Introducción
es un componente importante, así como uno de los pasos más subestimados en cualquier proyecto de ciencia de datos. EDA es esencial para un análisis de datos bien definido y estructurado y debe realizarse antes de la fase de modelado de aprendizaje automático.
Implica encontrar ideas a partir de los datos tras una observación cuidadosa y resumir aún más sus principales características. Generalmente, los datos de la vida real con los que trabajamos contienen mucho «ruido» y, por lo tanto, realizar el análisis de datos manualmente en dichos conjuntos de datos se convierte en un proceso complicado y tedioso.

Tutorial de introducción a Python: cálculo científico con pandas | por entusiasta del análisis de datos | Medio
Pitón es uno de los lenguajes más utilizados para Ciencia de los datos particularmente debido a la presencia de varias bibliotecas y paquetes que facilitan el análisis de datos.
Respectivamente, Pandas es una de las bibliotecas más populares de Python que ayuda a presentar los datos de una manera adecuada para el análisis a través de su Serie y Marco de datos estructuras de datos. Proporciona varias funciones y métodos para simplificar y acelerar el proceso de análisis de datos.
Aquí utilizamos el conjunto de datos “TITANIC” para realizar la implementación práctica de todas las funciones.
En primer lugar, importamos la biblioteca de Numpy y pandas y luego leemos el conjunto de datos.

Ahora comencemos
1. df.head (): De forma predeterminada, devuelve las primeras 5 filas del marco de datos. Para cambiar el valor predeterminado, puede insertar un valor entre paréntesis para cambiar el número de filas devueltas.

2. df.tail (): De forma predeterminada, devuelve las últimas 5 filas del marco de datos. Esta función se usa para obtener las últimas n filas. Esta función devuelve las últimas n filas del objeto según la posición.

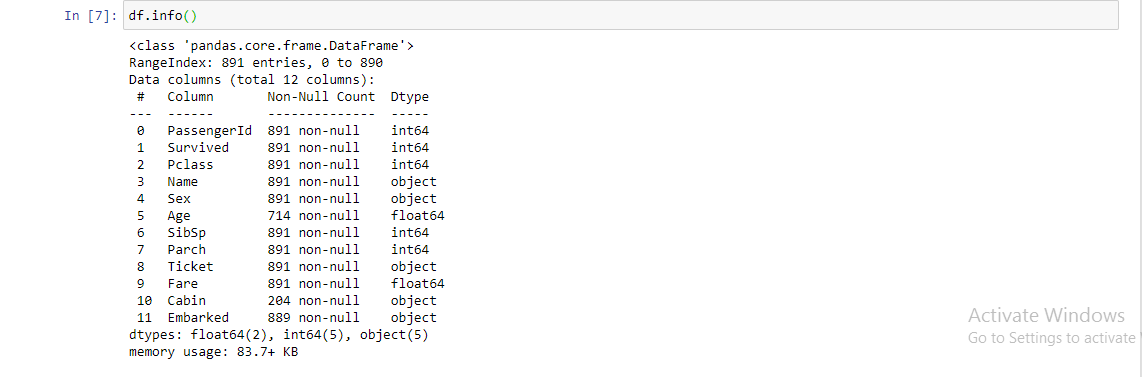
3. df.info (): Ayuda a obtener una descripción general rápida del conjunto de datos. Esta función se utiliza para obtener un breve resumen del marco de datos. Este método imprime información sobre un DataFrame, incluido el tipo de índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... y los tipos de columna, valores no nulos y uso de memoria.
4. df. Forma: Muestra el número de dimensiones así como el tamaño en cada dimensión"Dimensión" es un término que se utiliza en diversas disciplinas, como la física, la matemática y la filosofía. Se refiere a la medida en la que un objeto o fenómeno puede ser analizado o descrito. En física, por ejemplo, se habla de dimensiones espaciales y temporales, mientras que en matemáticas puede referirse a la cantidad de coordenadas necesarias para representar un espacio. Su comprensión es fundamental para el estudio y.... Dado que los marcos de datos son bidimensionales, la forma que devuelve es el número de filas y columnas.
5. df.tamaño: Devuelve un int que representa el número de elementos de este objeto. Devuelve el número de filas si es Serie; de lo contrario, devuelve el número de filas multiplicado por el número de columnas si es DataFrame.
6. df.ndim: Devuelve la dimensión del marco / serie de datos. 1 para una dimensión (serie), 2 para dos dimensiones (marco de datos).
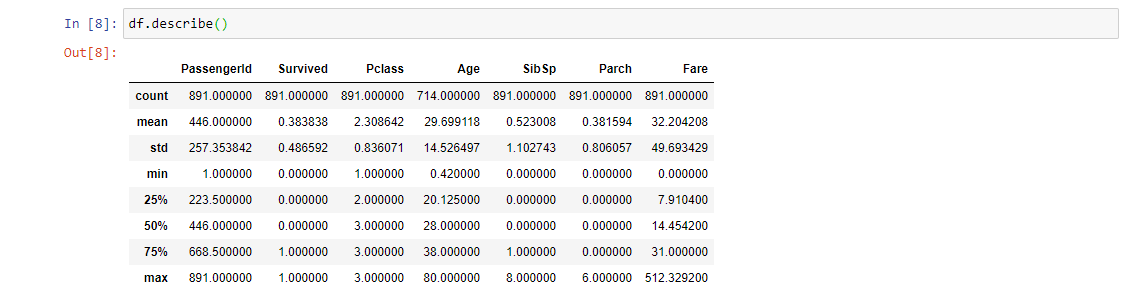
7. df.describe (): Devuelve un resumen estadístico de las columnas numéricas presentes en el conjunto de datos. Este método calcula algunas medidas estadísticas como el percentil, la media y la desviación estándar de los valores numéricos de la Serie o DataFrame.
8. df.sample (): Se utiliza para generar una muestra de forma aleatoria en una fila o en una columna. Le permite seleccionar valores aleatoriamente de una serie o DataFrame. Es útil cuando queremos seleccionar una muestra aleatoria de una distribución.

