Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
¡Una guía paso a paso para comenzar con Seaborn!
Si matplotlib «intenta hacer las cosas fáciles fáciles y las difíciles posibles», seaborn intenta hacer que un conjunto bien definido de cosas difíciles también sea fácil.
Frescura de Seaborn:
Las mayores fortalezas de Seaborn son su diversidad de funciones de trazado. ¡Nos permite hacer gráficos complicados incluso en una sola línea de código!
En este tutorial, utilizaremos tres bibliotecas para hacer el trabajo: Matplotlib, Seaborn, Pandas. Si eres un principiante completo en Python, te sugiero que comiences y te familiarices un poco con Matplotlib y Pandas.
Si sigue exactamente este tutorial, podrá crear hermosos gráficos con estas tres bibliotecas. A continuación, puede utilizar mi código como plantilla para futuras tareas de visualización en el futuro.
Comencemos nuestro viaje en el mar con el famoso conjunto de datos de Pokémon. Antes de comenzar, le recomiendo encarecidamente que escriba sus propios códigos base para cada gráfico e intente experimentar con gráficos.
Puedes encontrar el conjunto de datos de Pokémon en Kaggle. Sin embargo, para facilitar su viaje, he acortado y limpiado esta versión del conjunto de datos.
Puede descargar el conjunto de datos aquí: https://github.com/shelvi31/Seaborn-Experiments
Mi súper ahorrador: Me gustaría mencionar un recurso que siempre es mi súper ahorro cuando estoy atascado. https://python-graph-gallery.com/ .
Empecemos ahora:
Comenzaremos con la importación de las bibliotecas necesarias:
#importing libraries import pandas as pd import matplotlib.pyplot as plt import seaborn as sns
Leer el archivo CSV
data = pd.read_csv(“Pokemon.csv”,encoding= ‘unicode_escape’)
Cambié el error del códec utf8 definiendo un paquete de códec diferente en el comando read_csv ().
Nuestros datos se parecen a esto….
data.head()
Producción:
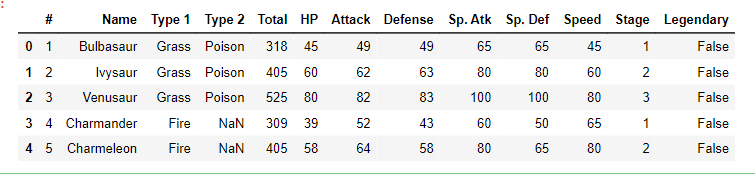 Producción
ProducciónEl nombre de las columnas no simplifica claramente su propósito. Es importante conocer el conjunto de datos antes de trabajar en él.
Aquí está la descripción simplificada del conjunto de datos para usted.
Este conjunto de datos incluye 150 Pokémon, se trata de los juegos de Pokémon (NO tarjetas de Pokémon o Pokémon Go).
En este conjunto de datos, tenemos 150 filas y 13 columnas.
Descripción de las columnas:
# ID para cada pokemon
# Nombre: Nombre de cada pokemon
# Tipo 1: cada pokemon tiene un tipo, esto determina la debilidad / resistencia a los ataques
# Tipo 2: Algunos Pokémon son de tipo dual y tienen 2
# Total: suma de todas las estadísticas que vienen después de esto, una guía general de qué tan fuerte es un Pokémon
# HP: puntos de golpe, o salud, define cuánto daño puede soportar un pokemon antes de desmayarse
# Ataque: el modificador base para ataques normales (por ejemplo, Scratch, Punch)
# Defensa: la resistencia base al daño contra ataques normales.
# SP Atk: ataque especial, el modificador base para ataques especiales (por ejemplo, explosión de fuego, haz de burbujas)
# SP Def: la resistencia base al daño contra ataques especiales
# Velocidad: determina qué Pokémon ataca primero en cada ronda.
# Etapa: Número de generación
#Legendario: verdadero si es un Pokémon legendario, falso si no
He cambiado el nombre de los nombres de las columnas para dar más sentido a nuestro trazado y para mayor claridad mental. Aunque es opcional, le recomiendo encarecidamente que lo haga para eliminar cualquier posibilidad de confusión.
