Antes de continuar, analicemos brevemente Raspado y luego AutoScraper:
¿Qué es el raspado?
El web scraping es una técnica fundamental que se utiliza para extraer información útil como contactos, correos electrónicos, imágenes, URL, etc… de los sitios web. La otra forma de raspado web es el rastreo. Se utiliza cuando necesitamos una gran cantidad de datos estructurados y etiquetados para los fundamentos industriales. El software de raspado web puede acceder directamente a la red mundial mediante protocolos HTML.
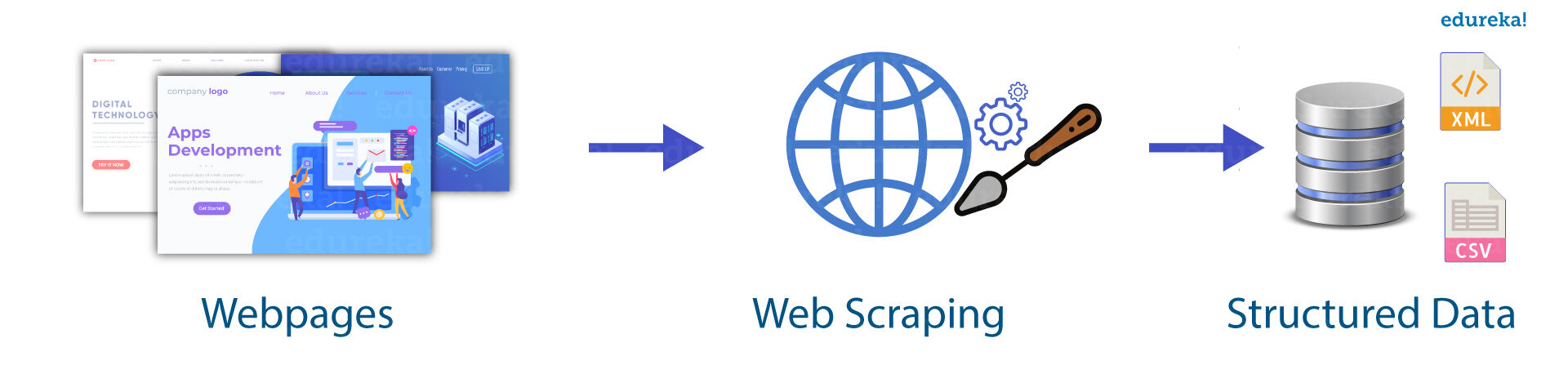
Usted sabe que las nuevas formas de raspado web implican la observación de la alimentación de datos en los servidores web, por ejemplo, un archivo JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software... que se utiliza como transportador entre el cliente y el servidor web.
Hay muchos sitios web grandes que Google, Facebook, Amazon, etc. proporcionan API que le permite acceder a sus datos en un formato estructurado o etiquetado.
Ahora, analizamos brevemente la biblioteca AutoScraper:
¿Qué es AutoScraper?
Cuando hablamos de scraping, hay muchas cosas en el sitio web que queremos eliminar, pero los scripts que se pueden escribir toman mucho tiempo para eliminar datos y es un proceso muy largo, para superar este problema, un grupo de desarrolladores de Python desarrolla una biblioteca. que extraerá todos los datos de un sitio web de una manera fácil. Entonces AutoScraper es la biblioteca de python de raspado web que se utiliza para raspar datos de un sitio web de una manera simple, fácil y rápida. Tiene un entorno fácil de usar por este raspador puede interactuar fácilmente con esta biblioteca.

Utiliza las URL y el contenido HTML del sitio web para extraer información y datos confiables.
Punto a tener en cuenta: aprende las reglas de raspado y devuelve elementos similares en un buen formato.
Es fácil eliminar el contenido del sitio web que fue fácil de revisar como título, precio, nombre, calificaciones, etc. ¡Espere un minuto! ¿Qué haremos con las imágenes? es una gran duda que nos surge podemos dar la imagen durante la ejecución del programa😅. Estoy encontrando una manera de eliminar las imágenes de los sitios web. Analicemos a continuación:

Primero, vamos por la instalación de esta biblioteca:
Instalación de AutoScraper
Hay dos formas de instalar AutoScraper:
Usando pip: –
Escriba el siguiente código en el símbolo del sistema,
pip instalar autoscraper
o con el repositorio de git,
clon de git https://github.com/brandonrobertz/autoscrape-py
cd autoscrape-py /
pip install.[all]
Ahora importamos módulos importantes:
Importación de módulos
# Importing AutoScraper from autoscraper import AutoScraper
Aquí importamos la clase AutoScraper de la biblioteca.
