Visión general
- Qlik está ampliamente asociado con potentes paneles de control e informes de inteligencia empresarial.
- ¿Sabía que puede utilizar el poder de Qlik para realizar modelado predictivo y construir modelos?
- Aprenda a hacer precisamente eso con esta guía realmente genial sobre cómo construir un modelo de regresión lineal usando Qlik Sense
Introducción
«¿Puedo utilizar Qlik Sense para crear un análisis Y SI SI construye un modelo de regresión lineal simple para que los usuarios de mi negocio puedan pronosticar las ganancias futuras en función de las ventas objetivo?»
¡Una pregunta intrigante! Qlik está ampliamente asociado con la creación de paneles de control e informes de inteligencia empresarial, no con el modelado predictivo. Si tuvieras el mismo pensamiento, ¡no estás solo!
Qlik es como un viento en la espalda para cualquier líder empresarial. Hace que analizar y presentar datos a los usuarios finales sea extremadamente fácil y rápido. No es de extrañar que Qlik sea nombrado regularmente líder en el Cuadrante Mágico de Gartner para plataformas de análisis e inteligencia empresarial.

Lo que realmente me gusta de Qlik es que su modelo asociativo ofrece descubrimiento de datos de forma libre. Esto ayuda a nuestro usuario final a encontrar rápidamente tendencias y valores atípicos para obtener información valiosa. Qlik es bien conocido por su modelo asociativo y por la increíble velocidad con la que revela asociaciones entre campos dentro de un modelo de datos.
Con su cambio de paradigma de mostrar todos los datos, incluidos los valores atípicos, nuestros clientes y partes interesadas pueden encontrar rápidamente información para tomar decisiones comerciales críticas. Las aplicaciones de Qlik abarcan múltiples industrias como:
- En el cuidado de la salud, una compañía de seguros puede querer predecir el costo futuro de la atención al paciente utilizando costos, datos demográficos y diagnósticos anteriores.
- Los defectos del producto se pueden predecir utilizando la eficiencia del proceso en función de los defectos anteriores y la precisión del equipo en el sector de fabricación.
- En recursos humanos, podemos predecir el costo futuro de la nómina de un empleado en función de su edad y experiencia.
Piense en las posibilidades, ¡son infinitas!
Después de leer este artículo, podrá ponerse el sombrero de un científico de datos, ya que tanto QlikView como Qlik Sense ofrecen una gran cantidad de funciones estadísticas que puede aprovechar para construir su primer modelo predictivo usando regresión lineal. ¡Vamos a empezar!
Tabla de contenido
- Introducción a la regresión lineal simple
- Implementación de regresión lineal en Qlik
- Comparación de nuestros resultados con un modelo creado con Python
Introducción a la regresión lineal simple

Fuente: xkcd.com
Comencemos con el concepto de análisis de regresión. Es una forma de modelado predictivo que revela la relación entre una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... independiente y una dependiente. Esta es quizás la técnica más común que los aspirantes a profesionales de la ciencia de datos aprenden primero.
La regresión se utiliza para evaluar la contribución de una o más variables «causantes» (variables independientes) a una variable «causada» (dependiente). También podemos usarlo para predecir el valor de la variable dependiente a partir de los valores de las variables independientes. Algunos ejemplos populares incluyen predecir el precio de una casa, el salario de un empleado, etc. (¡estoy seguro de que su mente debe estar llena de ideas!).
Cuando solo hay una variable independiente y cuando la relación se puede expresar como una línea recta, el procedimiento se denomina regresión lineal simple.
Una línea recta se puede definir mediante la ecuación matemática y = mx + b:
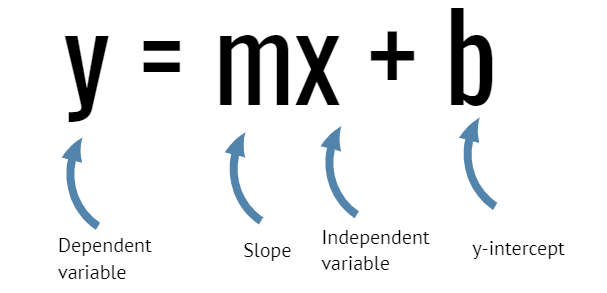
- y es una variable dependiente y se representa en el eje vertical
- x es una variable independiente y está representada en el eje horizontal
- m es la pendiente (cantidad de cambio en y correspondiente al aumento de una unidad en x)
- b es la intersección
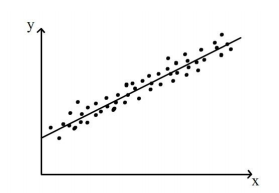 Fuente: http://www.statstutor.ac.uk
Fuente: http://www.statstutor.ac.uk
El procedimiento de regresión ajusta la mejor línea recta posible a una matriz de puntos de datos. Si no se puede trazar una sola línea de modo que todos los puntos caigan sobre ella, ¿cuál es la «mejor» línea? Piense en ello antes de leer la respuesta.
