
R ¿Estás listo? Aprendamos a agrupar en R.
http: // www.pags: //www.rstudio.com/products/rstudio/download/
Visualización de datos usando R
En los tiempos actuales, las imágenes hablan más que los números o el análisis de palabras. Sí, los gráficos y diagramas son más atractivos y fáciles de identificar para el ojo humano. Aquí es donde entra en juego la importancia del análisis de datos R. Los clientes comprenden mejor la representación gráfica de su crecimiento / evaluación / distribución de productos. Por lo tanto, la ciencia de datos está en auge hoy en día y R es uno de esos lenguajes que proporciona flexibilidad en el trazado y los gráficos, ya que tiene funciones y paquetes específicos para tales tareas. RStudio es un software donde los datos y la visualización ocurren uno al lado del otro, lo que lo hace muy favorable para un analista de datos. Los diagramas de dispersión, diagramas de cajaLos diagramas de caja, también conocidos como diagramas de caja y bigotes, son herramientas estadísticas que representan la distribución de un conjunto de datos. Estos diagramas muestran la mediana, los cuartiles y los valores atípicos, lo que permite visualizar la variabilidad y la simetría de los datos. Son útiles en la comparación entre diferentes grupos y en el análisis exploratorio, facilitando la identificación de tendencias y patrones en los datos...., gráficos de barras, gráficos de líneas, gráficos de líneas, mapas de calor, etc.son posibles en R con solo una función simple, por ejemplo: el histograma se puede trazar mediante la función hist (nombre de datos) con parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... como xlab (etiqueta x), color, borde, etc.
Aprovechando esta conveniencia, pasemos a un método de aprendizaje no supervisadoEl aprendizaje no supervisado es una técnica de machine learning que permite a los modelos identificar patrones y estructuras en datos sin etiquetas predefinidas. A través de algoritmos como k-means y análisis de componentes principales, este enfoque se utiliza en diversas aplicaciones, como la segmentación de clientes, la detección de anomalías y la compresión de datos. Su capacidad para revelar información oculta lo convierte en una herramienta valiosa en la...: la agrupación en clústeres.
Aprendizaje supervisado y no supervisado
Hay dos tipos de aprendizaje en el análisis de datos: aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en... y no supervisado.
Aprendizaje supervisado – Los datos etiquetados son una entrada a la máquina que aprende. La regresión, la clasificación, los árboles de decisión, etc. son métodos de aprendizaje supervisado.
Ejemplo de aprendizaje supervisado:
La regresión lineal es donde solo hay una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... dependiente. Ecuación: y = mx + c, y depende de x.
Por ejemplo: la edad y la circunferencia de un árbol son las 2 etiquetas como conjunto de datos de entrada, la máquina necesita predecir la edad de un árbol con una circunferencia como entrada después de conocer el conjunto de datos que se alimentó. La edad depende de la circunferencia.
Por tanto, el aprendizaje se supervisa sobre la base de las etiquetas.
Aprendizaje sin supervisión – Los datos sin etiquetar se envían a la máquina para encontrar un patrón por sí mismos. La agrupación en clústeres es un método de aprendizaje no supervisado que tiene modelos: KMeans, agrupación jerárquica, DBSCAN, etc.
La representación visual de los clústeres muestra los datos en un formato fácilmente comprensible, ya que agrupa elementos de un gran conjunto de datos de acuerdo con sus similitudes. Esto facilita el análisis. Sin embargo, el aprendizaje no supervisado no siempre es preciso y es un proceso complejo para la máquina, ya que los datos no están etiquetados.
Continuemos ahora con un ejemplo de agrupamientoEl "agrupamiento" es un concepto que se refiere a la organización de elementos o individuos en grupos con características o objetivos comunes. Este proceso se utiliza en diversas disciplinas, incluyendo la psicología, la educación y la biología, para facilitar el análisis y la comprensión de comportamientos o fenómenos. En el ámbito educativo, por ejemplo, el agrupamiento puede mejorar la interacción y el aprendizaje entre los estudiantes al fomentar el trabajo... utilizando el conjunto de datos de flores de Iris.
