Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
El análisis de sentimientos se refiere a identificar y clasificar los sentimientos que se expresan en la fuente del texto. Los tweets suelen ser útiles para generar una gran cantidad de datos de opinión tras el análisis. Estos datos son útiles para comprender la opinión de la gente sobre una variedad de temas.
Por lo tanto, necesitamos desarrollar una Modelo de análisis de sentimiento de aprendizaje automático automatizado para calcular la percepción del cliente. Debido a la presencia de caracteres no útiles (denominados colectivamente como ruido) junto con datos útiles, resulta difícil implementar modelos en ellos.
En este artículo, nuestro objetivo es analizar el sentimiento de los tweets proporcionados desde el Conjunto de datos Sentiment140 mediante el desarrollo de una canalización de aprendizaje automático que implica el uso de tres clasificadores (Regresión logística, Bernoulli Naive Bayes y SVM) junto con el uso Término Frecuencia – Frecuencia inversa del documento (TF-IDF). El desempeño de estos clasificadores luego se evalúa usando precisión y Puntuaciones F1.

Fuente de la imagen: imágenes de Google
Planteamiento del problema
En este proyecto, intentamos implementar un Modelo de análisis de sentimiento de Twitter que ayuda a superar los desafíos de identificar los sentimientos de los tweets. Los detalles necesarios con respecto al conjunto de datos son:
El conjunto de datos proporcionado es el Conjunto de datos Sentiment140 que consiste en 1,600,000 tweets que se han extraído mediante la API de Twitter. Las diversas columnas presentes en el conjunto de datos son:
- objetivo: la polaridad del tweet (positiva o negativa)
- identificadores: Identificación única del tweet
- fecha: la fecha del tweet
- bandera: Se refiere a la consulta. Si no existe tal consulta, entonces NO ES CONSULTA.
- usuario: Se refiere al nombre del usuario que tuiteó.
- texto: Se refiere al texto del tweet.
Canalización del proyecto
Los diversos pasos involucrados en el Canalización de aprendizaje automático están :
- Importar dependencias necesarias
- Leer y cargar el conjunto de datos
- Análisis exploratorio de datos
- Visualización de datos de variables objetivo
- Preprocesamiento de datos
- Dividir nuestros datos en subconjuntos de entrenamientoEl entrenamiento es un proceso sistemático diseñado para mejorar habilidades, conocimientos o capacidades físicas. Se aplica en diversas áreas, como el deporte, la educación y el desarrollo profesional. Un programa de entrenamiento efectivo incluye la planificación de objetivos, la práctica regular y la evaluación del progreso. La adaptación a las necesidades individuales y la motivación son factores clave para lograr resultados exitosos y sostenibles en cualquier disciplina.... y prueba
- Transformar el conjunto de datos usando TF-IDF Vectorizer
- Función para la evaluación del modelo
- Construcción del modelo
- Conclusión
Empecemos,
Paso 1: importar las dependencias necesarias
# utilities
import re
import numpy as np
import pandas as pd
# plotting
import seaborn as sns
from wordcloud import WordCloud
import matplotlib.pyplot as plt
# nltk
from nltk.stem import WordNetLemmatizer
# sklearn
from sklearn.svm import LinearSVC
from sklearn.naive_bayes import BernoulliNB
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import confusion_matrix, classification_report
Paso 2: leer y cargar el conjunto de datos
# Importing the dataset
DATASET_COLUMNS=['target','ids','date','flag','user','text']
DATASET_ENCODING = "ISO-8859-1"
df = pd.read_csv('Project_Data.csv', encoding=DATASET_ENCODING, names=DATASET_COLUMNS)
df.sample(5)
Producción:

Paso 3: Análisis de datos exploratorios
3.1: Cinco registros principales de datos
df.head()
Producción:

3.2: Columnas / características en los datos
df.columns
Producción:
Index(['target', 'ids', 'date', 'flag', 'user', 'text'], dtype="object")
3.3: Longitud del conjunto de datos
print('length of data is', len(df))
Producción:
length of data is 1048576
3.4: Forma de los datos
df. shape
Producción:
(1048576, 6)
3.5: Información de datos
df.info()
Producción:

