Este artículo fue publicado como parte del Blogatón de ciencia de datos

Según los expertos, el 80% de los datos existentes en el mundo se encuentran en forma de datos no estructurados (imágenes, videos, texto, etc.). Estos datos podrían ser generados por tweets / publicaciones de redes sociales, transcripciones de llamadas, reseñas de encuestas o entrevistas, mensajes de texto en blogs, foros, noticias, etc.
Es humanamente imposible leer todo el texto en la web y encontrar patrones. Sin embargo, definitivamente existe la necesidad de que la empresa analice estos datos para tomar mejores acciones.
Uno de esos procesos de obtención de conocimientos a partir de datos textuales es el análisis de sentimientos. Para obtener los datos para el análisis de sentimientos, uno puede raspar directamente el contenido de las páginas web utilizando diferentes técnicas de raspado web.
Si es nuevo en web scraping, no dude en consultar mi artículo «Web scraping con Python: BeautifulSoup».
¿Qué es el análisis de sentimiento?
El análisis de sentimientos (también conocido como minería de opiniones o IA de emociones) es un subcampo de la PNL que mide la inclinación de las opiniones de las personas (positivas / negativas / neutrales) dentro del texto no estructurado.
El análisis de sentimiento se puede realizar utilizando dos enfoques: basado en reglas, basado en aprendizaje automático.
Pocas aplicaciones del análisis de sentimiento
- Análisis de mercado
- Monitoreo de redes sociales
- Análisis de los comentarios de los clientes: análisis de la opinión de la marca o de la reputación
- Investigación de mercado
¿Qué es el procesamiento del lenguaje natural (PNL)?
El lenguaje natural es la forma en que nosotros, los humanos, nos comunicamos entre nosotros. Puede ser voz o texto. PNL es la manipulación automática del lenguaje natural por software. PNL es un término de nivel superior y es la combinación de Comprensión del lenguaje natural (NLU) y Generación de lenguaje natural (NLG).
PNL = NLU + NLG
Algunas de las bibliotecas de procesamiento del lenguaje natural de Python (NLP) son:
- Kit de herramientas de lenguaje natural (NLTK)
- TextBlob
- ESPACIO
- Gensim
- CoreNLP
Espero que tengamos una comprensión básica de los términos Análisis de sentimiento, PNL.
Este artículo se centra en el enfoque basado en reglas del análisis de sentimientos.
Enfoque basado en reglas
Este es un enfoque práctico para analizar texto sin formación ni utilizar modelos de aprendizaje automático. El resultado de este enfoque es un conjunto de reglas basadas en las cuales el texto se etiqueta como positivo / negativo / neutral. Estas reglas también se conocen como léxicos. Por lo tanto, el enfoque basado en reglas se denomina enfoque basado en léxico.
Los enfoques basados en léxico ampliamente utilizados son TextBlob, VADER, SentiWordNet.
Pasos del preprocesamiento de datos:
- Limpiando el texto
- Tokenización
- Enriquecimiento: etiquetado de puntos de venta
- Eliminación de palabras irrelevantes
- Obtener las palabras raíz
Antes de profundizar en los pasos anteriores, déjame importar los datos de texto de un archivo txt.
Importar un archivo de texto usando Los pandas leen CSV función
# install and import pandas library import pandas as pd # Creating a pandas dataframe from reviews.txt file data = pd.read_csv('reviews.txt', sep='t') data.head()

Esto no se ve bien. Entonces, ahora soltaremos el «Sin nombre: 0 ″ columna usando el df.drop función.
mydata = data.drop('Unnamed: 0', axis=1)
mydata.head()

Nuestro conjunto de datos tiene un total de 240 observaciones (revisiones).
Paso 1: Limpiar el texto
En este paso, necesitamos eliminar los caracteres especiales, números del texto. Podemos usar el operaciones de expresiones regulares biblioteca de Python.
# Define a function to clean the text
def clean(text):
# Removes all special characters and numericals leaving the alphabets
text = re.sub('[^A-Za-z]+', ' ', text)
return text
# Cleaning the text in the review column
mydata['Cleaned Reviews'] = mydata['review'].apply(clean)
mydata.head()
Explicación: “Limpiar” es la función que toma texto como entrada y lo devuelve sin signos de puntuación ni números. Lo aplicamos a la columna ‘revisión’ y creamos una nueva columna ‘Revisiones limpias’ con el texto limpio.

