Este artículo fue publicado como parte del Blogatón de ciencia de datos
Después de comprender y trabajar con este tutorial práctico, podrá:
- Comprender qué es el análisis de cohortes y cohortes.
- Manejo de valores perdidos
- Extracción del mes desde la fecha
- Asignar cohorte a cada transacciónLa "transacción" se refiere al proceso mediante el cual se lleva a cabo un intercambio de bienes, servicios o dinero entre dos o más partes. Este concepto es fundamental en el ámbito económico y legal, ya que implica el acuerdo mutuo y la consideración de términos específicos. Las transacciones pueden ser formales, como contratos, o informales, y son esenciales para el funcionamiento de mercados y negocios....
- Asignar índiceEl "Índice" es una herramienta fundamental en libros y documentos, que permite ubicar rápidamente la información deseada. Generalmente, se presenta al inicio de una obra y organiza los contenidos de manera jerárquica, incluyendo capítulos y secciones. Su correcta elaboración facilita la navegación y mejora la comprensión del material, convirtiéndolo en un recurso esencial tanto para estudiantes como para profesionales en diversas áreas.... de cohorte a cada transacción
- Calcule el número de clientes únicos en cada grupo.
- Crear una tabla de cohortes para la tasa de retención
- Visualice la tabla de cohortes usando el mapa de calorUn "mapa de calor" es una representación gráfica que utiliza colores para mostrar la densidad de datos en un área específica. Comúnmente utilizado en análisis de datos, marketing y estudios de comportamiento, este tipo de visualización permite identificar patrones y tendencias rápidamente. A través de variaciones cromáticas, los mapas de calor facilitan la interpretación de grandes volúmenes de información, ayudando a la toma de decisiones informadas....
- Interpretar la tasa de retención
¿Qué es el análisis de cohortes y cohortes?
Una cohorte es una colección de usuarios que tienen algo en común. Una cohorte tradicional, por ejemplo, divide a las personas por la semana o el mes en que fueron adquiridas por primera vez. Cuando se hace referencia a agrupaciones no dependientes del tiempo, el término segmento se utiliza a menudo en lugar de cohorte.
El análisis de cohortes es una técnica analíticaLa analítica se refiere al proceso de recopilar, medir y analizar datos para obtener información valiosa que facilite la toma de decisiones. En diversos campos, como los negocios, la salud y el deporte, la analítica permite identificar patrones y tendencias, optimizar procesos y mejorar resultados. El uso de herramientas avanzadas y técnicas estadísticas es fundamental para transformar datos en conocimiento aplicable y estratégico.... descriptiva en el análisis de cohortes. Los clientes se dividen en cohortes mutuamente excluyentes, que luego se rastrean a lo largo del tiempo. Los indicadores de vanidad no ofrecen el mismo nivel de perspectiva que la investigación de cohortes. Ayuda en la interpretación más profunda de patrones de alto nivel al proporcionar métricas sobre el ciclo de vida del producto y del consumidor.
Generalmente, hay tres tipos principales de cohortes:
- Cohortes de tiempo: clientes que se inscribieron en un producto o servicio durante un período de tiempo en particular.
- Cohortes de comportamiento: clientes que compraron un producto o se suscribieron a un servicio en el pasado.
- Cohortes de tamaño: se refieren a los distintos tamaños de clientes que compran los productos o servicios de la empresa.
Sin embargo, estaremos realizando Análisis de cohorte basado en el tiempo. Los clientes se dividirán en cohortes de adquisición según el mes de su primera compra. Luego, el índice de cohorte se asignaría a cada una de las compras del cliente, lo que representará el número de meses desde la primera transacción.
Objetivos:
- Encontrar el porcentaje de clientes activos en comparación con el número total de clientes después de cada mes: Segmentaciones de clientes
- Interpretar la tasa de retención
Aquí está el código completo de este tutorial. si desea seguir la información a medida que avanza en el tutorial.
Paso involucrado en el análisis de la tasa de retención de cohortes
1. Carga y limpieza de datos
2. Asigne la cohorte y calcule la
Paso 2.1
- Truncar el objeto de datos en uno necesario (aquí necesitamos el mes, así que la fecha de la transacción)
- Crear objeto groupby con columna de destino (aquí, customer_id)
- Transforme con una función min () para asignar la fecha de transacción más pequeña en el valor del mes a cada cliente.
