Introducción
Si en algún momento ha participado en concursos de ciencia de datos, debe ser consciente del papel fundamental que desempeña el modelado de conjuntos. En realidad, se dice que el modelado de conjuntos ofrece una de las formas más convincentes de construir modelos predictivos de alta precisión. La disponibilidad de embolsado y refuerzo Los algoritmos embellecen aún más este método para producir un nivel de precisión asombroso.
Por eso, la próxima vez que cree un modelo predictivo, considere utilizar este algoritmo. Definitivamente me daría una palmada en la espalda por esta sugerencia. Y, si ya domina este método, genial. Me encantaría escuchar su experiencia sobre el modelado de conjuntos en la sección de comentarios a continuación.
Por lo demás, comparto algunas de las preguntas más frecuentes sobre el modelado de conjuntos. Si en algún momento desea examinar el conocimiento de cualquier persona sobre el conjunto, puede atreverse a hacer estas preguntas y verificar su conocimiento. Al mismo tiempo, estas son algunas de las preguntas más fáciles, por lo que no puedes atreverte a equivocarte.

¿Cuáles son las preguntas comunes (asociadas con los modelos de conjuntos)?
Después de analizar varios foros de ciencia de datos, He identificado las 5 preguntas más comunes asociadas con el modelado de conjuntos. Estas preguntas son muy relevantes para los científicos de datos que son nuevos en el modelado de conjuntos. Aquí están las preguntas:
- ¿Qué es un modelo de conjunto?
- ¿Qué son el ensacado, el refuerzo y el apilado?
- ¿Podemos ensamblar varios modelos del mismo algoritmo ML?
- ¿Cómo podemos identificar los pesos de diferentes modelos?
- ¿Cuáles son los beneficios del modelo de conjunto?
Analicemos cada pregunta en detalle.
1. ¿Qué es un modelo de conjunto?
Intentemos entenderlo resolviendo un desafío de clasificación.
Problema: establezca reglas para la clasificación de correos electrónicos no deseados

Solución: Podemos generar varias reglas para la clasificación de correos electrónicos no deseados, veamos algunas de ellas:
- Correo no deseado
- Tener una extensión total de menos de 20 palabras.
- Tener solo imagen (imágenes promocionales)
- Tenga palabras clave específicas como «ganar dinero y crecer» y «reducir su grasa»
- Más palabras deletreadas en el email
- No spam
- Email del dominio de DataPeaker
- Email de miembros de la familia o cualquier persona de la libreta de direcciones de email
Arriba, he enumerado algunas reglas comunes para filtrar los correos electrónicos no deseados. ¿Crees que todas estas reglas individualmente pueden predecir la clase correcta?
La mayoría de nosotros diría que no, ¡y eso es cierto! La combinación de estas reglas proporcionará una predicción sólida en comparación con el pronóstico realizada por reglas individuales. Este es el principio del modelado de conjuntos. El modelo de conjunto combina varios modelos ‘individuales’ (múltiples) juntos y ofrece un poder de predicción superior.
Si desea relacionar esto con la vida real, es probable que un grupo de personas tome mejores decisiones en comparación con los individuos, especialmente cuando los miembros del grupo provienen de múltiples antecedentes. Lo mismo ocurre con el aprendizaje automático. Simplemente, un conjunto es una técnica de aprendizaje supervisadoEl aprendizaje supervisado es un enfoque de machine learning donde un modelo se entrena utilizando un conjunto de datos etiquetados. Cada entrada en el conjunto de datos está asociada a una salida conocida, lo que permite al modelo aprender a predecir resultados para nuevas entradas. Este método es ampliamente utilizado en aplicaciones como la clasificación de imágenes, el reconocimiento de voz y la predicción de tendencias, destacando su importancia en... para combinar múltiples estudiantes / modelos débiles para producir un aprendiz fuerte. El modelo de conjunto funciona mejor cuando ensamblamos modelos con baja correlación.
