Este post fue difundido como parte del Blogatón de ciencia de datos
Introducción
En estadística aplicada y aprendizaje automático, Visualización de datos es una de las habilidades más importantes.
La visualización de datos proporciona un conjunto importante de herramientas para identificar una comprensión cualitativa. Esto puede ser útil cuando intentamos explorar el conjunto de datos y extraer información para conocer un conjunto de datos y puede ayudar con identificación de patrones, datos corruptos, valores atípicos, y mucho más.
Si tenemos un poco de conocimiento del dominio, las visualizaciones de datos se pueden utilizar para expresar e identificar relaciones clave en gráficos y gráficos que sean más útiles para usted y las partes interesadas que las medidas de asociación o relevancia.
En este post, discutiremos algunos de los gráficos básicos o parcelas que puede usar para comprender y visualizar mejor sus datos.
Tabla de contenido
1. ¿Qué es la visualización de datos?
2. Beneficios de una buena visualización de datos
3. Diferentes tipos de análisis para la visualización de datos
4. Técnicas de análisis univariante para la visualización de datos
- Parcela de distribución
- Diagrama de caja y bigotes
- Trama de violín
5. Técnicas de análisis bivariado para la visualización de datos
- Gráfico de línea
- Gráfico de barrasEl gráfico de barras es una representación visual de datos que utiliza barras rectangulares para mostrar comparaciones entre diferentes categorías. Cada barra representa un valor y su longitud es proporcional a este. Este tipo de gráfico es útil para visualizar y analizar tendencias, facilitando la interpretación de información cuantitativa. Es ampliamente utilizado en diversas disciplinas, como la estadística, el marketing y la investigación, debido a su simplicidad y efectividad....
- Gráfico de dispersiónUn gráfico de dispersión es una representación visual que muestra la relación entre dos variables numéricas mediante puntos en un plano cartesiano. Cada eje representa una variable, y la ubicación de cada punto indica su valor en relación con ambas. Este tipo de gráfico es útil para identificar patrones, correlaciones y tendencias en los datos, facilitando el análisis y la interpretación de relaciones cuantitativas....
¿Qué es la visualización de datos?
La visualización de datos se establece como representación grafica que contiene el información y el datos.
Usando ítems visuales como gráficos, graficas, y mapas, las técnicas de visualización de datos proporcionan una forma alcanzable de ver y comprender tendencias, valores atípicos y patrones en los datos.
Actualmente, tenemos muchos datos en nuestras manos, dicho de otra forma, en el mundo de Big Data, las herramientas y las tecnologías de visualización de datos son cruciales para analizar cantidades masivas de información y tomar decisiones sustentadas en datos.
Se utiliza en muchas áreas como:
- Modelar eventos complejos.
- Visualizar fenómenos que no se pueden observar de forma directa, como patrones meteorológicos, condiciones médicas, o relaciones matemáticas.
Beneficios de una buena visualización de datos
Dado que nuestros ojos pueden capturar los colores y patrones, por eso, podemos identificar rápidamente la parte roja del azul, el cuadrado del círculo, nuestra cultura es visual, que incluye todo, desde el arte y los anuncios hasta la televisión y las películas.
Entonces, la visualización de datos es otra técnica de arte visual que capta nuestro interés y mantiene nuestro enfoque principal en el mensaje capturado con la ayuda de los ojos.
Siempre que visualizamos un gráfico, identificamos rápidamente las tendencias y valores atípicos presentes en el conjunto de datos.
Los usos básicos de la técnica de visualización de datos son los siguientes:
- Es una técnica poderosa para explorar los datos con presentable y interpretable resultados.
- En el procedimiento de minería de datos, actúa como un paso principal en la parte de preprocesamiento.
- Es compatible con procedimiento de limpieza de datos encontrando datos incorrectos y valores dañados o faltantes.
- Además ayuda a construir y elegir variables, lo que significa que tenemos que determinar qué variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... incluir y descartar en el análisis.
