Este post fue difundido como parte del Blogatón de ciencia de datos
Introducción
Como científico de datos, el web scraping es una de las habilidades vitales que necesita dominar, y debe buscar datos útiles, recabar y preprocesar datos para que sus resultados sean significativos y precisos.
Antes de sumergirnos en las herramientas que podrían ayudar en las actividades de extracción de datos, confirmemos que esta actividad es lícito dado que el web scraping ha sido un área legal gris. La corte de EE. UU. Legalizó por completo el raspado web de datos disponibles públicamente en 2020. Significa que si encontró información en línea (como posts de Wiki), entonces es lícito raspar los datos.
Aún así, cuando lo hagas, asegúrate de:
- Que no reutilice ni vuelva a publicar los datos de una manera que viole los derechos de autor.
- Que cumpla con los términos de servicio del portal web que está raspando.
- Que tienes una tasa de rastreo justa.
- Que no intente extraer partes privadas del portal web.
Siempre que no infrinja los términos anteriores, su actividad de raspado web estará en el lado legal.
Creo que algunos de ustedes podrían haber usado BeautifulSoup y solicitudes para recabar los datos y pandas para analizarlos para sus proyectos. Esta publicación le brindará cinco herramientas de raspado web que no incluyen BeautifulSoup; es de uso sin costes y recopila los datos para su próximo proyecto.
El creador de Common Crawl creó esta herramienta debido a que asume que todos deberían tener la posibilidad de explorar y realizar análisis de los datos que los rodean y descubrir información útil. Contribuyen con datos de alta calidad que solo estaban abiertos para grandes instituciones e institutos de investigación a cualquier mente entrometida sin costo para alentar sus creencias open source.
Se puede usar esta herramienta sin preocuparse por los cargos o cualquier otra dificultad financiera. Si es un estudiante, un novato que se sumerge en la ciencia de datos o simplemente una persona ansiosa a la que le encanta explorar conocimientos y descubrir nuevas tendencias, esta herramienta sería útil. Hacen que los datos sin procesar de la página web y las extracciones de palabras estén disponibles como conjuntos de datos abiertos. Además ofrece recursos para instructores que enseñan análisis de datos y asistencia para casos de uso no basados en código.
Ir por medio de sitio web para obtener más información sobre el uso de conjuntos de datos y las alternativas para extraer los datos.
Crawly es otra alternativa, especialmente si solo necesita extraer datos simples de un portal web o si desea extraer datos en formato CSV para poder examinarlos sin escribir ningún código. El usuario debe ingresar una URL, una identificación de email para enviar los datos extraídos, el formato de los datos requeridos (elija entre CSV o JSONJSON, o JavaScript Object Notation, es un formato ligero de intercambio de datos que es fácil de leer y escribir para los humanos, y fácil de analizar y generar para las máquinas. Se utiliza comúnmente en aplicaciones web para enviar y recibir información entre un servidor y un cliente. Su estructura se basa en pares de clave-valor, lo que lo hace versátil y ampliamente adoptado en el desarrollo de software...) y listo, los datos extraídos están en su bandeja de entrada para usarlos.
Uno puede utilizar datos JSON y analizarlos usando Pandas y Matplotlib, o cualquier otro lenguaje de programación. Si es un novato en la ciencia de datos y el raspado web, no un programador, esto es bueno y tiene sus limitaciones. Se puede extraer un conjunto limitado de etiquetas HTML que incluyen título, autor, URL de la imagen y editor.