Genial, mira la imagen de arriba, se eliminan todos los caracteres especiales y los números.
Paso 2: Tokenización
La tokenización es el proceso de dividir el texto en partes más pequeñas llamadas Tokens. Se puede realizar a nivel de oraciones (tokenización de oraciones) o de palabra (tokenización de palabras).
Realizaré tokenización a nivel de palabra usando tokenizar nltk función word_tokenize ().
Nota: Como nuestros datos de texto son un poco grandes, primero ilustraré los pasos 2-5 con pequeñas oraciones de ejemplo.
Digamos que tenemos una oración «Este es un artículo sobre análisis de sentimientos.“. Se puede dividir en trozos pequeños (fichas) como se muestra a continuación.

Paso 3: Enriquecimiento: etiquetado POS
El etiquetado de Partes del habla (POS) es un proceso de conversión de cada token en una tupla que tiene la forma (palabra, etiqueta). El etiquetado POS es esencial para preservar el contexto de la palabra y es esencial para la lematización.
Esto se puede lograr utilizando nltk pos_tag función.
A continuación se muestran las etiquetas POS de la oración de ejemplo «Este es un artículo sobre análisis de opinión».
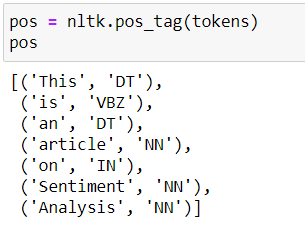
Consulte la lista de posibles etiquetas pos de aquí.
Paso 4: eliminación de palabras irrelevantes
Las palabras vacías en inglés son palabras que contienen muy poca información útil. Necesitamos eliminarlos como parte del preprocesamiento del texto. nltk tiene una lista de palabras vacías de cada idioma.
Consulte las palabras vacías en inglés.

Ejemplo de eliminación de palabras vacías:

Las palabras vacías This, is, an, on se eliminan y la oración de salida es ‘Análisis de opinión del artículo’.
Paso 5: obtención de las palabras raíz
Una raíz es parte de una palabra responsable de su significado léxico. Las dos técnicas populares para obtener las palabras raíz / raíz son Stemming y Lemmatization.
La diferencia clave es que Stemming a menudo da algunas palabras raíz sin sentido, ya que simplemente corta algunos caracteres al final. La lematización proporciona raíces significativas, sin embargo, requiere etiquetas POS de las palabras.
Ejemplo para ilustrar la diferencia entre Stemming y Lematization: Haga clic aquí para obtener el código

Si miramos el ejemplo anterior, la salida de Stemming es Stem y la salida de Lemmatizatin es Lemma.
Por la palabra mirada, el tallo glanc no tiene sentido. Considerando que, el Lema mirada es perfecto.
Ahora entendimos los pasos 2-5 tomando ejemplos simples. Sin más demora, volvamos a nuestro problema real.
Código para los pasos 2 a 4: tokenización, etiquetado de POS, eliminación de palabras irrelevantes
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
from nltk import pos_tag
nltk.download('stopwords')
from nltk.corpus import stopwords
nltk.download('wordnet')
from nltk.corpus import wordnet
# POS tagger dictionary
pos_dict = {'J':wordnet.ADJ, 'V':wordnet.VERB, 'N':wordnet.NOUN, 'R':wordnet.ADV}
def token_stop_pos(text):
tags = pos_tag(word_tokenize(text))
newlist = []
for word, tag in tags:
if word.lower() not in set(stopwords.words('english')):
newlist.append(tuple([word, pos_dict.get(tag[0])]))
return newlist
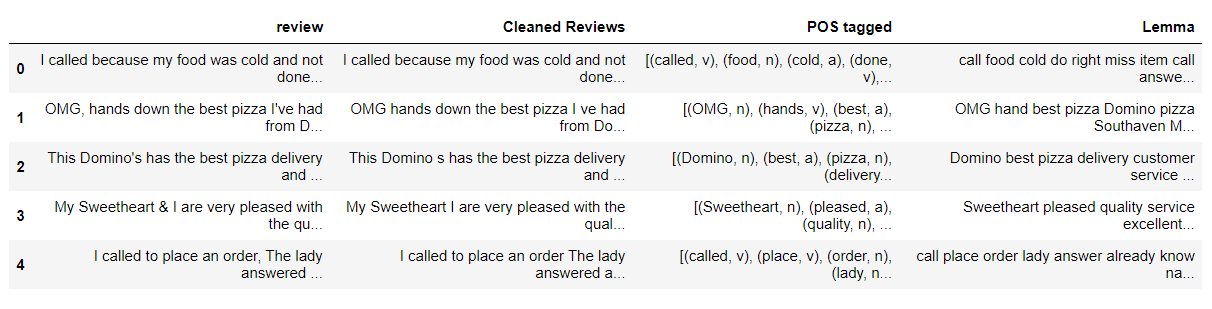
mydata['POS tagged'] = mydata['Cleaned Reviews'].apply(token_stop_pos)
mydata.head()
Explicación: token_stop_pos es la función que toma el texto y realiza la tokenización, elimina las palabras vacías y etiqueta las palabras en su POS. Lo aplicamos a la columna ‘Reseñas limpias’ y creamos una nueva columna para los datos de ‘POS etiquetados’.
Como se mencionó anteriormente, para obtener el Lema preciso, WordNetLemmatizer requiere etiquetas POS en forma de ‘n’, ‘a’, etc. Pero las etiquetas POS obtenidas de pos_tag tienen la forma ‘NN’, ‘ADJ’, etc.
Para asignar pos_tag a etiquetas de wordnet, creamos un diccionario pos_dict. Cualquier pos_tag que comience con J se asigna a wordnet.ADJ, cualquier pos_tag que comience con R se asigna a wordnet.ADV, y así sucesivamente.
Nuestras etiquetas de interés son Sustantivo, Adjetivo, Adverbio, Verbo. Cualquier cosa de estos cuatro se asigna a Ninguno.

