Este artículo fue publicado como parte del Blogatón de ciencia de datos
Asuma el trabajo de un ingeniero de datos, extrayendo datos de múltiples fuentes de formatos de archivo, transformándolos en tipos de datos particulares y cargándolos en una sola fuente para su análisis. Poco después de leer este artículo, con la ayuda de varios ejemplos prácticos, podrá poner a prueba sus habilidades implementando web scraping y extrayendo datos con API. Con Python y la ingeniería de datos, podrá comenzar a recopilar enormes conjuntos de datos de muchas fuentes y transformarlos en una única fuente primaria o comenzar a rastrear la web para obtener información empresarial útil.
Sinopsis:
- ¿Por qué la ingeniería de datos es más confiable?
- Proceso del ciclo ETL
- Paso a paso Extraer, transformar, la función de carga
- Acerca de la ingeniería de datos
- Sobre mí
- Conclusión
¿Por qué la ingeniería de datos es más confiable?
Es una ocupación tecnológica más confiable y de más rápido crecimiento en la generación actual, ya que se concentra más en web scraping y rastreo de conjuntos de datos.
Proceso (ciclo ETL):
¿Se ha preguntado alguna vez cómo se integraron los datos de muchas fuentes para crear una única fuente de información? El procesamiento por lotes es una forma de recopilar datos y aprender más sobre “cómo explorar un tipo de procesamiento por lotes” llamado Extraer, Transformar y Cargar.
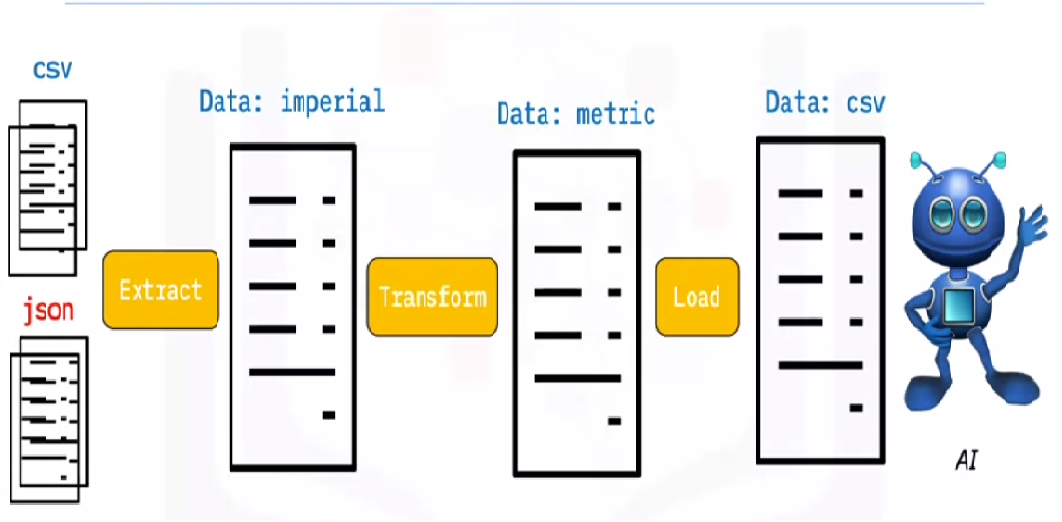
ETL es el proceso de extraer grandes volúmenes de datos de una variedad de fuentes y formatos y convertirlos a un formato único antes de colocarlos en una base de datosUna base de datos es un conjunto organizado de información que permite almacenar, gestionar y recuperar datos de manera eficiente. Utilizadas en diversas aplicaciones, desde sistemas empresariales hasta plataformas en línea, las bases de datos pueden ser relacionales o no relacionales. Su diseño adecuado es fundamental para optimizar el rendimiento y garantizar la integridad de la información, facilitando así la toma de decisiones informadas en diferentes contextos.... o en un archivo de destino.
Algunos de sus datos se almacenan en archivos CSV, mientras que otros se almacenan en archivos JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software.... Debe recopilar toda esta información en un solo archivo para que la IA la lea. Debido a que sus datos están en unidades imperiales, pero la IA necesita unidades métricas, deberá convertirlos. Debido a que la IA solo puede leer datos CSV en un solo archivo grande, primero debe cargarlo. Si los datos están en formato CSV, pongamos el siguiente ETL con python y echemos un vistazo al paso de extracción con algunos ejemplos sencillos.
Mirando la lista de archivos .json y .csv. La extensión del archivo glob está precedida por una estrella y un punto en la entrada. Se devuelve una lista de archivos .csv. Para los archivos .json, podemos hacer lo mismo. Podemos crear un archivo que extraiga nombres, alturas y pesos en formato CSV. El nombre de archivo del archivo .csv es la entrada y la salida es un marco de datos. Para los formatos JSON, podemos hacer lo mismo.
