Introducción
Soy un gran admirador de R, no es ningún secreto. He confiado en él desde que aprendí estadística en la universidad. De hecho, R sigue siendo mi lenguaje preferido para proyectos de aprendizaje automático.
Tres cosas me atrajeron principalmente a R:
- La sintaxis fácil de entender y usar
- La increíble herramienta RStudio
- Paquetes R!
R ofrece una gran cantidad de paquetes para realizar tareas de aprendizaje automático, que incluyen ‘dplyr’ para la manipulación de datos, ‘ggplot2’ para la visualización de datos, ‘caret’ para la construcción de modelos ML, etc.

Incluso hay paquetes R para funciones específicas, que incluyen puntuación de riesgo crediticio, extracción de datos de sitios web, econometría, etc. Hay una razón por la que R es querido entre los estadísticos de todo el mundo: la gran cantidad de paquetes R disponibles hace la vida mucho más fácil.
En este artículo, mostraré ocho paquetes R que han pasado desapercibidos entre los científicos de datos, pero que son increíblemente útiles para realizar tareas específicas de aprendizaje automático. Para empezar, he incluido un ejemplo junto con el código de cada paquete.
Créame, ¡su amor por R está a punto de sufrir otra revolución!
Los paquetes R que cubriremos en este artículo
He dividido ampliamente estos paquetes R en tres categorías:
- Visualización de datos
- Aprendizaje automático
- Otros paquetes R varios
- Bono: ¡Más paquetes R!
Visualización de datos

R es una herramienta increíble para visualizar datos. ¿La facilidad con la que podemos generar todo tipo de gráficos con solo una o dos líneas de código? Verdaderamente un ahorro de tiempo.
R proporciona aparentemente innumerables formas de visualizar sus datos. Incluso cuando estoy usando Python para una determinada tarea, vuelvo a R para explorar y visualizar mis datos. ¡Estoy seguro de que la mayoría de los usuarios de R sienten lo mismo!
Veamos algunos paquetes R increíbles pero menos conocidos para realizar análisis de datos exploratorios.
Este es mi paquete de referencia para realizar análisis de datos exploratorios. Desde trazar la estructura de los datos hasta gráficos QQ e incluso crear informes para su conjunto de datos, este paquete lo hace todo.
Veamos qué puede hacer DataExplorer con un ejemplo. Considere que hemos almacenado nuestros datos en el datos variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos..... Ahora, queremos averiguar el porcentaje de valores perdidos en cada característica presente. Esto es extremadamente útil cuando trabajamos con conjuntos de datos masivos y calcular la suma de los valores faltantes puede llevar mucho tiempo.
Puede instalar DataExplorer usando el siguiente código:
install.packages("DataExplorer")
Ahora veamos qué puede hacer DataExplorer por nosotros:
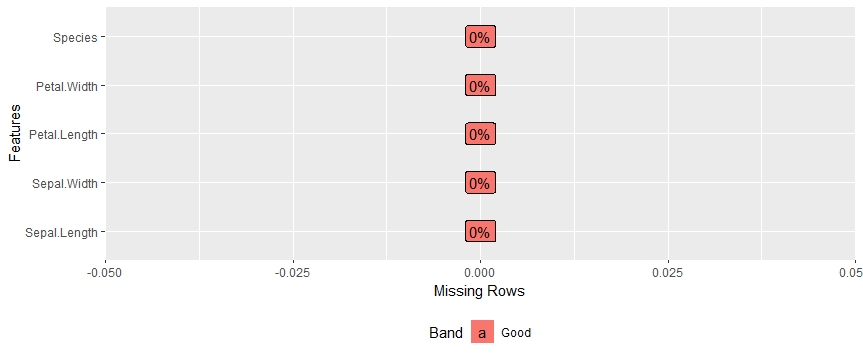
library(DataExplorer) data(iris) plot_missing(iris)
Obtenemos una gráfica realmente intuitiva para los valores perdidos:
Uno de mis aspectos favoritos de DataExplorer es el informe completo que podemos generar usando solo una línea de código:
create_report(iris)
A continuación se muestran los diferentes tipos de factores que obtenemos en este informe:

Puede acceder al informe completo a través de este enlace. Un paquete MUY útil.
