«Así como los atletas no pueden ganar sin una combinación sofisticada de estrategia, forma, actitud, tácticas y velocidad, la ingeniería de rendimiento requiere una buena colección de métricas y herramientas para ofrecer los resultados comerciales deseados».– Todd DeCapua
Introducción:
A lo largo de los años, la adopción del aprendizaje automático para impulsar las decisiones comerciales ha aumentado exponencialmente. Según Forbes, se proyecta que ML crezca a $ 30.6 mil millones para 2024 y no es sorprendente ver la gran cantidad de soluciones de ML personalizadas que invaden el mercado que abordan necesidades comerciales específicas. La facilidad de disponibilidad de los poderes informáticos, la infraestructura y la automatización en la nube lo ha acelerado aún más.
La tendencia actual de aprovechar los poderes de ML en los negocios ha hecho que los científicos e ingenieros de datos diseñen soluciones / servicios innovadores y uno de esos servicios ha sido Model As A Service (MaaS). Hemos utilizado muchos de estos servicios sin el conocimiento de cómo se construyeron o sirvieron en la web, algunos ejemplos incluyen visualización de datos, reconocimiento facial, procesamiento de lenguaje natural, análisis predictivo y más. En resumen, MaaS encapsula todos los datos complejos, entrenamiento y evaluación de modelos, implementación, etc., y permite a los clientes consumirlos para su propósito.
Por muy simple que parezca utilizar estos servicios, existen muchos desafíos en la creación de dicho servicio, por ejemplo: ¿cómo mantenemos el servicio? ¿Cómo nos aseguramos de que la precisión de nuestro modelo no disminuya con el tiempo? etc. Al igual que con cualquier servicio o aplicación, un factor importante a considerar es la carga o el tráfico que un servicio / API puede manejar para asegurar su tiempo de actividad. La mejor característica de la API es tener un gran rendimiento y la única forma de probar esto es presionando la API para ver cómo responde. Esta es la prueba de carga.
En este blog, no solo veremos cómo se construye dicho servicio, sino también cómo probar la carga del servicio para planificar los requisitos de hardware / infraestructura en el entorno de producción. Intentaremos lograrlo en el siguiente orden:
- Cree una API simple con FastAPI
- Construye un modelo de clasificación en Python
- Envuelva el modelo con FastAPI
- Pruebe la API con el cliente Postman
- Prueba de carga con Locust
Empecemos !!
Creando una API web simple usando FastAPI:
El siguiente código muestra la implementación básica de FastAPI. El código se utiliza para crear una API web simple que, al recibir una entrada en particular, produce una salida específica. Aquí está la división del código:
- Cargar las bibliotecas
- Crea un objeto de aplicación
- Crea una ruta con @ app.get ()
- Escriba una función de controlador que tenga un host y un número de puerto definidos
from fastapi import FastAPI, Request
from typing import Dict
from pydantic import BaseModel
import uvicorn
import numpy as np
import pickle
import pandas as pd
import json
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Built with FastAPI"}
if __name__ == '__main__':
uvicorn.run(app, host="127.0.0.1", port=8000)
Una vez ejecutado, puede navegar hasta el navegador con la URL: http: // localhost: 8000 y observe el resultado que en este caso será ‘ Construido con FastAPI ‘
Creando una API a partir de un modelo ML usando FastAPI:
Ahora que tiene una idea clara de FastAPI, veamos cómo puede envolver un modelo de aprendizaje automático (desarrollado en Python) en una API en Python. Utilizaré el conjunto de datos (diagnóstico) de cáncer de mama de Wisconsin. El objetivo de este proyecto de ML es predecir si una persona tiene un tumor benigno o maligno. Yo usaré VSCode como mi editor y tenga en cuenta que probaremos nuestro servicio con Cartero Cliente. Estos son los pasos que seguiremos.
- Primero construiremos nuestro modelo de clasificación: KNeighborsClassifier ()
- Construya nuestro archivo de servidor que tendrá lógica para API en el FlastAPI estructura.
- Finalmente, probaremos nuestro servicio con Cartero
Paso 1: Modelo de clasificación
Un modelo de clasificación simple con el proceso estándar de cargar datos, dividir los datos en tren / prueba, seguido de la construcción del modelo y guardar el modelo en el formato pickle en la unidad. No voy a entrar en los detalles de la construcción del modelo, ya que el artículo trata sobre las pruebas de carga.