El resultado de este proceso es la cohorte del mes de adquisición para cada cliente, es decir, hemos asignado la cohorte del mes de adquisición a cada cliente.
Paso 2.2
- Calcule la compensación de tiempo extrayendo valores enteros del año, mes y día de un objeto datetime ().
- Calcule el número de meses entre cualquier transacción y la primera transacción para cada cliente. Usaremos los valores TransactionMonth y CohortMonth para hacer esto.
El resultado de esto será cohortIndex, es decir, la diferencia entre «TransactionMonth» y «CohortMonth» en términos de la cantidad de meses y llamar a la columna «cohortIndex».
Paso 2.3
- Cree un objeto groupby con CohortMonth y CohortIndex.
- Cuente el número de clientes en cada grupo aplicando la función pandas nunique ().
- Restablezca el índice y cree un pivote de pandas con CohortMonth en las filas, CohortIndex en las columnas y customer_id cuenta como valores.
El resultado de esto será la tabla que servirá de base para calcular la tasa de retención y también otras matrices.
3. Calcular matrices comerciales: Tasa de retención.
La retención mide cuántos clientes de cada cohorte han regresado en los meses siguientes.
- Usando el marco de datos llamado cohort_counts, seleccionaremos las primeras columnas (igual al número total de clientes en cohortes)
- Calcule la proporción de cuántos de estos clientes regresaron en los meses siguientes.
El resultado da una tasa de retención.
4. Visualización de la tasa de retención
5. Interpretación de la tasa de retención
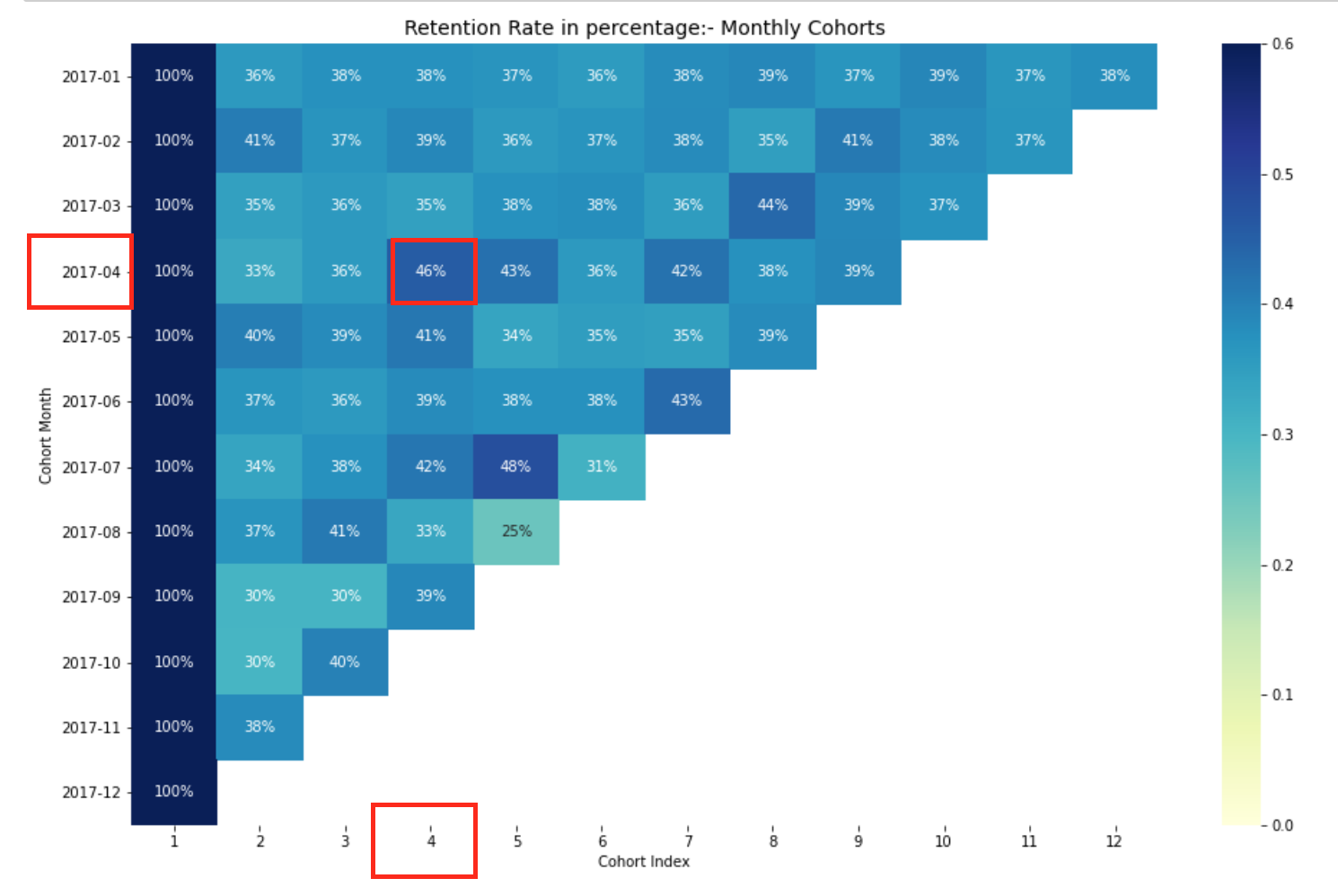
Tasa de retención de cohortes mensuales.
