Este artículo fue publicado como parte del Blogatón de ciencia de datos
Preprocesamiento de datos
También es un paso importante en la minería de datos, ya que no podemos trabajar con datos sin procesar. Se debe verificar la calidad de los datos antes de aplicar algoritmos de aprendizaje automático o minería de datos.
¿Por qué es importante el preprocesamiento de datos?
El procesamiento previo de datos es principalmente para verificar la calidad de los datos. La calidad puede comprobarse mediante los siguientes
- Precisión: Para comprobar si los datos introducidos son correctos o no.
- Lo completo: Para comprobar si los datos están disponibles o no registrados.
- Consistencia: Para comprobar si se guardan los mismos datos en todos los lugares que coinciden o no.
- Oportunidad: Los datos deben actualizarse correctamente.
- Credibilidad: Los datos deben ser confiables.
- Interpretabilidad: La comprensibilidad de los datos.
- Limpieza de datos
- Integración de datos
- Reducción de datos
- Transformación de datos
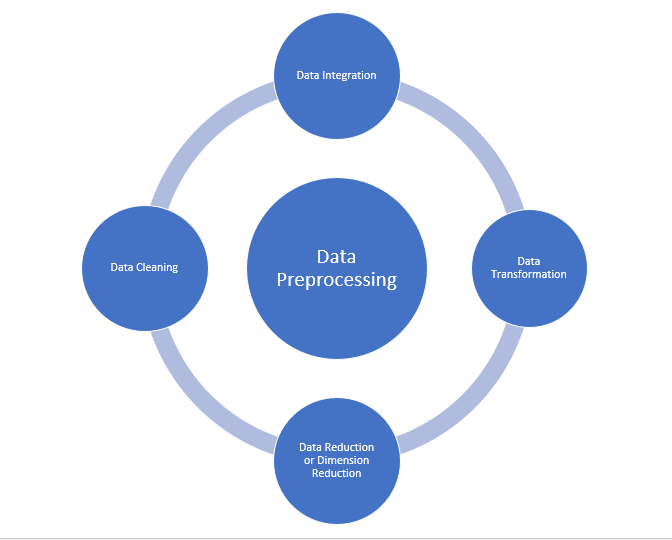
Fuente: medium.com
Limpieza de datos:
La limpieza de datos es el proceso para eliminar datos incorrectos, datos incompletos y datos inexactos de los conjuntos de datos, y también reemplaza los valores faltantes. Existen algunas técnicas de limpieza de datos
Manejo de valores perdidos:
- Se pueden usar valores estándar como «No disponible» o «NA» para reemplazar los valores faltantes.
- Los valores faltantes también se pueden completar manualmente, pero no se recomienda cuando el conjunto de datos es grande.
- El valor medio del atributo se puede utilizar para reemplazar el valor faltante cuando los datos se distribuyen normalmente.
en el que, en el caso de una distribución no normal, se puede utilizar el valor mediano del atributo. - Al usar algoritmos de árbol de decisión o regresión, el valor faltante puede ser reemplazado por el valor más probable.
valor.
Ruidoso:
Ruidoso generalmente significa error aleatorio o que contiene puntos de datos innecesarios. Estos son algunos de los métodos para manejar datos ruidosos.
- Binning: Este método sirve para suavizar o manejar datos ruidosos. Primero, los datos se clasifican y luego los valores ordenados se separan y almacenan en forma de contenedores. Hay tres métodos para suavizar los datos del contenedor. Suavizado por método bin mean: En este método, los valores del contenedor se reemplazan por el valor medio del contenedor; Suavizado por medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos.... de bin: En este método, los valores del contenedor se reemplazan por el valor mediano; Suavizado por límite de contenedor: En este método, se toman los valores de uso mínimo y máximo de los valores de ubicación y los valores se reemplazan por el valor límite más cercano.