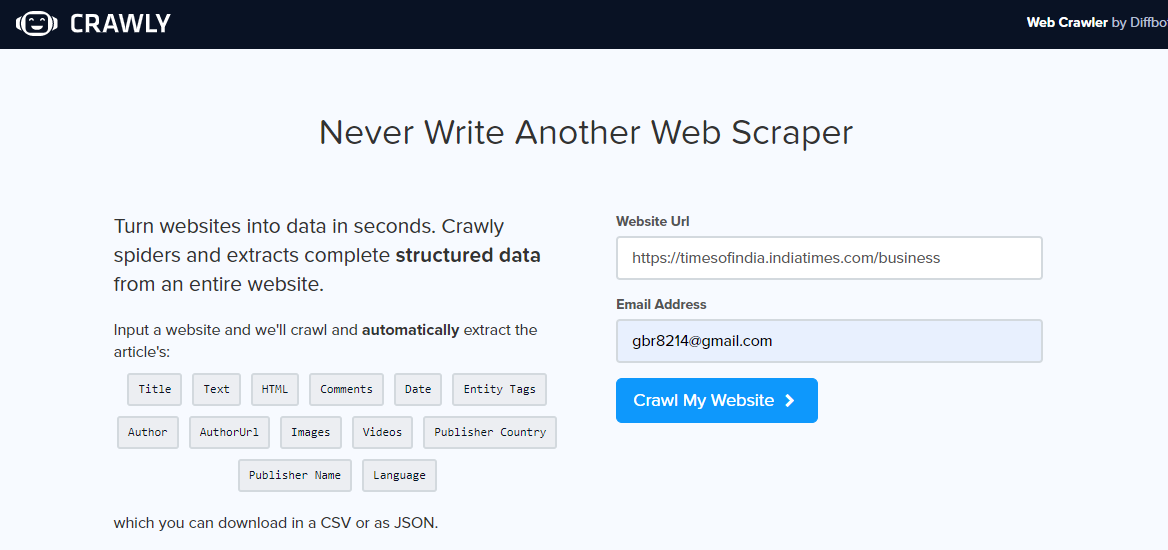
Una vez que haya abierto el portal web de rastreo, ingrese la URL a raspar, seleccione el formato de los datos y su ID de email para recibir los datos. Revise su bandeja de entrada para ver los datos.
El capturador de contenido es una herramienta flexible si le gusta raspar una página web y no desea especificar otros parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto...., el usuario puede hacerlo usando su GUI simple. Aún así, brinda la opción de control total de los parámetros de extracción para personalizar.
El usuario puede programar el raspado de información de la web automáticamente, es una de sus ventajas. En la actualidad, todos sabemos que las páginas web se actualizan con regularidad, por lo que la extracción frecuente de contenido sería útil.
Ofrece varios formatos de datos extraídos como CSV, JSON a SQL Server o MySQL.
Un ejemplo rápido para raspar los datos
Se puede usar esta herramienta para navegar visualmente por el portal web y hacer un clic en los ítems de datos en el orden en que desee recopilarlos. Detectará automáticamente el tipo de acción correcto y proporcionará nombres predeterminados para cada comando a medida que crea el agente según los ítems de contenido especificados.
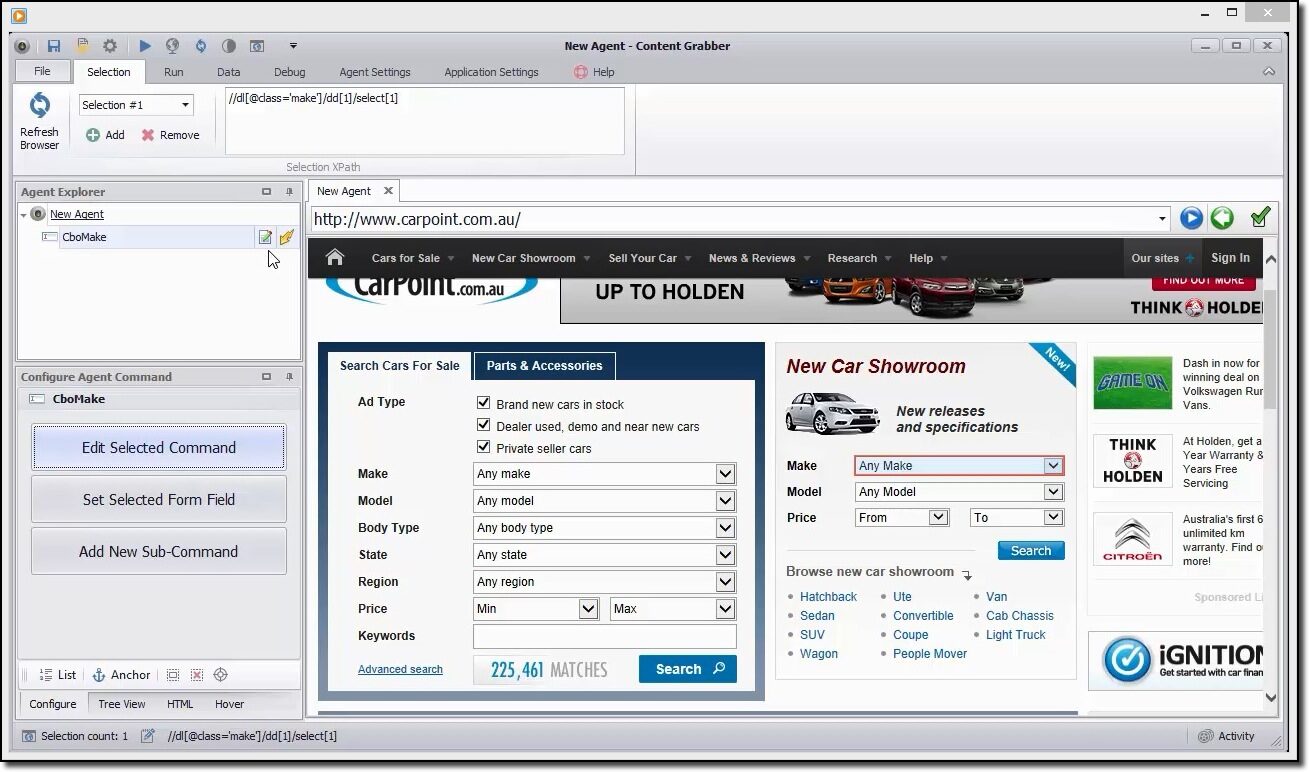
Esta herramienta es una colección de comandos que se ejecutan en orden hasta que se completan. El orden de ejecución se actualiza en el panelUn panel es un grupo de expertos que se reúne para discutir y analizar un tema específico. Estos foros son comunes en conferencias, seminarios y debates públicos, donde los participantes comparten sus conocimientos y perspectivas. Los paneles pueden abordar diversas áreas, desde la ciencia hasta la política, y su objetivo es fomentar el intercambio de ideas y la reflexión crítica entre los asistentes.... Explorador de agentes. Se puede hacer uso del panel de comando del agente de configuración para personalizar el comando en función de los requerimientos de datos particulares. Los usuarios además pueden agregar nuevos comandos.
