Este artículo fue publicado como parte del Blogatón de ciencia de datos
Visión general
- Aprenda el concepto básico de minería de datos
- Comprender las aplicaciones de la minería de datos
Prerrequisitos
- Comprensión básica de Python
- Conocimientos básicos de DataBase
¡Bienvenidos chicos!
Aquí te voy a dar una breve comprensión de los conceptos básicos de Data Mining. Sabemos que en todas partes hay datos en varios formatos que se almacenarán en una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos..... Según la escala de datos, podemos elegir una base de datos adecuada. Entonces, existen bases de datos populares que conocemos, como PostgreSQL, NoSQL, MongoDB, Microsoft SQL Server y muchas más.
En este artículo, obtendrá una idea de la minería de datos.
Así que sigamos …
¿Qué es la minería de datos?
«Procesamiento de datos», que extrae los datos. En palabras simples, se define como encontrar insights ocultos (información) de la base de datos, extraer patrones de los datos.
Existen diferentes algoritmos para diferentes tareas. La función de estos algoritmos es ajustarse al modelo. Estos algoritmos identifican las características de los datos. Hay 2 tipos de modelos.
1) Modelo predictivo
2) Modelo descriptivo
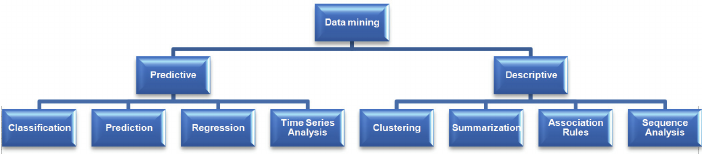
Tareas básicas de minería de datos
En esta sección, veremos algunas de las funciones / tareas de minería.
1) Clasificación
Este término viene bajo aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en.... Los algoritmos de clasificación requieren que las clases se definan en función de variables. Las características de los datos definen a qué clase pertenece. El reconocimiento de patrones es uno de los tipos de problemas de clasificación en los que la entrada (patrón) se clasifica en diferentes clases en función de su similitud de clases definidas.
2) Predicción
En la vida real, a menudo vemos predecir cosas / valores futuros / o de otra manera basados en datos pasados y datos presentes. La predicción también es un tipo de tarea de clasificación. Según el tipo de aplicación, por ejemplo, predecir inundaciones donde las variables dependientes son el nivel del agua del río, su humedad, escala de lluvia, etc. son los atributos.
3) Regresión
La regresión es una técnica estadística que se utiliza para determinar la relación entre las variables (x) y las variables dependientes (y). Existen pocos tipos de regresión como Lineal, Logística, etc. La Regresión Lineal se usa en valores continuos (0,1,1,5,… .y así sucesivamente) y la Regresión Logística se usa cuando existe la posibilidad de solo dos eventos como pasa / falla, verdadero / falso, sí / no, etc.
4) Análisis de series de tiempo
En el análisis de series de tiempo, una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... cambia su valor según el tiempo. Significa que el análisis pasa por patrones de identificación de datos durante un período de tiempo. Puede ser variación estacional, variación irregular, tendencia secular y fluctuación cíclica. Por ejemplo, lluvia anual, precio de la bolsa, etc.
5) Agrupación
La agrupación es lo mismo que la clasificación, es decir, agrupa los datos. La agrupación en clústeres se incluye en el aprendizaje automático no supervisado. Es un proceso de dividir los datos en grupos basados en tipos de datos similares.
6) Resumen
El resumen no es más que caracterización o generalización. Recupera información significativa de los datos. También ofrece un resumen de variables numéricas como media, moda, medianaLa mediana es una medida estadística que representa el valor central de un conjunto de datos ordenados. Para calcularla, se organizan los datos de menor a mayor y se identifica el número que se encuentra en el medio. Si hay un número par de observaciones, se promedia los dos valores centrales. Este indicador es especialmente útil en distribuciones asimétricas, ya que no se ve afectado por valores extremos...., etc.
7) Reglas de asociación
Es la tarea principal de Data Mining. Ayuda a encontrar patrones apropiados y conocimientos significativos de la base de datos. La regla de asociación es un modelo que extrae tipos de asociaciones de datos. Por ejemplo, Market Basket Analysis donde las reglas de asociación se aplican a la base de datos para saber qué artículos compran juntos el cliente.