- Regresión: Se utiliza para suavizar los datos y ayudará a manejar los datos cuando haya datos innecesarios. Para el análisis, la regresión de propósito ayuda a decidir la variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... que es adecuada para nuestro análisis.
- Agrupación: Se utiliza para encontrar los valores atípicos y también para agrupar los datos. La agrupación en clústeres se utiliza generalmente en el aprendizaje no supervisadoEl aprendizaje no supervisado es una técnica de machine learning que permite a los modelos identificar patrones y estructuras en datos sin etiquetas predefinidas. A través de algoritmos como k-means y análisis de componentes principales, este enfoque se utiliza en diversas aplicaciones, como la segmentación de clientes, la detección de anomalías y la compresión de datos. Su capacidad para revelar información oculta lo convierte en una herramienta valiosa en la....
Integración de datos:
El proceso de combinar varias fuentes en un solo conjunto de datos. El proceso de integración de datos es uno de los componentes principales en la gestión de datos. Hay algunos problemas que deben tenerse en cuenta durante la integración de datos.
- Integración de esquemas: Integra metadatos (un conjunto de datos que describe otros datos) de diferentes fuentes.
- Problema de identificación de entidad: Identificación de entidades de múltiples bases de datos. Por ejemplo, el sistema o el uso deben saber el _id de estudiante de una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... y el nombre de estudiante de otra base de datos pertenece a la misma entidad.
- Detectar y resolver conceptos de valor de datos: Los datos tomados de diferentes bases de datos durante la fusión pueden diferir. Como los valores de los atributos de una base de datos pueden diferir de otra base de datos. Por ejemplo, el formato de la fecha puede diferir como «MM / DD / AAAA» o «DD / MM / AAAA».
Reducción de datos:
Este proceso ayuda a reducir el volumen de datos, lo que facilita el análisis y produce el mismo o casi el mismo resultado. Esta reducción también ayuda a reducir el espacio de almacenamiento. Algunas de las técnicas en la reducción de datos son Reducción de dimensionalidad, Reducción de numerosidad, Compresión de datos.
- Reducción de dimensionalidad: Este proceso es necesario para las aplicaciones del mundo real, ya que el tamaño de los datos es grande. En este proceso, la reducción de atributos o variables aleatorias se realiza para que se pueda reducir la dimensionalidad del conjunto de datos. Combinar y fusionar los atributos de los datos sin perder sus características originales. Esto también ayuda a reducir el espacio de almacenamiento y el tiempo de cálculo. Cuando los datos son muy dimensionales, se produce el problema llamado «La maldición de la dimensionalidad».
- Reducción de la numerosidad: En este método, la representación de los datos se hace más pequeña al reducir el volumen. No habrá pérdida de datos en esta reducción.
- Compresión de datos: La forma comprimida de los datos se denomina compresión de datos. Esta compresión puede ser sin pérdida o con pérdida. Cuando no hay pérdida de información durante la compresión, se denomina compresión sin pérdidas. Mientras que la compresión con pérdida reduce la información, pero solo elimina la información innecesaria.
Transformación de datos:
El cambio realizado en el formato o la estructura de los datos se denomina transformación de datos. Este paso puede ser simple o complejo según los requisitos. Existen algunos métodos en la transformación de datos.
- Suavizado: Con la ayuda de algoritmos, podemos eliminar el ruido del conjunto de datos y ayuda a conocer las características importantes del conjunto de datos. Al suavizar podemos encontrar incluso un cambio simple que ayude en la predicción.
- Agregación: En este método, los datos se almacenan y se presentan en forma de resumen. El conjunto de datos que proviene de múltiples fuentes se integra con la descripción del análisis de datos. Este es un paso importante ya que la precisión de los datos depende de la cantidad y calidad de los datos. Cuando la calidad y la cantidad de datos son buenas, los resultados son más relevantes.
- Discretización: Los datos continuos aquí se dividen en intervalos. La discretización reduce el tamaño de los datos. Por ejemplo, en lugar de especificar la hora de la clase, podemos establecer un intervalo como (3 pm-5 pm, 6 pm-8 pm).