ParseHub es una poderosa herramienta de raspado web que cualquiera puede utilizar de forma gratuita. Ofrece una extracción de datos segura y precisa con la facilidad de un clic. Los usuarios además pueden determinar tiempos de extracción para mantener la relevancia de sus restos.
Uno de sus puntos fuertes es que puede borrar inclusive las páginas web más complicadas sin problemas. El usuario puede especificar instrucciones tales como formularios de búsqueda, iniciar sesiónLa "Sesión" es un concepto clave en el ámbito de la psicología y la terapia. Se refiere a un encuentro programado entre un terapeuta y un cliente, donde se exploran pensamientos, emociones y comportamientos. Estas sesiones pueden variar en duración y frecuencia, y su objetivo principal es facilitar el crecimiento personal y la resolución de problemas. La efectividad de las sesiones depende de la relación entre el terapeuta y el... en sitios web y hacer un clic en mapas o imágenes para la recopilación posterior de datos.
Los usuarios además pueden ingresar con bastantes links y palabras clave, donde pueden extraer información relevante en segundos. Para terminar, se puede utilizar la API REST para descargar los datos extraídos para su análisis en formatos CSV o JSON. Los usuarios además pueden exportar la información recopilada como una hoja de Google o Tableau.
Ejemplo de portal web de raspado de comercio electrónico
Una vez que haya terminado la instalación, abra un nuevo proyecto en ParseHub, use la URL de comercio electrónico y la página se representará en la aplicación.
- Haga clic en el nombre del producto del primer resultado en la página una vez que se haya cargado el sitio. Cuando selecciona el producto, se torna verde para indicar que ha sido escogido.