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import joblib, pickle
import os
import yaml
# folder to load config file
CONFIG_PATH = "../Configs"
# Function to load yaml configuration file
def load_config(config_name):
"""[The function takes the yaml config file as input and loads the the config]
Args:
config_name ([yaml]): [The function takes yaml config as input]
Returns:
[string]: [Returns the config]
"""
with open(os.path.join(CONFIG_PATH, config_name)) as file:
config = yaml.safe_load(file)
return config
config = load_config("config.yaml")
#path to the dataset
filename = "../../Data/breast-cancer-wisconsin.csv"
#load data
data = pd.read_csv(filename)
#replace "?" with -99999
data = data.replace('?', -99999)
# drop id column
data = data.drop(config["drop_columns"], axis=1)
# Define X (independent variables) and y (target variable)
X = np.array(data.drop(config["target_name"], 1))
y = np.array(data[config["target_name"]])
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=config["test_size"], random_state= config["random_state"]
)
# call our classifier and fit to our data
classifier = KNeighborsClassifier(
n_neighbors=config["n_neighbors"],
weights=config["weights"],
algorithm=config["algorithm"],
leaf_size=config["leaf_size"],
p=config["p"],
metric=config["metric"],
n_jobs=config["n_jobs"],
)
# training the classifier
classifier.fit(X_train, y_train)
# test our classifier
result = classifier.score(X_test, y_test)
print("Accuracy score is. {:.1f}".format(result))
# Saving model to disk
pickle.dump(classifier, open('../../FastAPI//Models/KNN_model.pkl','wb'))
Puede acceder al código completo desde Github
Paso 2: compila la API con FastAPI:
Construiremos sobre el ejemplo básico que hicimos en una sección anterior.
Cargue las bibliotecas:
from fastapi import FastAPI, Request from typing import Dict from pydantic import BaseModel import uvicorn import numpy as np import pickle import pandas as pd import json
Cargue el modelo KNN guardado y escriba una función de enrutamiento para devolver el JsonJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software...:
app = FastAPI()
@app.get("/")
async def root():
return {"message": "Hello World"}
# Load the model
# model = pickle.load(open('../Models/KNN_model.pkl','rb'))
model = pickle.load(open('../Models/KNN_model.pkl','rb'))
@app.post('/predict')
def pred(body: dict):
"""[summary]
Args:
body (dict): [The pred methos takes Response as input which is in the Json format and returns the predicted value from the saved model.]
Returns:
[Json]: [The pred function returns the predicted value]
"""
# Get the data from the POST request.
data = body
varList = []
for val in data.values():
varList.append(val)
# Make prediction from the saved model
prediction = model.predict([varList])
# Extract the value
output = prediction[0]
#return the output in the json format
return {'The prediction is ': output}
# 5. Run the API with uvicorn
# Will run on http://127.0.0.1:8000
if __name__ == '__main__':
"""[The API will run on the localhost on port 8000]
"""
uvicorn.run(app, host="127.0.0.1", port=8000)
Puede acceder al código completo desde Github.
Utilizando Postman Client:
En nuestra sección anterior, creamos una API simple en la que al presionar el http: // localhost: 8000 en el navegador obtuvimos un mensaje de salida «Built with FastAPI». Esto está bien siempre que la salida sea más simple y se espere una entrada del usuario o del sistema. Pero estamos construyendo un modelo como servicio en el que enviamos datos como entrada para que el modelo los prediga. En tal caso, necesitaremos una forma mejor y más fácil de probarlo. Usaremos cartero para probar nuestra API.
- Ejecute el archivo server.py
- Abra el cliente Postman y complete los detalles relevantes que se resaltan a continuación y presione el botón enviar.
- Observe el resultado en la sección de respuesta a continuación.