Un buen ejemplo de cómo se usan comúnmente los métodos de conjunto para solucionar problemas de ciencia de datos es el bosque aleatorio algoritmo (que cuenta con varios modelos CART). Funciona mejor en comparación con el modelo CART individual al categorizar un nuevo objeto donde cada árbol da «votos» para esa clase y el bosque elige la clasificación que tiene la mayor cantidad de votos (sobre todos los árboles del bosque). En caso de regresión, toma el promedio de salidas de diferentes árboles.
Además puede seguir este post «Conceptos básicos del aprendizaje de conjuntos explicados en inglés simple» para obtener más conocimientos sobre el modelado de conjuntos.
2. ¿Qué son el ensacado, el refuerzo y el apilado?
Veamos cada uno de estos individualmente e intentemos comprender las diferencias entre estos términos:
Harpillera (Bootstrap Aggregating) es un método de conjunto. Primero, creamos muestras aleatorias del conjunto de datos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... (subconjuntos del conjunto de datos de entrenamiento). Después, construimos un clasificador para cada muestra. En resumen, los resultados de estos múltiples clasificadores se combinan a través de votación promedio o mayoritaria. El ensacado ayuda a reducir el error de variación.
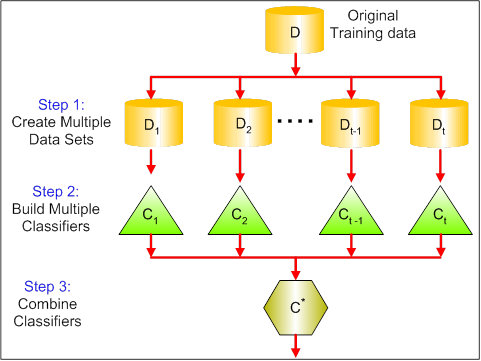
Impulso proporciona aprendizaje secuencial de los predictores. El primer predictor se aprende en todo el conjunto de datos, mientras que lo siguiente se aprende en el conjunto de entrenamiento en función del rendimiento del anterior.. Eso comienza clasificando el conjunto de datos original y dando la misma ponderación a cada observación. Si las clases se predicen incorrectamente usando el primer alumno, entonces se da mayor peso a la observación clasificada perdida. Al ser un procedimiento iterativo, continúa agregando aprendices clasificadores hasta que se cumple un límite en el número de modelos o precisión. El impulso ha mostrado una mejor precisión predictiva que el ensacado, pero además tiende a sobreajustar los datos de entrenamiento. 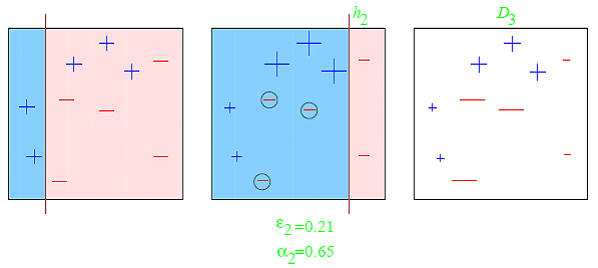
El ejemplo más común de refuerzo es AdaBoost y Gradient Boosting. Además puede consultar estos posts para obtener más información acerca de cómo impulsar algoritmos.
Apilado trabaja en dos fases. Primero, usamos múltiples clasificadores base para predecir la clase. En segundo lugar, se utiliza un nuevo alumno para combinar sus predicciones con el fin de reducir el error de generalización. 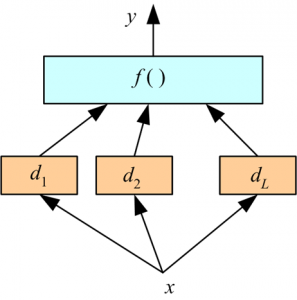
3. ¿Podemos ensamblar múltiples modelos del mismo algoritmo ML?
