Introducción: –
El aprendizaje automático está impulsando las maravillas tecnológicas actuales, como los automóviles sin conductor, los vuelos espaciales, la imagen y el acreditación de voz. A pesar de esto, un profesional de la ciencia de datos necesitaría un gran volumen de datos para construir un modelo de aprendizaje automático robusto y confiable para tales problemas comerciales.

La minería de datos o la recopilación de datos es un paso muy primitivo en el ciclo de vida de la ciencia de datos. Según los requerimientos comerciales, es factible que tenga que recabar datos de fuentes como servidores, registros, bases de datos, API, repositorios en línea o web de SAP.
Las herramientas para raspado web como Selenium pueden raspar un gran volumen de datos, como texto e imágenes, en un tiempo relativamente corto.
Tabla de contenido: –
- ¿Qué es el web scraping?
- Por qué Web Scraping
- Cómo es útil Web Scraping
- ¿Qué es el selenio?
- Configuración y herramientas
- Implementación del desguace web de imágenes usando Selenium Python
- Navegador Chrome sin cabeza
- Poniéndolo por completo
- Notas finales
¿Qué es Web Scraping? : –
Web Scrapping, además llamado «rastreo» o «spidering» es la técnica para recabar datos automáticamente de una fuente en línea, de forma general de un portal web. Aunque el Web Scrapping es una manera fácil de obtener un gran volumen de datos en un período de tiempo relativamente corto, agrega estrés al servidor donde se aloja la fuente.
Esta es además una de las principales razones por las que muchos sitios web no posibilitan raspar todo en su portal web. A pesar de esto, siempre que no interrumpa la función principal de la fuente en línea, es bastante aceptable.
¿Por qué Web Scraping? –
Existe un gran volumen de datos en la web que las personas pueden usar para satisfacer las necesidades comerciales. Por eso, se necesita alguna herramienta o técnica para recabar esta información de la web. Y ahí es donde entra en juego el concepto de Web-Scrapping.
¿Qué utilidad tiene el Web Scraping? –
El web scraping puede ayudarnos a extraer una enorme cantidad de datos sobre clientes, productos, personas, mercados de valores, etc.
Se pueden usar los datos recopilados de un portal web, como un portal de comercio electrónico, portales de empleo, canales de redes sociales para comprender los patrones de compra de los clientes, el comportamiento de deserción de los trabajadores y los sentimientos de los clientes, y la lista continúa.
Las bibliotecas o marcos más populares que se usan en Python para Web – Scrapping son BeautifulSoup, Scrappy y Selenium.
En este post, hablaremos sobre el desguace web usando Selenium en Python. Y la cereza en la parte de arriba veremos cómo podemos recabar imágenes de la web que puede usar para crear datos de trenes para su proyecto de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud....
¿Qué es el selenio?
Selenio es una herramienta de automatización open source basada en la web. El selenio se utiliza principalmente para pruebas en la industria, pero además se puede utilizar para raspar la tela. Usaremos el navegador Chrome pero puedes probarlo en cualquier navegador, es casi lo mismo.

Ahora veamos cómo utilizar selenio para Web Scraping.
Configuración y herramientas: –
- Instalación:
- Instalar selenio usando pip
pip install selenium
- Instalar selenio usando pip
- Descargar el controlador de Chrome:
Para descargar controladores web, puede seleccionar cualquiera de los siguientes métodos:- Puede descargar de forma directa el controlador de Chrome desde el siguiente link:
https://chromedriver.chromium.org/downloads - O puede descargarlo de forma directa usando la próxima línea de código:controlador = webdriver.Chrome (ChromeDriverManager (). install ())
- Puede descargar de forma directa el controlador de Chrome desde el siguiente link:
Puede hallar documentación completa sobre el selenio aquí. La documentación se explica por sí misma, por lo tanto asegúrese de leerla para aprovechar el selenio con Python.
Los siguientes métodos nos ayudarán a hallar ítems en una página web (estos métodos devolverán una lista):
- find_elements_by_name
- find_elements_by_xpath
- find_elements_by_link_text
- find_elements_by_partial_link_text
- find_elements_by_tag_name
- find_elements_by_class_name
- find_elements_by_css_selector
Ahora, escriba un código Python para extraer imágenes de la web.