¿Qué tal un complemento de ‘arrastrar y soltar’ para generar gráficos en R? Eso es correcto – esquivar es un paquete que le permite seguir creando gráficos sin tener que codificarlos.
![]()
Esquisse se basa en el paquete ggplot2. Eso significa que puede explorar sus datos de forma interactiva en el entorno de esquisse generando gráficos ggplot2.
Utilice el siguiente código para instalar y cargar esquivar en su máquina:
# From CRAN
install.packages("esquisse")
#Load the package in R
library(esquisse)
esquisse::esquisser() #helps in launching the add-inTambién puede iniciar el complemento esquisse a través del menú RStudio. La interfaz de usuario de esquisse se ve así:
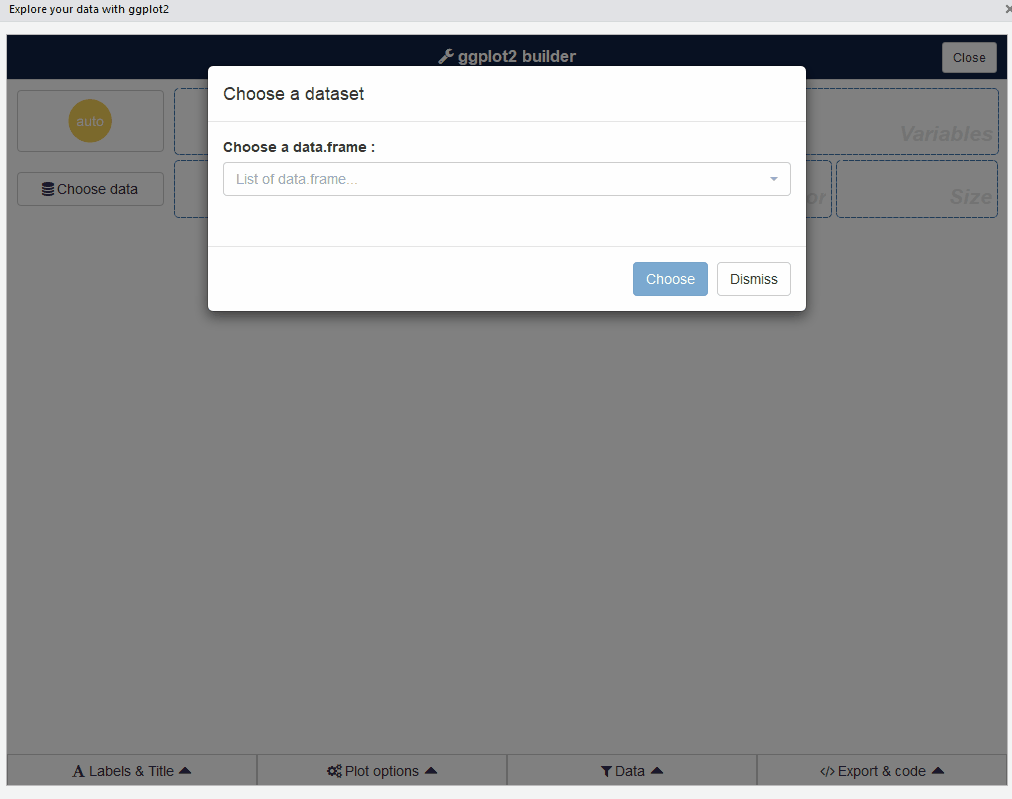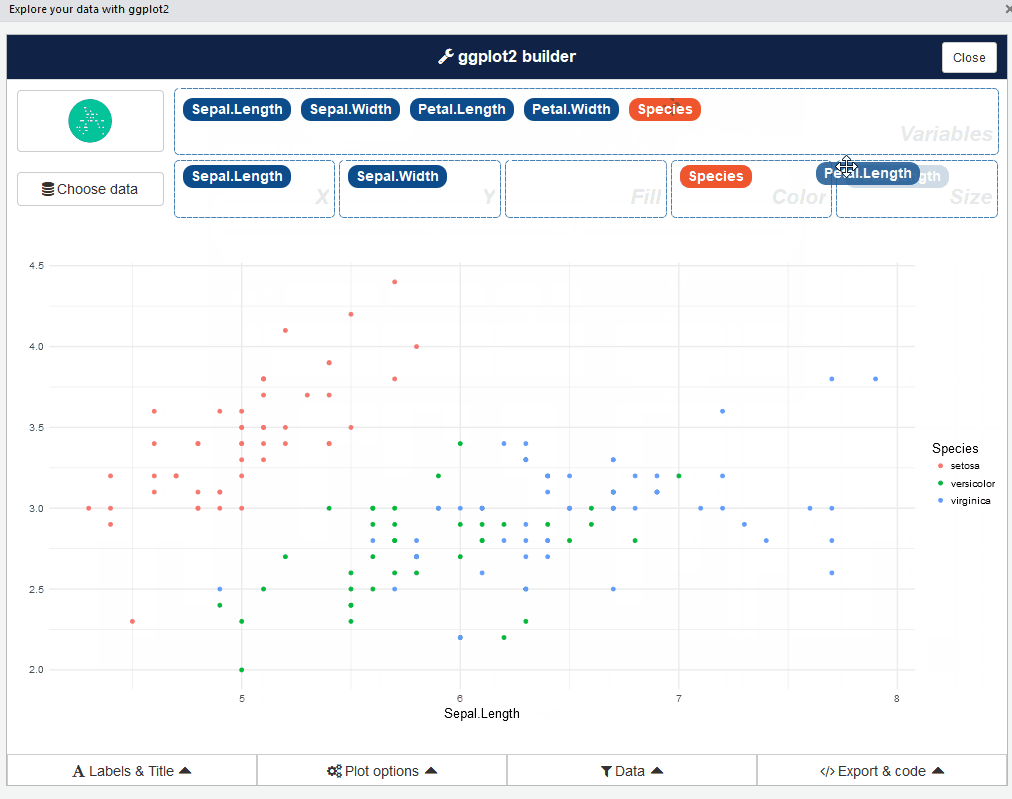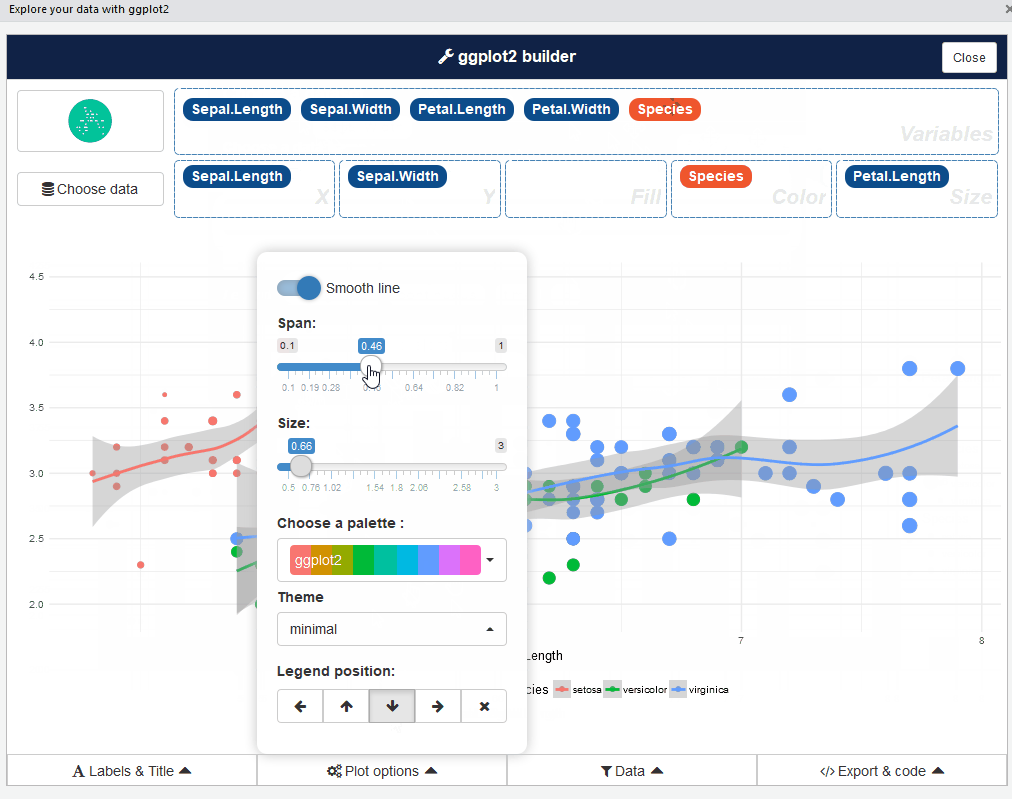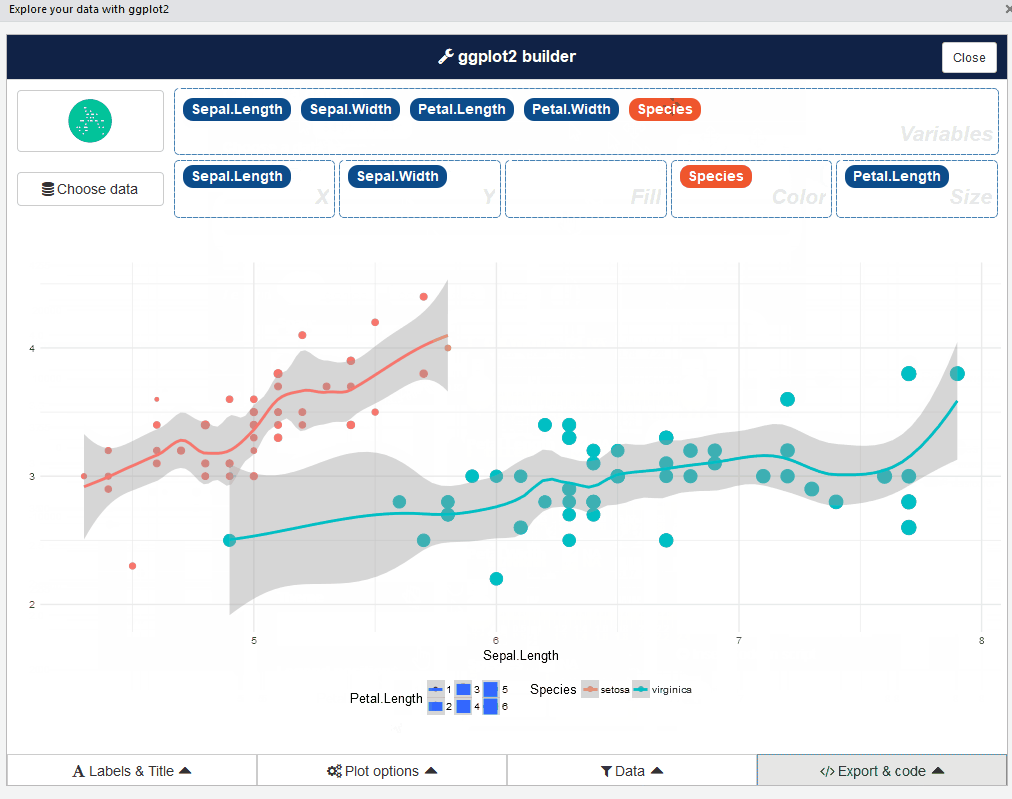
Bastante bien, ¿verdad? Continúe y juegue con diferentes tipos de tramas: es una experiencia reveladora.
Aprendizaje automático

Ah, construir modelos de aprendizaje automático en R. El santo grial por el que nos esforzamos los científicos de datos cuando emprendemos nuevos proyectos de aprendizaje automático. Es posible que haya utilizado el paquete ‘caret’ para construir modelos antes.
Ahora, permítame presentarle algunos paquetes de R que pueden cambiar la forma en que aborda el proceso de construcción de modelos.
Una de las principales razones por las que Python se adelantó a R fue gracias a sus bibliotecas centradas en el aprendizaje automático (como scikit-learn). Durante mucho tiempo, R careció de esta habilidad. Seguro que podría usar diferentes paquetes para realizar diferentes tareas de AA, pero no había un solo paquete que pudiera hacerlo todo. Tuvimos que llamar a tres bibliotecas diferentes para construir tres modelos diferentes.
No es ideal.
Y luego llegó el paquete MLR. Es un paquete increíble que nos permite realizar todo tipo de tareas de aprendizaje automático. MLR incluye todos los algoritmos populares de aprendizaje automático que usamos en nuestros proyectos.