data.rename(columns = {“#”:”No.”,”Type 1":”Pokemon_Type”,”Type 2":”PokemonType2",’Total’:’Sum of Attack’,”HP”:”Hit Points”,”Attack” : “Attack Strength”, “Defense”:”Defensive Strength”,”Sp. Atk”:”Special Attack Stenth”,”Sp. Def”:”Special Defense Strength”,”Stage”:”Generation”}, inplace = True)data.head()
Mi salida ahora se ve:
 ¡Mucho mejor!
¡Mucho mejor!Comencemos la visualización con los simples, el gráfico de distribuciones.
Parcelas de distribución:
A parcela de distribución muestra un distribución y rango de un conjunto de valores numéricos trazados contra una dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y.... Los histogramasLos histogramas son representaciones gráficas que muestran la distribución de un conjunto de datos. Se construyen dividiendo el rango de valores en intervalos, o "bins", y contando cuántos datos caen en cada intervalo. Esta visualización permite identificar patrones, tendencias y la variabilidad de los datos de manera efectiva, facilitando el análisis estadístico y la toma de decisiones informadas en diversas disciplinas.... le permiten trazar las distribuciones de variables numéricas.
Podría haber usado «Data.hist (figsize = (12,10), bins = 20)» , pero como no todas las columnas de esta base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... tienen valores numéricos. Por lo tanto, tengo que trazar parcelas de distribución individuales.
plt.figure(figsize=(4,3)) sns.distplot(x=data[“Sum of Attack”],color=”Orange”,kde=True,rug=True); plt.show()
Salida de la gráfica de distribución: suma del ataque de Pokémon
La función de trazado de seaborn traza un histograma con una curva de densidad. Podemos eliminar la densidad usando la opción kde = ”False”. Controlar la presencia de alfombras usando rug = ”True”.
Hay muchas formas alternativas de trazar un histograma en Python:
plt.figure(figsize=(3,3)) sns.histplot(x=data[“Sum of Attack”],color=”Green”); plt.show()
Otra forma es: usando plt.hist ()
plt.figure(figsize=(3,3)) plt.hist(x=data["Sum of Attack"],color="Red",bins=20); plt.show()
Por lo tanto, existen muchas formas de graficar distribuciones. Todas las funciones pyplot.hist, seaborn.coOutuntplot y seaborn.displot actúan como envoltorios para un diagrama de barras de matplotlib y se pueden usar si trazar manualmente dicho diagrama de barras se considera demasiado engorroso.
- Para variables discretas, un
seaborn.countplotes más conveniente. - Para variables continuas:
pyplot.histoseaborn.distplotson usados.
Parcelas de distribución conjunta:
Los diagramas de distribución conjunta combinan información de diagramas de dispersión e histogramas para darnos información detallada para distribuciones bivariadas.
sns.jointplot(x=data[“Sum of Attack”],y=data[“Defensive Strength”],color=”Red”);
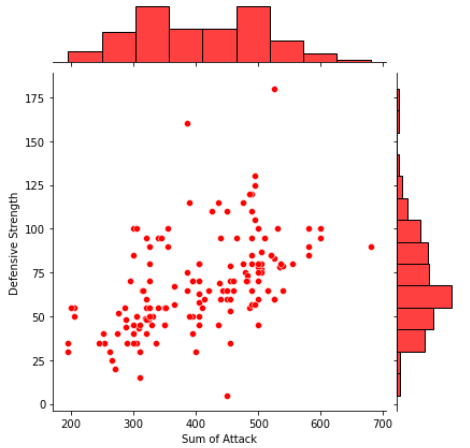
Salida: Jointplot
Gráficos de densidad:
Los gráficos de densidad muestran la distribución entre dos variables.
