Este artículo fue publicado como parte del Blogatón de ciencia de datos.
Introducción
La inteligencia artificial se ha mejorado enormemente sin necesidad de cambiar la infraestructura de hardware subyacente. Los usuarios pueden ejecutar un programa de inteligencia artificial en un sistema informático antiguo. Por otro lado, el efecto beneficiario del aprendizaje automático es ilimitado. El procesamiento del lenguaje natural es una de las ramas de la inteligencia artificial que brinda a las máquinas la capacidad de leer, comprender y entregar significado. La PNL ha tenido mucho éxito en la atención médica, los medios de comunicación, las finanzas y los recursos humanos.
La forma más común de datos no estructurados son los textos y los discursos. Es abundante, pero difícil, extraer información útil. De lo contrario, se necesitaría mucho tiempo para extraer la información. El texto escrito y el habla contienen información valiosa. Es porque nosotros, como seres inteligentes, usamos la escritura y el habla como la forma principal de comunicación. La PNL puede analizar estos datos por nosotros y realizar tareas como análisis de sentimientos, asistente cognitivo, filtrado de intervalo, identificación de noticias falsas y traducción de idiomas en tiempo real.
Este artículo cubrirá cómo la PNL entiende los textos o partes del discurso. Principalmente nos centraremos en palabras y análisis de secuencias. Incluye clasificación de texto, semántica vectorial e incrustación de palabras, modelo de lenguaje probabilístico, etiquetado secuencial y reorganización del habla. Veremos el análisis de sentimientos de cincuenta mil críticos de películas de IMDB. Nuestro objetivo es identificar si la revisión publicada en el sitio de IMDB por su usuario es positiva o negativa.
Lista de temas
- ¿Entiende qué es la PNL?
- ¿Para qué sirve la PNL?
- Palabras y secuencias
- Clasificación de texto
- Incrustación de semántica y Word de vectores
- Modelos probabilísticos del lenguaje
- Etiquetado de secuencia
- Analizadores
- Semántica
- Realización de análisis semántico en el proyecto de datos de revisión de películas de IMDB
La PNL se ha utilizado ampliamente en automóviles, teléfonos inteligentes, parlantes, computadoras, sitios web, etc. Traductor automático de uso de Google Translator, que es el sistema de PNL. Google Translator escribió y habló en lenguaje natural para el idioma que los usuarios desean traducir. NLP ayuda al traductor de Google a comprender la palabra en contexto, eliminar ruidos adicionales y crear CNN para comprender la voz nativa.
La PNL también es popular en los chatbots. Los chatbots son muy útiles porque reducen el trabajo humano de preguntar qué necesita el cliente. Los bots de chatbot de PNL hacen preguntas secuenciales como cuál es el problema del usuario y dónde encontrar la solución. Apple y AMAZON tienen un robusto chatbot en su sistema. Cuando el usuario hace algunas preguntas, el chatbot las convierte en frases comprensibles en el sistema interno.
Es llamada toke. Luego, el token pasa a NLP para hacerse una idea de lo que preguntan los usuarios. La PNL se utiliza en la recuperación de información (IR). IR es un programa de software que se ocupa de un gran almacenamiento, evaluación de información de documentos de texto grandes de repositorios. Recuperará solo información relevante. Por ejemplo, se utiliza en la detección de voz de Google para recortar palabras innecesarias.
Aplicación de PNL
- Traducción automática, es decir, traductor de Google
- Recuperación de información
- Respuesta a preguntas, es decir, ChatBot
- Resumen
- Análisis de los sentimientos
- Análisis de redes sociales
- Minería de datos grandes
Palabras y secuencias
El sistema de PNL necesita comprender correctamente el texto, los signos y la semántica. Muchos métodos ayudan al sistema de PNL a comprender el texto y los símbolos. Son clasificación de texto, semántica vectorial, incrustación de palabras, modelo de lenguaje probabilístico, etiquetado de secuencias y reorganización del habla.
-
Clasificación de texto
La aclaración del texto es el proceso de categorizar el texto en un grupo de palabras. Al usar NLP, la clasificación de texto puede analizar automáticamente el texto y luego asignar un conjunto de etiquetas o categorías predefinidas según su contexto. La PNL se utiliza para el análisis de opiniones, la detección de temas y la detección de idiomas. Hay principalmente tres enfoques de clasificación de texto:
- Sistema basado en reglas,
- Sistema de máquina
- Sistema híbrido.
