Visión general
- Obtenga más información sobre el etiquetado de parte de la voz (POS),
- Comprender el análisis de dependencias y el análisis de distritos
Introducción
El conocimiento de idiomas es la puerta a la sabiduría.
– Roger Bacon
Me asombró que Roger Bacon dio la cita anterior en el siglo XIII, y todavía se mantiene, ¿no es así? Estoy seguro de que todos estarán de acuerdo conmigo.
Hoy en día, la forma de entender los idiomas ha cambiado mucho desde el siglo XIII. Ahora nos referimos a él como lingüística y procesamiento del lenguaje natural. Pero su importancia no ha disminuido; en cambio, ha aumentado enormemente. ¿Sabes por qué? Porque es aplicaciones se han disparado y una de ellas es la razón por la que aterrizó en este artículo.

Cada una de estas aplicaciones implica técnicas complejas de PNL y, para comprenderlas, es necesario tener un buen conocimiento de los conceptos básicos de PNL. Por lo tanto, antes de pasar a temas complejos, es importante mantener los fundamentos correctos.
Es por eso que he creado este artículo en el que cubriré algunos conceptos básicos de PNL: etiquetado de parte del habla (POS), análisis de dependencias y análisis de distritos en el procesamiento del lenguaje natural. Entenderemos estos conceptos y también los implementaremos en Python. ¡Vamos a empezar!
Tabla de contenido
- Etiquetado de parte del discurso (POS)
- Análisis de dependencia
- Análisis de circunscripciones
Etiquetado de parte del discurso (POS)
En nuestros días escolares, todos hemos estudiado las partes del discurso, que incluye sustantivos, pronombres, adjetivos, verbos, etc. Las palabras que pertenecen a varias partes del discurso forman una oración. Conocer la parte del habla de las palabras en una oración es importante para comprenderla.
Esa es la razón de la creación del concepto de etiquetado POS. Estoy seguro de que a estas alturas ya habrá adivinado qué es el etiquetado POS. Aún así, permíteme explicártelo.
El etiquetado de parte del discurso (POS) es el proceso de asignar diferentes etiquetas conocidas como etiquetas POS a las palabras en una oración que nos informa sobre la parte del discurso de la palabra.
En términos generales, existen dos tipos de etiquetas POS:
1. Etiquetas POS universales: Estas etiquetas se utilizan en las dependencias universales (UD) (última versión 2), un proyecto que está desarrollando anotaciones de bancos de árboles coherentes entre lenguas para muchos idiomas. Estas etiquetas se basan en el tipo de palabras. Por ejemplo, NOUN (sustantivo común), ADJ (adjetivo), ADV (adverbio).
Lista de etiquetas POS universales
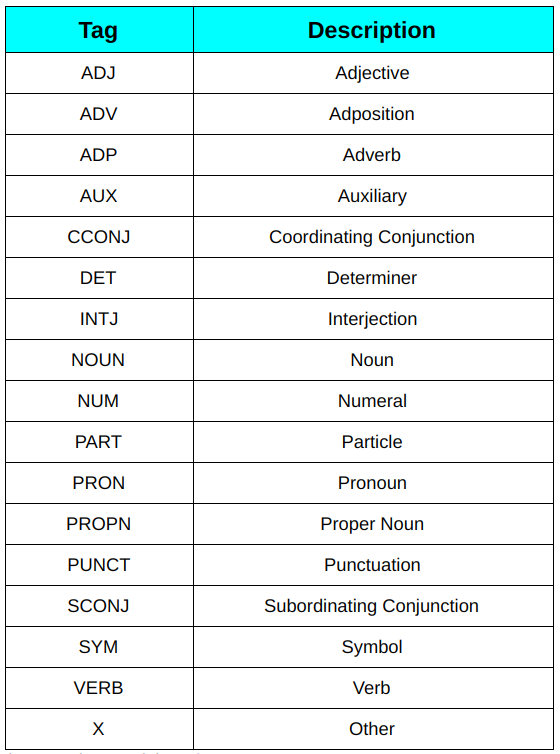
Puedes leer más sobre cada uno de ellos aquí.
2. Etiquetas de punto de venta detalladas: Estas etiquetas son el resultado de la división de etiquetas POS universales en varias etiquetas, como NNS para sustantivos comunes en plural y NN para el sustantivo común singular en comparación con NOUN para sustantivos comunes en inglés. Estas etiquetas son específicas del idioma. Puedes echar un vistazo a la lista completa aquí.
Ahora ya sabe qué son las etiquetas de punto de venta y qué es el etiquetado de punto de venta. Entonces, escribamos el código en Python para las oraciones de etiquetado POS. Para este propósito, he usado Spacy aquí, pero hay otras bibliotecas como NLTK y Estrofa, que también se puede utilizar para hacer lo mismo.