![]()
Recomiendo encarecidamente leer el siguiente artículo para profundizar en MLR:
Veamos cómo instalar MLR y construir un modelo de bosque aleatorio en el conjunto de datos de iris:
install.packages("mlr")
library(mlr)
# Load the dataset
data(iris)
# create task
task = makeClassifTask(id = ”iris”, iris, target = ”Species”)
# create learner
learner = makeLearner(”classif.randomForest”)
# build model and evaluate
holdout(learner, task)
# measure accuracy
holdout(learner, task, measures = acc)
Producción:
Resample Result Task: iris Learner: classif.randomForest Aggr perf: acc.test.mean=0.9200000 # 92% accuracy - not bad! Runtime: 0.0239332
Un problema común con las diferentes funciones disponibles en R (que hacen lo mismo) es que pueden tener diferentes interfaces y argumentos. Tomemos el algoritmo de bosque aleatorio, por ejemplo. El código que usaría en el bosque aleatorio paquete y el signo de intercalación el paquete es diferente, ¿verdad?
Como MLR, chirivía elimina el problema de hacer referencia a varios paquetes para un determinado algoritmo de aprendizaje automático. Imita con éxito el paquete scikit-learn de Python en R.
Veamos el siguiente ejemplo simple para darle una idea de cómo chirivía funciona para un problema de regresión lineal:
install.packages("parsnip")
library(parsnip)
#Load the dataset
data(mtcars)
#Build a linear regression model
fit <- linear_reg("regression") %>%
set_engine("lm") %>%
fit(mpg~.,data=mtcars)
fit #extracts the coefficient values
Producción:
parsnip model object
Call:
stats::lm(formula = formula, data = data)
Coefficients:
(Intercept) cyl disp hp drat wt qsec
12.30337 -0.11144 0.01334 -0.02148 0.78711 -3.71530 0.82104
vs am gear carb
0.31776 2.52023 0.65541 -0.19942
Ranger es uno de mis paquetes R favoritos. Utilizo regularmente bosques aleatorios para crear modelos de línea de base, especialmente cuando participo en hackatones de ciencia de datos.
Aquí hay una pregunta: ¿cuántas veces ha encontrado un cálculo de bosque aleatorio lento para grandes conjuntos de datos en R? Sucede con demasiada frecuencia en mi vieja máquina.
Los paquetes como el símbolo de intercalación, los bosques aleatorios y rf requieren mucho tiempo para calcular los resultados. El paquete ‘Ranger’ acelera nuestro proceso de construcción de modelos para el algoritmo de bosque aleatorio. Le ayuda a crear rápidamente una gran cantidad de árboles en menos tiempo.
Codifiquemos un modelo de bosque aleatorio usando Ranger:
install.packages("ranger")
#Load the Ranger package
require(ranger)
ranger(Species ~ ., data = iris,num.trees=100,mtry=3)
train.idx <- sample(nrow(iris), 2/3 * nrow(iris))
iris.train <- iris[train.idx, ]
iris.test <- iris[-train.idx, ]
rg.iris <- ranger(Species ~ ., data = iris.train)
pred.iris <- predict(rg.iris, data = iris.test)
#Build a confusion matrix
table(iris.test$Species, pred.iris$predictions)
Producción:
setosa versicolor virginica setosa 16 0 0 versicolor 0 16 2 virginica 0 0 16
Una actuación bastante impresionante. Debería probar Ranger en conjuntos de datos más complejos y ver cuánto más rápidos se vuelven sus cálculos.
¿Agotado mientras ejecuta su modelo de regresión lineal en diferentes partes de datos y calcula las métricas de evaluación para cada modelo? los ronroneo paquete viene a su rescate.
También puede crear modelos lineales generalizados (glm) para diferentes piezas de datos y calcular valores p para cada característica en forma de lista. Las ventajas de ronroneo son infinitas!
Veamos un ejemplo para entender su funcionalidad. Construiremos un modelo de regresión lineal aquí y subconjuntaremos los valores de R-cuadrado:
#First, read in the data mtcars
data(mtcars)
mtcars %>%
split(.$cyl) %>% #selecting cylinder to create three sets of data using the cyl values
map(~ lm(mpg ~ wt, data = .)) %>%
map(summary) %>%
map_dbl("r.squared")
Producción
4 6 8 0.5086326 0.4645102 0.4229655
Entonces, ¿observaste? Este ejemplo usa ronroneo para resolver un problema bastante realista:
- Dividir un marco de datos en pedazos
- Ajusta un modelo a cada pieza
- Calcular el resumen
- Finalmente, extrae los valores de R-cuadrado
Nos ahorra mucho tiempo, ¿verdad? En lugar de ejecutar tres modelos diferentes y tres comandos para crear un subconjunto del valor R cuadrado, solo usamos una línea de código.