La mejor línea es la que minimiza la distancia de todos los puntos de datos a la línea.
El coeficiente de correlación indica la fuerza de la relación entre la variable independiente y la dependiente, mientras que el coeficiente de determinación (r cuadrado) explica hasta qué punto la varianza de la variable independiente explica la varianza de la variable dependiente.
Un coeficiente de correlación cercano a 1 indica una relación positiva entre la variable independiente y dependiente y un coeficiente de determinación más cercano a 1 indica un buen ajuste de los datos al modelo predictivo.
Armados con este conocimiento, podemos crear nuestro primer modelo de regresión lineal simple en Qlik Sense o QlikView.
Implementación de regresión lineal en Qlik
Recientemente, me topé con este artículo muy interesante que muestra el nexo entre el embarazo adolescente y la tasa de pobreza en Estados Unidos. Vale la pena reflexionar sobre estos hechos sobre las razones por las que el embarazo en la adolescencia conduce a una mayor tasa de pobreza:
- Solo el 38 por ciento de las niñas que tienen un hijo antes de los 18 años obtienen su diploma de escuela secundaria a los 22
- Dos tercios de las madres adolescentes que se mudan de su hogar familiar viven en la pobreza y una proporción similar recibe beneficios públicos en el primer año de vida de su hijo.
- El setenta y ocho por ciento de los niños nacidos de madres adolescentes que nunca se casaron y que no se graduaron de la escuela secundaria viven por debajo del nivel federal de pobreza.
Es un problema del que todos deberíamos estar conscientes y si podemos ayudar de alguna manera, al menos deberíamos intentarlo. Tuve la suerte de encontrar un conjunto de datos sobre esto en Sitio web de estadísticas de la Universidad Estatal de Pensilvania, STAT462.
Entonces, usaremos este conjunto de datos para crear un modelo de regresión lineal simple en Qlik Sense. Continúe y guárdelo en su máquina. Aquí hay una instantánea del conjunto de datos:
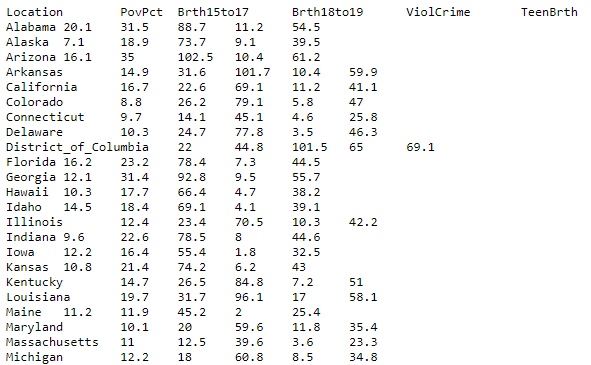
Este conjunto de datos de tamaño n = 51 es para los 50 estados y el Distrito de Columbia en los Estados Unidos.
Entonces, echemos un vistazo a los pasos y quiero que los siga en Qlik Sense a medida que los recorremos.
