Introducción
Repositorios de GitHub y discusiones de Reddit: ambas plataformas han jugado un papel clave en mi aprendizaje automático viaje. Me han ayudado a desarrollar mi conocimiento y comprensión de las técnicas de aprendizaje automático y mi perspicacia empresarial.
Tanto GitHub como Reddit también me mantienen al tanto de los últimos desarrollos en aprendizaje automático, ¡algo que debe tener cualquier persona que trabaje en este campo!
Y si eres un programador, bueno, GitHub es como un templo para ti. Puede descargar fácilmente el código y replicarlo en su máquina. Esto facilita aún más el aprendizaje de nuevas ideas y la construcción de un conjunto de habilidades diverso.

Estoy encantado de elegir los principales repositorios de GitHub y las discusiones de Reddit de este mes. Los hilos de Reddit que he presentado tratan tanto del aspecto técnico de aprendizaje automático así como la relacionada con la carrera. Esta capacidad de combinar los dos es lo que separa a los expertos en aprendizaje automático de los aficionados.
A continuación se muestran los artículos mensuales que hemos cubierto hasta ahora en esta serie:
Así que, ¡pongamos manos a la obra para marzo!
Repositorios de GitHub

Si tuviera que elegir una de las razones de mi fascinación por visión por computador, serían GANs (Generative Adversarial Networks). Fueron inventados por Ian Goodfellow hace solo unos años y se han convertido en todo un cuerpo de investigación. ¿El arte de IA reciente que has visto en las noticias? Todo funciona con GAN.

DeepMind ideó el concepto de BigGAN el año pasado, pero hemos esperado un tiempo para una implementación de PyTorch. Este repositorio también incluye modelos previamente entrenados (128 × 128, 256 × 256 y 512 × 512). Puede instalar esto en solo una línea de código:
pip install pytorch-pretrained-biggan
Y si está interesado en leer el artículo de investigación completo de BigGAN, visite aquí.
La capacidad de trabajar con datos de imágenes se está convirtiendo en un rasgo definitorio para cualquier persona interesada en aprendizaje profundo. El advenimiento y el rápido florecimiento de los algoritmos de visión por computadora ha jugado un papel importante en esta transformación. No le sorprenderá saber que NVIDIA es uno de los principales líderes en este ámbito.
Solo echa un vistazo a sus desarrollos de 2018:
Y ahora, la gente de NVIDIA ha creado otro lanzamiento sorprendente: la capacidad de sintetizar imágenes fotorrealistas con un diseño semántico de entrada. ¿Que tan bueno es? La siguiente comparación proporciona una buena ilustración:

SPADE ha superado los métodos existentes en el popular conjunto de datos COCO. El repositorio que hemos vinculado anteriormente albergará la implementación de PyTorch y los modelos previamente entrenados para esta técnica (asegúrese de marcarlo como favorito).
Este video muestra lo bien que funciona SPADE en 40.000 imágenes extraídas de Flickr:
Este repositorio se basa en el ‘Segmentación y seguimiento rápido de objetos en línea: un enfoque unificador‘ papel. Aquí hay un resultado de muestra usando esta técnica:

¡Impresionante! La técnica, llamada SiamMask, es bastante sencilla, versátil y extremadamente rápida. Oh, ¿mencioné que el seguimiento de objetos se realiza en tiempo real? Eso ciertamente llamó mi atención. Este repositorio también contiene modelos previamente entrenados para que pueda comenzar.
El trabajo se presentará en la prestigiosa conferencia CVPR 2019 (Computer Vision and Pattern Recognition) en junio. Los autores han demostrado su enfoque en el siguiente video:
¿Ha trabajado alguna vez en un proyecto de detección de pose? Lo he hecho y déjame decirte que es excelente. Es un testimonio del progreso que hemos logrado como comunidad en el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud.... ¿Quién hubiera pensado hace 10 años que seríamos capaces de predecir el próximo movimiento corporal de una persona?
Este repositorio de GitHub es un PyTorch implementacion de ‘Aprendizaje auto-supervisado de la pose humana 3D usando geometría de múltiples vistas‘ papel. Los autores han sido pioneros en una nueva técnica llamada EpipolarPose, un método de aprendizaje auto-supervisado para estimar la pose de un ser humano en 3D.
La técnica EpipolarPose estima las poses 2D a partir de imágenes de múltiples vistas durante la fase de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina..... Luego usa geometría epipolar para generar una pose 3D. Esto, a su vez, se utiliza para entrenar el estimadorEl "Estimador" es una herramienta estadística utilizada para inferir características de una población a partir de una muestra. Se basa en métodos matemáticos para proporcionar estimaciones precisas y confiables. Existen diferentes tipos de estimadores, como los insesgados y los consistentes, que se eligen según el contexto y el objetivo del estudio. Su correcto uso es fundamental en investigaciones científicas, encuestas y análisis de datos.... de pose 3D. Este proceso se ilustra en la imagen de arriba.
Este artículo también ha sido aceptado en la conferencia CVPR 2019. ¡Se perfila como una excelente alineación!
Este es un repositorio único en muchos sentidos. Es un modelo de aprendizaje profundo de código abierto para proteger su privacidad. Todo el concepto de DeepCamera se basa en el aprendizaje automático automatizado (AutoML). Por lo tanto, ni siquiera necesita experiencia en programación para entrenar un nuevo modelo.