Utilidades: Otros paquetes R impresionantes
Veamos algunos otros paquetes que no necesariamente caen bajo el paraguas del ‘aprendizaje automático’. Los he encontrado útiles en términos de trabajar con R en general.
El análisis de sentimientos es una de las aplicaciones más populares del aprendizaje automático. Es una realidad ineludible en el mundo digital actual. Y Twitter es un objetivo principal para extraer tweets y crear modelos para comprender y predecir el sentimiento.
Ahora, hay algunos paquetes R para extraer / raspar Tweets y realizar análisis de opiniones. El paquete ‘rtweet’ hace lo mismo. Entonces, ¿en qué se diferencia de los otros paquetes que existen?
![]()
‘rtweet’ también le ayuda a comprobar las tendencias de los tweets de la propia R. ¡Impresionante!
# install rtweet from CRAN install.packages("rtweet") # load rtweet package library(rtweet)
Todos los usuarios deben estar autorizados para interactuar con la API de Twitter. Para obtener la autorización, siga las instrucciones a continuación:
1.Haz una aplicación de Twitter
2. Crea y guarda tu token de acceso
Para obtener un procedimiento detallado paso a paso para obtener la autenticación de Twitter, siga este enlace aquí.
Puede buscar tweets con ciertos hashtags simplemente por la línea de código que se menciona a continuación. Intentemos buscar todos los tweets con el hashtag #avengers ya que Infinity War está listo para su lanzamiento.
#1000 tweets with hashtag avengers tweets <- search_tweets( "#avengers", n = 1000, include_rts = FALSE)
Incluso puede acceder a los ID de usuario de las personas que siguen una determinada página. Veamos un ejemplo:
## get user IDs of accounts following marvel marvel_flw <- get_followers("marvel", n = 20000)
Puede hacer mucho más con este paquete. Pruébelo y no olvide actualizar la comunidad si encuentra algo emocionante.
¿Te encanta codificar en R y Python, pero quieres seguir con RStudio? ¡Reticular es la respuesta! El paquete resuelve este problema importante al proporcionar una interfaz Python en R. ¡Puede usar fácilmente las principales bibliotecas de Python como numpy, pandas y matplotlib dentro de R!
También puede transferir su progreso con datos fácilmente de Python a R y de R a Python con solo una línea de código. ¿No es asombroso? Consulte el bloque de código a continuación para ver lo fácil que es ejecutar Python en R.