Vamos a empezar:
Importar bibliotecas
import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import numpy as np import datetime as dt import missingno as msno from textwrap import wrap
Carga y limpieza de datos
# Loading dataset
transaction_df = pd.read_excel('transcations.xlsx')
# View data
transaction_df.head()
Comprobando y trabajando con valor faltante
# Inspect missing values in the dataset
print(transaction_df.isnull().values.sum())
# Replace the ' 's with NaN
transaction_df = transaction_df.replace(" ",np.NaN)
# Impute the missing values with mean imputation
transaction_df = transaction_df.fillna(transaction_df.mean())
# Count the number of NaNs in the dataset to verify
print(transaction_df.isnull().values.sum())
print(transaction_df.info())
for col in transaction_df.columns:
# Check if the column is of object type
if transaction_df[col].dtypes == 'object':
# Impute with the most frequent value
transaction_df[col] = transaction_df[col].fillna(transaction_df[col].value_counts().index[0])
# Count the number of NaNs in the dataset and print the counts to verify
print(transaction_df.isnull().values.sum())
Aquí, podemos ver que tenemos 1542 valores nulos. Que tratamos con valores medios y más frecuentes según el tipo de datos. Ahora que hemos completado nuestra limpieza y comprensión de datos, comenzaremos el análisis de cohorte.
Asignó las cohortes y calculó la compensación mensual.
# A function that will parse the date Time based cohort: 1 day of month
def get_month(x): return dt.datetime(x.year, x.month, 1)
# Create transaction_date column based on month and store in TransactionMonth
transaction_df['TransactionMonth'] = transaction_df['transaction_date'].apply(get_month)
# Grouping by customer_id and select the InvoiceMonth value
grouping = transaction_df.groupby('customer_id')['TransactionMonth']
# Assigning a minimum InvoiceMonth value to the dataset
transaction_df['CohortMonth'] = grouping.transform('min')