3.6: Tipos de datos de todas las columnas
df.dtypes
Producción:
target int64 ids int64 date object flag object user object text object dtype: object
3.7: Comprobación de valores nulos
np.sum(df.isnull().any(axis=1))
Producción:
0
3.8: Filas y columnas en el conjunto de datos
print('Count of columns in the data is: ', len(df.columns))
print('Count of rows in the data is: ', len(df))
Producción:
Count of columns in the data is: 6 Count of rows in the data is: 1048576
3.9: Verifique valores objetivo únicos
df['target'].unique()
Producción:
array([0, 4], dtype=int64)
3.10: Verifique el número de valores objetivo
df['target'].nunique()
Producción:
2
Paso 4: Visualización de datos de variables de destino
# Plotting the distribution for dataset.
ax = df.groupby('target').count().plot(kind='bar', title="Distribution of data",legend=False)
ax.set_xticklabels(['Negative','Positive'], rotation=0)
# Storing data in lists.
text, sentiment = list(df['text']), list(df['target'])
Producción:

import seaborn as sns
sns.countplot(x='target', data=df)
Producción:

Paso 5: preprocesamiento de datos
En la declaración del problema anterior antes de entrenar el modelo, hemos realizado varios pasos de preprocesamiento en el conjunto de datos que se ocuparon principalmente de eliminar palabras vacías, eliminar emojis. Luego, el documento de texto se convierte a minúsculas para una mejor generalización.
Posteriormente, las puntuaciones se limpiaron y eliminaron, reduciendo así el ruido innecesario del conjunto de datos. Después de eso, también hemos eliminado los caracteres repetidos de las palabras junto con la eliminación de las URL, ya que no tienen ninguna importancia significativa.
Por fin, realizamos Stemming (reduciendo las palabras a sus raíces derivadas) y Lematización (reduciendo las palabras derivadas a su forma raíz conocida como lema) para obtener mejores resultados.
5.1: Seleccionar el texto y la columna de destino para nuestro análisis posterior
data=df[['text','target']]
5.2: Reemplazo de los valores para facilitar la comprensión. (Asignando 1 al sentimiento positivo 4)
data['target'] = data['target'].replace(4,1)
5.3: Imprimir valores únicos de variables de destino
data['target'].unique()
Producción:
array([0, 1], dtype=int64)
5.4: Separación de tweets positivos y negativos
data_pos = data[data['target'] == 1] data_neg = data[data['target'] == 0]
5.5: tomando un cuarto de datos para que podamos ejecutar en nuestra máquina fácilmente
data_pos = data_pos.iloc[:int(20000)] data_neg = data_neg.iloc[:int(20000)]
5.6: Combinando tweets positivos y negativos
dataset = pd.concat([data_pos, data_neg])
5.7: Hacer el texto de la declaración en minúsculas
dataset['text']=dataset['text'].str.lower() dataset['text'].tail()
Producción:

5.8: Conjunto de definición que contiene todas las palabras vacías en inglés.
stopwordlist = ['a', 'about', 'above', 'after', 'again', 'ain', 'all', 'am', 'an',
'and','any','are', 'as', 'at', 'be', 'because', 'been', 'before',
'being', 'below', 'between','both', 'by', 'can', 'd', 'did', 'do',
'does', 'doing', 'down', 'during', 'each','few', 'for', 'from',
'further', 'had', 'has', 'have', 'having', 'he', 'her', 'here',
'hers', 'herself', 'him', 'himself', 'his', 'how', 'i', 'if', 'in',
'into','is', 'it', 'its', 'itself', 'just', 'll', 'm', 'ma',
'me', 'more', 'most','my', 'myself', 'now', 'o', 'of', 'on', 'once',
'only', 'or', 'other', 'our', 'ours','ourselves', 'out', 'own', 're','s', 'same', 'she', "shes", 'should', "shouldve",'so', 'some', 'such',
't', 'than', 'that', "thatll", 'the', 'their', 'theirs', 'them',
'themselves', 'then', 'there', 'these', 'they', 'this', 'those',
'through', 'to', 'too','under', 'until', 'up', 've', 'very', 'was',
'we', 'were', 'what', 'when', 'where','which','while', 'who', 'whom',
'why', 'will', 'with', 'won', 'y', 'you', "youd","youll", "youre",
"youve", 'your', 'yours', 'yourself', 'yourselves']
5.9: Limpiar y eliminar la lista de palabras vacías anterior del texto del tweet
STOPWORDS = set(stopwordlist)
def cleaning_stopwords(text):
return " ".join([word for word in str(text).split() if word not in STOPWORDS])
dataset['text'] = dataset['text'].apply(lambda text: cleaning_stopwords(text))
dataset['text'].head()
Producción:

5.10: Limpieza y eliminación de puntuaciones
import string
english_punctuations = string.punctuation
punctuations_list = english_punctuations
def cleaning_punctuations(text):
translator = str.maketrans('', '', punctuations_list)
return text.translate(translator)
dataset['text']= dataset['text'].apply(lambda x: cleaning_punctuations(x))
dataset['text'].tail()
Producción:

5.11: Limpieza y eliminación de caracteres repetidos
def cleaning_repeating_char(text):
return re.sub(r'(.)1+', r'1', text)
dataset['text'] = dataset['text'].apply(lambda x: cleaning_repeating_char(x))
dataset['text'].tail()
Producción:

5.12: Limpieza y eliminación de URL
def cleaning_URLs(data):
return re.sub('((www.[^s]+)|(https?://[^s]+))',' ',data)
dataset['text'] = dataset['text'].apply(lambda x: cleaning_URLs(x))
dataset['text'].tail()
Producción:

5.13: Limpieza y eliminación de números numéricos
def cleaning_numbers(data):
return re.sub('[0-9]+', '', data)
dataset['text'] = dataset['text'].apply(lambda x: cleaning_numbers(x))
dataset['text'].tail()
Producción:

5.14: Obtención de tokenización del texto del tweet
from nltk.tokenize import RegexpTokenizer tokenizer = RegexpTokenizer(r'w+') dataset['text'] = dataset['text'].apply(tokenizer.tokenize) dataset['text'].head()
Producción:

5.15: Aplicación de la derivación
import nltk
st = nltk.PorterStemmer()
def stemming_on_text(data):
text = [st.stem(word) for word in data]
return data
dataset['text']= dataset['text'].apply(lambda x: stemming_on_text(x))
dataset['text'].head()
Producción:

5.16: Aplicación de Lemmatizer
lm = nltk.WordNetLemmatizer()
def lemmatizer_on_text(data):
text = [lm.lemmatize(word) for word in data]
return data
dataset['text'] = dataset['text'].apply(lambda x: lemmatizer_on_text(x))
dataset['text'].head()
Producción:

5.17: Separación de la función de entrada y la etiqueta
X=data.text y=data.target
5.18: trazar una nube de palabras para tweets negativos
data_neg = data['text'][:800000]
plt.figure(figsize = (20,20))
wc = WordCloud(max_words = 1000 , width = 1600 , height = 800,
collocations=False).generate(" ".join(data_neg))
plt.imshow(wc)
Producción:
5.19: trazar una nube de palabras para tweets positivos
data_pos = data['text'][800000:]
wc = WordCloud(max_words = 1000 , width = 1600 , height = 800,
collocations=False).generate(" ".join(data_pos))
plt.figure(figsize = (20,20))
plt.imshow(wc)
Producción:
Paso 6: Dividir nuestros datos en subconjuntos de entrenamiento y prueba
# Separating the 95% data for training data and 5% for testing data X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.05, random_state =26105111)
Paso 7: Transformar el conjunto de datos usando TF-IDF Vectorizer
7.1: Instale el vectorizador TF-IDF
vectoriser = TfidfVectorizer(ngram_range=(1,2), max_features=500000)
vectoriser.fit(X_train)
print('No. of feature_words: ', len(vectoriser.get_feature_names()))
Producción:
No. of feature_words: 500000
7.2: Transformar los datos usando TF-IDF Vectorizer
X_train = vectoriser.transform(X_train) X_test = vectoriser.transform(X_test)
Paso 8: Función para la evaluación del modelo