Implementación del desguace web de imágenes usando Selenium Python: –
Paso 1: – Importar bibliotecas
import os import selenium from selenium import webdriver import time from PIL import Image import io import requests from webdriver_manager.chrome import ChromeDriverManager from selenium.common.exceptions import ElementClickInterceptedException
Paso 2: – Instalar controlador
#Install Driver driver = webdriver.Chrome(ChromeDriverManager().install())
Paso 3: – Especificar la URL de búsqueda
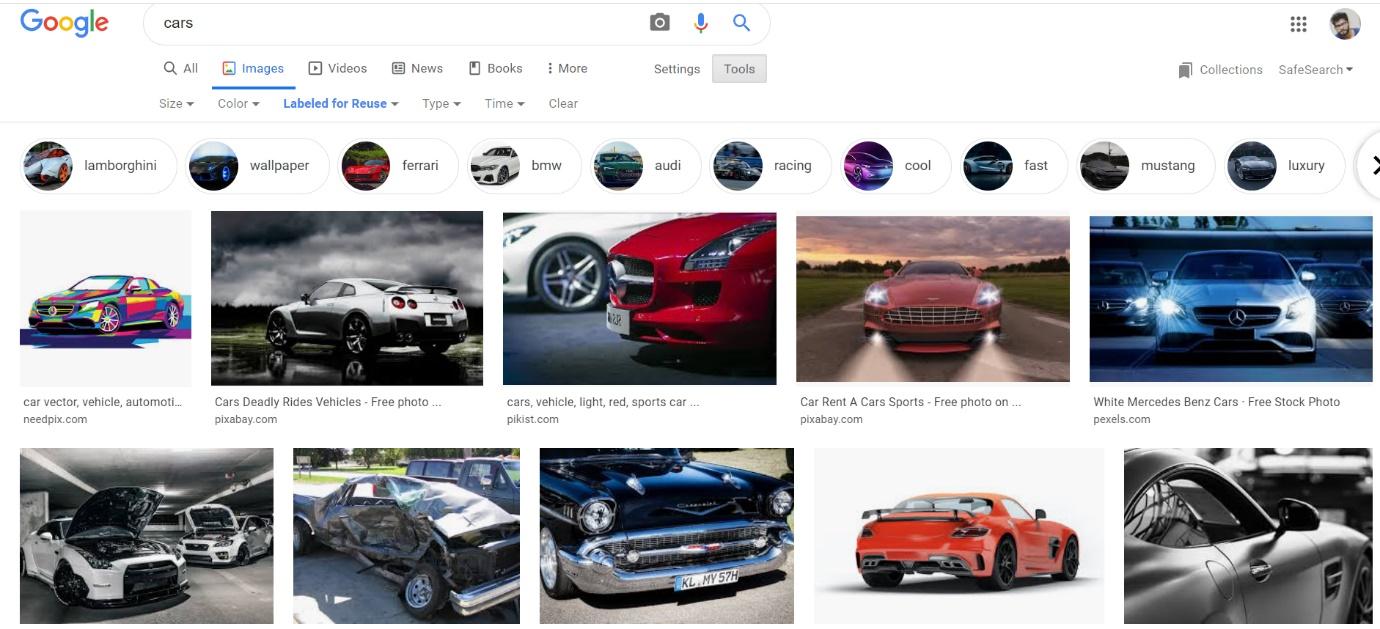
#Specify Search URL search_url=“https://www.google.com/search?q={q}&tbm=isch&tbs=sur%3Afc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568" driver.get(search_url.format(q='Car'))
He usado esta URL específica para que no se meta en problemas por utilizar imágenes con derechos de autor o con licencia. Caso contrario, puede utilizar https://google.com además como URL de búsqueda.
Después buscamos Coche en nuestra URL de búsqueda. Pegue el link en la función driver.get («Su link aquí») y ejecute la celda. Esto abrirá una nueva ventana del navegador para ese link.