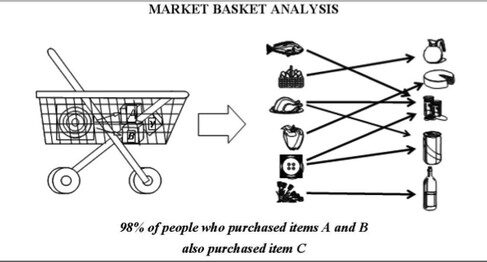
8) Descubrimiento de secuencia
También se llama análisis secuencial. Se utiliza para descubrir o encontrar el patrón secuencial en los datos.
Patrón secuencial significa el patrón que se basa puramente en una secuencia de tiempo. Estos patrones son similares a las reglas de asociación encontradas en la base de datos o los eventos están relacionados pero su relación se basa únicamente en el “Tiempo”.
Hasta este punto, hemos visto todas las funciones o tareas básicas de Data Mining. Sigamos adelante para saber más sobre la minería de datos …
Minería de datos VS KDD (descubrimiento de conocimientos en la base de datos)
Procesamiento de datos: Proceso de uso de algoritmos para extraer información significativa y patrones derivados del proceso KDD. Es un paso involucrado en KDD.
KDD: Es un proceso significativo de identificación de patrones e información significativa en los datos. La entrada que se le da a este proceso son los datos y la salida proporciona información útil a partir de los datos.
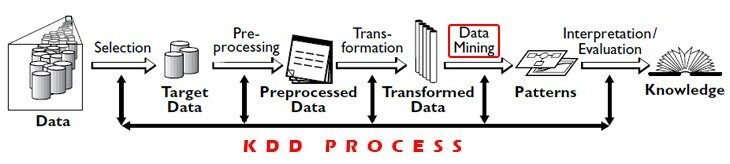
El proceso KDD consta de 5 pasos:
1) Selección: Necesidad de obtener datos de diversas fuentes de datos, bases de datos.
2) Preprocesamiento: Este proceso de limpieza de datos en términos de datos incorrectos, valores faltantes, datos erróneos.
3) Transformación: Los datos de diversas fuentes deben convertirse y codificarse en algún formato para su preprocesamiento.
4) Minería de datos: En este proceso, se aplican algoritmos a los datos transformados para lograr la salida o los resultados deseados.
5) Interpretación / evaluación: Tiene que realizar algunas visualizaciones para presentar resultados de minería de datos que son muy importantes.
Aplicaciones de minería de datos
1) Comercio electrónico
El comercio electrónico es una de sus aplicaciones en la vida real. Las empresas de comercio electrónico son como Amazon, Flipkart, Myntra, etc. Utilizan técnicas de minería de datos para ver la funcionalidad de cada producto de tal manera que “qué producto es visto más por el cliente también qué otro le gustó”.
2) Venta al por menor
Es otra aplicación de minería de datos del mercado minorista. Los minoristas encuentran el patrón de «frescura, frecuencia, monetario (en términos de moneda)». Los minoristas realizan un seguimiento de las ventas de productos y transacciones.
3) Educación
La educación es un campo emergente y de tendencia en la actualidad. Se trata del descubrimiento de conocimientos a partir de datos educativos. El objetivo principal de esta aplicación es estudiar o identificar el patrón de comportamiento del estudiante en términos de aprendizaje futuro, efectos del estudio, conocimiento avanzado del aprendizaje, etc. Estas técnicas de minería de datos son utilizadas por las instituciones para tomar decisiones precisas y también predecir resultados adecuados.
Herramientas para minería de datos
– KNIME
-WEKA
-NARANJA
Algoritmos de minería de datos
- Agrupación de K-medias
- Máquinas de vectores de soporte
- A priori
- KNN
- Bayes ingenuo
- CART y muchos más …
Estos son algunos algoritmos.
* Ahora le voy a dar información sobre las bibliotecas requeridas a continuación.
– A priori:
from apyori import apriori
– Agrupación de K-medias:
from kneed import KneeLocator
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.preprocessing import StandardScaler– Máquinas de vectores de soporte:
from sklearn import svm
-Naive Bayes:
from sklearn.naive_bayes import GaussianNB
-CARRO:
from sklearn.tree import DecisionTreeRegressor
-KNN:
fromsklearn.neighborsimportKNeighborsClassifier
Así que aquí hay algunas bibliotecas que deben instalarse mientras se realiza el algoritmo.
Conclusión
Espero les haya gustado mi artículo. Si tiene alguna consulta, puede dejar comentarios a continuación. ¡Gracias!
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





