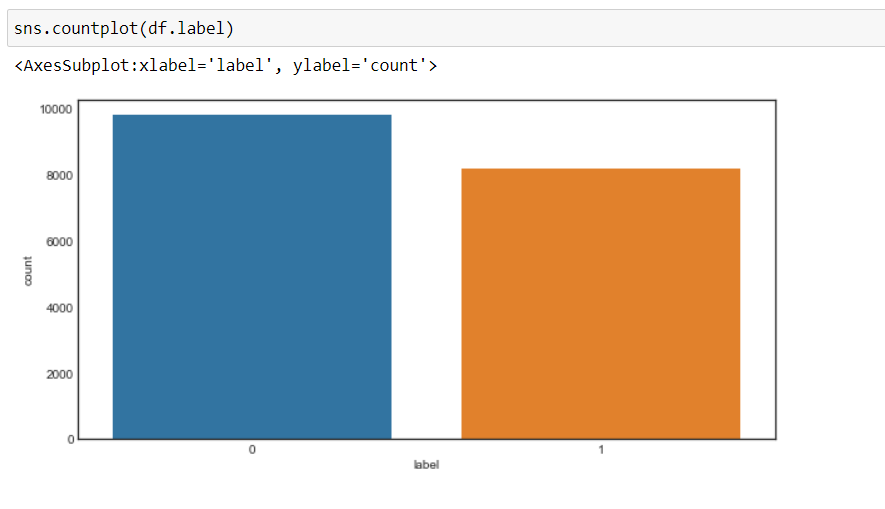
Ahora, podemos ver que nuestro objetivo ha cambiado a 0 y 1, es decir, 0 para negativo y 1 para positivo, y los datos están más o menos en un estado equilibrado.
Preprocesamiento de datos
Ahora, realizaremos un procesamiento previo de los datos antes de convertirlos en vectores y pasarlos al modelo de aprendizaje automático.
Crearemos una función para el preprocesamiento de datos.
1. Primero, iteraremos a través de cada registro y usaremos un expresión regular, eliminaremos cualquier carácter aparte de los alfabetos.
2. Luego, convertiremos la cadena a minúscula como, la palabra «Bien» es diferente de la palabra «bien».
Porque, sin convertir a minúsculas, causará un problema cuando creemos vectores de estas palabras, ya que se crearán dos vectores diferentes para la misma palabra que no queremos.
3. Luego, buscaremos palabras vacías en los datos y las eliminaremos. Para las palabras son palabras de uso común en una oración como «el», «una», «a», etc. que no añaden mucho valor.
4. Luego, realizaremos lematización en cada palabra, es decir, cambiar las diferentes formas de una palabra en un solo elemento llamado lema.
A lema es una forma básica de una palabra. Por ejemplo, «ejecutar», «correr» y «ejecutar» son todas formas del mismo lexema, donde «ejecutar» es el lema. Por lo tanto, estamos convirtiendo todas las apariciones del mismo lexema a su lema respectivo.
5. Y luego devuelva un corpus de datos procesados.
Pero primero crearemos un objeto de WordNetLemmatizer y luego realizaremos la transformación.
#object of WordNetLemmatizer lm = WordNetLemmatizer()
def text_transformation(df_col):
corpus = []
for item in df_col:
new_item = re.sub('[^a-zA-Z]',' ',str(item))
new_item = new_item.lower()
new_item = new_item.split()
new_item = [lm.lemmatize(word) for word in new_item if word not in set(stopwords.words('english'))]
corpus.append(' '.join(str(x) for x in new_item))
return corpus
corpus = text_transformation(df['text'])
Ahora crearemos un Nube de palabras. Es una técnica de visualización de datos que se utiliza para representar texto de tal manera que las palabras más frecuentes aparecen agrandadas en comparación con las palabras menos frecuentes. Esto nos da una pequeña idea de cómo se ven los datos después de ser procesados a través de todos los pasos hasta ahora.
