En este artículo, aprenderemos cómo podemos manejar variables de categorías múltiples utilizando la técnica de ingeniería de funciones One Hot Encoding.
Pero antes de continuar, tengamos una breve discusión sobre la ingeniería de funciones y One Hot Encoding.
Ingeniería de funciones
Entonces, la ingeniería de características es el proceso de extraer características de datos sin procesar utilizando el conocimiento de dominio del problema. Estas funciones se pueden utilizar para mejorar el rendimiento de los algoritmos de aprendizaje automático y, si el rendimiento aumenta, proporcionará la mejor precisión. También podemos decir que la ingeniería de funciones es lo mismo que el aprendizaje automático aplicado. La ingeniería de características es el arte más importante en el aprendizaje automático que crea una gran diferencia entre un buen modelo y un mal modelo. Este es el tercer paso en el ciclo de vida de cualquier proyecto de ciencia de datos.
El concepto de transparencia para los modelos de aprendizaje automático es algo complicado, ya que los diferentes modelos a menudo requieren diferentes enfoques para los diferentes tipos de datos. Tal como:-
- Datos continuos
- Características categóricas
- Valores faltantes
- NormalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos....
- Fechas y hora
Pero aquí solo discutiremos las características categóricas, las características categóricas son aquellas características en las que el tipo de datos es un tipo de objeto. El valor del punto de datos en cualquier característica categórica no está en forma numérica, sino en forma de objeto.
Existen muchas técnicas para manejar las variables categóricas, algunas son:
- Codificación de etiquetas o codificación ordinal
- Una codificación en caliente
- Codificación ficticia
- Codificación de efectos
- Codificación binaria
- Codificación de Basilea
- Codificación hash
- Codificación de destino
Entonces, aquí manejamos características categóricas por One Hot Encoding, por lo tanto, en primer lugar, discutiremos One Hot Encoding.
Una codificación en caliente
Sabemos que las variables categóricas contienen los valores de la etiqueta en lugar de valores numéricos. El número de valores posibles se limita a menudo a un conjunto fijo. Las variables categóricas a menudo se denominan nominales. Muchos algoritmos de aprendizaje automático no pueden operar directamente en datos de etiquetas. Requieren que todas las variables de entrada y de salida sean numéricas.
Esto significa que los datos categóricos deben convertirse a una forma numérica. Si la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... categórica es una variable de salida, es posible que también desee volver a convertir las predicciones del modelo en una forma categórica para presentarlas o utilizarlas en alguna aplicación.
por ejemplo los datos sobre género están en forma de ‘masculino’ y ‘mujer’.
Pero si usamos codificación one-hot, codificar y permitir que el modelo asuma un orden natural entre categorías puede resultar en un rendimiento deficiente o resultados inesperados.
La codificación one-hot se puede aplicar a la representación de números enteros. Aquí es donde se elimina la variable codificada como entero y se agrega una nueva variable binaria para cada valor entero único.
Por ejemplo, codificamos la variable de colores,
| Color rojo | Color azul |
| 0 | 1 |
| 1 | 0 |
| 0 | 1 |
Ahora comenzaremos nuestro viaje. En el primer paso, tomamos un conjunto de datos de predicción del precio de la vivienda.
Conjunto de datos
Aquí usaremos el conjunto de datos de house_price que se usa para predecir el precio de la vivienda de acuerdo con el tamaño del área.
Si desea descargar el conjunto de datos de predicción del precio de la vivienda, haga clic en aquí.
Importación de módulos
Ahora, tenemos que importar módulos importantes de Python que se utilizarán para la codificación one-hot
# importing pandas import pandas as pd # importing numpy import numpy as np # importing OneHotEncoder from sklearn.preprocessing import OneHotEncoder()
Aquí, utilizamos pandas que se utilizan para el análisis de datos, NumPyused para matrices de n dimensiones, y de sklearn, utilizaremos un codificador en caliente de clase One importante para la codificación categórica.
Ahora tenemos que leer estos datos usando Python.