En el enfoque basado en reglas, los textos se separan en un grupo organizado utilizando un conjunto de reglas lingüísticas artesanales. Esas reglas lingüísticas artesanales contienen usuarios para definir una lista de palabras que se caracterizan por grupos. Por ejemplo, palabras como Donald Trump y Boris Johnson se clasificarían en política. Personas como LeBron James y Ronaldo se clasificarían en deportes.
El clasificador basado en máquina aprende a hacer una clasificación basada en observaciones pasadas de los conjuntos de datos. Los datos del usuario están preetiquetados como tarin y datos de prueba. Recopila la estrategia de clasificación de las entradas anteriores y aprende continuamente. El clasificador basado en máquina utiliza una bolsa de una palabra para la extensión de características.
En una bolsa de palabras, un vector representa la frecuencia de palabras en un diccionario predefinido de una lista de palabras. Podemos realizar PNL utilizando los siguientes algoritmos de aprendizaje automático: Naïve Bayer, SVM y Deep Learning.
El tercer enfoque para la clasificación de textos es el enfoque híbrido. El uso del enfoque híbrido combina un enfoque basado en reglas y basado en máquinas. Uso de enfoque híbrido del sistema basado en reglas para crear una etiqueta y usar el aprendizaje automático para entrenar el sistema y crear una regla. Luego, la lista de reglas basadas en máquinas se compara con la lista de reglas basadas en reglas. Si algo no coincide en las etiquetas, los humanos mejoran la lista manualmente. Es el mejor método para implementar la clasificación de texto.
-
Semántica vectorial
Vector Semantic es otra forma de análisis de palabras y secuencias. La semántica vectorial define la semántica e interpreta el significado de las palabras para explicar características como palabras similares y palabras opuestas. La idea principal detrás de la semántica vectorial es que dos palabras son iguales si se han usado en un contexto similar. La semántica vectorial divide las palabras en un espacio vectorial multidimensional. La semántica vectorial es útil en el análisis de sentimientos.
-
Incrustación de palabras
La incrustación de palabras es otro método de análisis de palabras y secuencias. La incrustación traduce los vectores de reserva en un espacio de baja dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y... que conserva las relaciones semánticas. La incrustación de palabras es un tipo de representación de palabras que permite que las palabras con un significado similar tengan una representación similar. Hay dos tipos de incrustaciones de palabras:
Word2Vec es un método estadístico para aprender eficazmente una incrustación de palabras independientes de un corpus de texto.
Doc2Vec es similar a Doc2Vec, pero analiza un grupo de texto como páginas.
-
Modelo de lenguaje probabilístico
Otro enfoque para el análisis de palabras y secuencias es el modelo de lenguaje probabilístico. El objetivo del modelo de lenguaje probabilístico es calcular la probabilidad de una oración de una secuencia de palabras. Por ejemplo, la probabilidad de que la palabra «a» aparezca en una palabra dada «a» es 0.00013131 por ciento.
-
Etiquetado de secuencia
El etiquetado de secuencia es una tarea típica de PNL que asigna una clase o etiqueta a cada token en una secuencia de entrada determinada. Si alguien dice «pon la película de tom hanks». En secuencia, el etiquetado se [play, movie, tom hanks]. El juego determina una acción. Las películas son un ejemplo de acción. Tom Hanks busca una entidad de búsqueda. Divide la entrada en varios tokens y usa LSTM para analizarla. Hay dos formas de etiquetado de secuencias. Son etiquetado de tokens y etiquetado de tramos.
El análisis es una fase de la PNL en la que el analizador determina la estructura sintáctica de un texto analizando las palabras que lo constituyen en función de una gramática subyacente. Por ejemplo, “tom comió una manzana” se dividirá en nombre propio tom, verbo ate, determinante , sustantivo manzana. El mejor ejemplo es Amazon Alexa.
Discutimos cómo se clasifica el texto y cómo dividir la palabra y la secuencia para que el algoritmo pueda entenderlo y categorizarlo. En este proyecto, vamos a descubrir un análisis de sentimiento de cincuenta mil críticos de películas de IMDB. Nuestro objetivo es identificar si la revisión publicada en el sitio de IMDB por su usuario es positiva o negativa.
Este proyecto cubre técnicas de minería de texto como incrustación de texto, bolsas de palabras, contexto de palabras y otras cosas. También cubriremos la introducción de un clasificador de sentimientos LSTM bidireccional. También veremos cómo importar un conjunto de datos etiquetado desde TensorFlow automáticamente. Este proyecto también cubre pasos como limpieza de datos, procesamiento de texto, balance de datos mediante muestreo y entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y prueba de un modelo de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... para clasificar texto.