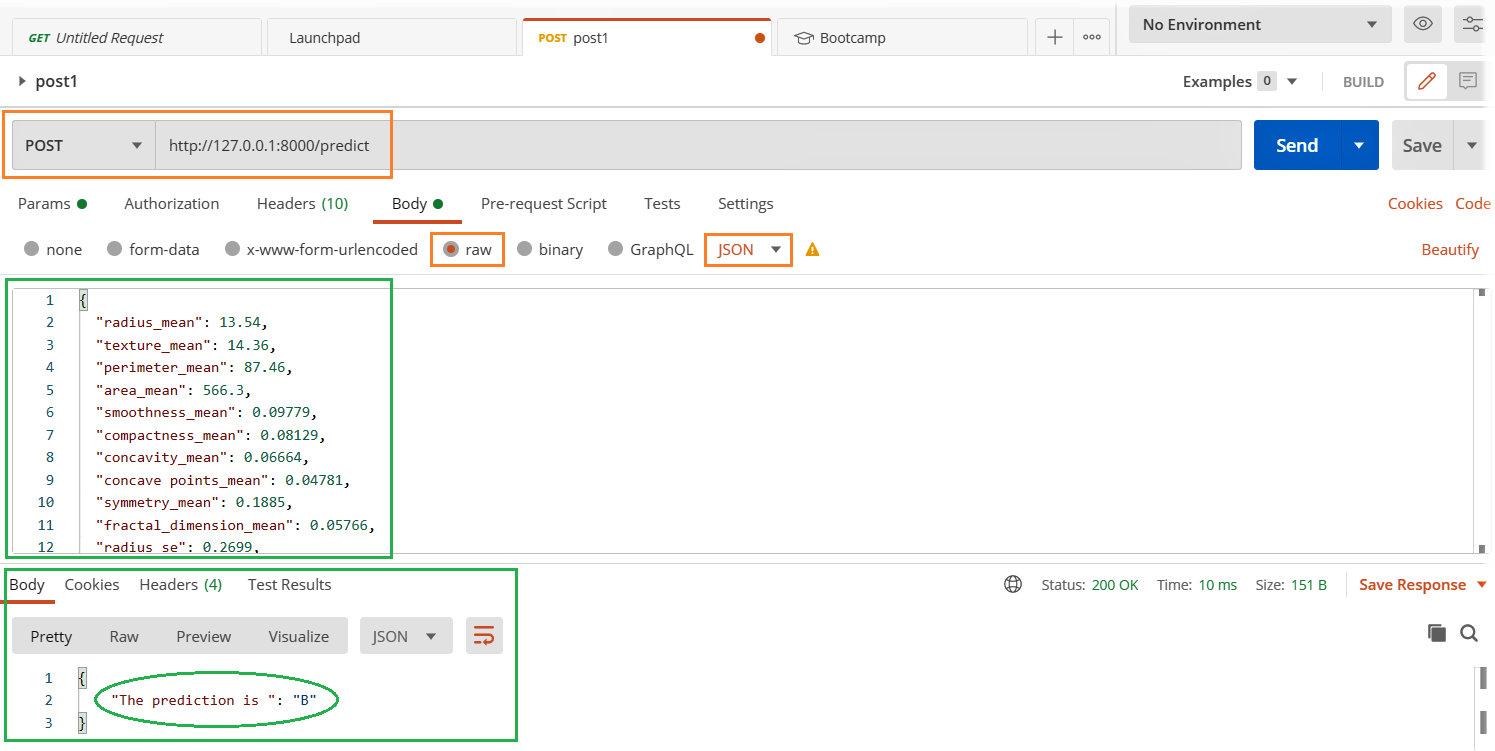
¿Son sus aplicaciones y servicios estables bajo carga máxima?
Tiempo para la prueba de carga:
Exploraremos la biblioteca Locust para realizar pruebas de carga y la forma más fácil de instalar Langosta es
pip install locust
Creemos un perf.py archivo con el siguiente código. Me he referido al código Inicio rápido página de langosta
import time
import json
from locust import HttpUser, task, between
class QuickstartUser(HttpUser):
wait_time = between(1, 3)
@task(1)
def testFlask(self):
load = {
"radius_mean": 13.54,
"texture_mean": 14.36,
......
......