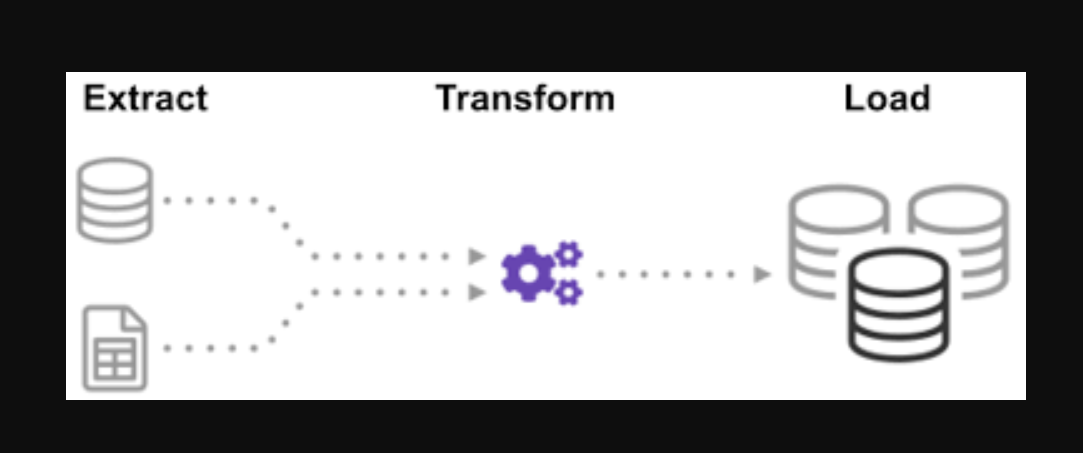
Paso 1:
Abra el cuaderno e importe las funciones y los módulos necesarios
import glob import pandas as pd import xml.etree.ElementTree as ET from datetime import datetime
Datos utilizados:
Los archivos dealership_data contienen archivos CSV, JSON y XML para datos de automóviles usados que contienen características denominadas car_model, year_of_manufacture, price, y fuel. Así que vamos a extraer el archivo de los datos sin procesar y transformarlo en un archivo de destino y cargarlo en la salida.
Descargue el archivo fuente de la nube:
!wget https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0221EN-SkillsNetwork/labs/module%206/Lab%20-%20Extract%20Transform%20Load/data/datasource.zip
Extraiga el archivo zip:
nzip datasource.zip -d dealership_data
Establezca la ruta de los archivos de destino:
tmpfile = "dealership_temp.tmp" # store all extracted data logfile = "dealership_logfile.txt" # all event logs will be stored targetfile = "dealership_transformed_data.csv" # transformed data is stored
Paso 2 (EXTRACTOEl extracto es una sustancia obtenida mediante la concentración de compuestos de origen vegetal, animal o mineral. Se utiliza en diversas aplicaciones, como la industria alimentaria, farmacéutica y cosmética. Los extractos pueden presentarse en forma líquida, en polvo o como tinturas, y su producción implica técnicas como la maceración, la destilación o la extracción con solventes. Su uso permite aprovechar las propiedades beneficiosas de los ingredientes originales de manera más...):
El extracto de función extraerá grandes cantidades de datos de múltiples fuentes en lotes. Al agregar esta función, ahora descubrirá y cargará todos los nombres de archivos CSV, y los archivos CSV se agregarán al marco de fecha con cada iteración del ciclo, con la primera iteración adjuntando primero, seguida de la segunda iteración, lo que resulta en una lista de datos extraídos. Una vez que hayamos recopilado los datos, pasaremos al paso «Transformar» del proceso.
Nota: Si el «índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... de ignorar» se establece en verdadero, el orden de cada fila será el mismo que el orden en el que se agregaron las filas al marco de datos.
Función de extracción de CSV
def extract_from_csv(file_to_process):
dataframe = pd.read_csv(file_to_process)
return dataframe
Función de extracción JSON
def extract_from_json(file_to_process):
dataframe = pd.read_json(file_to_process,lines=True)
return dataframe
Función de extracción XML
def extract_from_xml(file_to_process):
dataframe = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
tree = ET.parse(file_to_process)
root = tree.getroot()
for person in root:
car_model = person.find("car_model").text
year_of_manufacture = int(person.find("year_of_manufacture").text)
price = float(person.find("price").text)
fuel = person.find("fuel").text
dataframe = dataframe.append({"car_model":car_model, "year_of_manufacture":year_of_manufacture, "price":price, "fuel":fuel}, ignore_index=True)
return dataframe
Función de extracción ():
Ahora llame a la función de extracción usando su llamada de función para CSV, JSON, XML.