En la figura"Figura" es un término que se utiliza en diversos contextos, desde el arte hasta la anatomía. En el ámbito artístico, se refiere a la representación de formas humanas o animales en esculturas y pinturas. En la anatomía, designa la forma y estructura del cuerpo. Además, en matemáticas, "figura" se relaciona con las formas geométricas. Su versatilidad hace que sea un concepto fundamental en múltiples disciplinas.... anterior, podemos observar que cada palabra de la columna ‘POS etiquetado’ se asigna a su POS desde pos_dict.
Código para el paso 5: obtención de las palabras raíz – Lematización
from nltk.stem import WordNetLemmatizer
wordnet_lemmatizer = WordNetLemmatizer()
def lemmatize(pos_data):
lemma_rew = " "
for word, pos in pos_data:
if not pos:
lemma = word
lemma_rew = lemma_rew + " " + lemma
else:
lemma = wordnet_lemmatizer.lemmatize(word, pos=pos)
lemma_rew = lemma_rew + " " + lemma
return lemma_rew
mydata['Lemma'] = mydata['POS tagged'].apply(lemmatize)
mydata.head()
Explicación: lemmatize es una función que toma tuplas pos_tag y da el Lema para cada palabra en pos_tag basado en el pos de esa palabra. Lo aplicamos a la columna ‘POS etiquetado’ y creamos una columna ‘Lema’ para almacenar la salida.
Sí, después de un largo viaje, hemos terminado con el procesamiento previo del texto.
Ahora, tómese un minuto para mirar las columnas ‘revisión’, ‘Lema’ y observe cómo se procesa el texto.
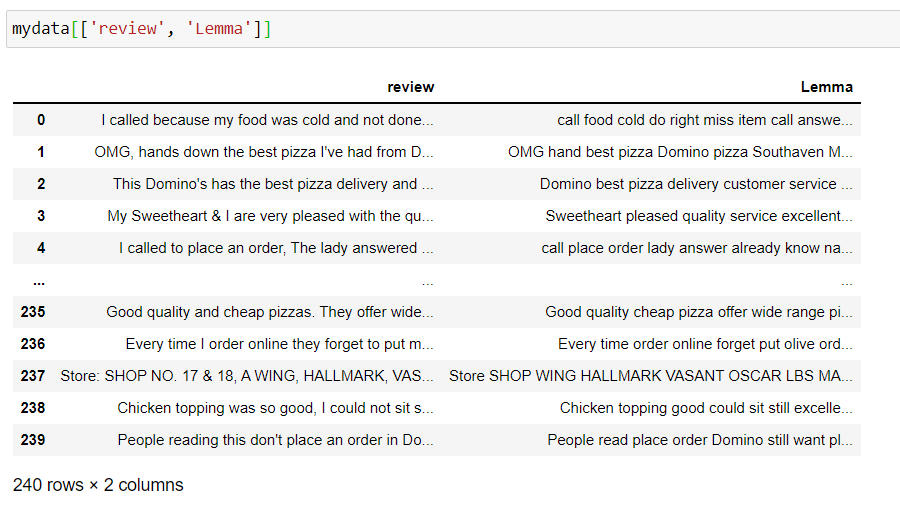
Cuando terminamos con el preprocesamiento de datos, nuestros datos finales se ven limpios. Tómate un breve descanso y vuelve para continuar con la tarea real.
Análisis de sentimiento usando TextBlob:
TextBlob es una biblioteca de Python para procesar datos textuales. Proporciona una API coherente para sumergirse en tareas comunes de procesamiento del lenguaje natural (NLP), como el etiquetado de parte del discurso, la extracción de frases nominales, el análisis de sentimientos y más.