# printing top 5 rows
print(transaction_df.head())
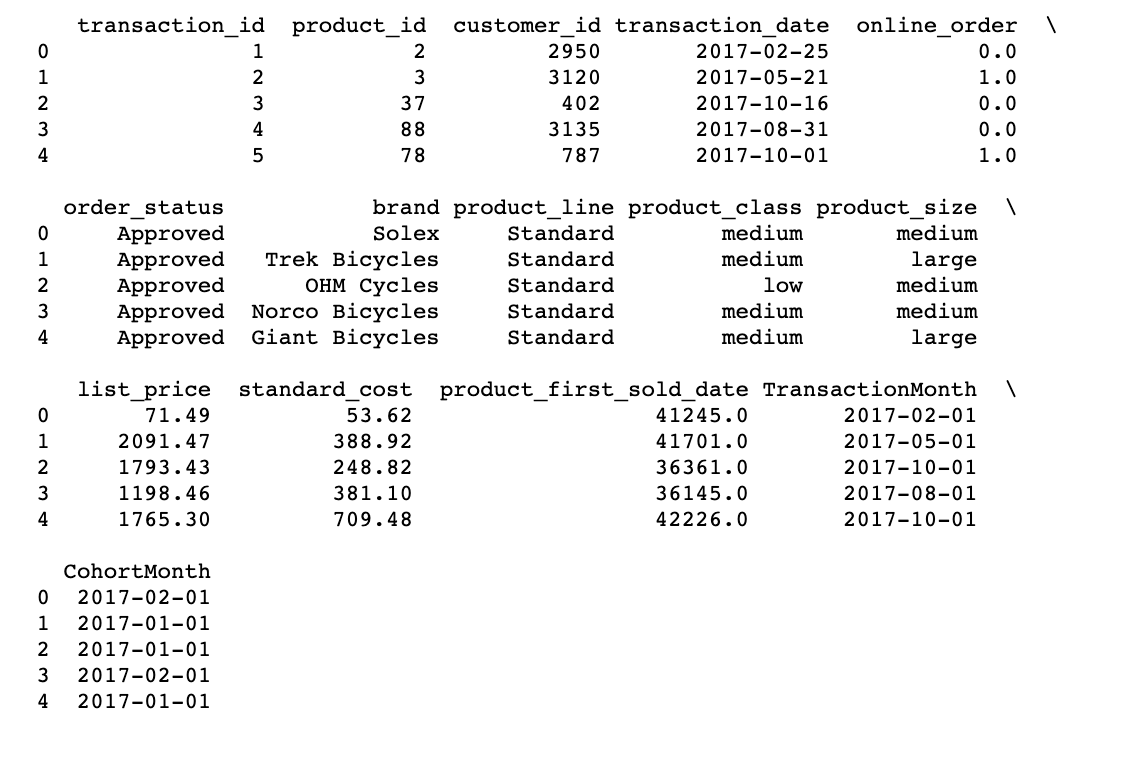
Cálculo de la compensación de tiempo en el mes como índice de cohorte
El cálculo de la compensación de tiempo para cada transacción le permite evaluar las métricas para cada cohorte de una manera comparable.
Primero, crearemos 6 variables que capturen el valor entero de años, meses y días para Transaction y Cohort Date usando la función get_date_int ().
def get_date_int(df, column):
year = df[column].dt.year
month = df[column].dt.month
day = df[column].dt.day
return year, month, day
# Getting the integers for date parts from the `InvoiceDay` column
transcation_year, transaction_month, _ = get_date_int(transaction_df, 'TransactionMonth')
# Getting the integers for date parts from the `CohortDay` column
cohort_year, cohort_month, _ = get_date_int(transaction_df, 'CohortMonth')
Ahora calcularemos la diferencia entre las fechas de factura y las fechas de cohorte en años, meses por separado. luego calcule la diferencia total de meses entre los dos. Este será el índice de cohorte o compensación de nuestro mes, que usaremos en la siguiente sección para calcular la tasa de retención.
# Get the difference in years years_diff = transcation_year - cohort_year # Calculate difference in months months_diff = transaction_month - cohort_month """ Extract the difference in months from all previous values "+1" in addeded at the end so that first month is marked as 1 instead of 0 for easier interpretation. """ transaction_df['CohortIndex'] = years_diff * 12 + months_diff + 1 print(transaction_df.head(5))
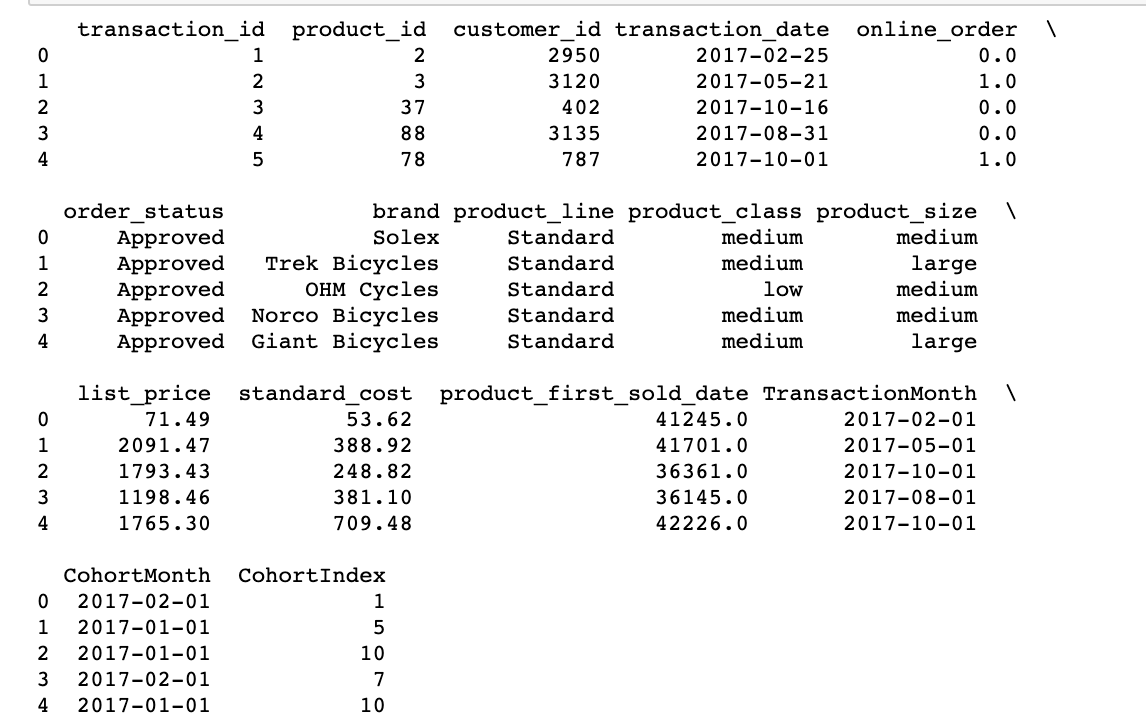
Aquí, al principio, creamos un grupo() objeto con CohortMonth y CohortIndex y guárdelo como una agrupación.
Luego, llamamos a este objeto, seleccionamos el Identificación del cliente columna y calcular el promedio.