DeepCamera funciona en dispositivos Android. También puede integrar el código con cámaras de vigilancia. Hay MUCHO que puedes hacer con el código de DeepCamera, que incluye:
- Reconocimiento facial
- Detección de rostro
- Control desde aplicación móvil
- Detección de objetos
- Detección de movimiento
Y muchas otras cosas. ¡Construir tu propio modelo impulsado por IA nunca ha sido tan fácil!
Discusiones de Reddit

He dividido las discusiones de Reddit de este mes en dos categorías:
- El lado técnico del aprendizaje automático
- Discusiones relacionadas con la carrera de aprendizaje automático (roles y trabajos)
Empecemos por el aspecto técnico.
Los científicos de datos están fascinados con los trabajos de investigación. Queremos leerlos, codificarlos y tal vez incluso escribir uno desde cero. ¿Qué tan genial sería presentar su propio trabajo de investigación en una conferencia de ML de primer nivel?

Ciertamente pertenezco a la categoría de «quiero escribir un artículo de investigación». Esta discusión, iniciada por un investigador veterano, profundiza en las mejores prácticas que debemos seguir al escribir un artículo de investigación. Aquí hay mucha información y experiencia, ¡una lectura obligada para todos nosotros!
Aquí esta la Repositorio de GitHub con los mejores consejos, trucos e ideas en un solo lugar. Trate estos consejos como un conjunto de pautas y no como reglas escritas en piedra.
¿Cómo pone en producción sus modelos de aprendizaje automático entrenados? ¿Cómo los implementa? Estas son preguntas MUY comunes que enfrentará en su entrevista de ciencia de datos (y el trabajo, por supuesto). Si no está seguro de qué es esto, le sugiero que lo lea AHORA.
Este hilo de discusión trata sobre una biblioteca de código abierto que convierte sus modelos de aprendizaje automático en código nativo (C, Python, Java) sin dependencias. Debe desplazarse por el hilo, ya que hay algunas preguntas comunes que el autor ha abordado en detalle.
Puedes encontrar el código completo en este repositorio de GitHub. A continuación se muestra la lista de modelos que esta biblioteca admite actualmente:
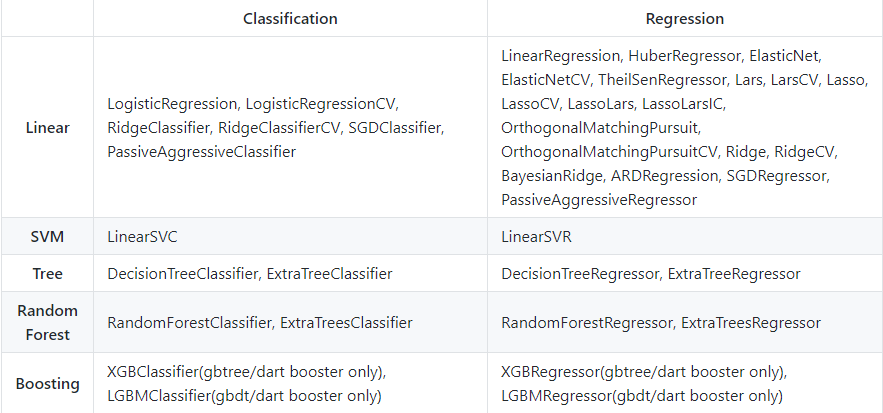
Cambiemos de enfoque ahora y veamos algunas discusiones sobre la carrera de aprendizaje automático. Estos son aplicables a TODOS los profesionales del aprendizaje automático, tanto aspirantes como establecidos.
¿La aparición del aprendizaje automático automatizado será una desventaja para el campo mismo? Esa es una pregunta sobre la que la mayoría de nosotros nos hemos estado preguntando. La mayoría de los artículos con los que me cruzo predicen todo pesimismo. ¡Algunos incluso afirman que los científicos de datos no serán necesarios en 5 años!