Las dos medidas que se utilizan para analizar el sentimiento son:
- Polaridad: habla de cuán positiva o negativa es la opinión.
- Subjetividad: habla de cuán subjetiva es la opinión.
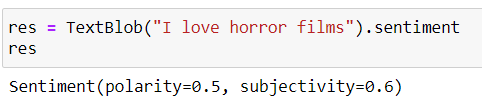
TextBlob (texto) .sentiment nos da los valores de Polaridad, Subjetividad.
La polaridad varía de -1 a 1 (1 es más positivo, 0 es neutral, -1 es más negativo)
La subjetividad varía de 0 a 1 (0 es muy objetivo y 1 muy subjetivo)
Código Python:
from textblob import TextBlob
# function to calculate subjectivity
def getSubjectivity(review):
return TextBlob(review).sentiment.subjectivity
# function to calculate polarity
def getPolarity(review):
return TextBlob(review).sentiment.polarity
# function to analyze the reviews
def analysis(score):
if score < 0:
return 'Negative'
elif score == 0:
return 'Neutral'
else:
return 'Positive'
Explicación: funciones creadas para obtener valores de polaridad, subjetividad y etiquetar la revisión en función de la puntuación de polaridad.
Crear un nuevo marco de datos con la revisión, columnas de Lema y aplicar las funciones anteriores
fin_data = pd.DataFrame(mydata[['review', 'Lemma']])
# fin_data['Subjectivity'] = fin_data['Lemma'].apply(getSubjectivity) fin_data['Polarity'] = fin_data['Lemma'].apply(getPolarity) fin_data['Analysis'] = fin_data['Polarity'].apply(analysis) fin_data.head()
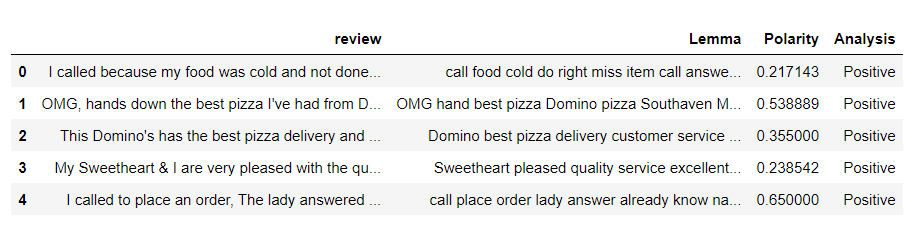
Cuente el número de críticas positivas, negativas y neutrales.
tb_counts = fin_data.Analysis.value_counts() tb_counts
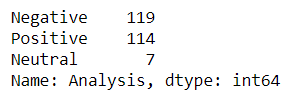
Análisis de sentimiento con VADER
VADER son las siglas de Valence Aware Dictionary y Sentiment Reasoner. El sentimiento de Vader no solo dice si la declaración es positiva o negativa junto con la intensidad de la emoción.