- En el procedimiento de Disminución de datos, además juega un papel crucial al combinar las categorías.

Fuente de la imagen: imágenes de Google
Diferentes tipos de análisis para la visualización de datos
Principalmente, existen tres tipos diferentes de análisis para la visualización de datos:
Análisis univariado: En el análisis univariado, usaremos una sola característica para analizar casi todas sus propiedades.
Análisis bivariado: Cuando comparamos los datos entre exactamente 2 características, se conoce como análisis bivariado.
Analisis multivariable: En el análisis multivariado, voluntad estar comparando más de 2 variables.
NOTA:
En este post, nuestro principal objetivo es comprender los siguientes conceptos:
- ¿Cómo hallar algunas inferencias de las técnicas de visualización de datos?
- ¿En qué condición, qué técnica es más útil que otras?
No vamos a profundizar en la parte de codificación / implementación de diferentes técnicas en un conjunto de datos en particular, pero intentamos hallar la solución a las preguntas anteriores y comprender solo el código del fragmento con la ayuda de diagramas de muestra para cada una de las técnicas de visualización de datos. .
Ahora, comencemos con las diferentes técnicas de visualización de datos:
Técnicas de análisis univariante para la visualización de datos
1. Parcela de distribución
- Es uno de los mejores gráficos univariados para conocer la distribución de datos.
- Cuando queremos analizar el impacto en la variable objetivo (salida) con respecto a una variable independiente (entrada), usamos mucho las gráficas de distribución.
- Esta gráfica nos da una combinación de funciones de densidad de probabilidad (pdf) e histograma en una sola gráfica.
Implementación:
- La gráfica de distribución está presente en el Seaborn paquete.
El fragmento de código es el siguiente:
sns.FacetGrid(hb,hue="SurvStat",size=5).map(sns.distplot,'age').add_legend()
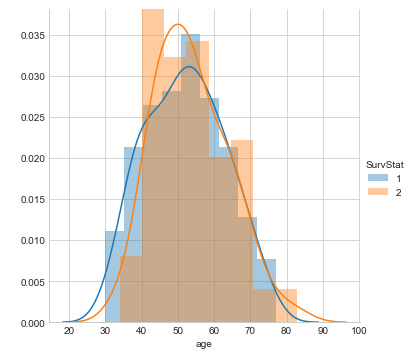
Algunas conclusiones inferidas del diagrama de distribución anterior:
De la gráfica de distribución anterior podemos concluir las siguientes observaciones:
- Hemos observado que creamos una gráfica de distribución en la característica ‘La edad’(variable de entrada) y usamos diferentes colores para la Estado de supervivencia(variable de salida) puesto que es la clase a predecir.
- Existe una gran área de superposición entre los PDF para diferentes combinaciones.
- En este gráfico, las estructuras afiladas en forma de bloque se denominan histogramasLos histogramas son representaciones gráficas que muestran la distribución de un conjunto de datos. Se construyen dividiendo el rango de valores en intervalos, o "bins", y contando cuántos datos caen en cada intervalo. Esta visualización permite identificar patrones, tendencias y la variabilidad de los datos de manera efectiva, facilitando el análisis estadístico y la toma de decisiones informadas en diversas disciplinas.... y la curva suavizada se conoce como función de densidad de probabilidad (PDF).
NOTA:
La función de densidad de probabilidad (PDF) de una curva puede ayudarnos a capturar la distribución subyacente de esa característica, que es una de las principales conclusiones de la visualización de datos o el análisis exploratorio de datos (EDA).
2. Diagrama de caja y bigotes
- Este gráfico se puede usar para obtener más detalles estadísticos sobre los datos.
- Las rectas en el máximo y mínimo además se denominan bigotes.
- Los puntos que se encuentran fuera de los bigotes se considerarán un valor atípico.
- El diagrama de caja además nos da una descripción de la Cuartiles 25, 50, 75.