sns.kdeplot(x=data[“Sum of Attack”],y=data[“Defensive Strength”]) plt.show()
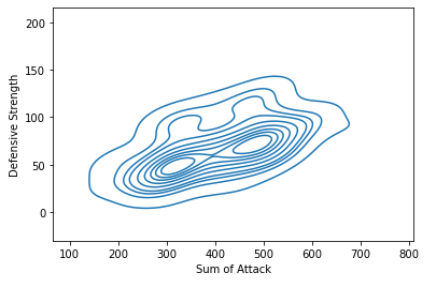 Salida: Gráfico de densidad
Salida: Gráfico de densidadGráfico de barras
Los diagramas de barras nos ayudan a visualizar las distribuciones de variables categóricas: Countplot es un tipo de diagrama de barras.
plt.figure(figsize=(10,6)); sns.countplot(x=data.Pokemon_Type,palette=pkmn_type_colors); plt.show()
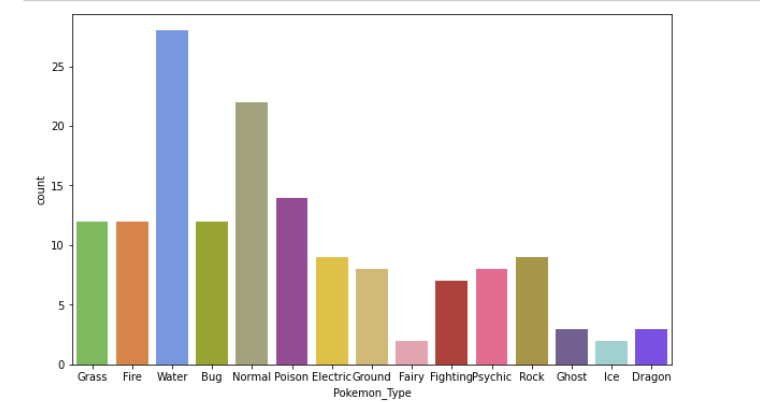 Salida: Gráfico de barrasEl gráfico de barras es una representación visual de datos que utiliza barras rectangulares para mostrar comparaciones entre diferentes categorías. Cada barra representa un valor y su longitud es proporcional a este. Este tipo de gráfico es útil para visualizar y analizar tendencias, facilitando la interpretación de información cuantitativa. Es ampliamente utilizado en diversas disciplinas, como la estadística, el marketing y la investigación, debido a su simplicidad y efectividad....
Salida: Gráfico de barrasEl gráfico de barras es una representación visual de datos que utiliza barras rectangulares para mostrar comparaciones entre diferentes categorías. Cada barra representa un valor y su longitud es proporcional a este. Este tipo de gráfico es útil para visualizar y analizar tendencias, facilitando la interpretación de información cuantitativa. Es ampliamente utilizado en diversas disciplinas, como la estadística, el marketing y la investigación, debido a su simplicidad y efectividad....Mapa de calorUn "mapa de calor" es una representación gráfica que utiliza colores para mostrar la densidad de datos en un área específica. Comúnmente utilizado en análisis de datos, marketing y estudios de comportamiento, este tipo de visualización permite identificar patrones y tendencias rápidamente. A través de variaciones cromáticas, los mapas de calor facilitan la interpretación de grandes volúmenes de información, ayudando a la toma de decisiones informadas....
Mapa de calor nos ayuda a visualizar datos matriciales en forma de puntos calientes y fríos. Los colores cálidos indicaron las secciones con la mayor interacción de los visitantes.