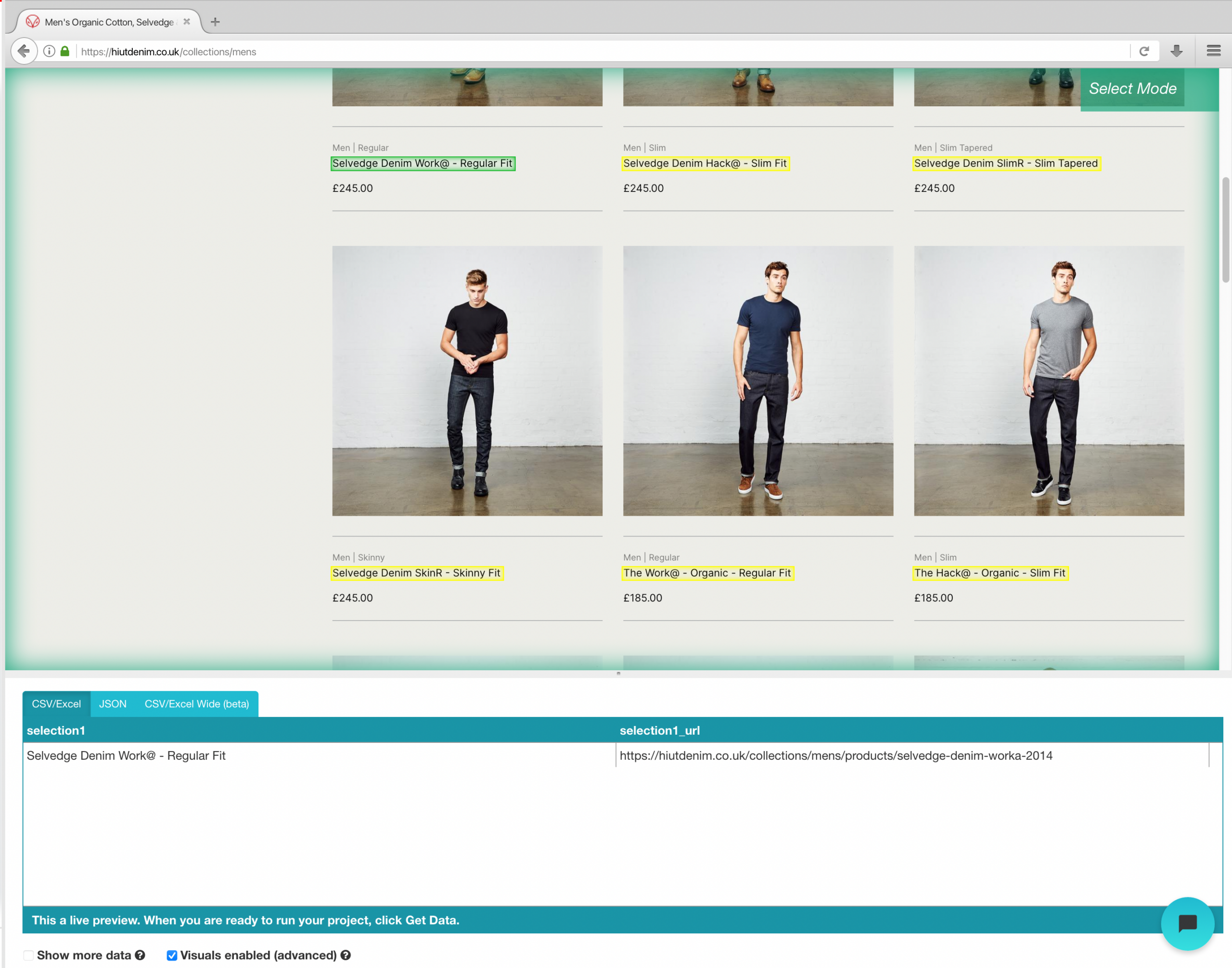
- El amarillo se utilizará para resaltar el resto de los nombres de productos. Seleccione la segunda opción de la lista. El verde ahora se usará para resaltar todos los objetos.
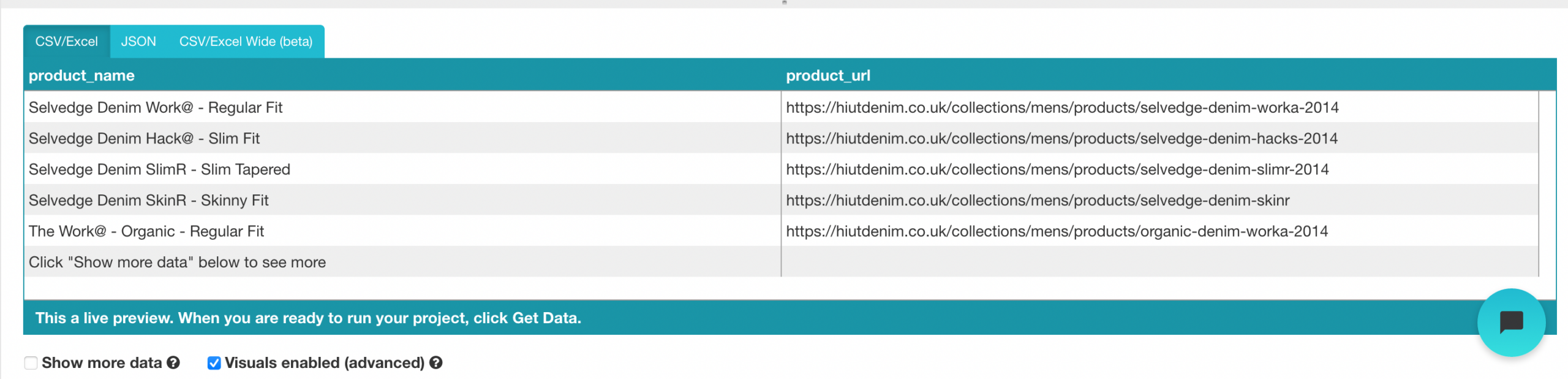
- Cambie el nombre de su elección a «producto» en la barra lateral izquierda. Ahora puede ver el nombre del producto y la URL extraídos por ParseHub.