Paso 4: – Desplácese hasta el final de la página.
#Scroll to the end of the page
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)#sleep_between_interactions
Esta línea de código nos ayudaría a llegar al final de la página. Y después le damos un tiempo de reposo de 5 segundos para que no tengamos problemas, donde estamos tratando de leer ítems de la página, que aún no está cargada.
Paso 5: – Localice las imágenes que se van a raspar de la página.
#Locate the images to be scraped from the current page
imgResults = driver.find_elements_by_xpath("//img[contains(@class,'Q4LuWd')]")
totalResults=len(imgResults)
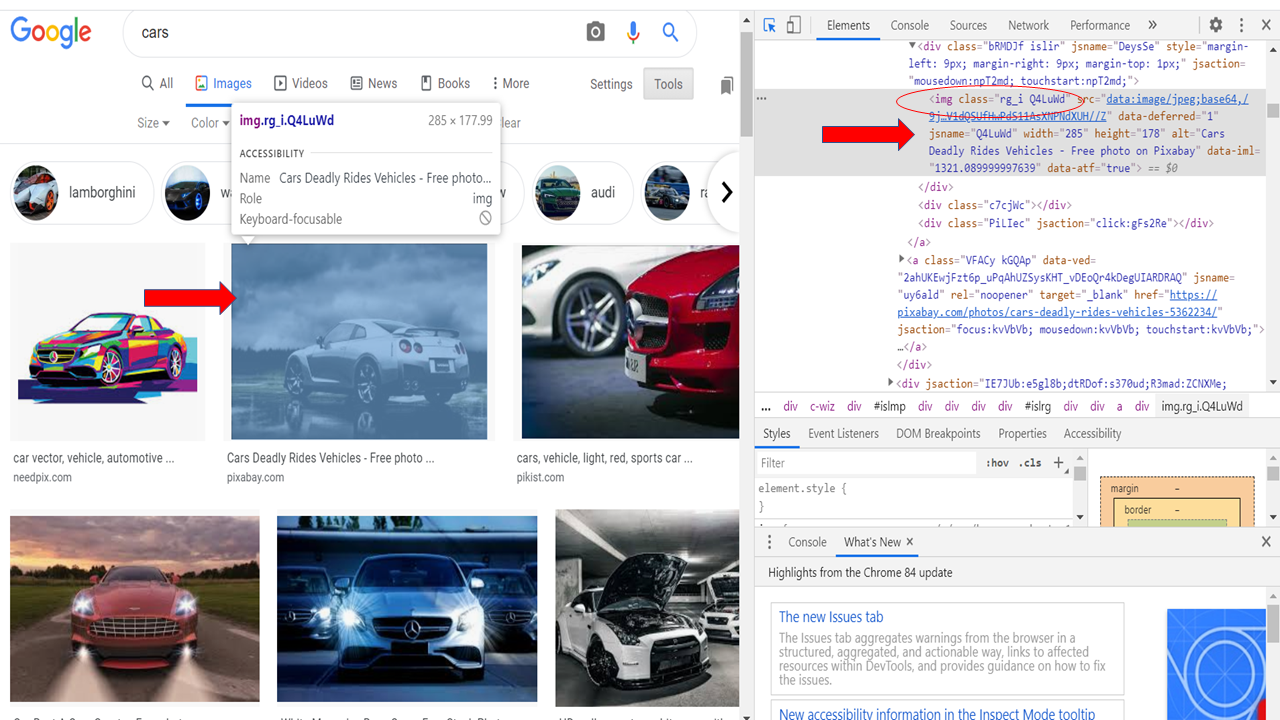
Ahora buscaremos todos los links de imágenes presentes en esa página en particular. Crearemos una «lista» para guardar esos links. Entonces, para hacer eso, vaya a la ventana del navegador, haga clic derecho en la página y seleccione ‘inspeccionar elemento’ o habilite las herramientas de desarrollo usando Ctrl + Shift + I.
Ahora identifique cualquier atributo como clase, id, etc. Lo cual es común en todas estas imágenes.