Agrupación
Clusters son un grupo de los mismos elementos o elementos como un racimo de estrellas o un racimo de uvas o un racimo de redes y así sucesivamente …
Uso de la agrupación en clústeres en el mundo real:
Se utiliza en sitios de comercio electrónico para formar grupos de clientes en función de su perfil como edad, sexo, gasto, regularidad, etc. Es útil en marketing y ventas, ya que ayuda a agrupar la audiencia objetivo del producto. El filtrado de correo no deseado en los correos electrónicos y muchos más son aplicaciones de la agrupación en clústeres en el mundo real.
La agrupación en R se refiere a la asimilación del mismo tipo de datos en grupos o conglomerados para distinguir un grupo de los demás (recopilación del mismo tipo de datos). Esto se puede representar en formato gráfico a través de R. Usamos el modelo KMeans en este proceso.
¿Qué es el algoritmo K Means?
K Means es un algoritmo de agrupamiento que asigna repetidamente un grupo entre los k grupos presentes a un punto de datos de acuerdo con las características del punto. Es un método de agrupación basado en centroides.
Se decide el número de conglomerados, los centros de conglomerados se seleccionan al azar más alejados entre sí, la distancia entre cada punto de datos y el centro se calcula utilizando la distancia euclidiana, el punto de datos se asigna al conglomerado cuyo centro está más cercano a ese punto. Este proceso se repite hasta que el centro de los grupos no cambia y los puntos de datos permanecen en el mismo grupo.