Analizando
El analizador determina la estructura sintáctica de un texto analizando las palabras que lo constituyen en función de una gramática subyacente. Divide las palabras del grupo en partes componentes y separa las palabras.
Para obtener más detalles sobre el análisis, consulte Este artículo.
Semántico
El texto está en el corazón de cómo nos comunicamos. ¿Lo que es realmente difícil es comprender lo que se dice en una conversación escrita o hablada? Comprender libros y artículos extensos es aún más difícil. La semántica es un proceso que busca comprender el significado lingüístico mediante la construcción de un modelo del principio que el hablante utiliza para transmitir significado. Se ha utilizado en análisis de comentarios de clientes, análisis de artículos, detección de noticias falsas, análisis semántico, etc.
Aplicación de ejemplo
Aquí está el ejemplo de código:
Importando la biblioteca necesaria
# It is defined by the kaggle/python Docker image: https://github.com/kaggle/docker-python
# For example, here's several helpful packages to load
import numpy as np # linear algebra
import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv)
# Input data files are available in the read-only "../input/" directory
# For example, running this (by clicking run or pressing Shift+Enter) will list all files under the input directory
import os
for dirname, _, filenames in os.walk('/kaggle/input'):
for filename in filenames:
print(os.path.join(dirname, filename))
# You can write up to 20GB to the current directory (/kaggle/working/) that gets preserved as output when you create a version using "Save & Run All"
# You can also write temporary files to /kaggle/temp/, but they won't be saved outside of the current session
#Importing require Libraries
import os
import matplotlib.pyplot as plt
import nltk
from tkinter import *
import seaborn as sns
import matplotlib.pyplot as plt
sns.set()
import scipy
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
from tensorflow.python import keras
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Embedding, LSTM
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.metrics import classification_report
Descargando el archivo necesario
# this cells takes time, please run once
# Split the training set into 60% and 40%, so we'll end up with 15,000 examples
# for training, 10,000 examples for validation and 25,000 examples for testing.
original_train_data, original_validation_data, original_test_data = tfds.load(
name="imdb_reviews",
split=('train[:60%]', 'train[60%:]', 'test'),
as_supervised=True)
Obtener el índice de palabras de los conjuntos de datos de Keras
#tokanizing by tensorflow
word_index = tf.keras.datasets.imdb.get_word_index(
path="imdb_word_index.json"
)
En [8]:
{k:v for (k,v) in word_index.items() if v < 20}
Fuera[8]:
{'with': 16, 'i': 10, 'as': 14, 'it': 9, 'is': 6, 'in': 8, 'but': 18, 'of': 4, 'this': 11, 'a': 3, 'for': 15, 'br': 7, 'the': 1, 'was': 13, 'and': 2, 'to': 5, 'film': 19, 'movie': 17, 'that': 12}