rcParams['figure.figsize'] = 20,8
word_cloud = ""
for row in corpus:
for word in row:
word_cloud+=" ".join(word)
wordcloud = WordCloud(width = 1000, height = 500,background_color="white",min_font_size = 10).generate(word_cloud)
plt.imshow(wordcloud)
Producción:
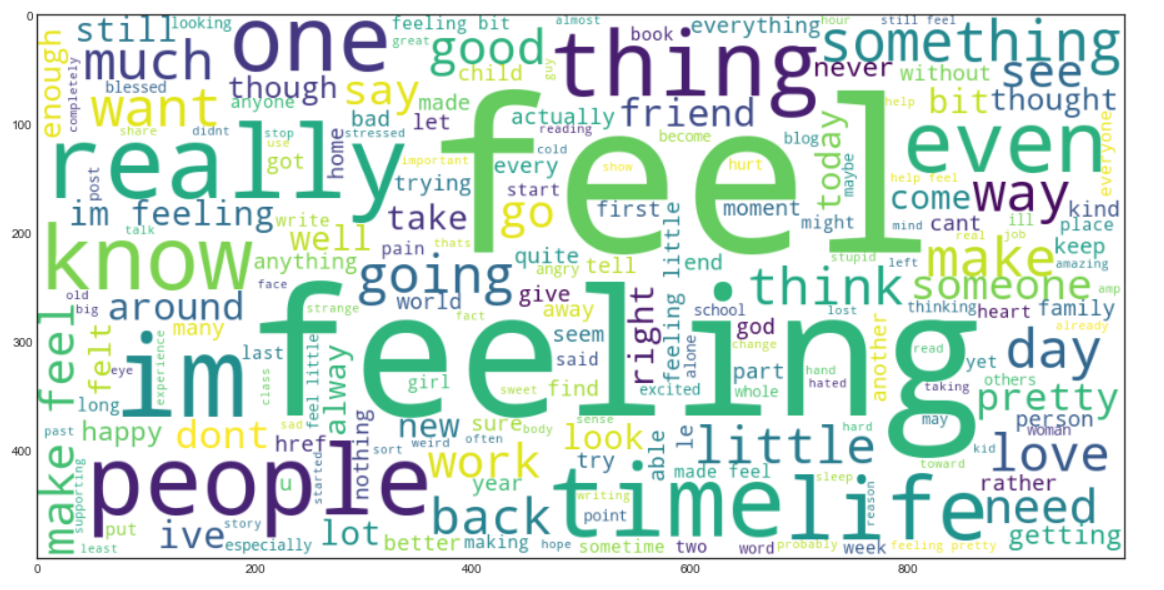
Bolsa de palabras
Ahora, usaremos el Modelo de Bolsa de Palabras (BOW), que se utiliza para representar el texto en forma de bolsa de palabras, es decir, a la gramática y al orden de las palabras en una oración no se le da ninguna importancia, en cambio, la multiplicidad , es decir (el número de veces que aparece una palabra en un documento) es el principal motivo de preocupación.
Básicamente, describe la ocurrencia total de palabras dentro de un documento.
Scikit-Learn proporciona una forma ordenada de realizar la técnica de la bolsa de palabras utilizando CountVectorizer.
Ahora, convertiremos los datos de texto en vectores, ajustando y transformando el corpus que hemos creado.
cv = CountVectorizer(ngram_range=(1,2)) traindata = cv.fit_transform(corpus) X = traindata y = df.label
Nosotros lo tomaremos ngram_range como (1,2) que significa un bigrama.
Ngram es una secuencia de ‘n’ palabras en una fila u oración. ‘ngram_range’ es un parámetro, que usamos para dar importancia a la combinación de palabras, como «social media» tiene un significado diferente a «social» y «media» por separado.
Podemos experimentar con el valor de la ngram_range parámetro y seleccione la opción que dé mejores resultados.
Ahora viene la parte de creación del modelo de aprendizaje automático y en este proyecto, voy a usar Clasificador de bosque aleatorio, y ajustaremos los hiperparámetros usando GridSearchCV.