- NormalizaciónLa normalización es un proceso fundamental en diversas disciplinas, que busca establecer estándares y criterios uniformes para mejorar la calidad y la eficiencia. En contextos como la ingeniería, la educación y la administración, la normalización facilita la comparación, la interoperabilidad y la comprensión mutua. Al implementar normas, se promueve la cohesión y se optimizan recursos, lo que contribuye al desarrollo sostenible y a la mejora continua de los procesos....: Es el método de escalar los datos para que se puedan representar en un rango más pequeño. Ejemplo que va de -1.0 a 1.0.
Pasos del preprocesamiento de datos en el aprendizaje automático
Importar bibliotecas y el conjunto de datos
import pandas as pd
import numpy as np
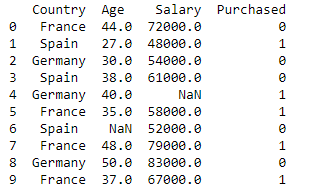
dataset = pd.read_csv('Datasets.csv')
print (data_set)
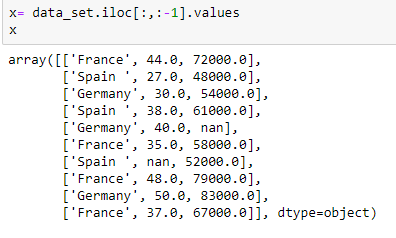
Extrayendo variable independiente:
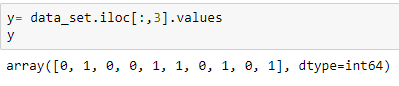
Extrayendo variable dependiente:
Llenar el conjunto de datos con el valor medio del atributo
from sklearn.preprocessing import Imputer imputer= Imputer(missing_values="NaN", strategy='mean', axis = 0) imputerimputer= imputer.fit(x[:, 1:3]) x[:, 1:3]= imputer.transform(x[:, 1:3]) x
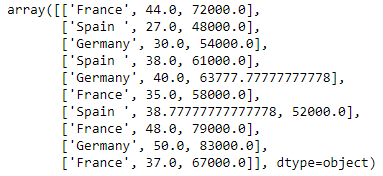
Codificación de la variable país
Los modelos de aprendizaje automático utilizan ecuaciones matemáticas. Entonces, los datos categóricos no se aceptan, por lo que los convertimos en forma numérica.
from sklearn.preprocessing import LabelEncoder label_encoder_x= LabelEncoder() x[:, 0]= label_encoder_x.fit_transform(x[:, 0])
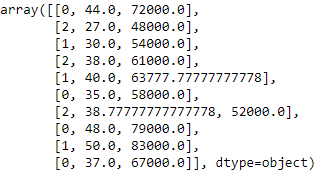
Codificación ficticia
Estas variables ficticias reemplazan los datos categóricos como 0 y 1 en ausencia o presencia de datos categóricos específicos.
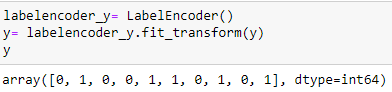
Codificación de la variable comprada
labelencoder_y= LabelEncoder() y= labelencoder_y.fit_transform(y)
Dividir el conjunto de datos en conjunto de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y prueba:
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test= train_test_split(x, y, test_size= 0.2, random_state=0)
Escala de características
from sklearn.preprocessing import StandardScaler
st_x= StandardScaler() x_train= st_x.fit_transform(x_train)

x_test= st_x.transform(x_test)
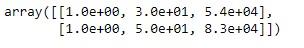
Conclusión:
En este artículo, he explicado sobre el paso más crucial en el aprendizaje automático es el preprocesamiento de datos. Espero que este artículo le ayude a comprender mejor el concepto.
Referencia:
https://www.javatpoint.com/data-preprocessing-machine-learning
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