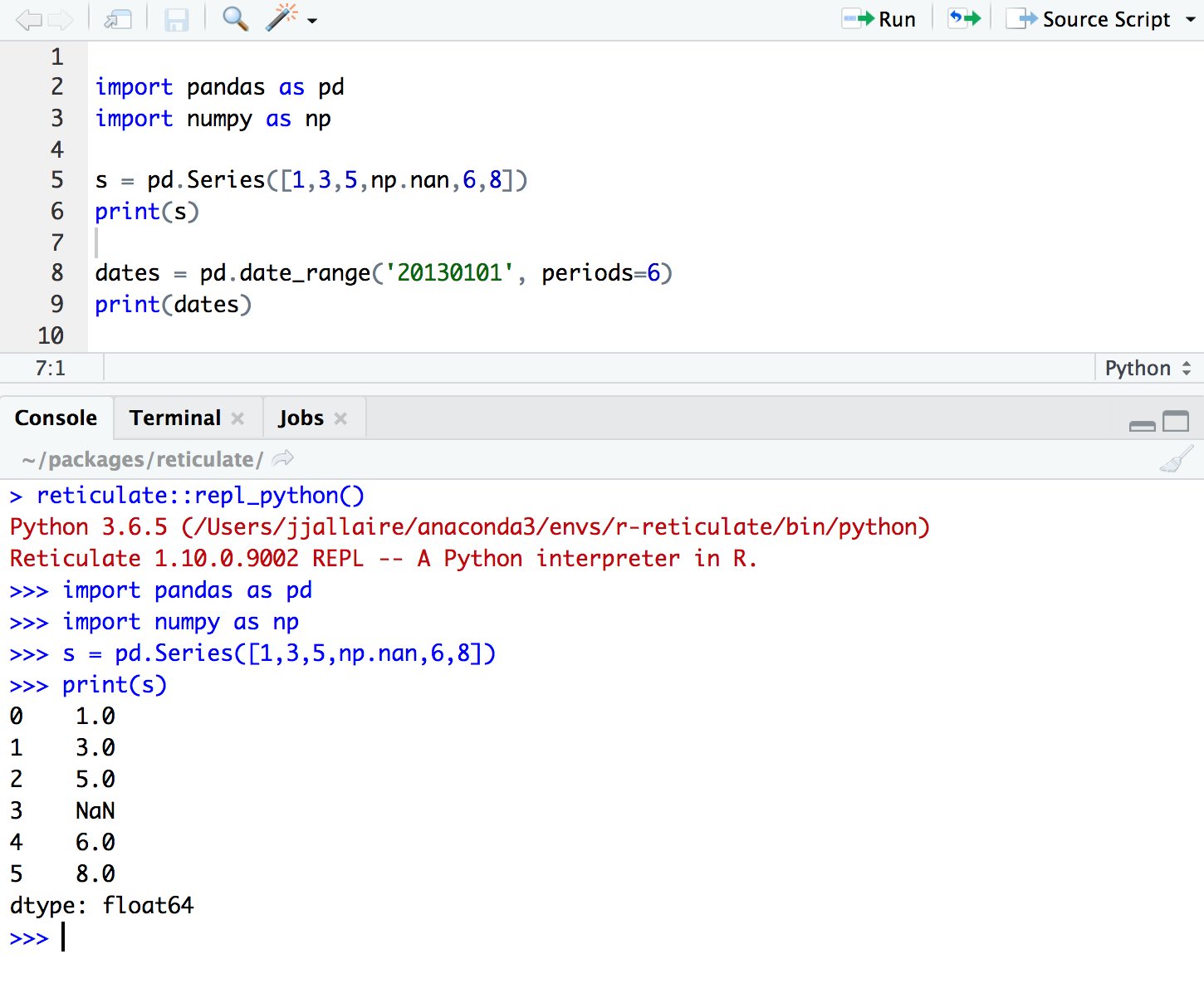
Antes de continuar con la instalación directa de reticulate en R, primero deberá instalar TensorFlow y Keras.
install.packages("tensorflow")
install.packages("keras")
library(tensorflow)
library(keras)
install_keras()
install.packages("reticulate")
library(reticulate)
¡Y estás listo para irte! Ejecute los comandos que proporcioné anteriormente en la captura de pantalla y pruebe sus proyectos de ciencia de datos de manera similar.
PRIMA
¡Aquí hay otros dos paquetes de utilidades R para todos sus nerds de programación!
¿Actualiza sus paquetes R individualmente? Puede ser una tarea tediosa, especialmente cuando hay varios paquetes en juego.
¡El paquete ‘InstallR’ le permite actualizar R y todos sus paquetes usando un solo comando! En lugar de verificar la última versión de cada paquete, podemos usar InstallR para actualizar todos los paquetes de una vez.
# installing/loading the package:
if(!require(installr)) {
install.packages("installr"); require(installr)} #load / install+load installr
# using the package:
updateR() # this will start the updating process of your R installation.
# It will check for newer versions, and if one is available, will guide you through the decisions you'd need to make
¿Qué paquete usas para instalar bibliotecas desde GitHub? La mayoría de nosotros confiamos en el paquete ‘devtools’ durante mucho tiempo. Parecía ser la única forma. Pero había una advertencia: necesitábamos recordar el nombre del desarrollador para instalar un paquete:
Con el paquete ‘githubinstall’, el nombre del desarrollador ya no es necesario.
install.packages("githubinstall")
#Install any GitHub package by supplying the name
githubinstall("PackageName")
#githubinstall("AnomalyDetection")
Notas finales
Esta no es de ninguna manera una lista exhaustiva. Hay muchos otros paquetes de R que tienen funciones útiles, pero la mayoría los ha pasado por alto.
¿Conoce algún paquete que me haya perdido en este artículo? ¿O ha utilizado alguno de los mencionados anteriormente para su proyecto? ¡Me encantaría saber de ti! ¡Conéctese conmigo en la sección de comentarios a continuación y hablemos de R!