Todo esto es teoría, pero en la práctica, R tiene un paquete de agrupamiento que calcula los pasos anteriores.
Paso 1
Trabajaré en el conjunto de datos Iris, que es un conjunto de datos incorporado en R usando el paquete Cluster. Tiene 5 columnas, a saber: longitud del sépalo, ancho del sépalo, longitud del pétalo, ancho del pétalo y especie. Iris es una flor y aquí en este conjunto de datos se mencionan 3 de sus especies Setosa, Versicolor, Verginica. Agruparemos las flores según su especie. El código para cargar el conjunto de datos:
data("iris")
head(iris) #will show top 6 rows only
Paso 2
El siguiente paso es separar las columnas 3 y 4 en un objeto x separado, ya que estamos usando el método de aprendizaje no supervisado. Estamos eliminando etiquetas para que la máquina utilice la enorme entrada de columnas de longitud y ancho de pétalo para realizar agrupaciones sin supervisión.
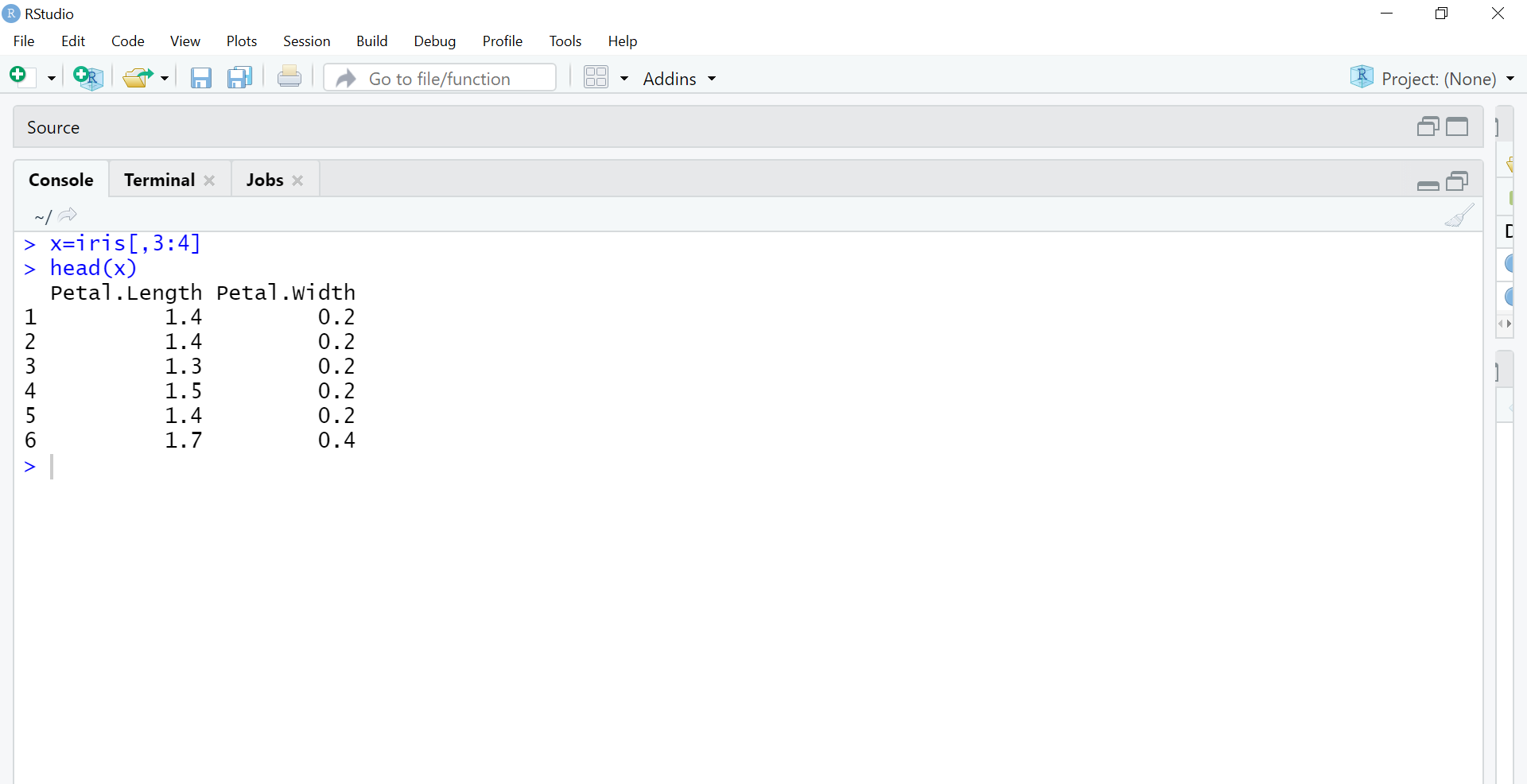
x=iris[,3:4] #using only petal length and width columns head(x)
Paso 3
El siguiente paso es utilizar el algoritmo K Means. K Means es el método que usamos que tiene parámetros (datos, no. De clusters o grupos). Aquí nuestros datos son el objeto x y tendremos k = 3 grupos, ya que hay 3 especies en el conjunto de datos.