GridSearchCV() tomará los siguientes parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto....,
1. EstimadorEl "Estimador" es una herramienta estadística utilizada para inferir características de una población a partir de una muestra. Se basa en métodos matemáticos para proporcionar estimaciones precisas y confiables. Existen diferentes tipos de estimadores, como los insesgados y los consistentes, que se eligen según el contexto y el objetivo del estudio. Su correcto uso es fundamental en investigaciones científicas, encuestas y análisis de datos.... o modelo – RandomForestClassifier en nuestro caso
2. parámetros: diccionario de nombres de hiperparámetros y sus valores
3. cv: significa pliegues de validación cruzada
4. return_train_score: devuelve las puntuaciones de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... de los distintos modelos
5. n_jobs – no. de trabajos para ejecutar en paralelo («-1» significa que se utilizarán todos los núcleos de CPU, lo que reduce drásticamente el tiempo de entrenamiento)
Primero, crearemos un diccionario, «parámetros» que contendrá los valores de diferentes hiperparámetros.
Pasaremos esto como un parámetro a GridSearchCV para entrenar nuestro modelo de clasificador de bosque aleatorio usando todas las combinaciones posibles de estos parámetros para encontrar el mejor modelo.
parameters = {'max_features': ('auto','sqrt'),
'n_estimators': [500, 1000, 1500],
'max_depth': [5, 10, None],
'min_samples_split': [5, 10, 15],
'min_samples_leaf': [1, 2, 5, 10],
'bootstrap': [True, False]}
Ahora, ajustaremos los datos en la búsqueda de la cuadrícula y veremos el mejor parámetro usando el atributo «best_params_» de GridSearchCV.
grid_search = GridSearchCV(RandomForestClassifier(),parameters,cv=5,return_train_score=True,n_jobs=-1) grid_search.fit(X,y) grid_search.best_params_
Producción:

Y luego, podemos ver todos los modelos y sus respectivos parámetros, la puntuación media de la prueba y la clasificación, ya que GridSearchCV almacena todos los resultados en el cv_results_ atributo.
for i in range(432):
print('Parameters: ',grid_search.cv_results_['params'][i])
print('Mean Test Score: ',grid_search.cv_results_['mean_test_score'][i])
print('Rank: ',grid_search.cv_results_['rank_test_score'][i])
Salida: (una muestra de la salida)

Ahora, elegiremos los mejores parámetros obtenidos de GridSearchCV y crearemos un modelo de clasificador de bosque aleatorio final y luego entrenaremos nuestro nuevo modelo.
rfc = RandomForestClassifier(max_features=grid_search.best_params_['max_features'],
max_depth=grid_search.best_params_['max_depth'],
n_estimators=grid_search.best_params_['n_estimators'],
min_samples_split=grid_search.best_params_['min_samples_split'],
min_samples_leaf=grid_search.best_params_['min_samples_leaf'],
bootstrap=grid_search.best_params_['bootstrap'])
rfc.fit(X,y)
Transformación de datos de prueba
Ahora, leeremos los datos de prueba y realizaremos las mismas transformaciones que hicimos en los datos de entrenamiento y finalmente evaluaremos el modelo en sus predicciones.
test_df = pd.read_csv('test.txt',delimiter=";",names=['text','label'])
X_test,y_test = test_df.text,test_df.label #encode the labels into two classes , 0 and 1 test_df = custom_encoder(y_test) #pre-processing of text test_corpus = text_transformation(X_test) #convert text data into vectors testdata = cv.transform(test_corpus) #predict the target predictions = rfc.predict(testdata)
Evaluación del modelo
Evaluaremos nuestro modelo usando varias métricas como Accuracy Score, Precision Score, Recall Score, Confusion Matrix y crearemos una curva roc para visualizar cómo se desempeñó nuestro modelo.
