Introducción
Si tuviera que elegir una plataforma que me haya mantenido al día con los últimos desarrollos en Ciencia de los datos y aprendizaje automático – sería GitHub. La gran escala de GitHub, combinada con el poder de los científicos de superdatos de todo el mundo, la convierte en una plataforma de uso obligatorio para cualquier persona interesada en este campo.
¿Te imaginas un mundo donde las bibliotecas y los marcos de aprendizaje automático como BERT, StanfordNLP, TensorFlow, PyTorch, etc. no fueran de código abierto? ¡Es impensable! GitHub ha democratizado el aprendizaje automático para las masas, exactamente en línea con lo que creemos en DataPeaker.
Esta fue una de las razones principales por las que comenzamos esta serie de GitHub que cubre las bibliotecas y paquetes de aprendizaje automático más útiles en enero de 2018.

Junto con eso, también hemos estado cubriendo las discusiones de Reddit que creemos que son relevantes para todos los profesionales de la ciencia de datos. Este mes no es diferente. He seleccionado los cinco debates principales de mayo, que se centran en dos cosas: técnicas de aprendizaje automático y asesoramiento profesional de científicos de datos expertos.
También puede consultar los repositorios de GitHub y las discusiones de Reddit que hemos cubierto a lo largo de este año:
Principales repositorios de GitHub (mayo de 2019)


La interpretabilidad es algo ENORME en el aprendizaje automático en este momento. Ser capaz de comprender cómo un modelo produjo el resultado que produjo, un aspecto fundamental de cualquier proyecto de aprendizaje automático. De hecho, incluso hicimos un podcast con Christoph Molar sobre ML interpretable que debería consultar.
InterpretML es un paquete de código abierto de Microsoft para entrenar modelos interpretables y explicar sistemas de caja negra. Microsoft lo expresó mejor cuando explicó por qué la interpretabilidad es esencial:
- Depuración de modelos: ¿Por qué mi modelo cometió este error?
- Detectando sesgo: ¿Mi modelo discrimina?
- Cooperación humano-IA: ¿Cómo puedo entender y confiar en las decisiones del modelo?
- Cumplimiento normativo: ¿Mi modelo cumple con los requisitos legales?
- Aplicaciones de alto riesgo: Sanitario, financiero, judicial, etc.
Interpretar el funcionamiento interno de un modelo de aprendizaje automático se vuelve más difícil a medida que aumenta la complejidad. ¿Alguna vez ha intentado desarmar y comprender un conjunto de modelos múltiples? Se necesita mucho tiempo y esfuerzo para hacerlo.
No podemos simplemente acudir a nuestro cliente o liderazgo con un modelo complejo sin poder explicar cómo produjo una buena puntuación / precisión. Ese es un boleto de ida de regreso a la mesa de dibujo para nosotros.
La gente de Microsoft Research ha desarrollado el algoritmo Explicable Boosting Machine (EBM) para ayudar con la interpretación. Esta técnica de MBE tiene alta precisión e inteligibilidad: el santo grial.
Interpretar ML no se limita a usar EBM. También soporta algoritmos como LIME, modelos lineales, árboles de decisión, entre otros. ¡Comparar modelos y elegir el mejor para nuestro proyecto nunca ha sido tan fácil!
Puede instalar InterpretML usando el siguiente código:
pip install numpy scipy pyscaffold pip install -U interpret
Google Research hace otra aparición en nuestra serie mensual de Github. Sin sorpresas: tienen la mayor potencia computacional en el negocio y la están utilizando en el aprendizaje automático.

Su último lanzamiento de código abierto, llamado Tensor2Robot (T2R) es bastante impresionante. T2R es una biblioteca para entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina...., evaluación e inferencia de redes neuronales profundas a gran escala. Pero espere, se ha desarrollado con un objetivo específico en mente. Está diseñado para redes neuronales relacionadas con la percepción y el control robóticos.
No hay premios por adivinar el marco de aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... en el que se construye Tensor2Robot. Así es, TensorFlow. Tensor2Robot se utiliza dentro de Alphabet, la organización matriz de Google.
Aquí hay un par de proyectos implementados con Tensor2Robot:
TensorFlow 2.0, la versión de TensorFlow (TF) más esperada de este año, se lanzó oficialmente el mes pasado. ¡Y no podía esperar para tenerlo en mis manos!