Ahora alimentamos la URL a la función AutoScraper para seguir raspando:
URL: – https://www.bookswagon.com/
Aquí alimentamos la URL del sitio web de comercio electrónico a la clase AutoScraper para extraer o raspar las imágenes de libros.
Ahora, antes de seguir adelante, primero vemos la demostración raspando títulos y precios de libros para tener una comprensión básica y mejor del código de raspado:
Demo raspado
Ahora, alimentaremos la lista de elementos para raspar, así que primero tenemos que inicializar la clase AutoScraper con su objeto:
Lista de buscados:
crear una lista de elementos
# create a list of elements items = ['Rs.349' , 'The Secret of the Nagas']

Creación de objetos:
# create object scrape = AutoScraper() # feeding for scraping final_result = scrape.build(URL,items) # display result print(final_result)

Hora de eliminar la imagen
Ahora, tiene una idea sobre el código de raspado web que discutimos anteriormente, por lo que usamos este mismo método para raspar las imágenes del sitio web con algunos cambios. Por lo tanto, discutiremos el método o la técnica para extraer las imágenes de los datos. veamos a continuación:
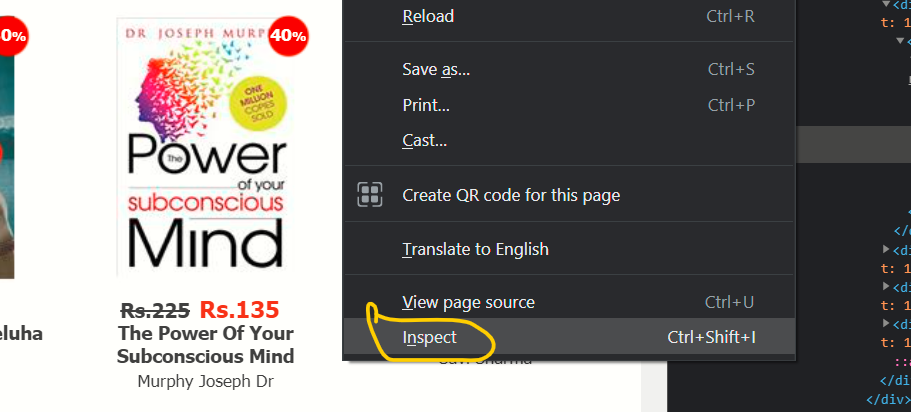
Paso 1:
En el primer paso, tenemos que hacer clic derecho en el mouse y luego seleccionar la opción inspeccionar de la lista del menú:
Paso 2:
Después de seleccionar la opción inspeccionar, se abre una página de contenido HTML al lado de la pantalla, luego se desplazará sobre la imagen del libro; en ese momento, observe en la página de contenido HTML que encontrará el URL de la imagen.