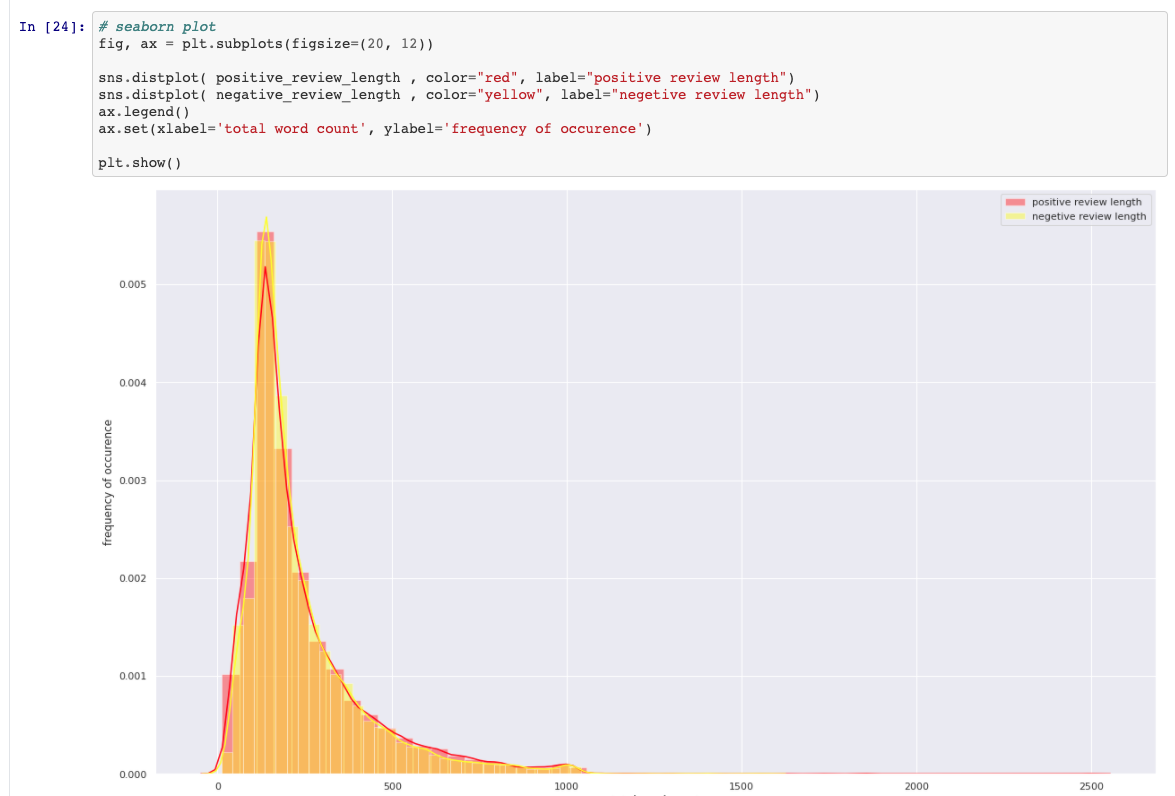
Comparación de revisión positiva y negativa
Crear tren, probar datos

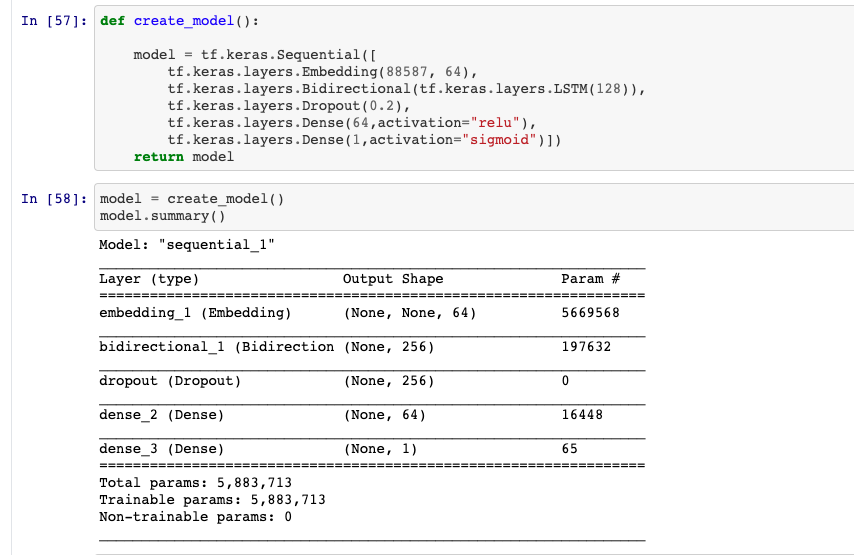
Modelo y resumen del modelo
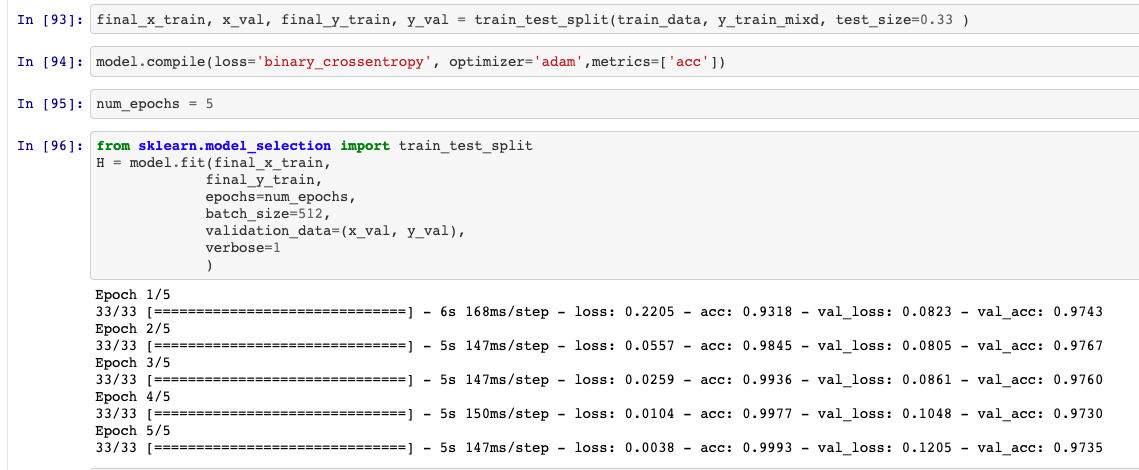
Dividir datos y ajustar el modelo
Descripción general del efecto del modelo
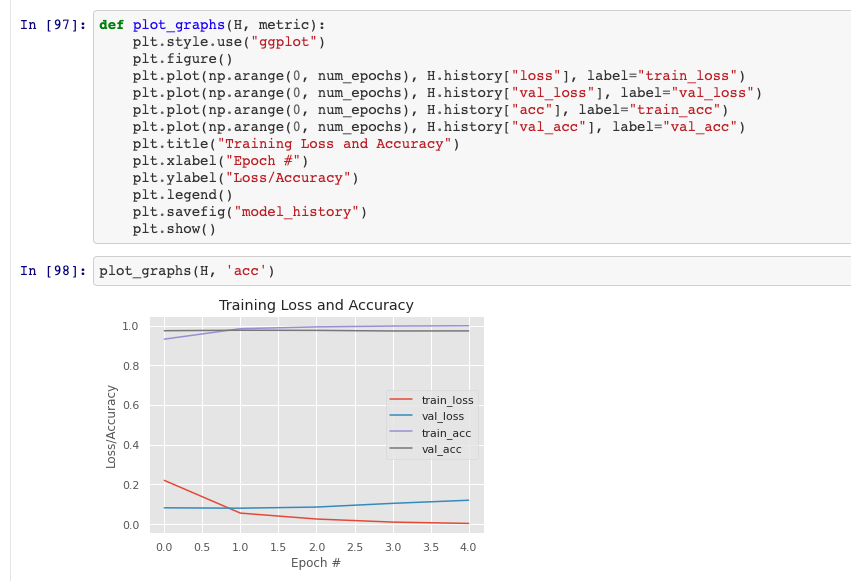
Matriz de confusión e informe de correlación
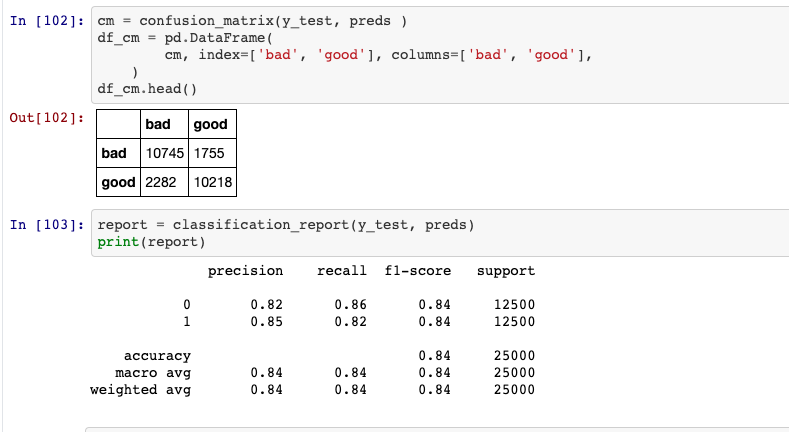
Nota: La fuente de datosUna "fuente de datos" se refiere a cualquier lugar o medio donde se puede obtener información. Estas fuentes pueden ser tanto primarias, como encuestas y experimentos, como secundarias, como bases de datos, artículos académicos o informes estadísticos. La elección adecuada de una fuente de datos es crucial para garantizar la validez y la fiabilidad de la información en investigaciones y análisis.... y los datos de este modelo están disponibles públicamente y se puede acceder a ellos mediante Tensorflow.
Para obtener el código completo y los detalles, siga este Repositorio de GitHub.
En conclusión, la PNL es un campo lleno de oportunidades. La PNL tiene un efecto tremendo sobre cómo analizar textos y discursos. La PNL está mejorando cada día más. La extracción de conocimientos del gran conjunto de datos era imposible hace cinco años. El auge de la técnica de la PNL lo hizo posible y fácil. Todavía quedan muchas oportunidades por descubrir en PNL.