Sí, podemos combinar múltiples modelos de los mismos algoritmos ML, pero la combinación de múltiples predicciones generadas por diferentes algoritmos regularmente le brindaría mejores predicciones. Se debe a la diversificación o naturaleza independiente en comparación entre sí. A modo de ejemplo, las predicciones de un bosque aleatorio, un KNN y un Naive Bayes pueden combinarse para crear un conjunto de predicciones final más sólido en comparación con la combinación de tres modelos de bosque aleatorio. La clave para crear un conjunto poderoso es la diversidad de modelos. Un conjunto con dos técnicas que son de naturaleza muy equivalente funcionará mal que un conjunto de modelos más diverso.
Ejemplo: Digamos que tenemos tres modelos (A, B y C). A, B y C disponen una precisión de predicción del 85%, 80% y 55% respectivamente. Pero se encuentra que A y B están altamente correlacionados cuando C está escasamente correlacionado con A y B. ¿Deberíamos combinar A y B? No, no deberíamos, debido a que estos modelos están altamente correlacionados. Por eso, no combinaremos estos dos, dado que este conjunto no ayudará a reducir ningún error de generalización. Preferiría combinar A y C o B y C.
4. ¿Cómo podemos identificar los pesos de diferentes modelos para el conjunto?
Uno de los desafíos más comunes con el modelado de conjuntos es hallar pesos óptimos para los modelos base de conjuntos. En general, asumimos el mismo peso para todos los modelos y tomamos el promedio de las predicciones. Pero, ¿es esta la mejor forma de afrontar este desafío?
Existen varios métodos para hallar el peso óptimo para combinar todos los alumnos básicos. Estos métodos proporcionan una comprensión justa acerca de cómo hallar el peso correcto. A continuación, enumero algunos de los métodos:
- Encuentre la colinealidad entre los alumnos base y basándose en esta tabla, después identifique los modelos base para ensamblar. Después de eso, observe la puntuación de validación cruzada (proporción de puntuación) de los modelos base identificados para hallar el peso.
- Encuentre el algoritmo para devolver el peso óptimo para los alumnos básicos. Puede consultar el post Cómo hallar pesos óptimos de aprendices de conjunto usando una red neuronalLas redes neuronales son modelos computacionales inspirados en el funcionamiento del cerebro humano. Utilizan estructuras conocidas como neuronas artificiales para procesar y aprender de los datos. Estas redes son fundamentales en el campo de la inteligencia artificial, permitiendo avances significativos en tareas como el reconocimiento de imágenes, el procesamiento del lenguaje natural y la predicción de series temporales, entre otros. Su capacidad para aprender patrones complejos las hace herramientas poderosas... para ver el método para hallar el peso óptimo.
- Además podemos solucionar el mismo problema usando métodos como:
Además puede ver la respuesta ganadora de los concursos de ciencia de datos / Kaggle para comprender otros métodos para enfrentar este desafío.
5. ¿Cuáles son los beneficios del modelo de conjunto?
Hay dos ventajas principales de los modelos Ensemble:
- Mejor predicción
- Modelo más estable
La opinión agregada de varios modelos es menos ruidosa que la de otros modelos. En finanzas, lo llamamos «Diversificación»: una cartera mixta de muchas acciones será mucho menos variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... que una sola de las acciones. Esta es además el motivo por la que sus modelos serán mejores con conjuntos de modelos en lugar de individuales. Una de las precauciones con los modelos de conjuntos es que se ajustan demasiado, aún cuando el ensacado se encarga de ello en gran medida.
Nota final
En este post, hemos analizado las 5 preguntas frecuentes sobre los modelos Ensemble. Al responder a estas preguntas, hemos discutido sobre “Modelos de conjunto”, “Métodos de conjunto”, “¿Por qué deberíamos ensamblar modelos múltiples?”, “Métodos para identificar el peso óptimo para el conjunto” y para terminar “Beneficios”. Le sugiero que mire las 5 mejores soluciones de concursos de ciencia de datos y vea sus enfoques conjuntos para tener una mejor comprensión y practicar mucho. Le ayudará a comprender qué funciona y qué no.
¿Le fue útil este post? ¿Ha intentado algo más para hallar pesos óptimos o identificar al alumno base adecuado? Estaré feliz de saber de usted en la sección de comentarios a continuación.