rcParams['figure.figsize'] = 10,5
plot_confusion_matrix(y_test,predictions)
acc_score = accuracy_score(y_test,predictions)
pre_score = precision_score(y_test,predictions)
rec_score = recall_score(y_test,predictions)
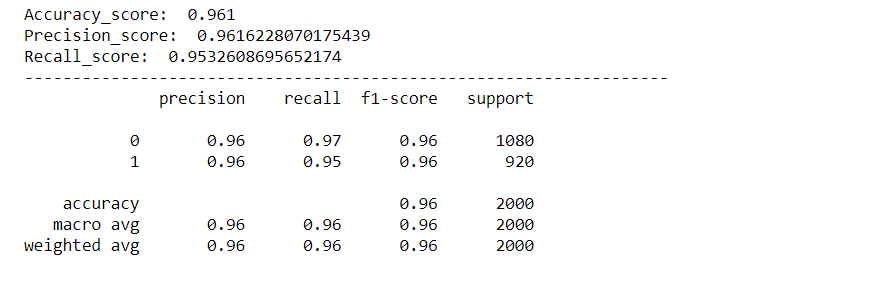
print('Accuracy_score: ',acc_score)
print('Precision_score: ',pre_score)
print('Recall_score: ',rec_score)
print("-"*50)
cr = classification_report(y_test,predictions)
print(cr)
Producción:
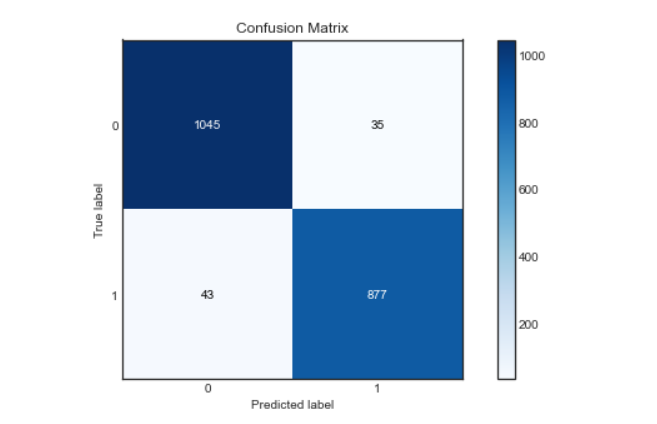
Matriz de confusión:
Curva de Roc:
Encontraremos la probabilidad de la clase usando el método predict_proba () de Random Forest Classifier y luego trazaremos la curva roc.
predictions_probability = rfc.predict_proba(testdata)
fpr,tpr,thresholds = roc_curve(y_test,predictions_probability[:,1])
plt.plot(fpr,tpr)
plt.plot([0,1])
plt.title('ROC Curve')
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Como podemos ver, nuestro modelo funcionó muy bien en la clasificación de los sentimientos, con una puntuación de precisión, precisión y recuperación de aprox. 96%. Y la curva roc y la matriz de confusión también son excelentes, lo que significa que nuestro modelo puede clasificar las etiquetas con precisión, con menos posibilidades de error.
Ahora, también comprobaremos la entrada personalizada y dejaremos que nuestro modelo identifique el sentimiento de la declaración de entrada.
Predecir para entrada personalizada:
def expression_check(prediction_input):
if prediction_input == 0:
print("Input statement has Negative Sentiment.")
elif prediction_input == 1:
print("Input statement has Positive Sentiment.")
else:
print("Invalid Statement.")
# function to take the input statement and perform the same transformations we did earlier
def sentiment_predictor(input):
input = text_transformation(input)
transformed_input = cv.transform(input)
prediction = rfc.predict(transformed_input)
expression_check(prediction)
input1 = ["Sometimes I just want to punch someone in the face."] input2 = ["I bought a new phone and it's so good."]
sentiment_predictor(input1) sentiment_predictor(input2)
Producción:
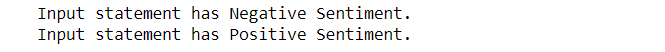
Hurra, ya que podemos ver que nuestro modelo clasificó con precisión los sentimientos detrás de las dos oraciones.
Si te gusta este artículo, sígueme en LinkedIn.
Y puede obtener el código completo y la salida de aquí.
Las imágenes de salida se mantienen aquí para referencia.
El fin?
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.