Este repositorio contiene implementaciones TF de múltiples modelos generativos, que incluyen:
- Redes generativas antagónicas (GAN)
- Autoencoder
- Autoencoder variacional (VAE)
- VAE-GAN, entre otros.
Todos estos modelos se implementan en dos conjuntos de datos con los que estará bastante familiarizado: Fashion MNIST y NSYNTH.
¿La mejor parte? ¡Todas estas implementaciones están disponibles en un Jupyter Notebook! Entonces puede descargarlo y ejecutarlo en su propia máquina o exportarlo a Google Colab. La elección es suya y TensorFlow 2.0 está aquí para que lo comprenda y lo use.
![]()
¡Un repositorio de series de tiempo! No me he encontrado con un nuevo desarrollo de serie temporalUna serie temporal es un conjunto de datos recogidos o medidos en momentos sucesivos, generalmente en intervalos de tiempo regulares. Este tipo de análisis permite identificar patrones, tendencias y ciclos en los datos a lo largo del tiempo. Su aplicación es amplia, abarcando áreas como la economía, la meteorología y la salud pública, facilitando la predicción y la toma de decisiones basadas en información histórica.... en bastante tiempo.
STUMPY es una biblioteca potente y escalable que nos ayuda a realizar tareas de minería de datos de series de tiempo. STUMPY está diseñado para calcular un perfil de matriz. Puedo verte preguntándote: ¿qué demonios es un perfil de matriz? Bueno, este perfil de matriz es un vector que almacena la distancia euclidiana normalizada z entre cualquier subsecuencia dentro de una serie de tiempo y su vecino más cercano.
A continuación se muestran algunas tareas de minería de datos de series de tiempo que este perfil de matriz nos ayuda a realizar:
- Descubrimiento de anomalías
- SegmentaciónLa segmentación es una técnica clave en marketing que consiste en dividir un mercado amplio en grupos más pequeños y homogéneos. Esta práctica permite a las empresas adaptar sus estrategias y mensajes a las características específicas de cada segmento, mejorando así la eficacia de sus campañas. La segmentación puede basarse en criterios demográficos, psicográficos, geográficos o conductuales, facilitando una comunicación más relevante y personalizada con el público objetivo.... semántica
- Estimación de densidad
- Cadenas de series de tiempo (conjunto ordenado temporalmente de patrones de subsecuencia)
- Descubrimiento de patrón / motivo (aproximadamente subsecuencias repetidas dentro de una serie de tiempo más larga)
Utilice el siguiente código para instalarlo directamente a través de pepita:
pip install stumpy
MeshCNN es una red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... profunda de uso general para mallas triangulares 3D. Estas mallas se pueden utilizar para tareas como la clasificación o segmentación de formas 3D. Una magnífica aplicación de visión artificial.
El marco MeshCNN incluye capas de convolución, agrupación y desaparición que se aplican directamente en los bordes de la malla:
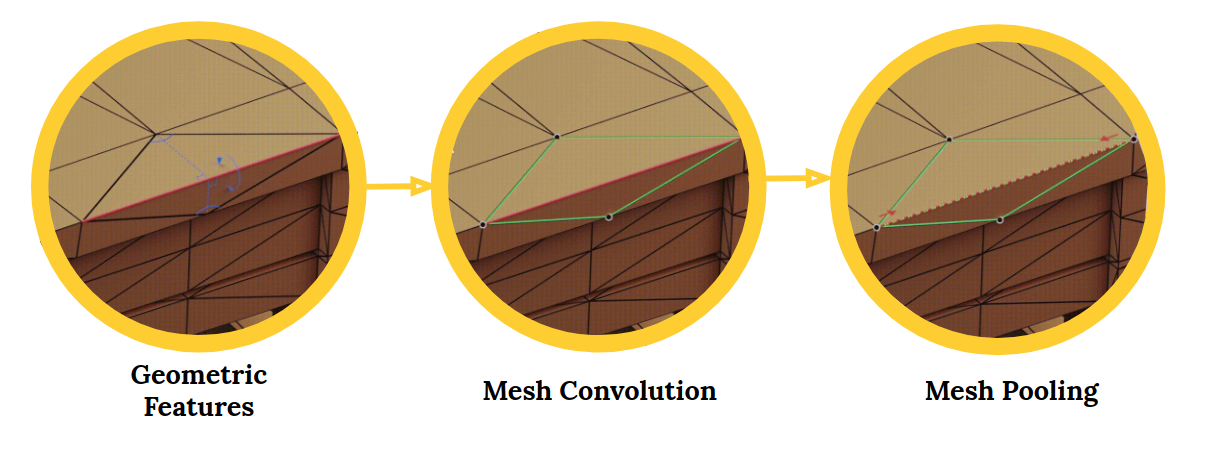
Las redes neuronales convolucionales (CNN) son perfectas para trabajar con imágenes y datos visuales. Las CNN se han puesto de moda en los últimos tiempos con un auge de tareas relacionadas con la imagen que surgen de ellas. Detección de objetos, segmentación de imágenes, clasificación de imágenes, etc., todo esto es posible gracias al avance de las CNN.
El aprendizaje profundo en 3D está atrayendo el interés de la industria, incluidos campos como la robótica y la conducción autónoma. El problema con las formas 3D es que son intrínsecamente irregulares. Esto hace que las operaciones como las convoluciones sean difíciles y desafiantes.
Aquí es donde entra en juego MeshCNN. Desde el repositorio:
Las mallas son una lista de vértices, aristas y caras, que juntos definen la forma del objeto 3D. El problema es que cada vértice tiene un número diferente de vecinos y no hay orden.
Si eres un fanático de la visión por computadora y estás interesado en aprender o aplicar las CNN, este es el repositorio perfecto para ti. Puede obtener más información sobre las CNN a través de nuestros artículos:

Los algoritmos del árbol de decisiones se encuentran entre las primeras técnicas avanzadas que aprendemos en el aprendizaje automático. Honestamente, realmente aprecio esta técnica después de la regresión logística. Podría usarlo en conjuntos de datos más grandes, comprender cómo funcionaba, cómo ocurrieron las divisiones, etc.
Personalmente, amo este repositorio. Es un tesoro para los científicos de datos. El repositorio contiene una colección de artículos sobre algoritmos basados en árboles, incluidos árboles de decisión, regresión y clasificación. El repositorio también contiene la implementación de cada artículo. ¿Qué más podríamos pedir?
¿Alguna vez te has preguntado cómo funciona el proceso de entrenamiento de tu algoritmo de aprendizaje automático? Escribimos el código, ocurre alguna complicación detrás de escena (¡el placer de programar!), Y obtenemos los resultados.
Microsoft Research ha creado una herramienta llamada TensorWatch que nos permite ver visualizaciones en tiempo real del proceso de entrenamiento de nuestro modelo de aprendizaje automático. ¡Increíble! Vea un fragmento de cómo funciona TensorWatch:

TensorWatch, en términos simples, es una herramienta de depuración y visualización para el aprendizaje profundo y el aprendizaje reforzado. Funciona en cuadernos de Jupyter y nos permite realizar muchas otras visualizaciones personalizadas de nuestros datos y nuestros modelos.
Discusiones de Reddit
![]()
Dediquemos unos momentos a ver las discusiones de Reddit más asombrosas relacionadas con la ciencia de datos y el aprendizaje automático de mayo de 2019. Aquí hay algo para todos, ya sea un entusiasta o un practicante de la ciencia de datos. ¡Así que profundicemos!
Este es un hueso duro de roer. La primera pregunta es si debería optar por un doctorado antes de ocupar un puesto en la industria. Y luego, si optó por uno, ¿qué habilidades debería adquirir para facilitar la transición de su industria?
Creo que esta discusión podría ser útil para descifrar uno de los mayores enigmas de nuestra carrera: ¿cómo hacemos la transición de un campo o línea de trabajo a otro? No mire esto solo desde el punto de vista de un estudiante de doctorado. Esto es muy relevante para la mayoría de nosotros que queremos obtener ese primer salto en el aprendizaje automático.
Le recomiendo encarecidamente que siga este hilo, ya que muchos científicos de datos experimentados han compartido sus experiencias personales y su aprendizaje.
Recientemente, se publicó un artículo de investigación que amplía el título de este hilo. El periódico explicaba la hipótesis del billete de lotería en la que una subred más pequeña, también conocida como billete ganador, podría entrenarse más rápido en comparación con una red más grande.
Esta discusión se centra en este documento. Para leer más sobre la hipótesis del billete de lotería y cómo funciona, puede consultar mi artículo donde analizo este concepto para que incluso los principiantes lo entiendan:
Decodificando los mejores artículos de ICLR 2019: las redes neuronales están aquí para gobernar
Elegí esta discusión porque puedo relacionarme totalmente con ella. Solía pensar: he aprendido mucho y, sin embargo, queda mucho más. ¿Me convertiré alguna vez en un experto? Cometí el error de mirar solo la cantidad y no la calidad de lo que estaba aprendiendo.
Con la tecnología de avance rápido y continuo, siempre habrá MUCHO que aprender. Este hilo tiene algunos consejos sólidos sobre cómo puede establecer prioridades, atenerse a ellas y concentrarse en la tarea en cuestión en lugar de tratar de convertirse en un experto en todos los oficios.
Notas finales
¡Me divertí mucho (y aprendí) al armar la colección de GitHub de aprendizaje automático de este mes! Recomiendo encarecidamente marcar ambas plataformas y revisarlas regularmente. Es una excelente manera de mantenerse actualizado con todas las novedades del aprendizaje automático.
O siempre puede volver cada mes y ver nuestras mejores opciones. 🙂
Si cree que me he perdido algún repositorio o alguna discusión, comente a continuación y estaré feliz de tener una discusión al respecto.