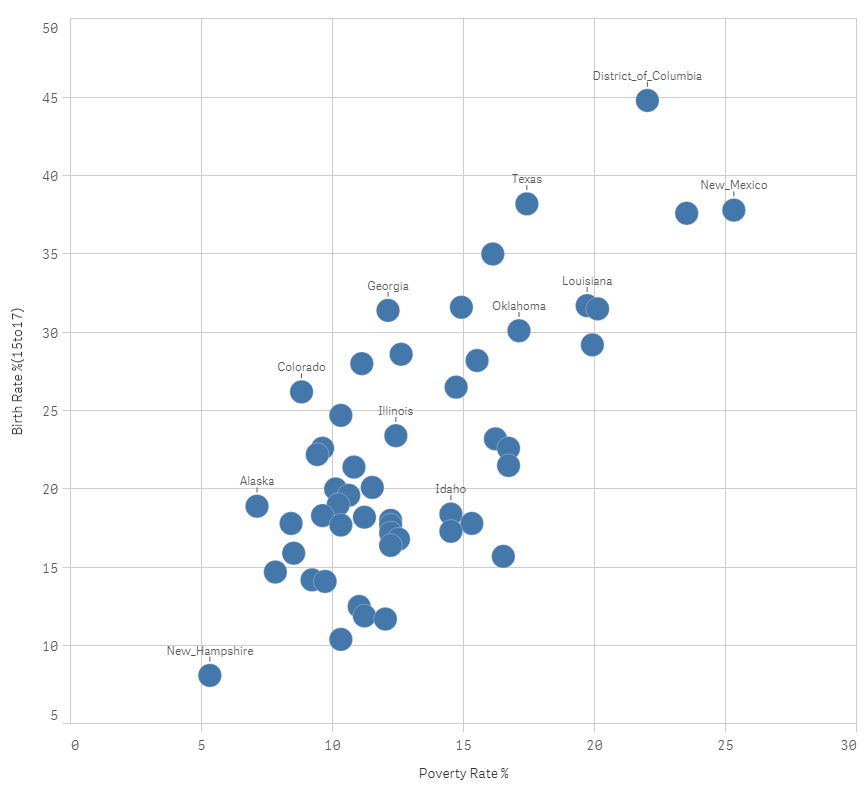
Paso 1: crear un diagrama de dispersión
Paso 2: Calcule el coeficiente de correlación
Cree un gráfico de texto e imágenes con la siguiente expresión:
![]()
Paso 3: Calcule el coeficiente de determinación.
Cree un gráfico de texto e imágenes con esta expresión:
![]()
Paso 4: calcula la pendiente
![]()
Paso 5: Calcula la intersección con el eje y
![]()
Paso 6: crea una variable x con valor inicial = 0
Esta variable nos permitirá cambiar el valor de la variable independiente, tasa de natalidad (15 a 17), para predecir la tasa de pobreza. Haga clic en la opción de variable de la esquina inferior izquierda del editor de hojas:
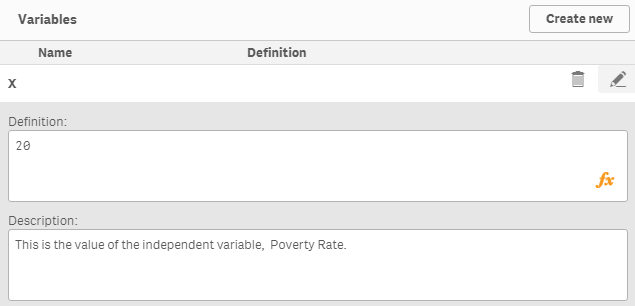
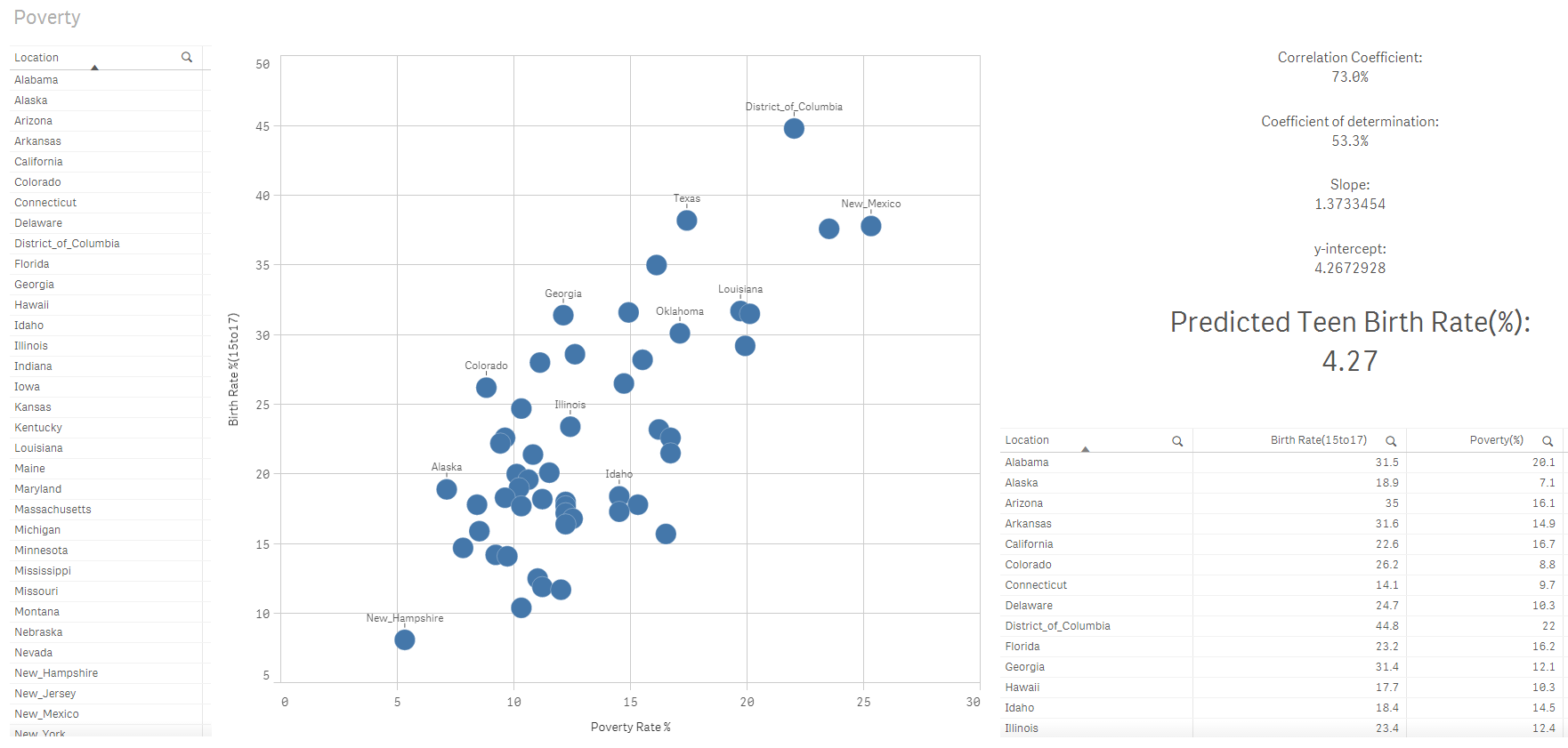
Paso 7: Calcule la tasa de natalidad prevista para el grupo de adolescentes (15 a 17)