plt.figure(figsize=(8,6)); sns.heatmap(data.corr());# Rotate x-labels with the help of matplotlib plt.xticks(rotation=-45);
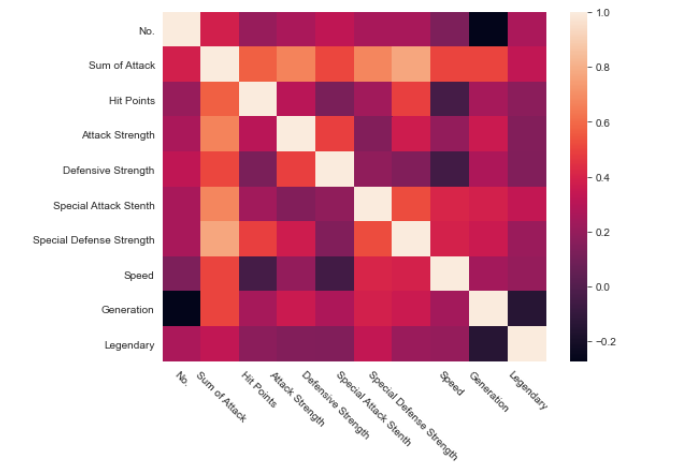 Salida: mapa de calor
Salida: mapa de calorGráfico de dispersiónUn gráfico de dispersión es una representación visual que muestra la relación entre dos variables numéricas mediante puntos en un plano cartesiano. Cada eje representa una variable, y la ubicación de cada punto indica su valor en relación con ambas. Este tipo de gráfico es útil para identificar patrones, correlaciones y tendencias en los datos, facilitando el análisis y la interpretación de relaciones cuantitativas....:
A gráfico de dispersión (también conocido como dispersión gráfico, Gráfico de dispersión) utiliza puntos para representar valores para dos variables numéricas diferentes. La posición de cada punto en el eje horizontal y vertical indica valores para un punto de datos individual.
Gráfico de dispersión se utilizan para observar relaciones entre variables.
He comparado las estadísticas de ataque y defensa de nuestros Pokémon con la ayuda de diagramas de dispersión.
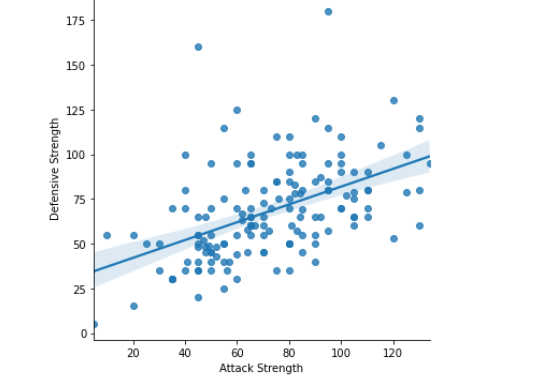 Salida: gráfico de dispersión
Salida: gráfico de dispersiónSeaborn no tiene una función de diagrama de dispersiónEl diagrama de dispersión es una herramienta gráfica utilizada en estadística para visualizar la relación entre dos variables. Consiste en un conjunto de puntos en un plano cartesiano, donde cada punto representa un par de valores correspondientes a las variables analizadas. Este tipo de gráfico permite identificar patrones, tendencias y posibles correlaciones, facilitando la interpretación de datos y la toma de decisiones basadas en la información visual presentada.... dedicada, por lo que vemos una línea diagonal (línea de regresión) aquí de forma predeterminada.
Afortunadamente, seaborn nos ayuda a modificar la trama:
- fit_reg = False se usa para eliminar la línea de regresión
- hue = ‘Stage’ se usa para colorear puntos por un tercer valor variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos..... De esta forma, nos permite expresar la tercera dimensión de la información utilizando el color.
¡Aquí tengo la etapa de evolución de Pokémon como tercera variable!