Después de entrenar el modelo, aplicamos las medidas de evaluación para comprobar el rendimiento del modelo. En consecuencia, utilizamos los siguientes parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... de evaluación para verificar el rendimiento de los modelos respectivamente:
- Puntuación de precisión
- Matriz de confusión con trama
- Curva ROC-AUC
def model_Evaluate(model):
# Predict values for Test dataset
y_pred = model.predict(X_test)
# Print the evaluation metrics for the dataset.
print(classification_report(y_test, y_pred))
# Compute and plot the Confusion matrix
cf_matrix = confusion_matrix(y_test, y_pred)
categories = ['Negative','Positive']
group_names = ['True Neg','False Pos', 'False Neg','True Pos']
group_percentages = ['{0:.2%}'.format(value) for value in cf_matrix.flatten() / np.sum(cf_matrix)]
labels = [f'{v1}n{v2}' for v1, v2 in zip(group_names,group_percentages)]
labels = np.asarray(labels).reshape(2,2)
sns.heatmap(cf_matrix, annot = labels, cmap = 'Blues',fmt="",
xticklabels = categories, yticklabels = categories)
plt.xlabel("Predicted values", fontdict = {'size':14}, labelpad = 10)
plt.ylabel("Actual values" , fontdict = {'size':14}, labelpad = 10)
plt.title ("Confusion Matrix", fontdict = {'size':18}, pad = 20)
Paso 9: Construcción de modelos
En el planteamiento del problema hemos utilizado tres modelos diferentes respectivamente:
- Bernoulli ingenuo Bayes
- SVM (máquina de vectores de soporte)