- Con la ayuda de un diagrama de caja, además podemos determinar el Rango intercuartil (IQR) donde estarán presentes los máximos detalles de los datos. Por eso, además puede darnos una idea clara sobre los valores atípicos en el conjunto de datos.
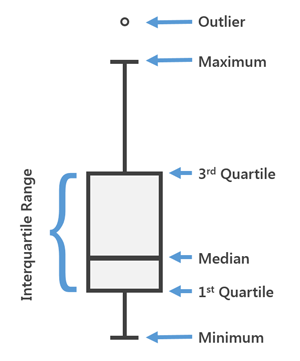
Fig. Diagrama general para un diagrama de caja
Implementación:
- Boxplot está habilitada en Seaborn Biblioteca.
- Aquí x se considera como la variable dependiente e y se considera como la variable independiente. Estos diagramas de cajaLos diagramas de caja, también conocidos como diagramas de caja y bigotes, son herramientas estadísticas que representan la distribución de un conjunto de datos. Estos diagramas muestran la mediana, los cuartiles y los valores atípicos, lo que permite visualizar la variabilidad y la simetría de los datos. Son útiles en la comparación entre diferentes grupos y en el análisis exploratorio, facilitando la identificación de tendencias y patrones en los datos.... vienen debajo análisis univariado, lo que significa que estamos explorando datos solo con una variable.
- Aquí estamos tratando de verificar el impacto de una característica llamada «Axil_nodes» en la clase nombrada «Estado de supervivencia» y no entre dos características independientes.
El fragmento de código es el siguiente:
sns.boxplot(x='SurvStat',y='axil_nodes',data=hb)
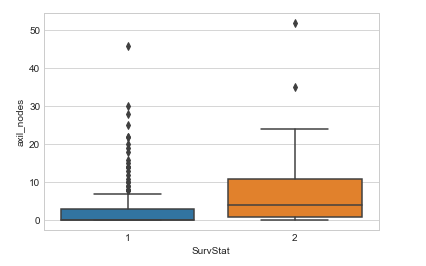
Algunas conclusiones inferidas del diagrama de caja anterior:
Del diagrama de caja y bigotes anterior podemos concluir las siguientes observaciones:
- Cuántos datos están presentes en el primer cuartil y cuántos puntos son valores atípicos, etc.
- Para la clase 1, podemos ver que hay muy pocos o ningún dato presente entre la medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... y el primer cuartil.
- Hay más valores atípicos para la clase 1 en la característica denominada axil_nodes.
NOTA:
Podemos obtener detalles sobre los valores atípicos que nos ayudarán a preparar bien los datos antes de enviarlos a un modelo, puesto que los valores atípicos influyen en muchos modelos de aprendizaje automático.
3. Trama de violín
- Las parcelas de violín se pueden considerar como una combinación de parcelas de caja en el medio y parcelas de distribución(Estimación de la densidad del grano) en ambos lados de los datos.
- Esto puede darnos la descripción de la distribución del conjunto de datos como si la distribución es multimodal, Oblicuidadetc.
- Además nos brinda información útil como Intervalo de confianza del 95%.
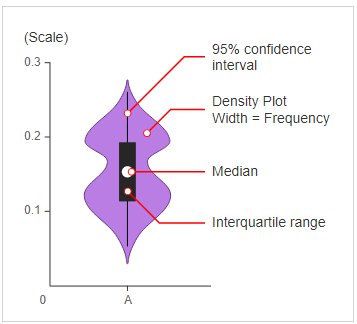
Fig. Diagrama general para una trama de violín
Implementación:
- La trama del violín está presente en el Seaborn paquete.
El fragmento de código es el siguiente:
sns.violinplot(x='SurvStat',y='op_yr',data=hb,size=6)
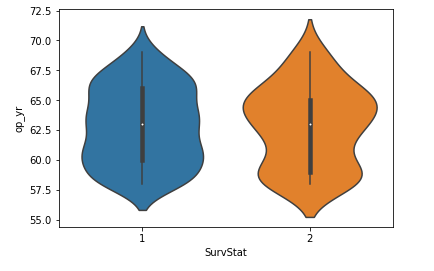
Algunas conclusiones inferidas de la trama de violín anterior:
De la trama de violín anterior podemos concluir las siguientes observaciones:
- La mediana de ambas clases se acerca a 63.