#Tweaking with scatter plotsns.lmplot(x=’Attack Strength’, y=’Defensive Strength’, data=data, fit_reg = False, #Deleting regression line hue=”Generation”); #Separating as per pokemon generation
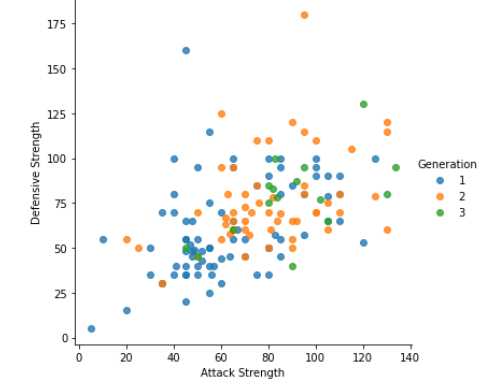 Resultado: gráfico de dispersión ajustado
Resultado: gráfico de dispersión ajustadoMás de la densidad cae en la marca 40-120, alteraré los límites de los ejes con la ayuda de matplotlib:
sns.lmplot(x=’Attack Strength’, y=’Defensive Strength’, data=data, fit_reg = False, #Deleting regression line hue=”Generation”); #Separating as per pokemon generationplt.ylim(20,130); plt.xlim(25,125);
¡Ahora podemos ver un gráfico mejor y más enfocado!
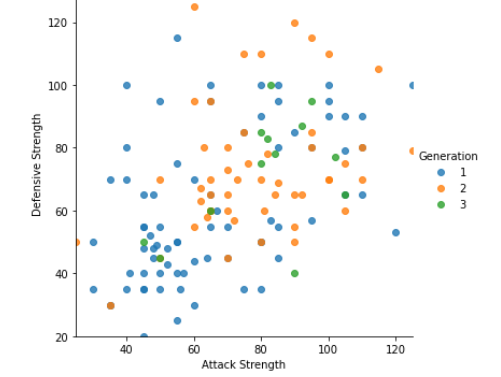 Resultado: mejor trazado de dispersión
Resultado: mejor trazado de dispersiónDiagrama de caja
Se utiliza un diagrama de caja para representar grupos de datos numéricos a través de su cuartiles.
Los diagramas de cajaLos diagramas de caja, también conocidos como diagramas de caja y bigotes, son herramientas estadísticas que representan la distribución de un conjunto de datos. Estos diagramas muestran la mediana, los cuartiles y los valores atípicos, lo que permite visualizar la variabilidad y la simetría de los datos. Son útiles en la comparación entre diferentes grupos y en el análisis exploratorio, facilitando la identificación de tendencias y patrones en los datos.... también pueden tener líneas que se extienden desde las cajas indicando variabilidad fuera del cuartiles superior e inferior, de ahí los términos diagrama de caja y bigotes y diagrama de caja y bigotes
Podemos eliminar la columna «Suma de ataque» ya que tenemos estadísticas individuales. También podemos eliminar las columnas «Generación» y «Legendario» porque no están combatiendo las estadísticas.
plt.figure(figsize=(15,7));# Pre-format DataFrame stats_data = data.drop([‘Sum of Attack’, ‘Generation’, ‘Legendary’], axis=1); # New boxplot using stats_df sns.boxplot(data=stats_data, showfliers=False); #Removing outlierssns.set_style(“whitegrid”)
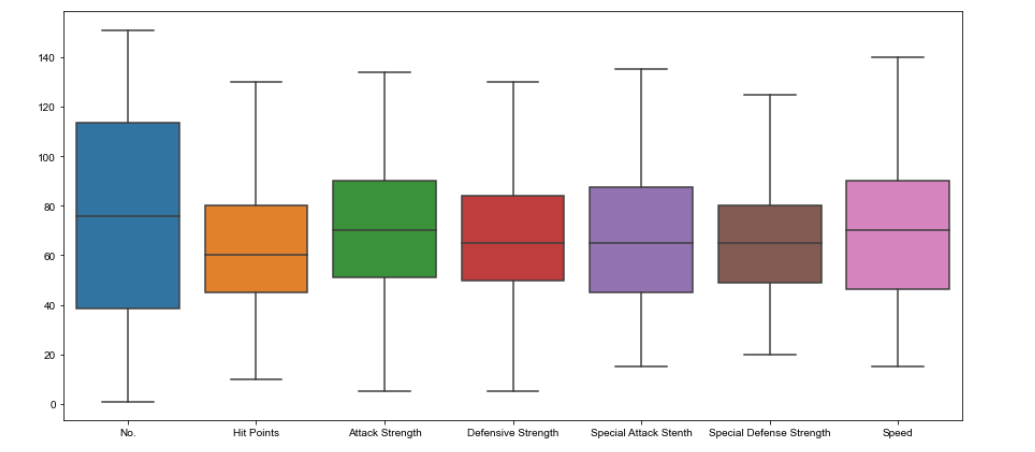 Salida: Diagrama de caja
Salida: Diagrama de cajaRecuerde mantener el tamaño de la figuraEl "tamaño de la figura" se refiere a las dimensiones y proporciones de un objeto o representación en el ámbito del arte, diseño y anatomía. Este concepto es fundamental para la composición visual, ya que influye en la percepción y el impacto de la obra. Comprender el tamaño adecuado permite crear un equilibrio estético y una jerarquía visual, facilitando así la comunicación efectiva del mensaje deseado.... antes de trazar el gráfico.