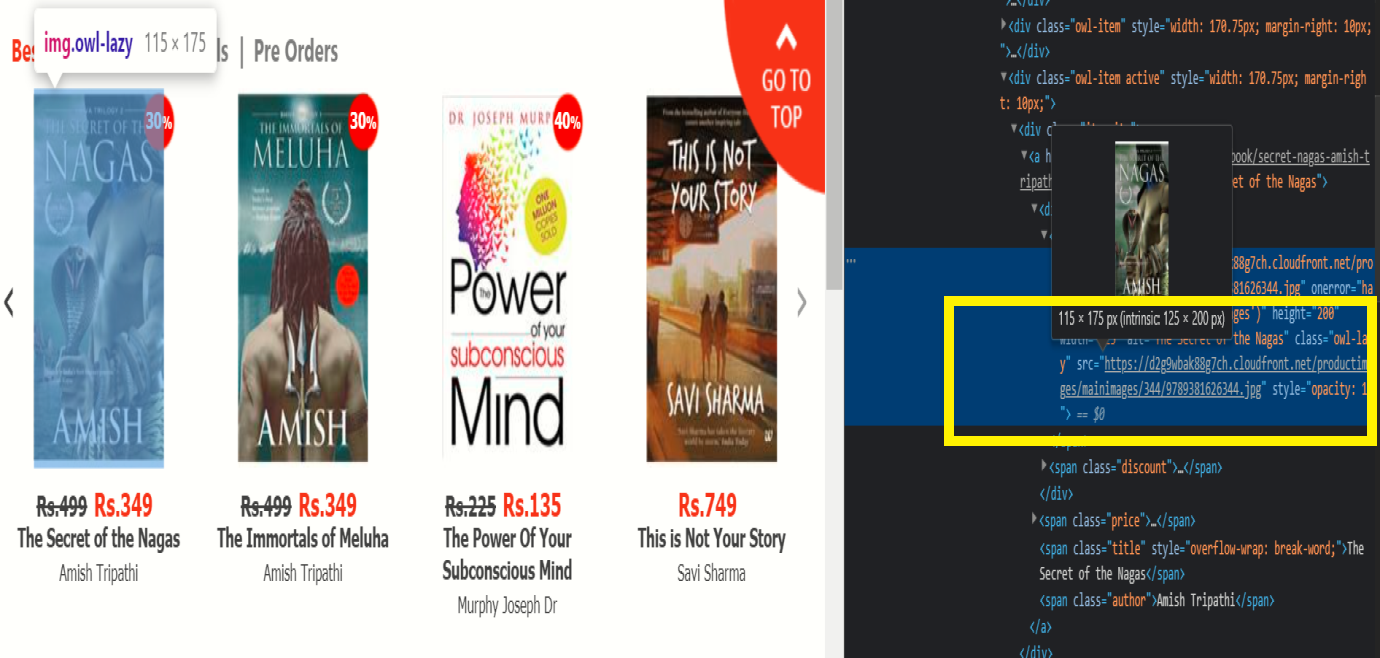
Cuando encuentre la URL de la imagen en particular, cópiela y la usaremos en la lista de elementos deseados. Este es solo el cambio que se requiere para raspar las imágenes del sitio web.
Paso 3:
Ahora, configuraremos esa URL de imagen junto con los libros que entraron en nuestra lista de buscados,
item = ['https://d2g9wbak88g7ch.cloudfront.net/productimages/mainimages/344/9789381626344.jpg','This is Not Your Story']
Después de crear una lista, hacemos el mismo proceso que hicimos arriba:
# creating object scrape = AutoScraper() # building result final_result = scrap.build( URL, item ) # display result print(final_result)
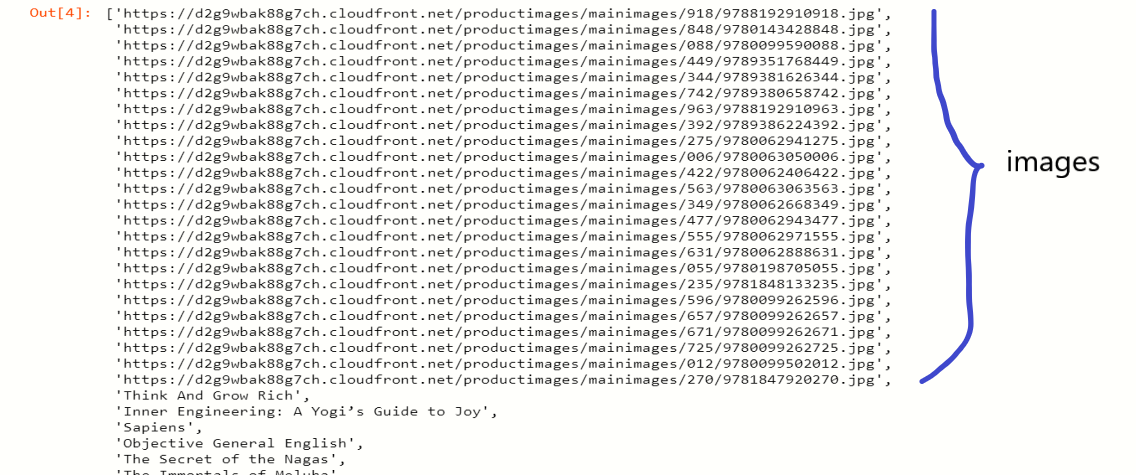
Nota: use la URL de las imágenes para extraer las imágenes del sitio web
Entonces, este es el proceso para raspar las imágenes de cualquier sitio web.
Nota final
Entonces, aquí discutiremos el raspado de imágenes del sitio web, si desea eliminar imágenes del sitio web, utilice esta técnica. Estoy muy sorprendido al usar esta biblioteca de AutoViz. Espero que hayas disfrutado de este artículo y gracias por leer este artículo.
Puedes conectarte conmigo en Linkedin: URL del perfil
Lea también mis otros artículos: https://www.analyticsvidhya.com/blog/author/mayurbadole2407/
Gracias😎.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