- El número máximo de personas con clase 2 tiene un op_yr valor de 65 mientras que, para las personas de la clase 1, el valor máximo es de alrededor de 60.
- Al mismo tiempo, el tercer cuartil a la mediana tiene un número menor de puntos de datos que la mediana al primer cuartil.
Técnicas de análisis bivariado para la visualización de datos
1. Gráfico de línea
- Esta es la gráfica que se puede ver en los rincones de cualquier tipo de análisis entre 2 variables.
- Los gráficos de líneas no son más que los valores de una serie de puntos de datos que se conectarán con líneas rectas.
- La trama puede parecer muy simple pero tiene más aplicaciones no solo en el aprendizaje automático sino en muchas otras áreas.
Implementación:
- La gráfica de línea está presente en el Matplotlib paquete.
El fragmento de código es el siguiente:
plt.plot(x,y)
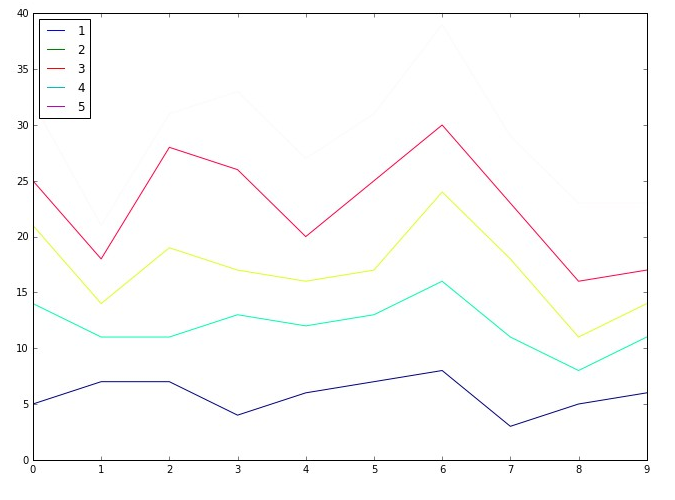
Algunas conclusiones inferidas del diagrama de líneas anterior:
Del gráfico de líneasEl gráfico de líneas es una herramienta visual utilizada para representar datos a lo largo del tiempo. Consiste en una serie de puntos conectados por líneas, lo que permite observar tendencias, fluctuaciones y patrones en los datos. Este tipo de gráfico es especialmente útil en áreas como la economía, la meteorología y la investigación científica, facilitando la comparación de diferentes conjuntos de datos y la identificación de comportamientos a lo... anterior podemos concluir las siguientes observaciones:
- Estos se usan de forma directa desde la realización de la comparación de distribución usando Parcelas QQ para sintonizar CV usando el método del codo.
- Se utiliza para analizar el rendimiento de un modelo usando el Curva ROC- AUC.
2. Gráfico de barras
- Este es uno de los gráficos más utilizados, que hubiéramos visto varias veces no solo en el análisis de datos, sino que además usamos este gráfico siempre que haya un análisis de tendencias en muchos campos.
- Aún cuando parezca simple, es poderoso para analizar datos como cifras de ventas cada semana, ingresos de un producto, Número de visitantes de un sitio cada día de la semanaetc.
Implementación:
- El gráfico de barras está presente en el Matplotlib paquete.