Tramas de violín
Ahora trazaré la trama del violín.
Los diagramas de violín son alternativas a los diagramas de caja. Muestran la distribución (a través del grosor del violín) en lugar de solo las estadísticas de resumen.
Aquí he mostrado la distribución de Ataque por tipo primario de Pokémon
plt.figure(figsize=(15,7)); sns.violinplot(x=data.Pokemon_Type, y = data[“Attack Strength”]);
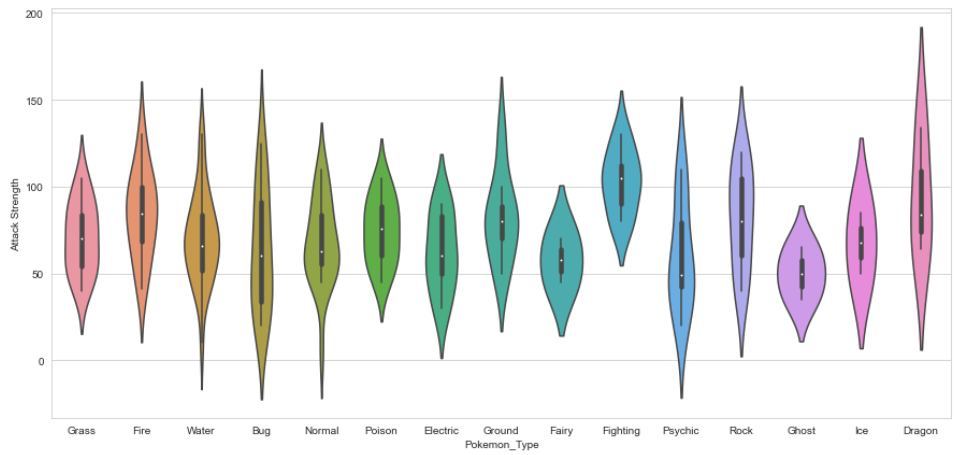 Salida: Parcela de violín
Salida: Parcela de violínComo puede ver, los tipos Dragón tienden a tener estadísticas de ataque más altas que los tipos Fantasma, pero también tienen una mayor variación.
Ahora, los fanáticos de Pokémon pueden encontrar algo bastante discordante en esa trama: Los colores son absurdos. ¿Por qué el tipo Hierba es de color rosa o el tipo Agua es de color naranja? ¡Debemos arreglar esto de inmediato!
Afortunadamente, Seaborn nos permite configurar paletas de colores personalizadas. Simplemente podemos crear un pedido Lista de Python de valores hexadecimales de color.
He usado Bulbapedia para crear una nueva paleta de coloresLa paleta de colores es una herramienta fundamental en el diseño gráfico y la decoración. Consiste en una selección de colores que se utilizan de manera armoniosa para crear una atmósfera específica o transmitir emociones. Existen diversas teorías del color que ayudan a elegir combinaciones efectivas, como la rueda de color y el contraste. Una paleta bien definida puede mejorar la estética y la comunicación visual de un proyecto.....