9. df.isnull () .sum (): Devuelve el número de valores perdidos en cada columna.

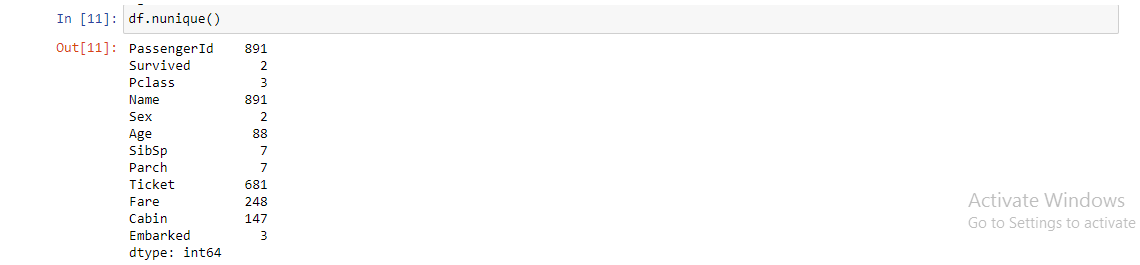
10. df.nunique (): Devuelve el número de elementos únicos del objeto. Cuenta el número de entradas únicas en columnas o filas. Es muy útil en características categóricas, especialmente en casos en los que no conocemos el número de categorías de antemano.
11. df.index: Esta función busca un elemento dado desde el principio de la lista y devuelve el índice más bajo donde aparece el elemento.
12. columnas de df .: Devuelve las etiquetas de columna del marco de datos.

13. df.memory_usage (): Devuelve cuánta memoria usa cada columna en bytes. Es útil especialmente cuando trabajamos con grandes marcos de datos.

14. df.dropna (): Esta función se utiliza para eliminar una fila o columna de un marco de datos que tiene un NaN o valores faltantes.

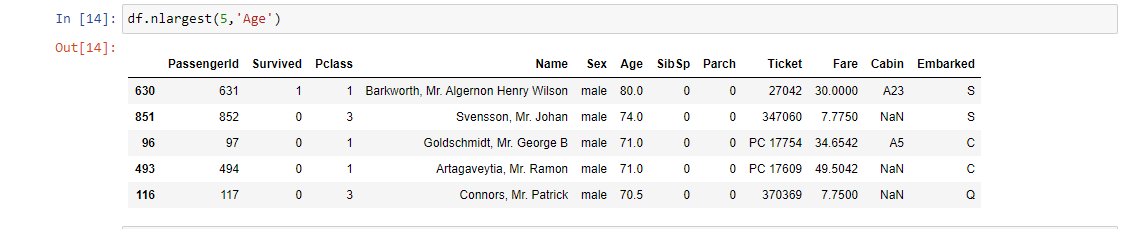
15. df.nlargest (): Devuelve el primero norte filas ordenadas por columnas en orden descendente.
16. df.isna (): Esta función devuelve un marco de datos lleno de valores booleanos con verdadero que indica valores faltantes.
17. df.duplicated (): Devuelve una serie booleana que denota filas duplicadas.

18. value_counts (): Esta función se utiliza para obtener una serie que contiene recuentos de valores únicos. El objeto resultante estará en orden descendente de modo que el primer elemento sea el elemento que se presente con más frecuencia. Excluye los valores perdidos de forma predeterminada. Esta función es útil cuando queremos verificar el problema del desequilibrio de clases para una variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... categórica.

19. df.corr (): Esta función se utiliza para encontrar la correlación por pares de todas las columnas en el marco de datos. Los valores faltantes se excluyen automáticamente. Para cualquier columna de tipo de datos no numéricos en el marco de datos, se ignora. Esta función es útil mientras hacemos la selección de características al observar la correlación entre las características y la variable de destino o entre las variables.
20. tipos de df.d: Esta función muestra el tipo de datos de cada columna.
Notas finales
¡Gracias por leer!
Si le gustó esto y desea saber más, visite mis otros artículos sobre ciencia de datos y aprendizaje automático haciendo clic en el enlace
No dude en ponerse en contacto conmigo en Linkedin, Correo electrónico.
¿Algo no mencionado o quieres compartir tus pensamientos? No dude en comentar a continuación y me pondré en contacto con usted.
Hasta entonces, quédese en casa, manténgase seguro para evitar la propagación de COVID-19, ¡y sigue aprendiendo!
Sobre el Autor
Chirag Goyal
Actualmente, estoy cursando mi Licenciatura en Tecnología (B.Tech) en Ciencias de la Computación e Ingeniería de la Instituto Indio de Tecnología de Jodhpur (IITJ). Estoy muy entusiasmado con el aprendizaje automático, el aprendizaje profundoEl aprendizaje profundo, una subdisciplina de la inteligencia artificial, se basa en redes neuronales artificiales para analizar y procesar grandes volúmenes de datos. Esta técnica permite a las máquinas aprender patrones y realizar tareas complejas, como el reconocimiento de voz y la visión por computadora. Su capacidad para mejorar continuamente a medida que se le proporcionan más datos la convierte en una herramienta clave en diversas industrias, desde la salud... y la inteligencia artificial.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