Entonces el ‘paquete de clúster se llama. La agrupación en R se realiza utilizando este paquete incorporado que realizará todas las matemáticas. La función Clusplot crea un gráfico 2D de los clústeres.
model=kmeans(x,3) library(cluster) clusplot(x,model$cluster)
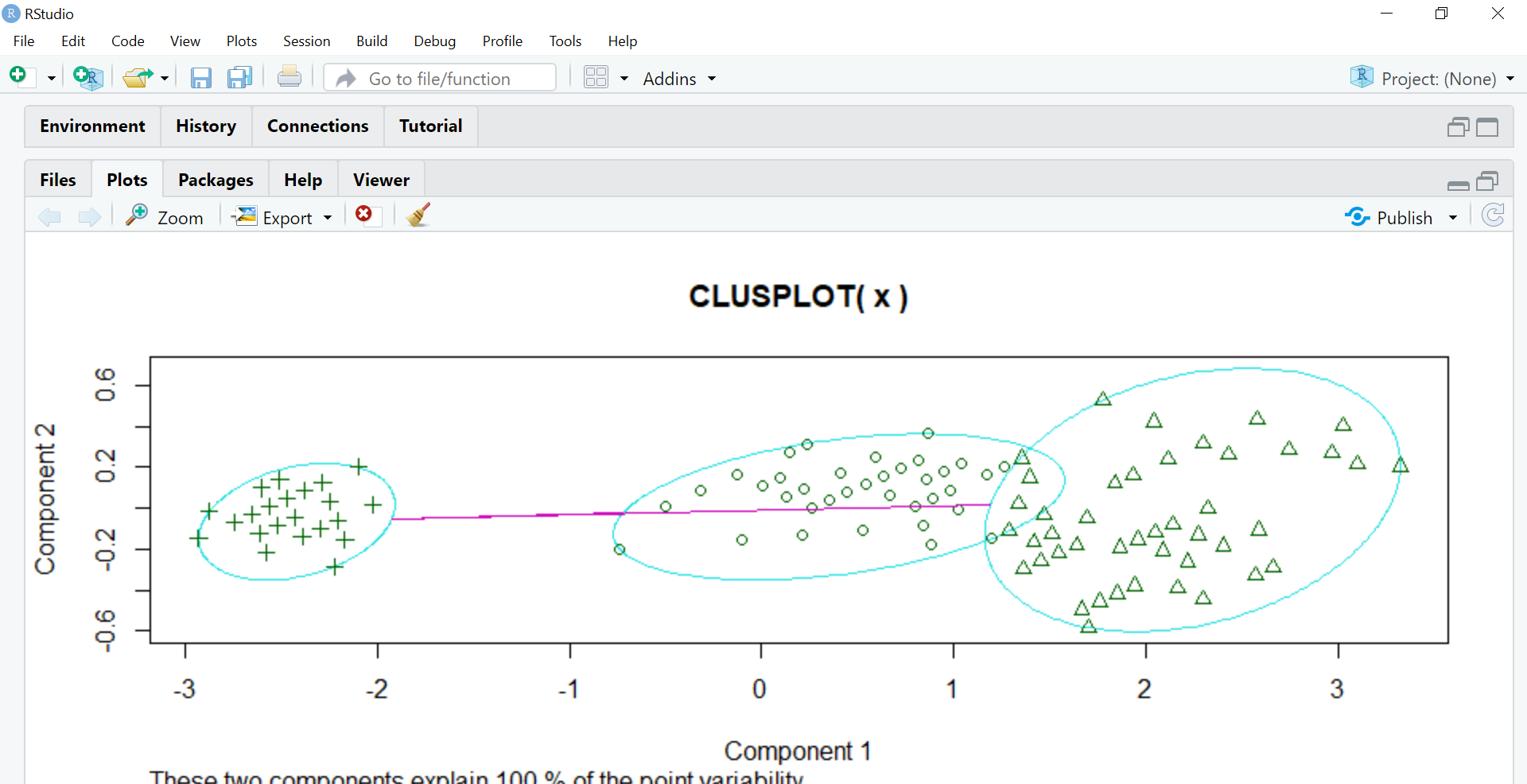
El componente 1 y el componente 2 que se ven en el gráfico son los dos componentes de PCA (análisis de componentes principales), que es básicamente un método de extracción de características que utiliza los componentes importantes y elimina el resto. Reduce la dimensionalidad de los datos para facilitar la aplicación de KMeans. Todo esto lo hace el paquete de clústerUn clúster es un conjunto de empresas y organizaciones interconectadas que operan en un mismo sector o área geográfica, y que colaboran para mejorar su competitividad. Estos agrupamientos permiten compartir recursos, conocimientos y tecnologías, fomentando la innovación y el crecimiento económico. Los clústeres pueden abarcar diversas industrias, desde tecnología hasta agricultura, y son fundamentales para el desarrollo regional y la creación de empleo.... en R.
Estos dos componentes explican la variabilidad del 100% en la salida, lo que significa que el objeto de datos x alimentado a PCA fue lo suficientemente preciso como para formar grupos claros utilizando KMeans y hay una superposición mínima (insignificante) entre ellos.