La suma de las intensidades pos, neg, neu da 1. El compuesto varía de -1 a 1 y es la métrica utilizada para dibujar el sentimiento general.
positivo si compuesto> = 0.5
neutro si -0,5 <compuesto <0,5
negativo si -0,5> = compuesto
Código Python:
from vaderSentiment.vaderSentiment import SentimentIntensityAnalyzer
analyzer = SentimentIntensityAnalyzer()
# function to calculate vader sentiment
def vadersentimentanalysis(review):
vs = analyzer.polarity_scores(review)
return vs['compound']
fin_data['Vader Sentiment'] = fin_data['Lemma'].apply(vadersentimentanalysis)
# function to analyse
def vader_analysis(compound):
if compound >= 0.5:
return 'Positive'
elif compound <= -0.5 :
return 'Negative'
else:
return 'Neutral'
fin_data['Vader Analysis'] = fin_data['Vader Sentiment'].apply(vader_analysis)
fin_data.head()
Explicación: Funciones creadas para obtener las puntuaciones de Vader y etiquetar las reseñas en función de las puntuaciones compuestas
Cuente el número de críticas positivas, negativas y neutrales.
vader_counts = fin_data['Vader Analysis'].value_counts() vader_counts
Análisis de sentimiento usando SentiWordNet
SentiWordNet utiliza la base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... WordNet. Es importante obtener el POS, lema de cada palabra. Luego usaremos el lema, POS para obtener los conjuntos de sinónimos (synsets). A continuación, obtenemos las puntuaciones objetivas, negativas y positivas para todos los sintetizadores posibles o el primer sintetizador y etiquetamos el texto.
si puntuación positiva> puntuación negativa, el sentimiento es positivo
si puntuación positiva <puntuación negativa, el sentimiento es negativo
si puntuación positiva = puntuación negativa, el sentimiento es neutral
Código Python:
nltk.download('sentiwordnet')
from nltk.corpus import sentiwordnet as swn
def sentiwordnetanalysis(pos_data):
sentiment = 0
tokens_count = 0
for word, pos in pos_data:
if not pos:
continue
lemma = wordnet_lemmatizer.lemmatize(word, pos=pos)
if not lemma:
continue
synsets = wordnet.synsets(lemma, pos=pos)
if not synsets:
continue
# Take the first sense, the most common
synset = synsets[0]
swn_synset = swn.senti_synset(synset.name())
sentiment += swn_synset.pos_score() - swn_synset.neg_score()
tokens_count += 1
# print(swn_synset.pos_score(),swn_synset.neg_score(),swn_synset.obj_score())
if not tokens_count:
return 0
if sentiment>0:
return "Positive"
if sentiment==0:
return "Neutral"
else:
return "Negative"
fin_data['SWN analysis'] = mydata['POS tagged'].apply(sentiwordnetanalysis)
fin_data.head()
Explicación: Creamos una función para obtener los puntajes positivos y negativos para la primera palabra del synset y luego etiquetar el texto calculando el sentimiento como la diferencia de puntajes positivos y negativos.
Cuente el número de críticas positivas, negativas y neutrales.
swn_counts= fin_data['SWN analysis'].value_counts() swn_counts
Hasta aquí, hemos visto la implementación del análisis de sentimientos utilizando algunas de las técnicas populares basadas en el léxico. Ahora haz rápidamente una visualización y compara los resultados.
Representación visual de los resultados de TextBlob, VADER, SentiWordNet
Trazaremos el recuento de revisiones positivas, negativas y neutrales para las tres técnicas.
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(15,7))
plt.subplot(1,3,1)
plt.title("TextBlob results")
plt.pie(tb_counts.values, labels = tb_counts.index, explode = (0, 0, 0.25), autopct="%1.1f%%", shadow=False)
plt.subplot(1,3,2)
plt.title("VADER results")
plt.pie(vader_counts.values, labels = vader_counts.index, explode = (0, 0, 0.25), autopct="%1.1f%%", shadow=False)
plt.subplot(1,3,3)
plt.title("SentiWordNet results")
plt.pie(swn_counts.values, labels = swn_counts.index, explode = (0, 0, 0.25), autopct="%1.1f%%", shadow=False)
Si observamos la imagen de arriba, los resultados de TextBlob y SentiWordNet se ven un poco cercanos, mientras que los resultados de VADER muestran una gran variación.
Notas finales:
Felicitaciones 🎉 a nosotros. Al final de este artículo, hemos aprendido los distintos pasos del preprocesamiento de datos y los diferentes enfoques basados en el léxico para el análisis de sentimientos. Comparamos los resultados de TextBlob, VADER, SentiWordNet utilizando gráficos circulares.
Referencias:
Consulte el cuaderno completo de Jupyter aquí alojado en GitHub.
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.