"fractal_dimension_worst": 0.07259}
myheaders = {'Content-Type': 'application/json', 'Accept': 'application/json'}
self.client.post("/predict", data= json.dumps(load), headers=myheaders)
Acceda al archivo de código completo desde Github
Iniciar langosta: Navegue al directorio de perf.py y ejecute el siguiente código.
locust -f perf.py
Interfaz web Locust:
Una vez que haya iniciado Locust con el comando anterior, navegue hasta un navegador y apúntelo a http: // localhost: 8089. Debería ver la siguiente página:
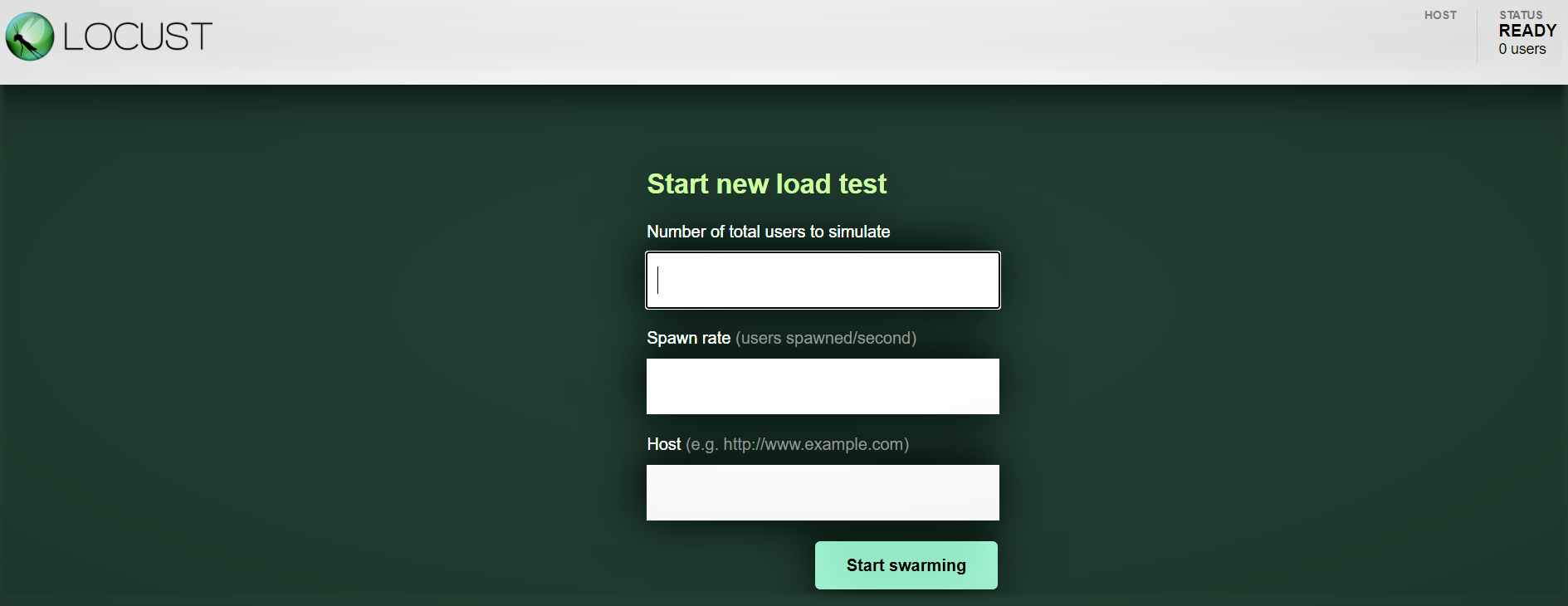
Probemos con 100 usuarios, proporción de generación de 3 y host: http: 127.0.0.1: 8000 donde se está ejecutando nuestra API. Puede ver la siguiente pantalla. Puede ver el aumento de la carga a lo largo del tiempo y el tiempo de respuesta, una representación gráfica muestra el tiempo medio y otras métricas.
Nota: asegúrese de que server.py se esté ejecutando.