# using Bulbapedia to create a new color palette:#Bulbapedia : https://bulbapedia.bulbagarden.net/wiki/Category:Type_color_templatspkmn_type_colors = [‘#78C850’, # Grass ‘#F08030’, # Fire ‘#6890F0’, # Water ‘#A8B820’, # Bug ‘#A8A878’, # Normal ‘#A040A0’, # Poison ‘#F8D030’, # Electric ‘#E0C068’, # Ground ‘#EE99AC’, # Fairy ‘#C03028’, # Fighting ‘#F85888’, # Psychic ‘#B8A038’, # Rock ‘#705898’, # Ghost ‘#98D8D8’, # Ice ‘#7038F8’, # Dragon ]
Realización de modificaciones en la trama del violín según el color del tipo de Pokémon:
plt.figure(figsize=(15,7)); sns.violinplot(x=data.Pokemon_Type, y = data[“Attack Strength”], palette = pkmn_type_colors);
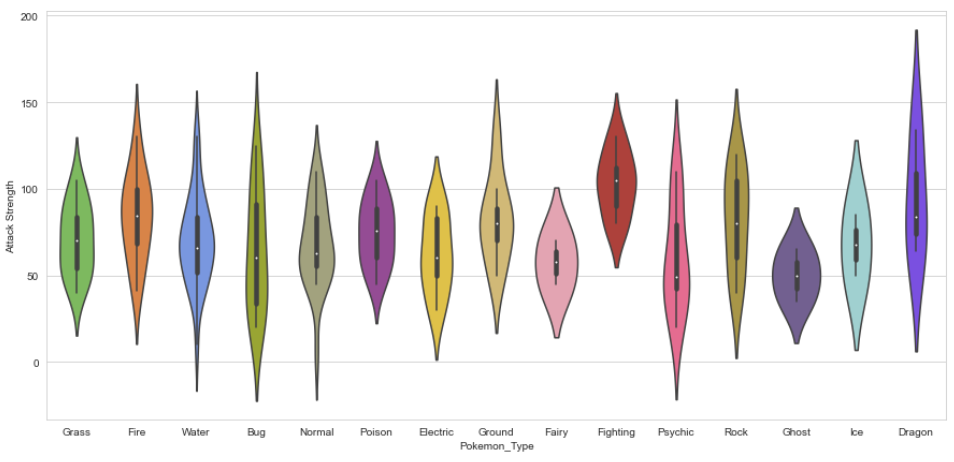 Resultado: Mejor trama de violín 🙂
Resultado: Mejor trama de violín 🙂Swarmplots
Como ha visto, los gráficos de violín son excelentes para visualizar distribuciones.
Sin embargo, dado que solo tenemos 150 Pokémon en nuestro conjunto de datos, es posible que queramos simplemente mostrar cada punto. Ahí es donde el trama de enjambre entra. Esta visualización mostrará cada punto, mientras «apila» aquellos con valores similares.
plt.figure(figsize=(12,5)); sns.swarmplot(x=data.Pokemon_Type,y=data[“Attack Strength”],palette=pkmn_type_colors);
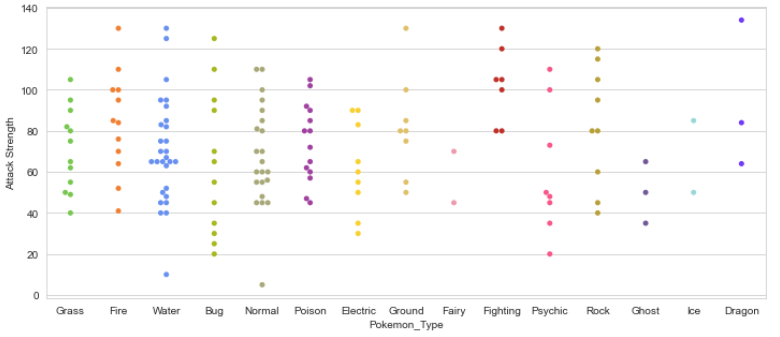 Swarmplot: Pokémon Tipo Vs Fuerza de ataque
Swarmplot: Pokémon Tipo Vs Fuerza de ataqueEsto se ve bien, pero para obtener mejores imágenes, ¡podemos combinar estos dos! Después de todo, muestran la misma información.