Luego almacenamos los resultados como cohort_data. Luego, restablecemos el índice antes de llamar a la función pivote para poder acceder a las columnas ahora almacenadas como índices.
Finalmente, creamos una tabla dinámicaLa tabla dinámica es una herramienta poderosa en programas de hoja de cálculo, como Microsoft Excel y Google Sheets. Permite resumir, analizar y visualizar grandes volúmenes de datos de manera eficiente. A través de su interfaz intuitiva, los usuarios pueden reorganizar la información, aplicar filtros y crear informes personalizados, facilitando la toma de decisiones informadas en diversos contextos, desde el ámbito empresarial hasta la investigación académica.... omitiendo
- CohorteMes al parámetro de índice,
- Índice de cohorte al parámetro de columnas,
- Identificación del cliente al parámetro de valores.
y redondearlo a 1 dígito y ver lo que obtenemos.
# Counting daily active user from each chort
grouping = transaction_df.groupby(['CohortMonth', 'CohortIndex'])
# Counting number of unique customer Id's falling in each group of CohortMonth and CohortIndex
cohort_data = grouping['customer_id'].apply(pd.Series.nunique)
cohort_data = cohort_data.reset_index()
# Assigning column names to the dataframe created above
cohort_counts = cohort_data.pivot(index='CohortMonth',
columns="CohortIndex",
values="customer_id")
# Printing top 5 rows of Dataframe
cohort_data.head()
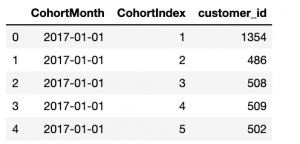
Calcular métricas comerciales: tasa de retención
El porcentaje de clientes activos en comparación con el número total de clientes después de un intervalo de tiempo específico se denomina tasa de retención.
En esta sección, calcularemos el recuento de retención para cada mes de cohorte emparejado con el índice de cohorte
Ahora que tenemos un recuento de los clientes retenidos para cada cohorteMes y cohortIndex. Calcularemos la tasa de retención para cada cohorte.