Como se indica aquí, nuestro modelo de regresión lineal de Qlik Sense coincide con la ecuación de línea ajustada:
Y = 1,373X + 4,267
Con una tasa de pobreza del 0%, la tasa de natalidad de adolescentes sería del 4,27%. Un cambio de una unidad en el valor de la variable independiente equivale a un cambio de 1,373 en el valor de la variable dependiente.
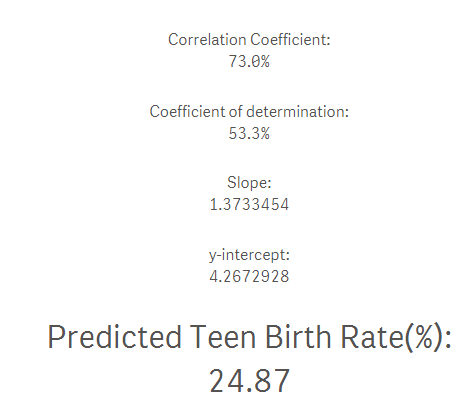
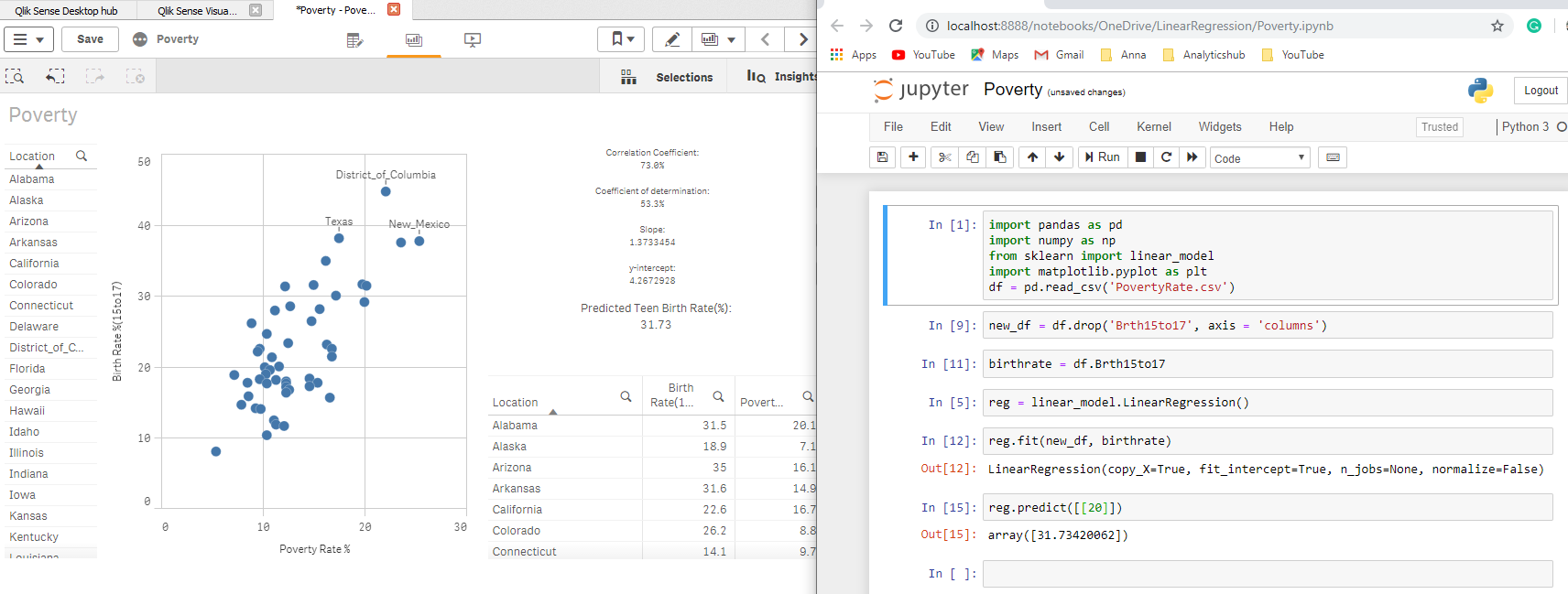
¿Cuál sería la tasa de natalidad de adolescentes si la tasa de pobreza fuera del 15%? Esta es la respuesta:
Ahora puedo combinar el poder del motor asociativo para reducir la lista de estados y predecir la tasa de natalidad para un grupo de edad de mujeres de 15 a 17 años en función de mis selecciones utilizando la tasa de pobreza del 15%:
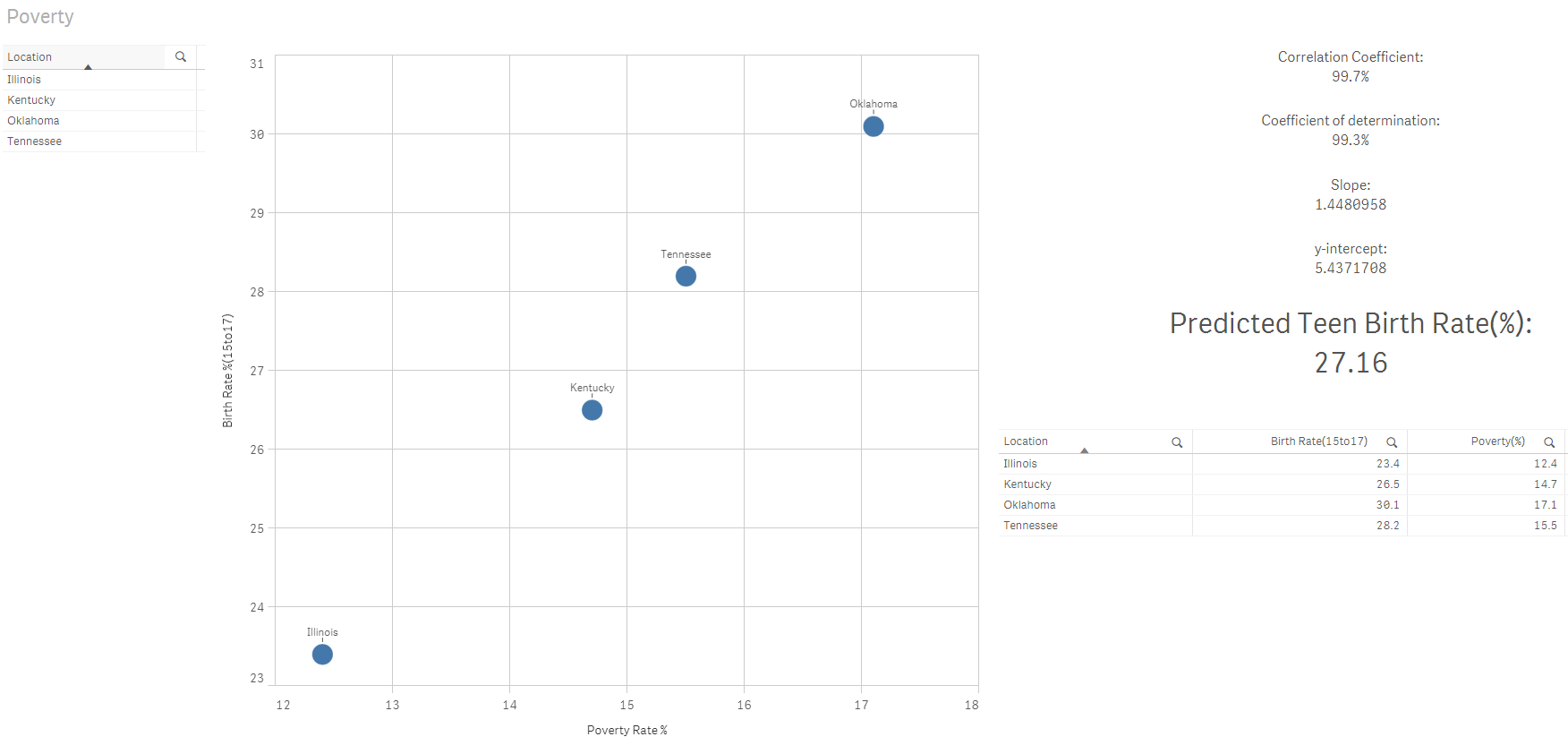