Leer conjunto de datos
Generalmente, el conjunto de datos está en forma de CSV, y el conjunto de datos que usamos también está en forma de CSV. Para leer el archivo CSV usaremos la función pandas read_csv (). vea abajo:
# reading dataset
df = pd.read_csv('house_price.csv')
df.head()
producción:-

Pero solo tenemos que usar variables categóricas para un codificador activo y solo intentaremos explicar con variables categóricas para una fácil comprensión.
para particionar variables categóricas a partir de datos, tenemos que verificar cuántas características tienen valores categóricos.
Comprobación de valores categóricos
Para verificar los valores usamos la función pandas select_dtypes que se usa para seleccionar los tipos de datos de la variable.
# checking features cat = df.select_dtypes(include="O").keys() # display variabels cat
producción:-

Ahora tenemos que eliminar esas columnas numéricas del conjunto de datos y usaremos esta variable categórica para nuestro uso. Solo usamos 3-4 columnas categóricas del conjunto de datos para aplicar la codificación one-hot.
Creación de un nuevo marco de datos
Ahora, para usar variables categóricas, crearemos un nuevo marco de datos de columnas categóricas seleccionadas.
# creating new df
# setting columns we use
new_df = pd.read_csv('house_price.csv',usecols=['Neighborhood','Exterior1st','Exterior2nd'])
new_df.head()
producción:-
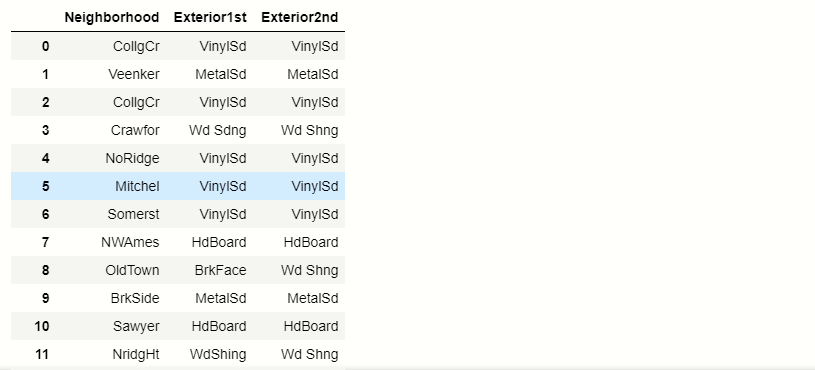
Ahora tenemos que averiguar cuántas categorías únicas están presentes en cada columna categórica.
Encontrar valores únicos
Para encontrar valores únicos usaremos la función pandas unique ().
# unique values in each columns
for x in new_df.columns:
#prinfting unique values
print(x ,':', len(new_df[x].unique()))
producción:-
| Barrio: 25 |
| Exterior 1er: 15 |
| Exterior 2do: 16 |
Ahora, usaremos nuestra técnica para aplicar la codificación one-hot en variables de múltiples categorías.
Técnica para variables multicategóricas
La técnica consiste en limitar la codificación one-hot a las 10 etiquetas más frecuentes de la variable. Esto significa que haríamos una variable binaria solo para cada una de las 10 etiquetas más frecuentes, esto equivale a agrupar todas las demás etiquetas en una nueva categoría, que en este caso se eliminará. Así, las 10 nuevas variables ficticias indican si una de las 10 etiquetas más frecuentes está presente es 1 o no entonces 0 para una observación particular.
Variables más frecuentes
Aquí seleccionaremos las 20 variables más frecuentes.
Supongamos que tomamos una variable categórica Vecindario.
# finding the top 20 categories new_df.Neighborhood.value_counts().sort_values(ascending=False).head(20)
producción:

Cuando vea en esta imagen de salida, notará que el Nombres La etiqueta se repite 225 veces en las columnas de Barrio y bajamos este número es decreciente.
Así que tomamos los 10 resultados principales de la parte superior y convertimos este resultado superior 10 en codificación one-hot y las etiquetas de la izquierda se convierten en cero.
producción:-
Lista de variables categóricas más frecuentes
# make list with top 10 variables top_10 = [x for x in new_df.Neighborhood.value_counts().sort_values(ascending=False).head(10).index] top_10
producción:-
[‘NAmes’,
‘CollgCr’,
‘OldTown’,
‘Edwards’,
‘Somerst’,
‘Gilbert’,
‘NridgHt’,
‘Sawyer’,
‘NWAmes’,
‘SawyerW’]
Hay las 10 etiquetas categóricas principales en la columna Vecindad.