Crearemos una tabla dinámica para este propósito.
cohort_sizes = cohort_counts.iloc[:,0] retention = cohort_counts.divide(cohort_sizes, axis=0) # Coverting the retention rate into percentage and Rounding off. retention.round(3)*100
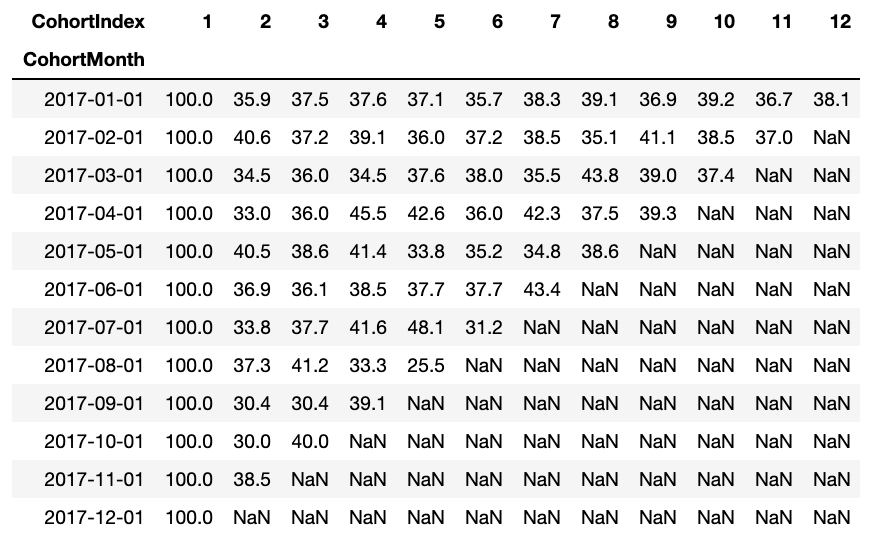
El marco de datos de la tasa de retención representa al Cliente retenido en todas las cohortes. Podemos leerlo de la siguiente manera:
- El valor del índice representa la cohorte
- Las columnas representan el número de meses desde la cohorte actual
Por ejemplo: El valor en CohortMonth 2017-01-01, CohortIndex 3 es 35,9 y representa 35,9% de clientes de la cohorte 2017-01 fueron retenidos en el 3er mes.
Además, puede ver en el DataFrame de tasa de retención:
- Tasa de retención El primer índice, es decir, el primer mes es del 100%, ya que todos los clientes de ese cliente en particular se registraron en el primer mes
- La tasa de retención puede aumentar o disminuir en índices posteriores.
- Los valores hacia la parte inferior derecha tienen muchos valores de NaN.
Visualizando la tasa de retención
Antes de comenzar a trazar nuestro mapa de calor, establezcamos el índice de nuestro marco de datos de tasa de retención en un formato de cadena más legible.
average_standard_cost.index = average_standard_cost.index.strftime('%Y-%m')
# Initialize the figure
plt.figure(figsize=(16, 10))
# Adding a title
plt.title('Average Standard Cost: Monthly Cohorts', fontsize = 14)
# Creating the heatmap
sns.heatmap(average_standard_cost, annot = True,vmin = 0.0, vmax =20,cmap="YlGnBu", fmt="g")
plt.ylabel('Cohort Month')
plt.xlabel('Cohort Index')
plt.yticks( rotation='360')
plt.show()