Fuente: Themocracy
El autor de este hilo presenta un maravilloso argumento contra el consenso general. Es muy poco probable que la ciencia de datos desaparezca debido a la automatización.
La discusión argumenta acertadamente que la ciencia de datos no se trata solo de modelado de datos. Eso es solo el 10% de todo el proceso. Una parte importante del ciclo de vida de la ciencia de datos es la intuición humana detrás de los modelos. La limpieza de datos, la visualización de datos y un toque de lógica son lo que impulsa todo este proceso.
Aquí hay una joya y un argumento sólido que llamó mi atención:
Desarrollamos todo tipo de software de estadísticas en el último siglo y, sin embargo, no ha reemplazado a los estadísticos.
¿Quiere conseguir su primer puesto en ciencia de datos? ¿Lo encuentra un proceso abrumador? He estado allí. Es uno de los mayores obstáculos a superar en nuestros respectivos viajes de ciencia de datos.
Por eso quería resaltar este hilo en particular. Es una discusión realmente reveladora, donde los profesionales de la ciencia de datos y los principiantes discuten cómo ingresar a este campo. El autor de la publicación ofrece algunos pensamientos en profundidad sobre el proceso de búsqueda de empleo de ciencia de datos junto con consejos para despejar cada ronda de entrevistas.

Una frase que realmente se destacó de esta discusión:
Recuerde, el aumento en las solicitudes de entrevistas y el aumento del conocimiento no es solo una correlación, es una causalidad. Mientras postula, aprenda algo nuevo todos los días.
En DataPeaker, nuestro objetivo es ayudarlo a conseguir su primer puesto en ciencia de datos. Consulte los increíbles recursos a continuación que lo ayudarán a comenzar:
Conocimiento del dominio: ese ingrediente clave en la receta general del científico de datos. A menudo, los aspirantes a científicos de datos lo pasan por alto o lo malinterpretan. Y eso a menudo se traduce en rechazos en las entrevistas. Entonces, ¿cómo puede desarrollar su visión para los negocios para complementar sus habilidades existentes en ciencia de datos técnicos?
Esta discusión de Reddit ofrece algunas ideas útiles. La capacidad de traducir sus ideas y sus resultados en términos comerciales es VITAL. La mayoría de las partes interesadas a las que te enfrentarás en tu carrera no entenderán la jerga técnica.
Aquí está mi selección favorita de la discusión:
Necesita conocer mejor a sus socios comerciales. Averigua qué hacen en el día a día, cuáles son sus procesos, cómo generan los datos que vas a utilizar. Si comprende cómo ven X e Y, podrá ayudarlos mejor cuando acudan a usted con problemas.
En DataPeaker creemos firmemente en la construcción de una mentalidad de pensamiento estructurado. Hemos reunido nuestra experiencia y conocimiento sobre este tema en el curso integral a continuación:
Este curso contiene varios estudios de casos que también lo ayudarán a tener una idea de cómo funcionan y piensan las empresas.
Notas finales
Disfruté especialmente las discusiones de Reddit del mes pasado. Le insto a que obtenga más información sobre cómo funciona el entorno de producción en un proyecto de aprendizaje automático. Ahora se considera casi obligatorio para un científico de datos, por lo que no puede alejarse de él.
También debe participar en estas discusiones de Reddit. El desplazamiento pasivo es bueno para adquirir conocimientos, pero agregar tu propia perspectiva también ayudará a los demás aspirantes. Este es un sentimiento intangible, pero apreciará y apreciará cuanto más experiencia obtenga.
¿Qué discusión le pareció más reveladora? ¿Y qué repositorio de GitHub se destacó para ti? ¡Házmelo saber en la sección de comentarios a continuación!