En el ejemplo de código anterior, he cargado el espacio en_web_core_sm modelo y lo usé para obtener las etiquetas POS. Puedes ver que el pos_ devuelve las etiquetas POS universales, y etiqueta_ devuelve etiquetas POS detalladas para las palabras de la oración.
Análisis de dependencia
El análisis de dependencias es el proceso de analizar la estructura gramatical de una oración en función de las dependencias entre las palabras de una oración.
En el análisis de dependencias, varias etiquetas representan la relación entre dos palabras en una oración. Estas etiquetas son las etiquetas de dependencia. Por ejemplo, en la frase «tiempo lluvioso», la palabra lluvioso modifica el significado del sustantivo clima. Por lo tanto, existe una dependencia del clima -> lluvioso en el que el clima actúa como el cabeza y el lluvioso actúa como dependiente o niño. Esta dependencia está representada por amod tag, que representa el modificador de adjetivo.
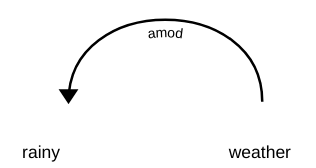
De manera similar, existen muchas dependencias entre las palabras en una oración, pero tenga en cuenta que una dependencia involucra solo dos palabras en las que una actúa como la cabeza y la otra actúa como el niño. A partir de ahora, hay 37 relaciones de dependencia universales utilizadas en Dependencia Universal (versión 2). Puedes echarles un vistazo a todos aquí. Aparte de estos, también existen muchas etiquetas específicas del idioma.
Ahora usemos Spacy y busquemos las dependencias en una oración.

En el ejemplo de código anterior, el dep_ devuelve la etiqueta de dependencia de una palabra y cabeza de texto devuelve el respectivo cabeza palabra. Si notó, en la imagen de arriba, la palabra tomó tiene una etiqueta de dependencia de RAÍZ. Esta etiqueta se asigna a la palabra que actúa como el encabezado de muchas palabras en una oración, pero no es hija de ninguna otra palabra. Generalmente, es el verbo principal de la oración similar a ‘tomó’ en este caso.
Ahora ya sabe qué etiquetas de dependencia y qué palabra principal, secundaria y raíz son. ¿Pero no significa el análisis sintáctico generar un árbol de análisis sintáctico?
Sí, estamos generando el árbol aquí, pero no lo estamos visualizando. El árbol generado por el análisis de dependencias se conoce como árbol de dependencias. Hay varias formas de visualizarlo, pero en aras de la simplicidad, usaremos DESPLAZAMIENTO que se utiliza para visualizar el análisis de dependencia.