def extract():
extracted_data = pd.DataFrame(columns=['car_model','year_of_manufacture','price', 'fuel'])
#for csv files
for csvfile in glob.glob("dealership_data/*.csv"):
extracted_data = extracted_data.append(extract_from_csv(csvfile), ignore_index=True)
#for json files
for jsonfile in glob.glob("dealership_data/*.json"):
extracted_data = extracted_data.append(extract_from_json(jsonfile), ignore_index=True)
#for xml files
for xmlfile in glob.glob("dealership_data/*.xml"):
extracted_data = extracted_data.append(extract_from_xml(xmlfile), ignore_index=True)
return extracted_data
Paso 3 (Transformar):
Una vez que hayamos recopilado los datos, pasaremos a la fase «Transformar» del proceso. Esta función convertirá la altura de la columna, que está en pulgadas, a milímetros y la columna libras, que está en libras, a kilogramo, y devolverá los resultados en los datos variables. En el marco de datos de entrada, la altura de la columna está en pies. Convierta la columna para convertirla a metros y redondee a dos decimales.
def transform(data): data['price'] = round(data.price, 2) return data
Paso 4 (carga y registro):
Es hora de cargar los datos en el archivo de destino ahora que lo hemos recopilado y especificado. Guardamos el marco de datos de pandas como un CSV en este escenario. Ahora hemos pasado por los pasos de extracción, transformación y carga de datos de varias fuentes en un solo archivo de destino. Necesitamos establecer una entrada de registro antes de que podamos terminar nuestro trabajo. Lo lograremos escribiendo una función de registro.
Función de carga:
def load(targetfile,data_to_load):
data_to_load.to_csv(targetfile)
Función de registro:
Todos los datos que se escriban se agregarán a la información actual cuando se agregue la «a». Luego podemos adjuntar una marca de tiempo a cada fase del proceso, indicando cuándo comienza y cuándo termina, generando este tipo de entrada. Una vez que hayamos definido todo el código necesario para realizar el proceso ETL en los datos, el último paso es llamar a todas las funciones.
def log(message):
timestamp_format="%H:%M:%S-%h-%d-%Y"
#Hour-Minute-Second-MonthName-Day-Year
now = datetime.now() # get current timestamp
timestamp = now.strftime(timestamp_format)
with open("dealership_logfile.txt","a") as f: f.write(timestamp + ',' + message + 'n')
Paso 5 (Ejecución del proceso ETL):
Primero comenzamos llamando a la función extract_data. Los datos recibidos de este paso luego se transferirán al segundo paso de transformar los datos. Una vez completado esto, los datos se cargan en el archivo de destino. Además, tenga en cuenta que antes y después de cada paso se han agregado la hora y la fecha de inicio y finalización.
El registro de que ha iniciado el proceso ETL:
log("ETL Job Started")
El registro que ha iniciado y finalizado el paso Extraer:
log("Extract phase Started")
extracted_data = extract()
log("Extract phase Ended")
El registro que inició y finalizó el Paso de transformación:
log («Fase de transformación iniciada»)
datos_transformados = transformar (datos_extraídos)
log("Transform phase Ended")
El registro que ha iniciado y finalizado la fase de carga:
log("Load phase Started")
load(targetfile,transformed_data)
log("Load phase Ended")
El registro de finalización del ciclo ETL:
log("ETL Job Ended")
Mediante este proceso, discutimos algunas funciones básicas de extracción, transformación y carga
- Cómo escribir una función Extraer simple.
- Cómo escribir una función de transformación simple.
- Cómo escribir una función de carga simple.
- Cómo escribir una función de registro simple.
«Sin grandes datos, eres ciego y sordo y estás en medio de una autopista «. – Geoffrey Moore.
A lo sumo, hemos discutido todos los procesos ETL. Además, veamos, «¿cuáles son los beneficios del trabajo de ingeniero de datos?».
Acerca de la ingeniería de datos:
La ingeniería de datos es un campo vasto con muchos nombres. Puede que ni siquiera tenga un título formal en muchas instituciones. Como resultado, generalmente es mejor comenzar por definir los objetivos del trabajo de ingeniería de datos que conducen a los resultados esperados. Los usuarios que confían en los ingenieros de datos son tan diversos como los talentos y los resultados de los equipos de ingeniería de datos. Sus consumidores siempre definirán qué problemas maneja y cómo los resuelve, independientemente del sector al que se dedique.
Sobre mí:
Hola, mi nombre es Lavanya y soy de Chennai. Soy un escritor apasionado y entusiasta creador de contenido. Los problemas más difíciles siempre me emocionan. Actualmente estoy cursando mi B. Tech en Ingeniería Química y tengo un gran interés en los campos de la ingeniería de datos, el aprendizaje automático, la ciencia de los datos y la inteligencia artificial, y estoy constantemente buscando formas de integrar estos campos con otras disciplinas como la ciencia. y química para promover mis objetivos de investigación.
Conclusión:
Espero que haya disfrutado de mi artículo y haya adquirido una comprensión de lo que es Python en pocas palabras, lo que le proporcionará alguna orientación al comenzar su viaje para aprender ingeniería de datos. Esta es solo la punta del iceberg en términos de posibilidades. Hay muchos temas más sofisticados en ingeniería de datos, por ejemplo, para aprender. Sin embargo, antes de que podamos captar tales nociones, me extenderé en el próximo artículo. ¡Gracias!
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