Paso 4
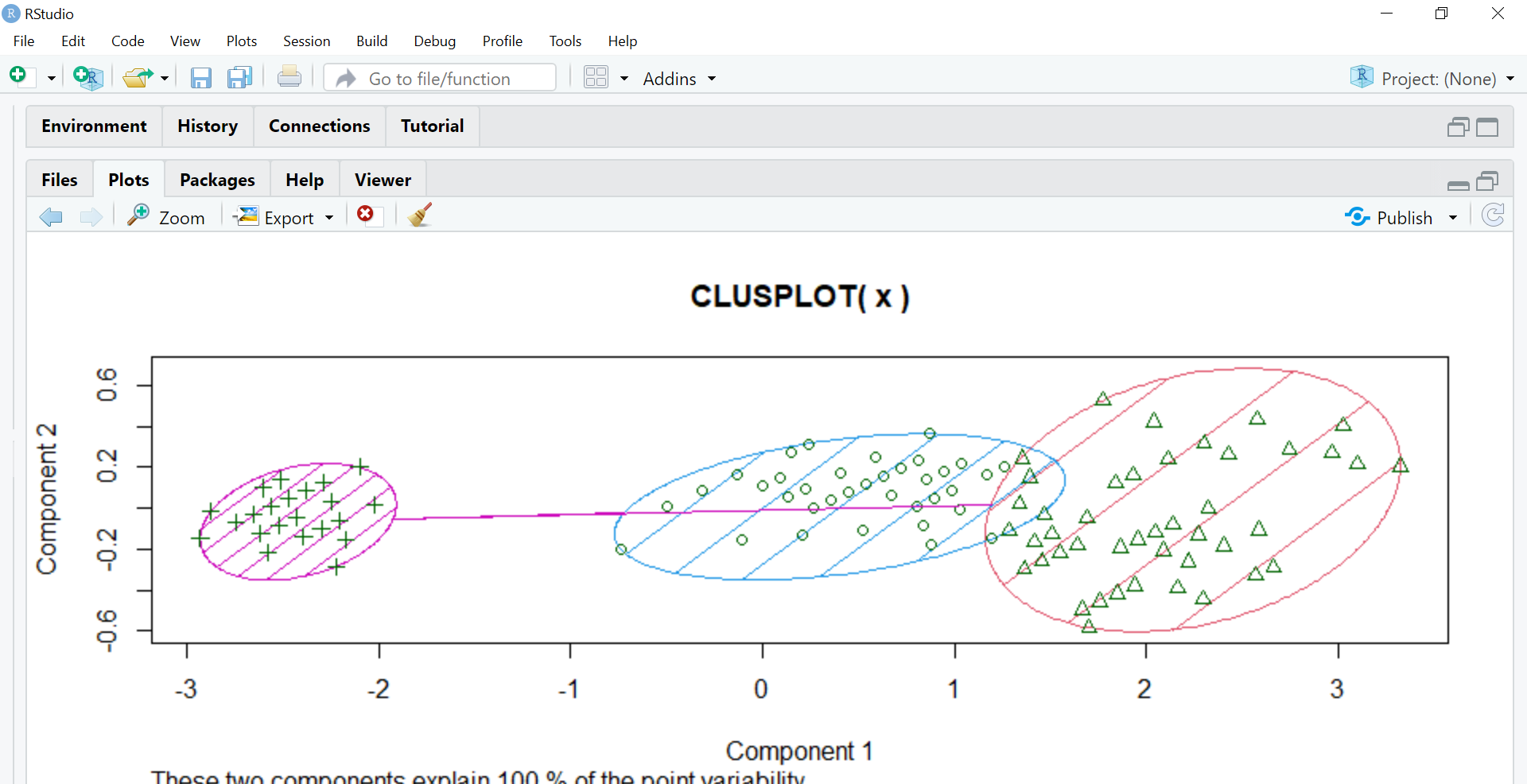
El siguiente paso es asignar diferentes colores a los grupos y sombrearlos, por lo tanto, usamos los parámetros de color y sombra configurándolos en T, lo que significa verdadero.
clusplot(x,model$cluster,color=T,shade=T)
Conclusión
Todo esto resume los conceptos básicos de la agrupación en clústeres en R. Aquí utilizo un conjunto de datos incorporado, pero los conjuntos de datos importados también se pueden utilizar para la agrupación en clústeres. Por ejemplo: agrupar a los usuarios de un sitio en función de los elementos favorecidos, etc. Es muy útil para realizar comparaciones comerciales.
Importar conjuntos de datos en R:
dataset <- read.csv("path.csv")
View(dataset)
attach(dataset)
Gracias por tomarse el tiempo y leer este artículo,Siéntase libre de comentar qué se puede mejorar, ya que el aprendizaje es un proceso diario.despuéstodos..
ConectarconmesobreLinkedIn:https://www.linkedin.com/in/akansha-bose-149b14164/
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