El fragmento de código es el siguiente:
plt.bar(x,y)
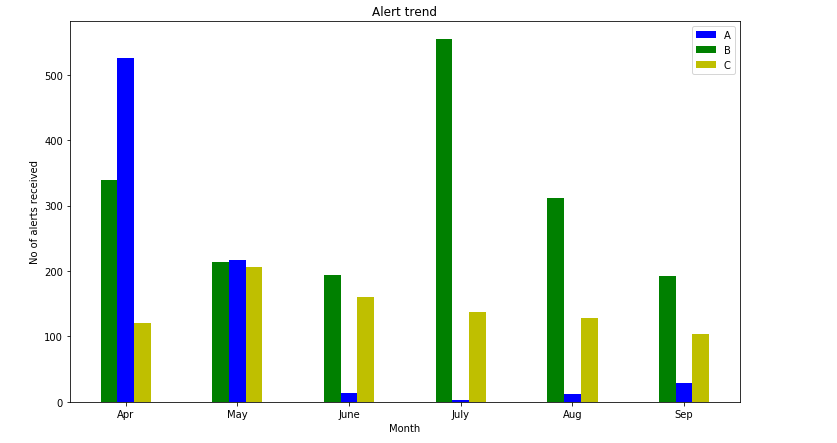
Algunas conclusiones inferidas del diagrama de barras anterior:
Del gráfico de barras anterior podemos concluir las siguientes observaciones:
- Podemos visualizar los datos en una trama genial y podemos transmitir los detalles de forma directa a los demás.
- Esta gráfica puede ser simple y clara, pero no se utiliza con mucha frecuencia en aplicaciones de ciencia de datos.
3. Diagrama de dispersiónEl diagrama de dispersión es una herramienta gráfica utilizada en estadística para visualizar la relación entre dos variables. Consiste en un conjunto de puntos en un plano cartesiano, donde cada punto representa un par de valores correspondientes a las variables analizadas. Este tipo de gráfico permite identificar patrones, tendencias y posibles correlaciones, facilitando la interpretación de datos y la toma de decisiones basadas en la información visual presentada....
- Es uno de los gráficos más utilizados para visualizar datos simples en el aprendizaje automático y la ciencia de datos.
- Esta gráfica nos describe como una representación, donde cada punto en el conjunto de datos completo está presente con respecto a 2 o 3 características (columnas).
- Los diagramas de dispersión están disponibles tanto en 2-D como en 3-D. El gráfico de dispersión 2-D es el más común, donde principalmente trataremos de hallar los patrones, grupos y separabilidad de los datos.
Implementación:
- El diagrama de dispersión está presente en el Matplotlib paquete.
El fragmento de código es el siguiente:
plt.scatter(x,y)
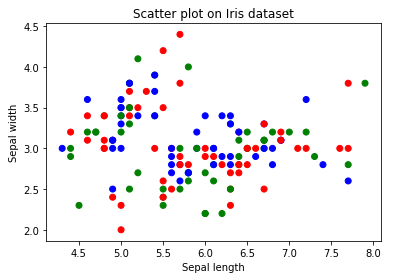
Algunas conclusiones inferidas del diagrama de dispersión anterior:
Del diagrama de dispersión anterior podemos concluir las siguientes observaciones:
- Los colores se asignan a diferentes puntos de datos en función de cómo estaban presentes en el conjunto de datos. dicho de otra forma, representación de la columna de destino.
- Podemos colorear los puntos de datos según su etiqueta de clase dada en el conjunto de datos.
¡Esto completa la discusión de hoy!
Notas finales
¡Gracias por leer!
Espero que haya disfrutado del post y haya aumentado sus conocimientos sobre las técnicas de visualización de datos.
Por favor no dude en ponerse en contacto conmigo sobre Correo electrónico
¿Algo no mencionado o deseas compartir tus pensamientos? No dude en comentar a continuación y me pondré en contacto con usted.
Para los posts restantes, consulte el Link.
Sobre el Autor
Aashi Goyal
En este momento, estoy cursando mi Licenciatura en Tecnología (B.Tech) en Ingeniería Electrónica y de Comunicación de Universidad Guru Jambheshwar (GJU), Hisar. Estoy muy entusiasmado con la estadística, el aprendizaje automático y el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud....
Tus sugerencias y dudas son bienvenidas aquí en la sección de comentarios. ¡Gracias por leer mi post!