En nuestro caso, class = ”’Q4LuWd” es común en todas estas imágenes.
Paso 6: – Extrae el link respectivo de cada imagen
Como podemos, las imágenes que se muestran en la página siguen siendo las miniaturas, no la imagen original. Entonces, para descargar cada imagen, debemos hacer un clic en cada miniatura y extraer la información relevante respectivo a esa imagen.
#Click on each Image to extract its corresponding link to download
img_urls = set()
for i in range(0,len(imgResults)):
img=imgResults[i]
try:
img.click()
time.sleep(2)
actual_images = driver.find_elements_by_css_selector('img.n3VNCb')
for actual_image in actual_images:
if actual_image.get_attribute('src') and 'https' in actual_image.get_attribute('src'):
img_urls.add(actual_image.get_attribute('src'))
except ElementClickInterceptedException or ElementNotInteractableException as err:
print(err)
Entonces, en el fragmento de código anterior, estamos realizando las siguientes tareas:
- Repita cada miniatura y después haga clic en ella.
- Haz que nuestro navegador duerma durante 2 segundos (: P).
- Busque la etiqueta HTML única respectivo a esa imagen para ubicarla en la página
- Aún obtenemos más de un resultado para una imagen en particular. Pero a todos nos interesa el link para descargar esa imagen.
- Entonces, iteramos por medio de cada resultado para esa imagen y extraemos el atributo ‘src’ de la misma y después vemos si «https» está presente en el ‘src’ o no. Dado que regularmente el link web comienza con ‘https’.
Paso 7: – Descargue y guarde cada imagen en el directorio de destino
os.chdir('C:/Qurantine/Blog/WebScrapping/Dataset1')
baseDir=os.getcwd()
for i, dirección url in enumerate(img_urls):
file_name = f"{i:150}.jpg"
try:
image_content = requests.get(dirección url).content
except Exception as e:
print(f"ERROR - COULD NOT DOWNLOAD {dirección url} - {e}")
try:
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert('RGB')
file_path = os.path.join(baseDir, file_name)
with open(file_path, 'wb') as f:
image.save(f, "JPEG", quality=85)
print(f"SAVED - {dirección url} - AT: {file_path}")
except Exception as e:
print(f"ERROR - COULD NOT SAVE {dirección url} - {e}")
Ahora en resumen has extraído la imagen para tu proyecto 😀
Nota: – Una vez que haya escrito el código adecuado, el navegador no es esencial, puede recabar datos sin navegador, lo que se denomina ventana del navegador sin cabeza, por eso, reemplace el siguiente código por el anterior.
Navegador Chrome sin cabeza
#Headless chrome browser from selenium import webdriver opts = webdriver.ChromeOptions() opts.headless =True driver =webdriver.Chrome(ChromeDriverManager().install())
Para este caso, el navegador no se ejecutará en segundo plano, lo que es muy útil al poner en práctica una solución en producción.
Pongamos todo este código en una función para hacerlo más organizable e implementemos la misma idea para descargar 100 imágenes para cada categoría (a modo de ejemplo, Autos, Caballos).
Y esta vez escribiríamos nuestro código usando la idea del cromo sin cabeza.
Poniendolo todo junto:
Paso 1: importar todas las bibliotecas indispensables
import os
import selenium
from selenium import webdriver
import time
from PIL import Image
import io
import requests
from webdriver_manager.chrome import ChromeDriverManager
os.chdir('C:/Qurantine/Blog/WebScrapping')
Paso 2: instale el controlador de Chrome
#Install driver opts=webdriver.ChromeOptions() opts.headless=True driver = webdriver.Chrome(ChromeDriverManager().install() ,options=opts)
En este paso, instalamos un controlador de Chrome y usamos un navegador sin cabeza para raspar la web.
Paso 3: especifique la URL de búsqueda
search_url = "https://www.google.com/search?q={q}&tbm=isch&tbs=sur%3Afc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568" driver.get(search_url.format(q='Car'))
He utilizado esta URL específica para extraer imágenes sin derechos de autor.