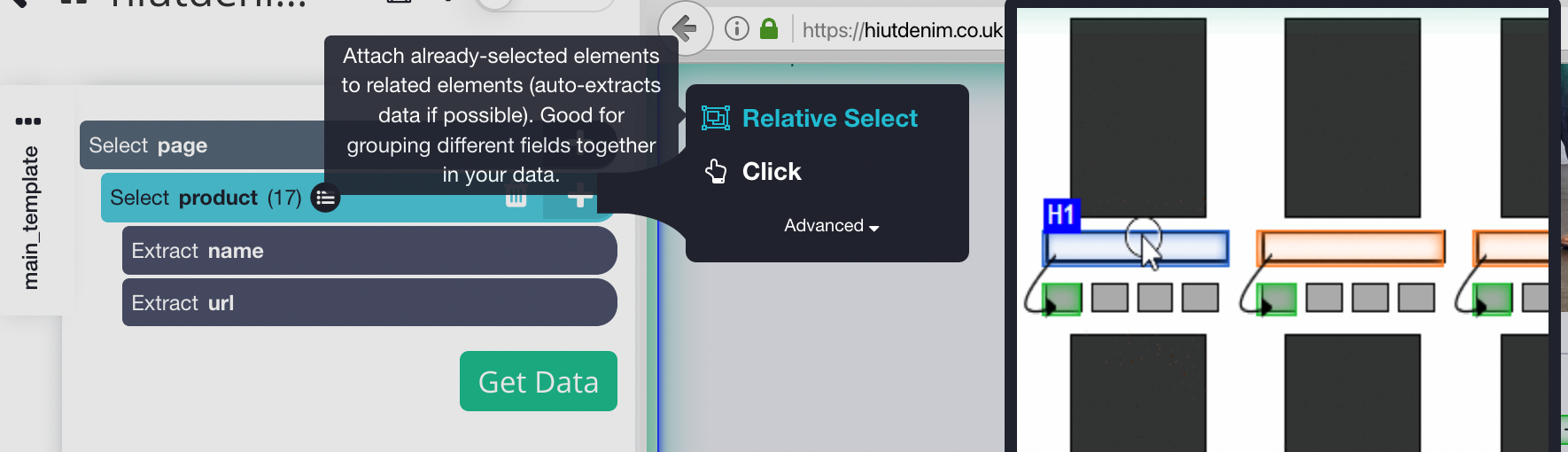
- Haga clic en el signo MÁS (+) junto a la selección de producto en la barra lateral izquierda y seleccione el comando Selección relativa.
- Haga clic en el primer nombre del producto en la página, seguido del precio del producto, usando el comando Selección relativa. Aparecerá una flecha conectando las dos opciones. Este paso debe repetirse varias veces para entrenar a Parsehub en lo que desea extraer.