Hacer binario
Ahora, tenemos que hacer las 10 variables binarias de las etiquetas top_10:
# hacer binario de etiquetas
para etiqueta en top_10:
new_df[label] = np.where (new_df[‘Neighborhood’]== etiqueta, 1,0)
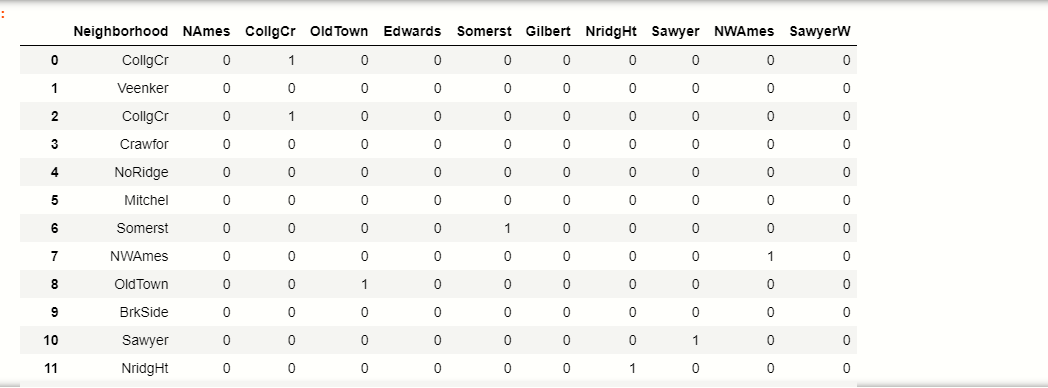
new_df[[‘Neighborhood’]+ top_10]
producción:-
| Nombres | CollgCr | Pueblo Viejo | Edwards | Somerst | Gilbert | NridgHt | Aserrador | NWAmes | SawyerW | ||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | CollgCr | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | Veenker | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | CollgCr | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | Crawfor | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | NoRidge | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 5 | Mitchel | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 6 | Somerst | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 7 | NWAmes | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 8 | Pueblo Viejo | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 9 | BrkSide | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | Aserrador | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| 11 | NridgHt | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
Puede ver cómo las etiquetas top_10 ahora se convierten a formato binario.
Tomemos un ejemplo, vea en la tabla donde 1 índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... Veenker que no pertenecía a nuestra etiqueta top_10 categorías, por lo que resultará en 0 todas las columnas.
Ahora lo haremos para todas las variables categóricas que hemos seleccionado anteriormente.
Todas las variables seleccionadas en OneHotEncoding
# for all categorical variables we selected
def top_x(df2,variable,top_x_labels):
for label in top_x_labels:
df2[variable+'_'+label] = np.where(data[variable]==label,1,0)
# read the data again
data = pd.read_csv('D://xdatasets/train.csv',usecols = ['Neighborhood','Exterior1st','Exterior2nd'])
#encode Nighborhood into the 10 most frequent categories
top_x(data,'Neighborhood',top_10)
# display data
data.head()
Producción:-

Ahora, aquí aplicamos la codificación one-hot en todas las variables de categorías múltiples.
Ahora veremos las ventajas y desventajas de One Hot Encoding para múltiples variables.
Ventajas
- Fácil de implementar
- No requiere mucho tiempo para la exploración de variables.
- No expande masivamente el espacio de características.
Desventajas
- No agrega ninguna información que pueda hacer que la variable sea más predictiva
- No guarde la información de las variables ignoradas.
Notas finales
Entonces, el resumen de esto es que aprendemos cómo manejar variables de múltiples categorías. Si se encuentra con este problema, entonces esta es una tarea muy difícil. Así que gracias por leer este artículo.
Conéctate conmigo en Linkedin: Perfil
Lea mis otros artículos: https://www.analyticsvidhya.com/blog/author/mayurbadole2407/
Gracias😎
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