Gráficos superpuestos
plt.figure(figsize=(10,10))sns.violinplot(x=data.Pokemon_Type, y = data[“Attack Strength”], inner=None, palette = pkmn_type_colors);sns.swarmplot(x=”Pokemon_Type”, y=”Attack Strength”, data=data, color=’black’, #making points black alpha=0.5);plt.title(“Attacking Strength as per Pokemon’s Type”);
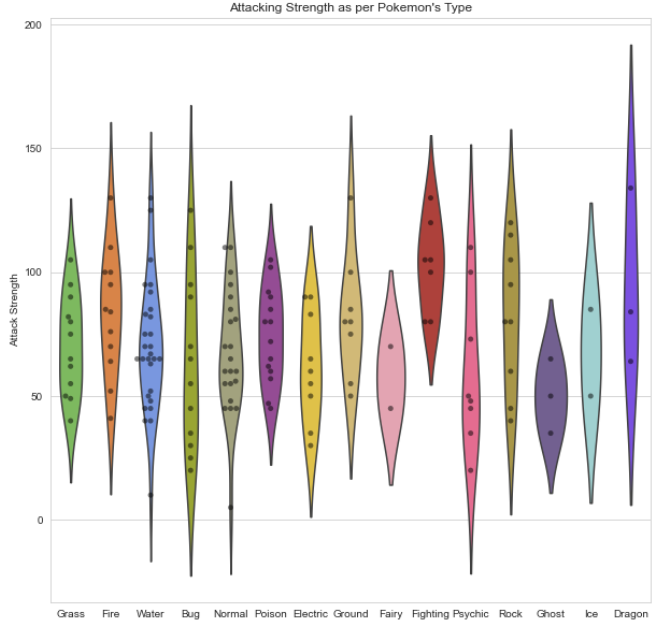 Gráficos superpuestos
Gráficos superpuestosPuntos a tener en cuenta:
inner = None: quita las barras dentro de los violines
alpha = 0.5: hace que los puntos sean ligeramente transparentes: recuerde que el valor alfa debe ser flotante, no lo mantenga en «»
Puede encontrar las referencias para el color marino aquí: https://python-graph-gallery.com/100-calling-a-color-with-seaborn/
Gráficos de factores
Las gráficas de factores facilitan la separación de las gráficas por clases categóricas.
plt.figure(figsize=(5,15)) factplot= sns.factorplot(x="Pokemon_Type",y="Attack Strength",data=data,hue="Generation",col="Generation",kind="swarm");factplot.set_xticklabels(rotation=-45) plt.show()
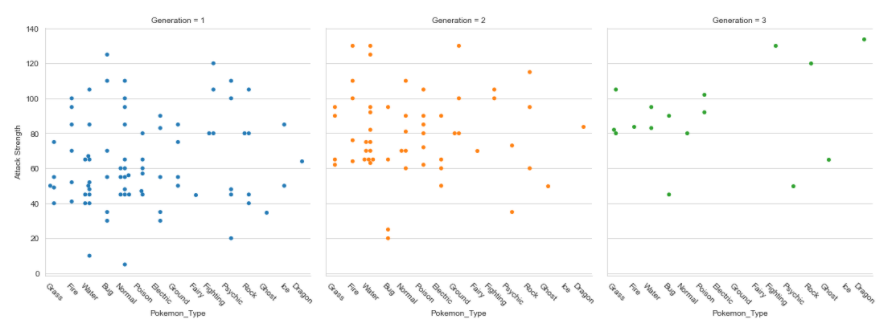 Factorplot: para clases categóricas separadas
Factorplot: para clases categóricas separadasNotas rápidas:
- plt.xticks (rotación = -45): no funciona porque solo rota el último gráfico
- Necesita usar: set_xticklabels