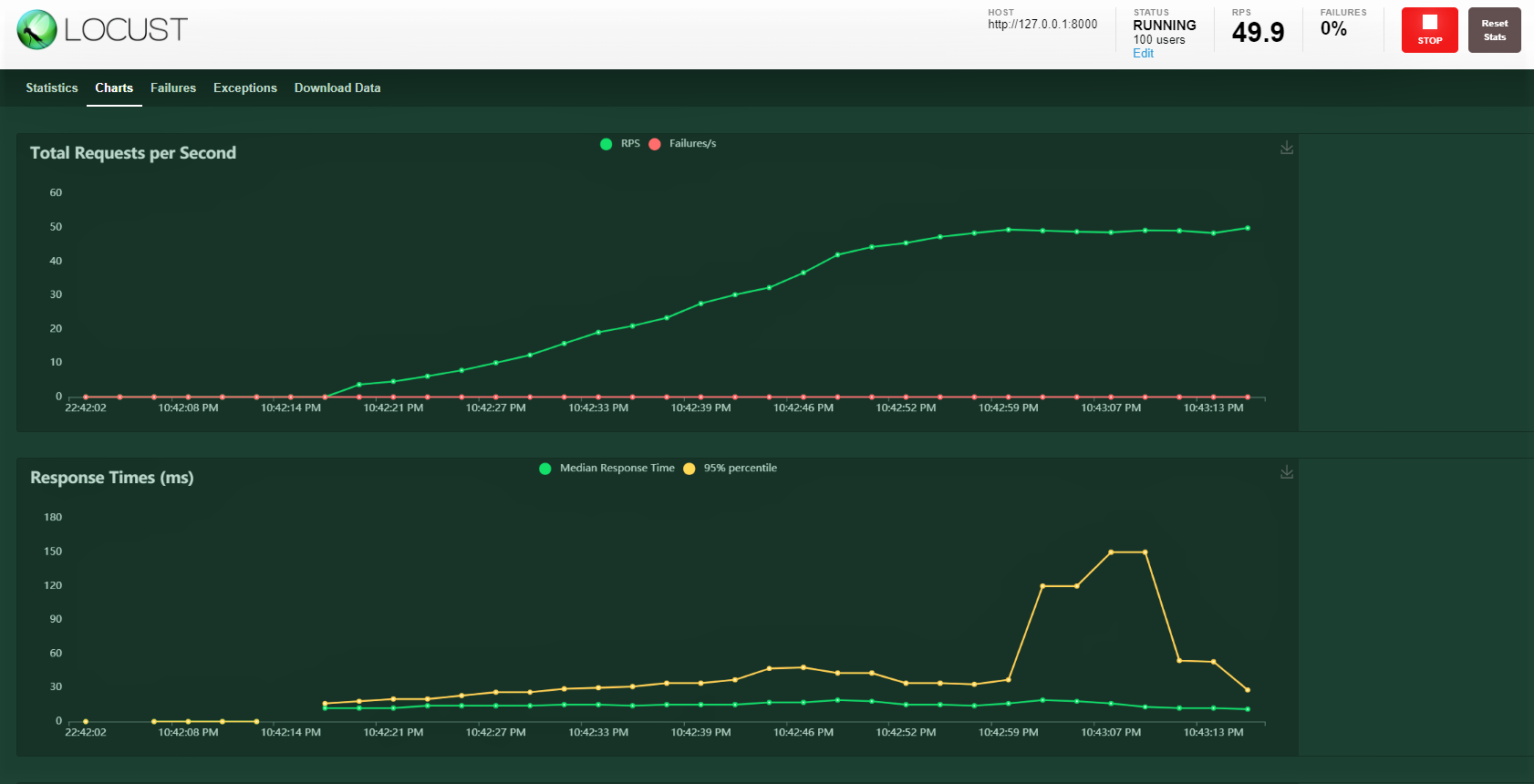
Conclusión:
Cubrimos bastante en este blog, desde la construcción de un modelo, el cierre con una FastAPI, la prueba del servicio con el cartero y finalmente la realización de una prueba de carga con 100 usuarios simulados que acceden a nuestro servicio con una carga que aumenta gradualmente. Pudimos monitorear cómo está respondiendo el servicio.
La mayoría de las veces hay SLA de nivel empresarial que deben cumplirse, es decir, mantener un cierto umbral para un tiempo de respuesta como 30ms o 20ms. Si no se cumplen los SLA, existen posibles implicaciones financieras según el contrato o la pérdida de clientes, ya que no recibieron el servicio con la suficiente rapidez.
Una prueba de carga nos ayuda a comprender los puntos máximos y potenciales de falla. Luego, podemos planificar una acción proactiva aumentando nuestra capacidad de hardware y, si el servicio se implementa en el tipo de configuración de Kubernetes, configurarlo para aumentar la cantidad de pods al aumentar la carga.
¡¡¡Felices aprendizajes !!!!
Puedes conectarte conmigo – Linkedin
Puede encontrar el código como referencia: Github
Referencias
https://docs.locust.io/en/stable/quickstart.html
https://fastapi.tiangolo.com/
https://unsplash.com/
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