Paso 4: escribe una función para llevar el cursor al final de la página
def scroll_to_end(driver):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(5)#sleep_between_interactions
Este fragmento de código se desplazará hacia abajo en la página.
Paso 5. Escribe una función para obtener la URL de cada imagen.
#no license issues def getImageUrls(name,totalImgs,driver): search_url = "https://www.google.com/search?q={q}&tbm=isch&tbs=sur%3Afc&hl=en&ved=0CAIQpwVqFwoTCKCa1c6s4-oCFQAAAAAdAAAAABAC&biw=1251&bih=568" driver.get(search_url.format(q=name)) img_urls = set() img_count = 0 results_start = 0 while(img_count<totalImgs): #Extract actual images now scroll_to_end(driver) thumbnail_results = driver.find_elements_by_xpath("//img[contains(@class,'Q4LuWd')]") totalResults=len(thumbnail_results) print(f"Found: {totalResults} search results. Extracting links from{results_start}:{totalResults}") for img in thumbnail_results[results_start:totalResults]: img.click() time.sleep(2) actual_images = driver.find_elements_by_css_selector('img.n3VNCb') for actual_image in actual_images: if actual_image.get_attribute('src') and 'https' in actual_image.get_attribute('src'): img_urls.add(actual_image.get_attribute('src')) img_count=len(img_urls) if img_count >= totalImgs: print(f"Found: {img_count} image links") break else: print("Found:", img_count, "looking for more image links ...") load_more_button = driver.find_element_by_css_selector(".mye4qd") driver.execute_script("document.querySelector('.mye4qd').click();") results_start = len(thumbnail_results) return img_urls
Esta función devolvería una lista de URL para cada categoría (a modo de ejemplo, coches, caballos, etc.)
Paso 6: escribe una función para descargar cada imagen
def downloadImages(folder_path,file_name,dirección url):
try:
image_content = requests.get(dirección url).content
except Exception as e:
print(f"ERROR - COULD NOT DOWNLOAD {dirección url} - {e}")
try:
image_file = io.BytesIO(image_content)
image = Image.open(image_file).convert('RGB')
file_path = os.path.join(folder_path, file_name)
with open(file_path, 'wb') as f:
image.save(f, "JPEG", quality=85)
print(f"SAVED - {dirección url} - AT: {file_path}")
except Exception as e:
print(f"ERROR - COULD NOT SAVE {dirección url} - {e}")
Este fragmento de código descargará la imagen de cada URL.
Paso 7: – Escriba una función para guardar cada imagen en el directorio de destino
def saveInDestFolder(searchNames,destDir,totalImgs,driver):
for name in list(searchNames):
path=os.path.join(destDir,name)
if not os.path.isdir(path):
os.mkdir(path)
print('Current Path',path)
totalLinks=getImageUrls(name,totalImgs,driver)
print('totalLinks',totalLinks)
if totalLinks is None:
print('images not found for :',name)
continue
else:
for i, link in enumerate(totalLinks):
file_name = f"{i:150}.jpg"
downloadImages(path,file_name,link)
searchNames=['Car','horses']
destDir=f'./Dataset2/'
totalImgs=5
saveInDestFolder(searchNames,destDir,totalImgs,driver)
Este fragmento de código guardará cada imagen en el directorio de destino.
Notas finales
He intentado mi parte para explicar Web Scraping usando Selenium con Python de la manera más simple factible. No dude en comentar sus consultas. Estaré más que feliz de responderles.
Puede clonar mi repositorio de Github para descargar todo el código y los datos, haga clic aquí!!
Sobre el Autor

Praveen Kumar Anwla
He trabajado como científico de datos con firmas de auditoría sustentadas en productos y Big 4 durante casi 5 años. He estado trabajando en varios marcos de PNL, aprendizaje automático y aprendizaje profundo de vanguardia para solucionar problemas comerciales. Por favor siéntete libre de revisar mi blog personal, donde cubro temas desde el aprendizaje automático: inteligencia artificial, chatbots hasta herramientas de visualización (Tableau, QlikView, etc.) y varias plataformas en la nube como Azure, IBM y la nube de AWS.