En la imagen de arriba, las flechas representan la dependencia entre dos palabras en las que la palabra en la punta de la flecha es el niño y la palabra al final de la flecha es la cabeza. La palabra raíz puede actuar como el encabezado de varias palabras en una oración, pero no es hija de ninguna otra palabra. Puede ver arriba que la palabra ‘tomó’ tiene múltiples flechas salientes pero ninguna entrante. Por tanto, es la raíz de la palabra. Una cosa interesante acerca de la palabra raíz es que si comienza a rastrear las dependencias en una oración, puede llegar a la palabra raíz, sin importar desde qué palabra comience.
Ahora que conoce el análisis de dependencias, aprendamos sobre otro tipo de análisis conocido como Análisis de constituyentes.
Análisis de circunscripciones
El análisis de constituyentes es el proceso de analizar las oraciones dividiéndolas en subfrases también conocidas como constituyentes. Estas subfrases pertenecen a una categoría específica de gramática como NP (frase nominal) y VP (frase verbal).
Entendamos con la ayuda de un ejemplo. Supongamos que tengo la misma oración que usé en ejemplos anteriores, es decir, «Me tomó más de dos horas traducir algunas páginas de inglés». y he realizado un análisis de circunscripción en él. Entonces, el árbol de análisis de constituyentes para esta oración viene dado por:
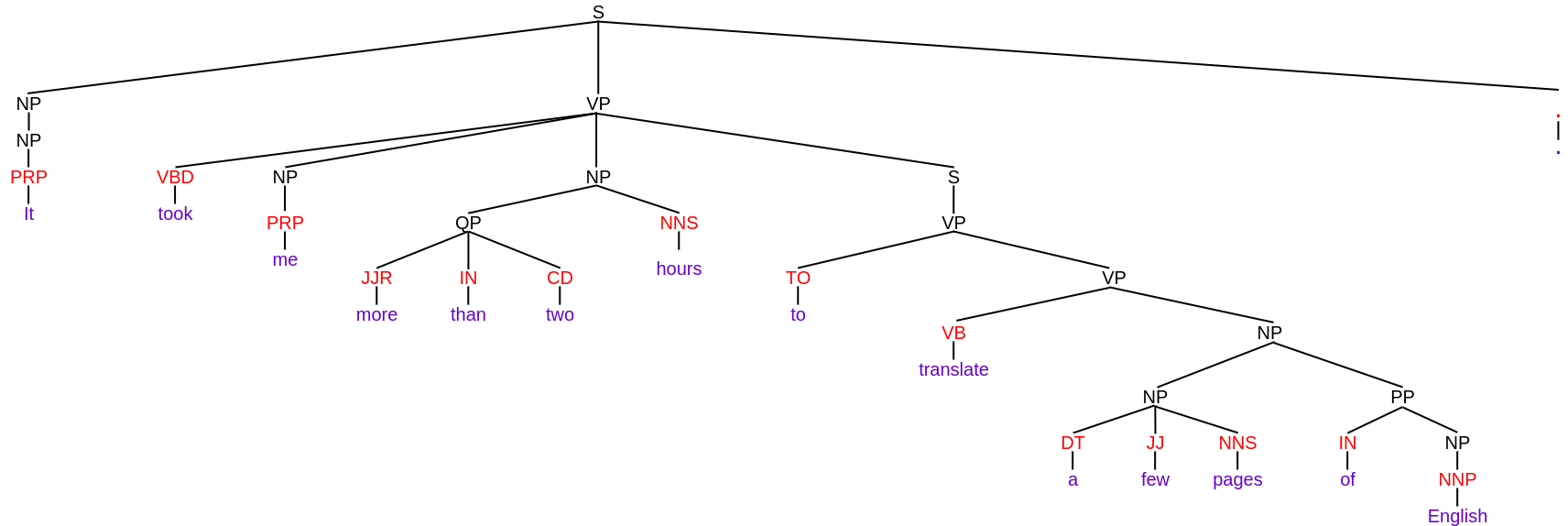
En el árbol anterior, las palabras de la oración están escritas en color púrpura y las etiquetas POS están escritas en color rojo. A excepción de estos, todo está escrito en color negro, que representa los componentes. Puede ver claramente cómo toda la oración se divide en subfrases hasta que solo quedan las palabras en las terminales. Además, existen diferentes etiquetas para denotar componentes como
- VP para frase verbal
- NP para frases nominales
Estas son las etiquetas constitutivas. Puede leer sobre diferentes etiquetas constituyentes aquí.
Ahora ya sabe qué es el análisis de circunscripciones, por lo que es hora de codificar en Python. Ahora, spaCy no proporciona una API oficial para el análisis de constituyentes. Por lo tanto, usaremos el Analizador neuronal de Berkeley. Es una implementación de Python de los analizadores basada en Análisis de la circunscripción con un codificador atento de ACL 2018.
También puede usar StanfordParser con Stanza o NLTK para este propósito, pero aquí he usado Berkely Neural Parser. Para usar esto, primero necesitamos instalarlo. Puede hacerlo ejecutando el siguiente comando.
!pip install benepar
Entonces tienes que descargar el benerpar_en2 modelo.
Es posible que haya notado que estoy usando TensorFlow 1.x aquí porque actualmente, el benepar no es compatible con TensorFlow 2.0. Ahora es el momento de analizar los distritos electorales.

Aquí, _.parse_string genera el árbol de análisis en forma de cadena.
Notas finales
Ahora, ya sabe qué son el etiquetado de POS, el análisis de dependencias y el análisis de constituyentes y cómo lo ayudan a comprender los datos de texto, es decir, las etiquetas de POS le informan sobre la parte gramatical de las palabras en una oración, el análisis de dependencias le informa sobre la las dependencias existentes entre las palabras de una oración y el análisis de constituyentes le informa sobre las subfrases o constituyentes de una oración. Ahora está listo para pasar a partes más complejas de la PNL. Como próximos pasos, puede leer los siguientes artículos sobre la extracción de información.
En estos artículos, aprenderá a usar etiquetas POS y etiquetas de dependencia para extraer información del corpus. Además, si desea obtener más información sobre spaCy, puede leer este artículo: Tutorial de spaCy para aprender y dominar el procesamiento del lenguaje natural (PNL) Aparte de estos, si desea aprender el procesamiento del lenguaje natural a través de un curso, puedo recomendarle lo siguiente que incluye todo, desde proyectos hasta tutorías individuales:
Si este artículo le pareció informativo, compártalo con sus amigos. Además, puedes comentar debajo de tus consultas.





