Almacene modelos en depósitos de Google Cloud Storage y posteriormente escriba Google Cloud Functions. Usando Python para recuperar modelos del depósito y usando solicitudes HTTP JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software..., podemos obtener valores predichos para las entradas dadas con la ayuda de Google Cloud Function.
1. Con relación a los datos, el código y los modelos
Tomando las reseñas de películas conjuntos de datos para el análisis de sentimiento, vea la respuesta aquí en mi repositorio de GitHub y datos, modelos además disponible en el mismo repositorio.
2. Crea un depósito de almacenamiento
Al ejecutar el «ServerlessDeployment.ipynb“Archivo obtendrá 3 modelos ML: Clasificador de decisiones, LinearSVC y Regresión logística.
Haga clic en la opción Navegador en almacenamiento para crear un nuevo depósito como se muestra en la imagen:
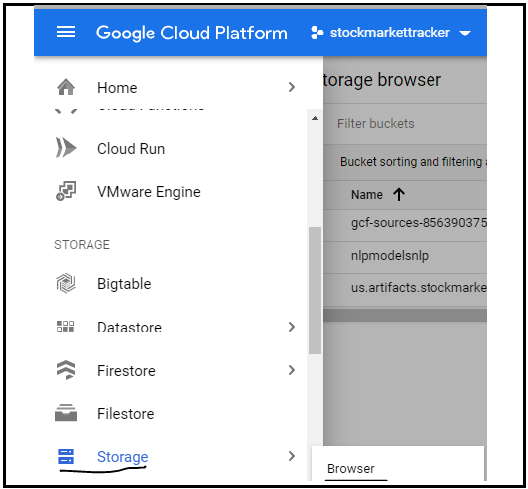
Higo: haga clic en la opción Store de GCP
3. Cree una nueva función
Cree un nuevo depósito, posteriormente cree una carpeta y cargue los 3 modelos en esa carpeta creando 3 subcarpetas como se muestra.
Aquí modelos son mi nombre de carpeta principal y mis subcarpetas son:
- decision_tree_model
- linear_svc_model
- modelo_región_logística
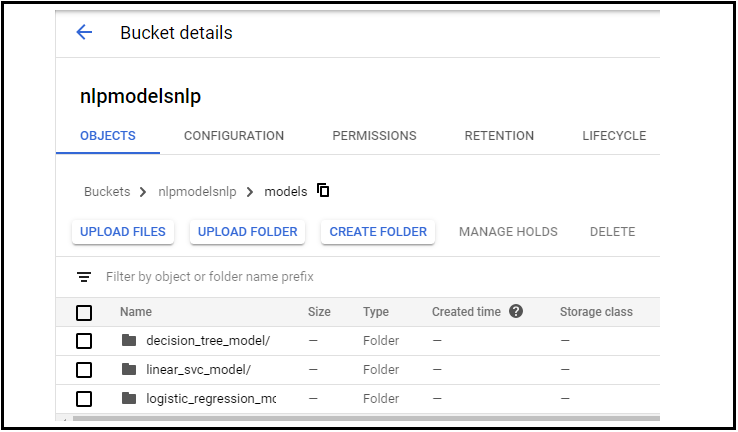
Higo: Carpetas en almacenamiento
4. Crea una función
Posteriormente, vaya a Google Cloud Functions y cree una función, posteriormente seleccione el tipo de activador como HTTP y seleccione el idioma como Python (puede seleccionar cualquier idioma):
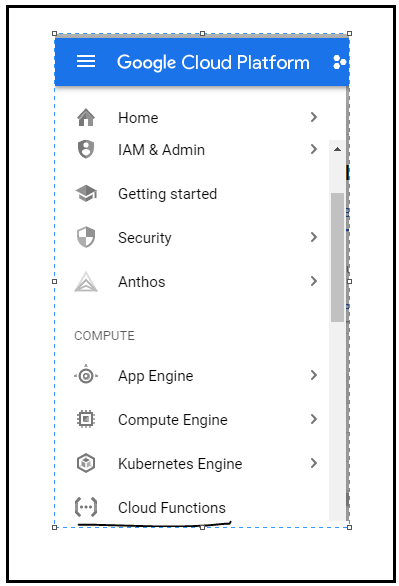
Higo: Seleccione la opción Cloud Function de GCP
5. Escribe la función de nube en el editor.
Verifique la función de la nube en mi repositorio, aquí he importado las bibliotecas requeridas para llamar a los modelos desde el depósito de la nube de Google y otras bibliotecas para la solicitud HTTP Método GET utilizado para probar la solución de URL y el método POST borrar la plantilla predeterminada y pegar nuestro código posteriormente pepinillo se utiliza para deserializar nuestro modelo google.cloud: acceda a nuestra función de almacenamiento en la nube.
Si la solicitud entrante es OBTENER simplemente devolvemos «bienvenido al clasificador».
Si la solicitud entrante es CORREO entrar a los datos JSON en la solicitud del cuerpo get JSON nos da para instanciar el objeto del cliente de almacenamiento y entrar a los modelos desde el depósito, aquí tenemos 3 – modelos de clasificación en el depósito.
Si el usuario especifica “Decision Classifier” accedemos al modelo desde la carpeta respectiva respectivamente con otros modelos.
Si el usuario no especifica ningún modelo, el modelo predeterminado es el modelo de regresión logística.
La variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... blob contiene una referencia al archivo model.pkl para el modelo correcto.
Descargamos el archivo .pkl en la máquina local donde se ejecuta esta función en la nube. Ahora, cada invocación podría estar ejecutándose en una VM distinto y solo accedemos a la carpeta / temp en la VM, es por ello que guardamos nuestro archivo model.pkl.
Desesterilizamos el modelo invocando pkl.load para entrar a las instancias de predicción desde la solicitud entrante y llamamos model.predict en los datos de predicción.
La solución que se enviará desde la función sin servidor es el texto original que es la revisión que queremos categorizar y nuestra clase pred.
Después de main.py, escriba requisito.txt con las bibliotecas y versiones imprescindibles
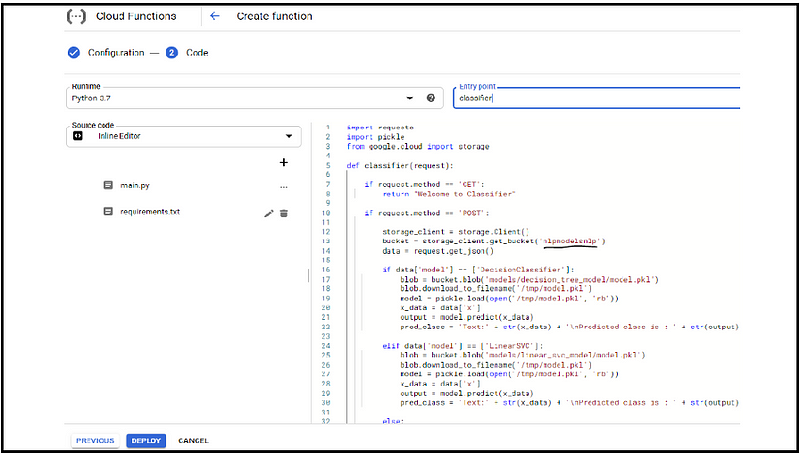
5. Poner en práctica el modelo
6. Prueba el modelo
Conviértase en un científico de datos de pila completa al aprender varias implementaciones de modelos de ML y el motivo detrás de esta gran explicación en los días iniciales.Me cuesta mucho aprender la implementación de modelos de ML, por lo que decidí que mi blog debería ser útil para los principiantes de la ciencia de datos de principio a fin.





