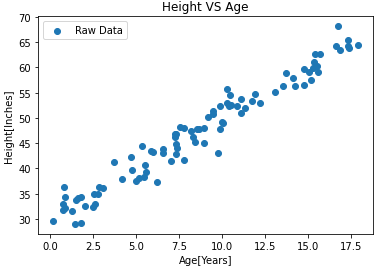
Visualice los datos limpios: ahora he utilizado los datos limpios y los visualicé en forma de gráfico.
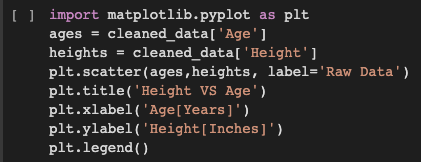
Para trazar gráficos en python, importo la biblioteca matplotlib.pyplot. Represento la edad en el eje X y la altura en el eje Y. Los puntos del gráfico se refieren a los datos brutos.
4. Construya el modelo y entrénelo:
Aquí es donde entra en juego el algoritmo ML, es decir, la regresión lineal simple.
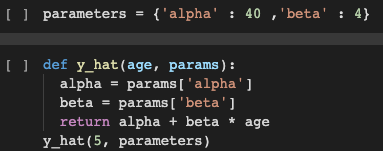
Usé un diccionario llamado parámetros que tiene alfa y beta como clave con 40 y 4 como valores respectivamente. También he definido una función y_hat que toma la edad y los parámetros como parámetros. Esta función usa la ecuación básica en línea recta y devuelve y, es decir, altura como en nuestro caso. Si pasamos los parámetros requeridos y ejecutamos la función, encontramos que la altura que obtenemos para la edad como entrada no coincide. Por lo tanto, usamos la función que se menciona a continuación para hacer llover el modelo.
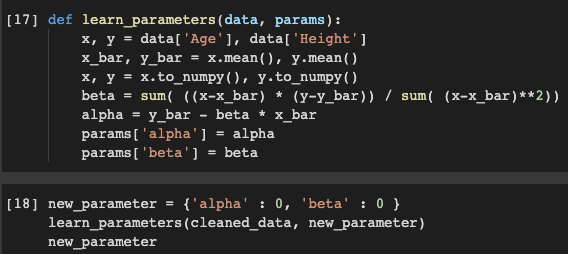
Aquí es donde usamos un método para encontrar el alfa y el beta correctos. La función aprender_parámetros acepta datos_limpiados y un diccionario ficticio new_parameter que puede tener cualquier valor para alfa y beta. Entonces, cuando los pasamos como argumentos a los parámetros y la función se ejecuta, podemos obtener el valor correcto de alfa y beta que se encuentra cerca de 30 y 2 respectivamente y reemplazar los valores antiguos por los nuevos.
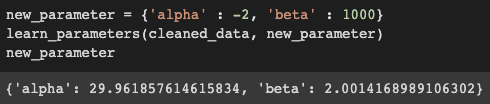
Hemos encontrado con precisión los valores de alfa y beta, y nuestro próximo objetivo es entrenar los datos. Pero permítanme los valores predichos no entrenados hasta qué punto son precisos.

Yo uso una lista llamada edades_espaciales que tiene valores de 0 a 18 (final – 1). Luego otra lista llamada spaced_untrained_predictions que tiene los valores predichos para la altura utiliza el y_hat función definida anteriormente para predecirlo. Estos valores se trazan en un gráfico y se visualizan.
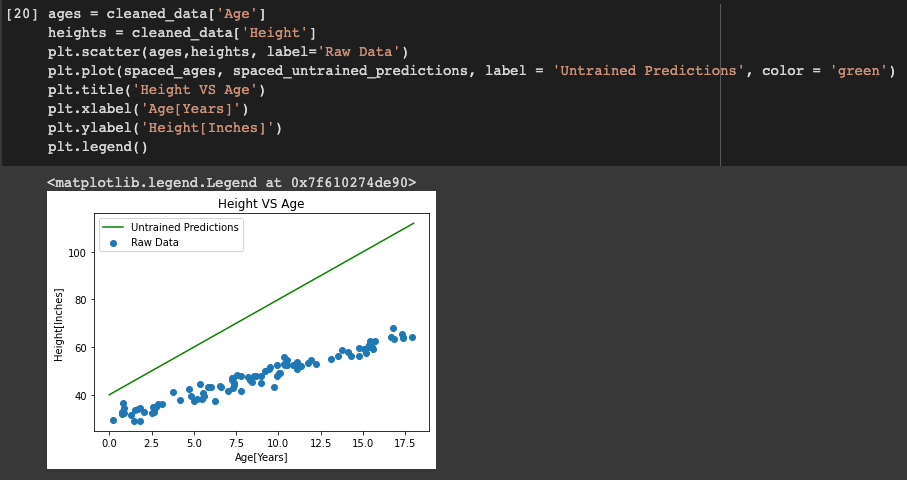
La línea verde muestra que el spaced_untrained_predictions se han desviado en gran medida de los valores reales y la precisión es muy pobre. Por lo tanto, es necesario aumentar la precisión para lo cual debemos entrenar los datos.

Entonces en lugar de usar parámetros usamos nuevos_parámetros ya que contiene el valor exacto de alfa y beta y lo almacena en una lista llamada spaced_trained_predictions. Entonces, cuando trazamos un gráfico para esto, podemos ver una diferencia visible y la precisión ha aumentado mucho. Por lo tanto, hemos construido y entrenado con éxito el modelo. Prueba de ello son los valores de spaced_trained_predictions y el gráfico.
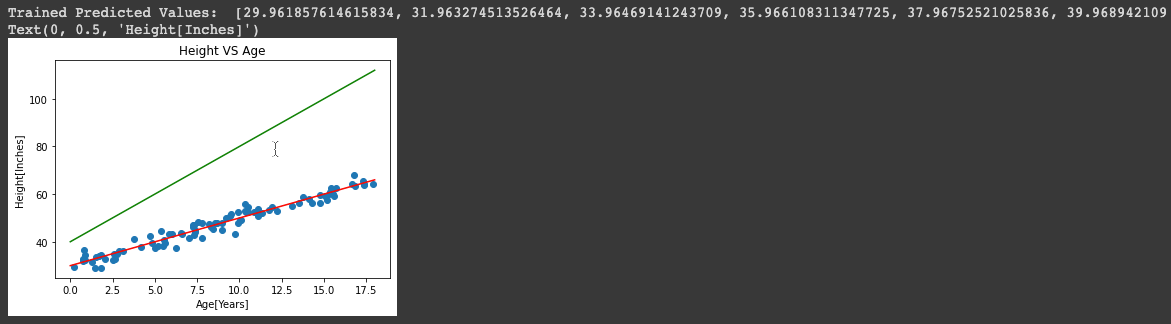
La Greenline se refiere a los valores de spaced_untrained_predictions y Redline se refiere a los valores de spaced_trained_predictions.
5.Haga predicciones sobre datos invisibles:
Con la ayuda de este modelo entrenado, ahora podemos hacer predicciones precisas.

Entonces, podemos ver que para cualquier edad dada encontramos la altura posible en pulgadas. Finalmente, hemos entrenado el modelo con éxito y con la máxima precisión, que es el objetivo final de este tutorial.
Como referencia, he pegado el Enlace al cuaderno juegas con él. Espero conectarme a través de LinkedIn también y comparta sus valiosos comentarios. Estén atentos para más blogs de este tipo😊.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