¡Fabuloso! ¿No te encanta el poder de Qlik?
Comparación de nuestros resultados con un modelo creado con Python
A continuación, crearemos un modelo de regresión simple similar en Python utilizando las bibliotecas Pandas y scikit-learn. Quiero comparar la precisión del modelo predictivo que creamos en Qlik Sense con uno que crearemos en Python.
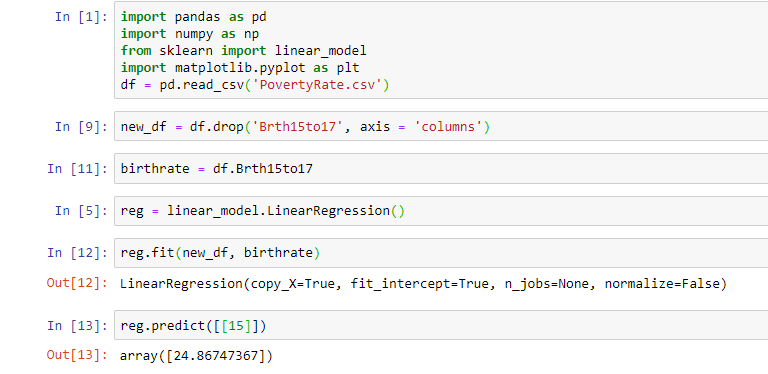
El resultado de nuestro modelo de regresión simple de Python coincide con el de Qlik Sense. Comparemos el valor predictor de nuestro modelo de regresión lineal Qlik Sense con el que creamos en Python:
Notas finales
Podemos crear un modelo de regresión simple para mostrar el escenario «Qué pasa si» en Qlik Sense siempre que primero validemos que la relación entre la variable independiente y la dependiente sea positiva o negativa usando una función de correlación incorporada para ver la relación .
Además, asegúrese de que los datos sean aptos para el modelado utilizando el coeficiente de determinación (R-cuadrado). Si un valor está más cerca de 1, entonces nuestros datos son adecuados para el modelado de regresión simple en Qlik Sense.
Déjeme saber sus sugerencias y comentarios para este artículo en la sección de comentarios a continuación.
Sobre el Autor
Shilpan Patel – Co-fundador, Analyticshub.io Y Qlik Luminary 2018, 2019

Shilpan es un Qlik Luminary y le apasiona permitir que los estudiantes desarrollen todo su potencial a través del aprendizaje y la tutoría a lo largo de toda la vida. Él cree que la mejor manera de aprender y dominar una habilidad es haciendo. Tiene más de 15 años de experiencia en datos y análisis, y ha enseñado y asesorado a miles de estudiantes.