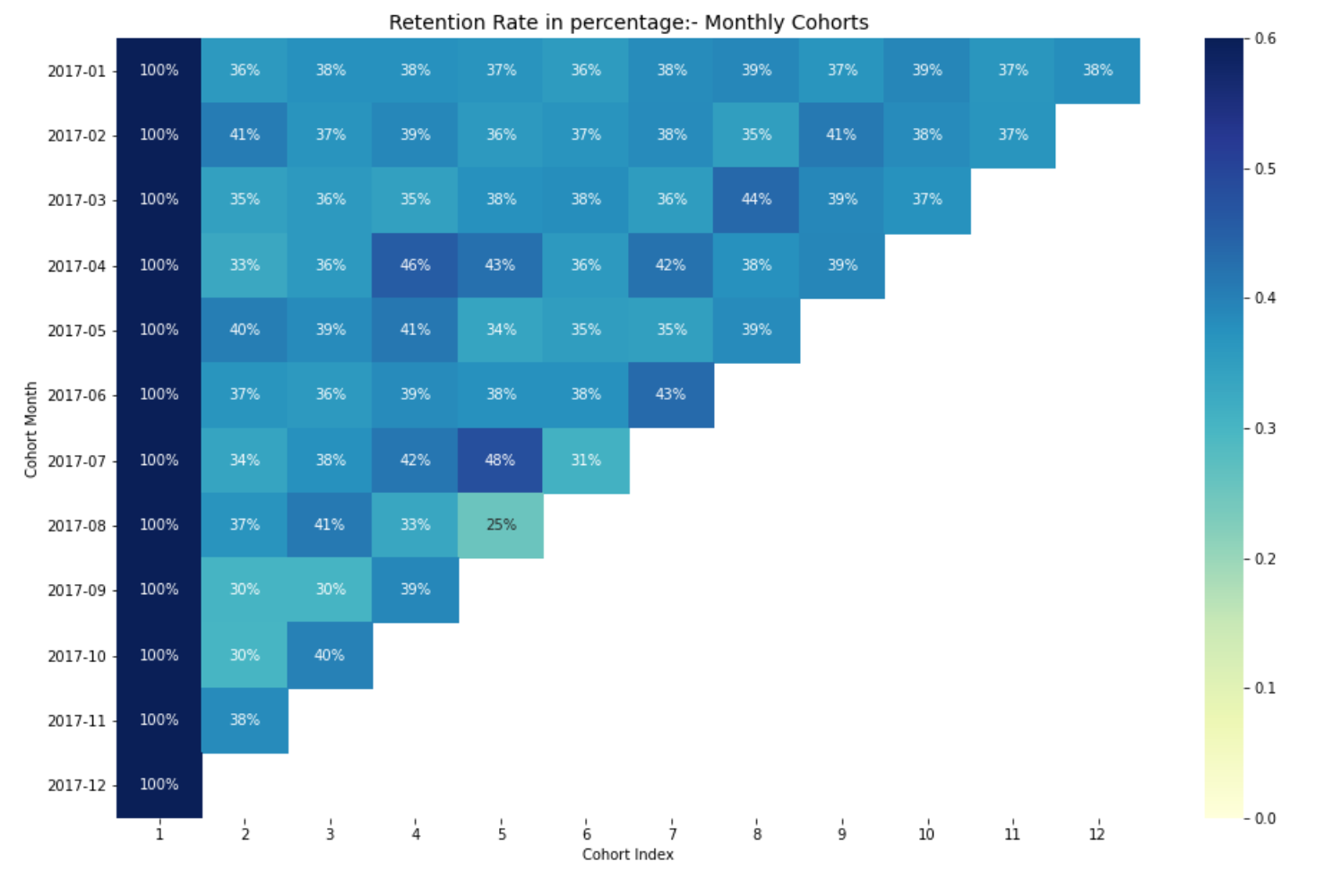
Interpretando la tasa de retención
La forma más eficaz de visualizar y analizar los datos del análisis de cohortes es a través de un mapa de calor, como hicimos anteriormente. Proporciona tanto los valores métricos reales como la codificación de colores para ver las diferencias en los números visualmente.
Si no tiene conocimientos básicos sobre el mapa de calor, puede consultar mi blog. Análisis de datos exploratorios para principiantes con Python, donde he hablado de mapas de calor para principiantes.
Aquí, tenemos 12 cohortes para cada mes y 12 índices de cohortes. Cuanto más oscuros sean los tonos de azul, más altos serán los valores. Así, si vemos en el mes de la cohorte 2017-07 en el 5o índice de cohorte, vemos el tono azul oscuro con un 48% lo que significa que el 48% de las cohortes que firmaron en julio de 2017 estaban activas 5 meses después.
Con esto concluye nuestro análisis de cohorte para la tasa de retención. De manera similar, podemos realizar análisis de cohortes para otras matrices comerciales.
Haga clic aquí para obtener más información sobre el análisis de cohortes para empresas gratis de DataCamp.(Enlace afiliado)
Por lo tanto, completamos nuestro Análisis de cohorte, donde aprendió sobre los análisis básicos y de cohorte, la realización de cohortes de tiempo, el trabajo con pandas pivot y la creación de una tabla de retención junto con la visualización. También aprendimos la forma de explorar otras matrices.
Ahora, puede comenzar a crear y explorar las métricas que son importantes para su negocio por su cuenta.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