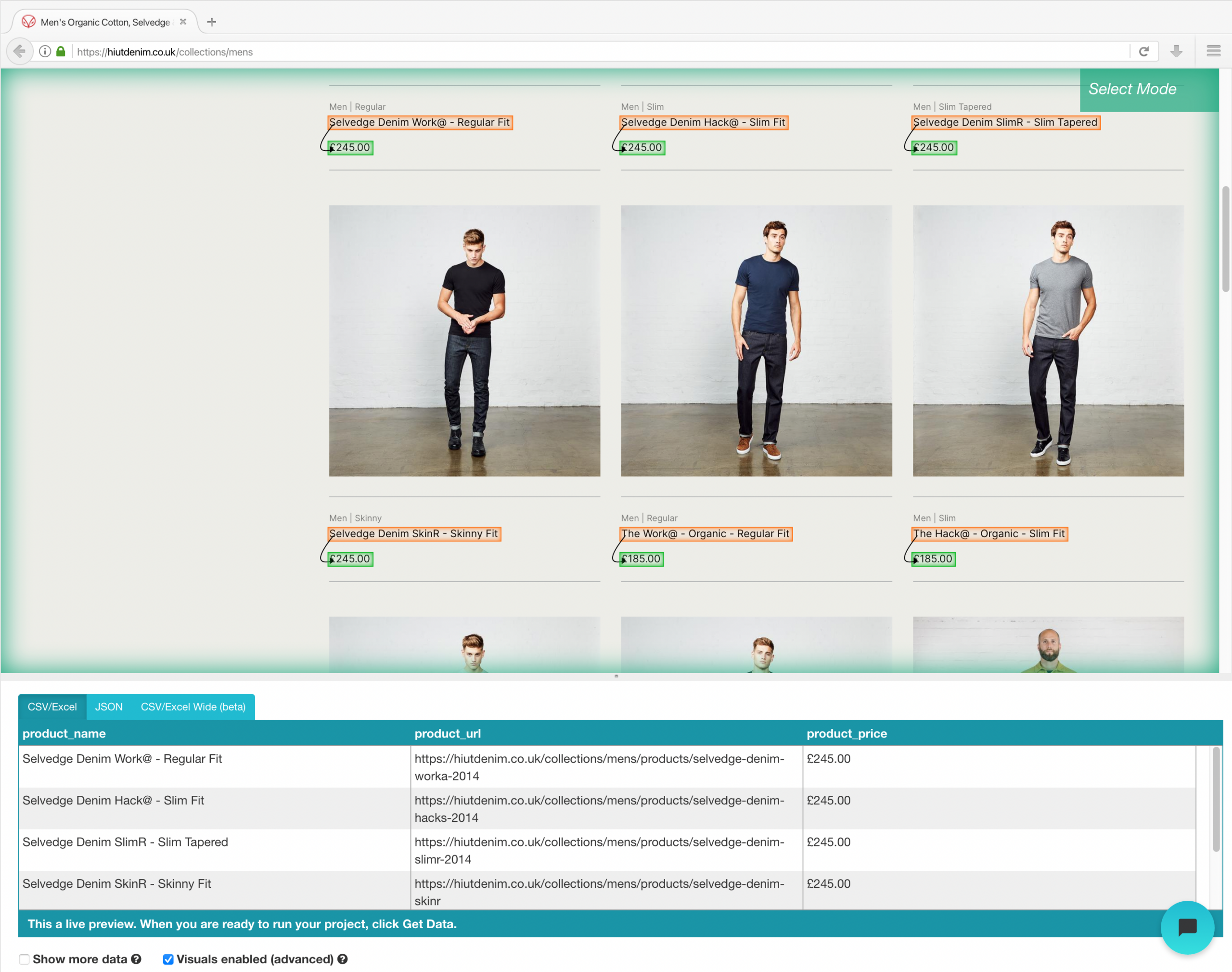
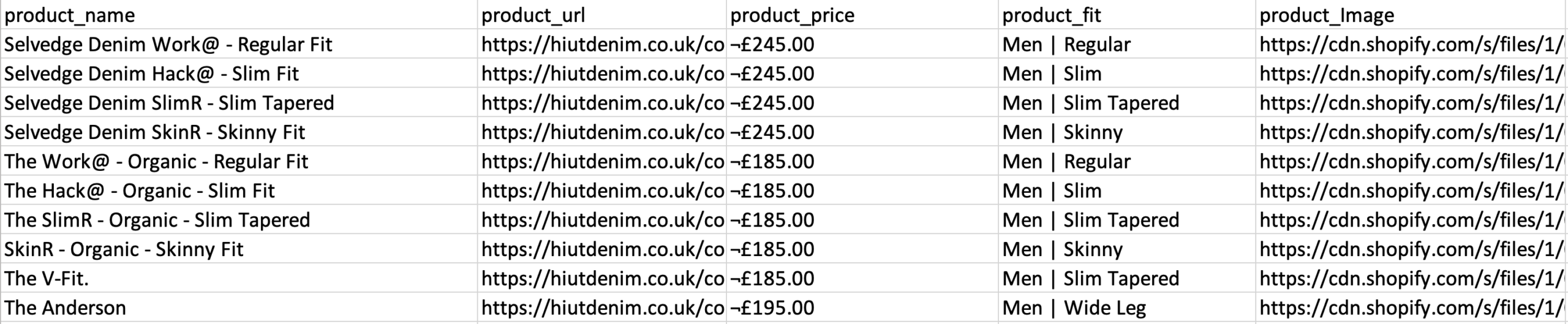
- Repita el paso anterior para extraer además el estilo de ajuste y la imagen del producto. Asegúrese de cambiar el nombre de sus nuevas opciones de manera adecuada.
Ejecución y exportación de su proyecto
Ahora que hemos terminado de configurar el proyecto, es hora de ejecutar nuestro trabajo de scrape.
Para ejecutar su raspado, haga clic en el botón Obtener datos en la barra lateral izquierda y después en el botón Ejecutar. Para proyectos más grandes, sugerimos ejecutar una ejecución de prueba para asegurarse de que sus datos tengan el formato correcto.
Es la última herramienta de raspado de la lista. Dispone de una API de raspado web que puede manejar inclusive las páginas Javascript más complejas y convertirlas a HTML sin procesar para que los usen los usuarios. Además ofrece una API específica para raspar sitios web a través de la búsqueda de Google.
Podemos usar esta herramienta de una de estas tres formas:
- Web Scraping general, a modo de ejemplo, extrayendo opiniones de clientes o precios de acciones.
- Página de resultados del motor de búsqueda utilizada para el seguimiento de palabras clave o SEO.
- La extracción de información de contacto o datos de redes sociales incluye Growth Hacking.
Esta herramienta ofrece un plan sin costes que incluye 1000 créditos y planes pagos para uso ilimitado.
Tutorial sobre el uso de la API de Scrapingbee
Regístrese para obtener un plan sin costes en el portal web de ScrapingBee y obtendrá 1000 solicitudes de API gratuitas, que deberían ser suficientes para aprender y probar esta API.
Ahora vaya al panel de control y copie la clave API que necesitaremos más adelante en esta guía. ScrapingBee ahora proporciona soporte en varios idiomas, lo que le posibilita utilizar la clave API de forma directa en sus aplicaciones.
Dado que Scaping Bee es compatible con las API REST, es adecuado para cualquier lenguaje de programación, incluidos CURL, Python, NodeJS, Java, PHP y Go. Para obtener más información sobre el raspado, usaremos Python y el marco de solicitud, así como BeautifulSoup. Instálelos usando PIP de la próxima manera:
# To install the Python Requests library: pip install requests # Additional modules we needed: pip install BeautifulSoup
Utilice el siguiente código para iniciar la API web de ScrapingBee. Estamos realizando una llamada de solicitud con los parámetros URL y clave de API, y la API responderá con el contenido HTML de la URL de destino.
import requests
def get_data():
response = requests.get(
dirección url="https://app.scrapingbee.com/api/v1/",
params={
"api_key": "INSERT-YOUR-API-KEY",
"dirección url": "https://example.com/", #website to scrape
},
)
print('HTTP Status Code: ', response.status_code)
print('HTTP Response Body: ', response.content)
get_data()
Al agregar un código de embellecimiento, podemos hacer que esta salida sea más legible usando BeautifulSoup.
Codificación
Además puede utilizar urllib.parse para cifrar la URL que desea raspar, como se muestra a continuación:
import urllib.parse
encoded_url = urllib.parse.quote("URL to scrape")
Conclusión
La recopilación de datos para sus proyectos es el paso más tedioso y menos divertido. Esta tarea puede llevar mucho tiempo, y si trabaja en una compañía o como autónomo, sabía que el tiempo es dinero, y si hay una forma más importante de hacer una tarea, es mejor que la utilice. La buena noticia es que el web scraping no tiene por qué ser tedioso, dado que el uso de la herramienta correcta puede ayudarlo a ahorrar mucho tiempo, dinero y esfuerzo. Estas herramientas pueden ser beneficiosas para analistas o personas sin conocimientos de codificación. Antes de elegir una herramienta para raspar, hay algunos factores a considerar, como la integración de API y la extensibilidad del raspado a gran escala. Este post le presentó algunas herramientas útiles para diferentes tareas de recopilación de datos, donde puede seleccionar la que facilita la recopilación de datos.
Espero que este articulo sea de utilidad. Gracias.
Los medios que se muestran en este post no son propiedad de DataPeaker y se usan a discreción del autor.