- Regresión logística
La idea detrás de la elección de estos modelos es que queremos probar todos los clasificadores en el conjunto de datos, desde los simples hasta los modelos complejos, y luego tratar de encontrar el que ofrece el mejor rendimiento entre ellos.
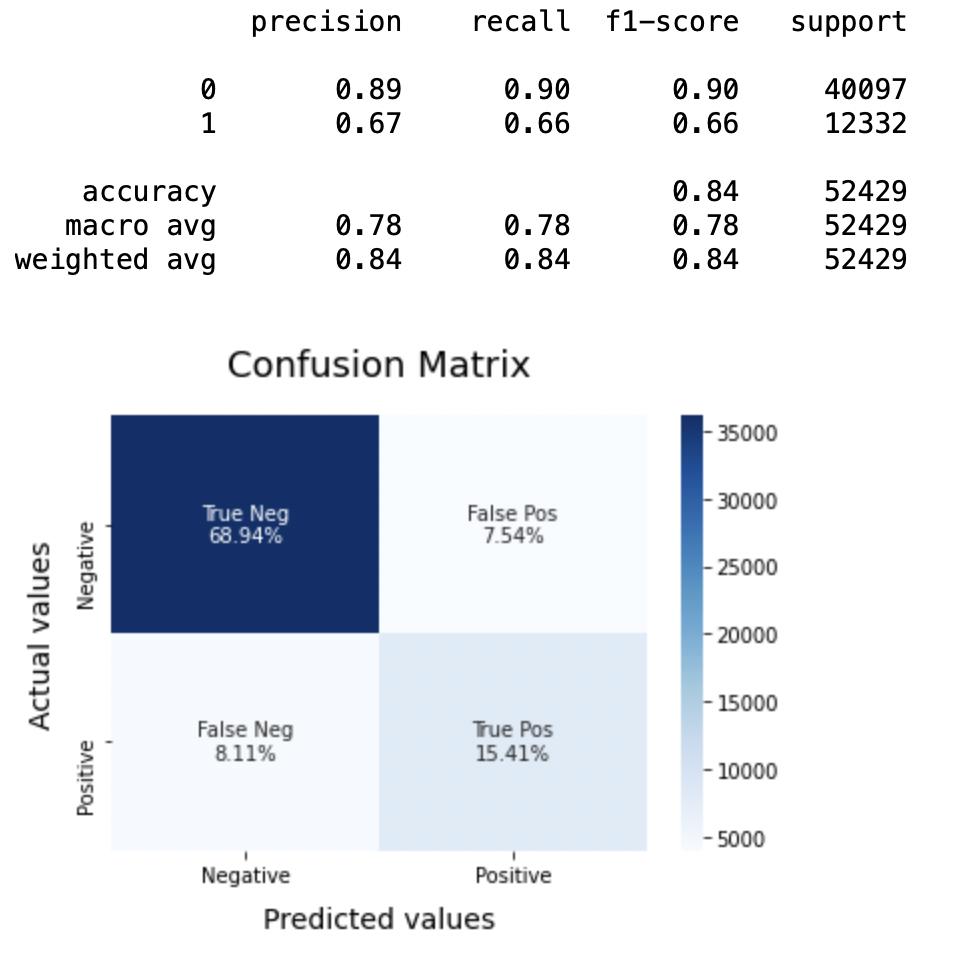
8.1: Modelo-1
BNBmodel = BernoulliNB() BNBmodel.fit(X_train, y_train) model_Evaluate(BNBmodel) y_pred1 = BNBmodel.predict(X_test)
Producción:
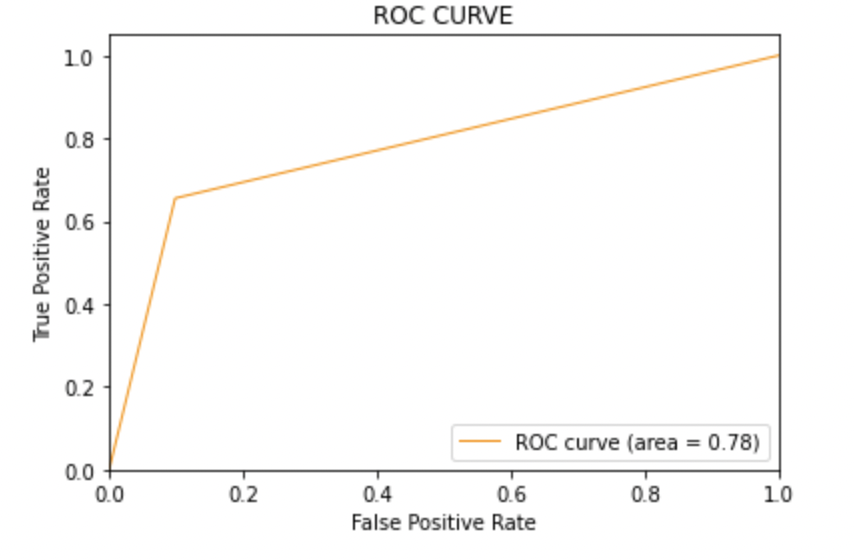
8.2: Trace la curva ROC-AUC para el modelo 1
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_test, y_pred1)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color="darkorange", lw=1, label="ROC curve (area = %0.2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC CURVE')
plt.legend(loc="lower right")
plt.show()
Producción:
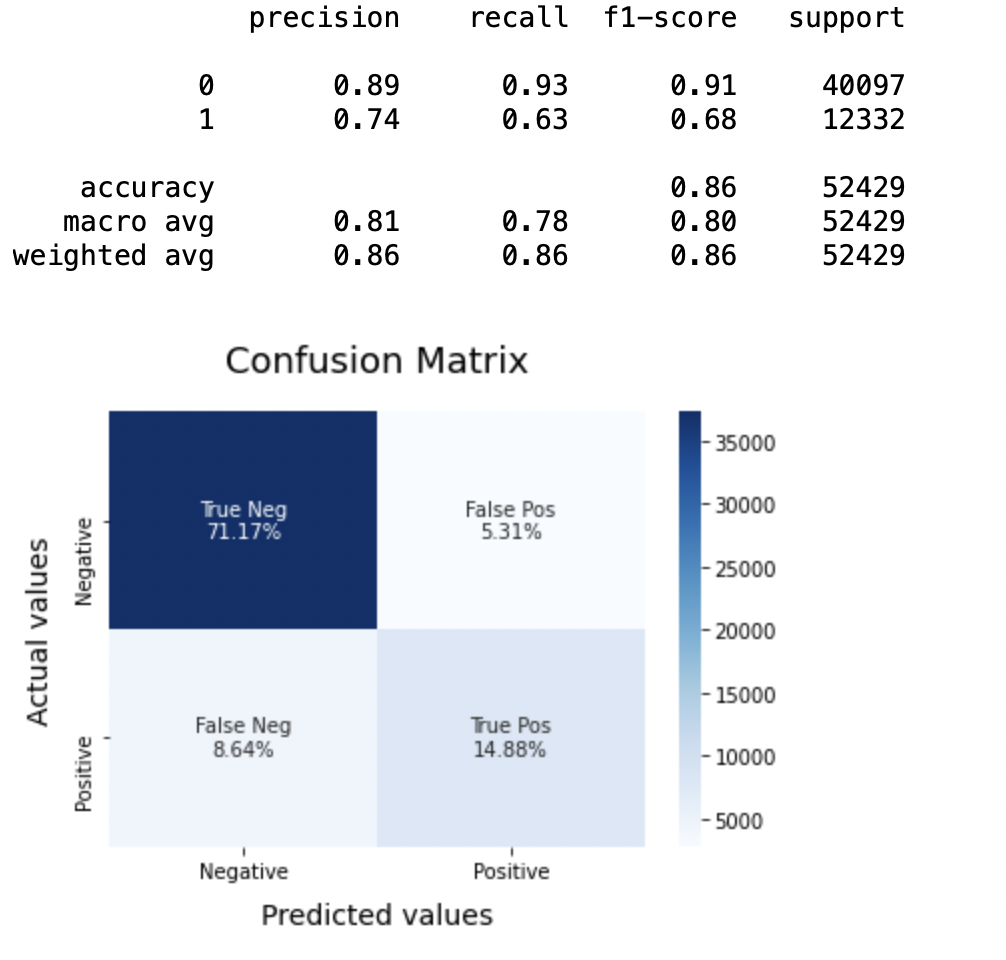
8.3: Modelo-2:
SVCmodel = LinearSVC() SVCmodel.fit(X_train, y_train) model_Evaluate(SVCmodel) y_pred2 = SVCmodel.predict(X_test)
Producción:
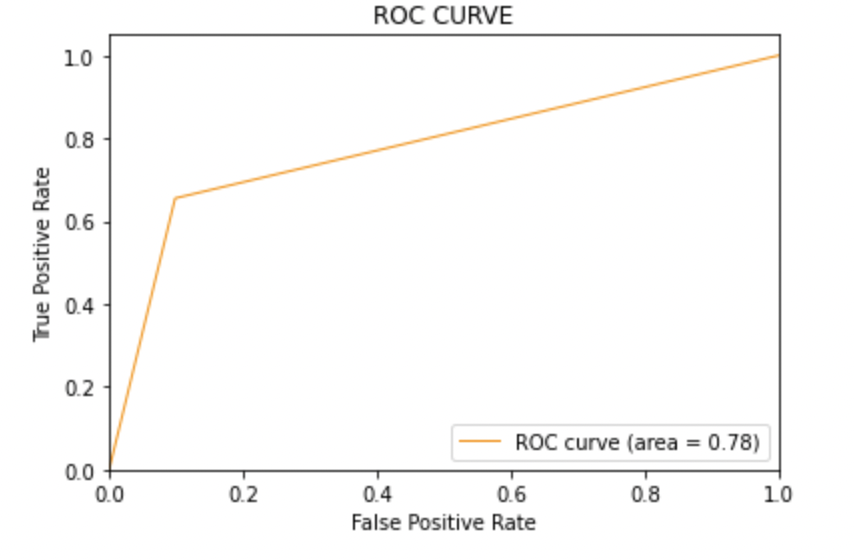
8.4: Trace la curva ROC-AUC para el modelo 2
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_test, y_pred2)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color="darkorange", lw=1, label="ROC curve (area = %0.2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC CURVE')
plt.legend(loc="lower right")
plt.show()
Producción:
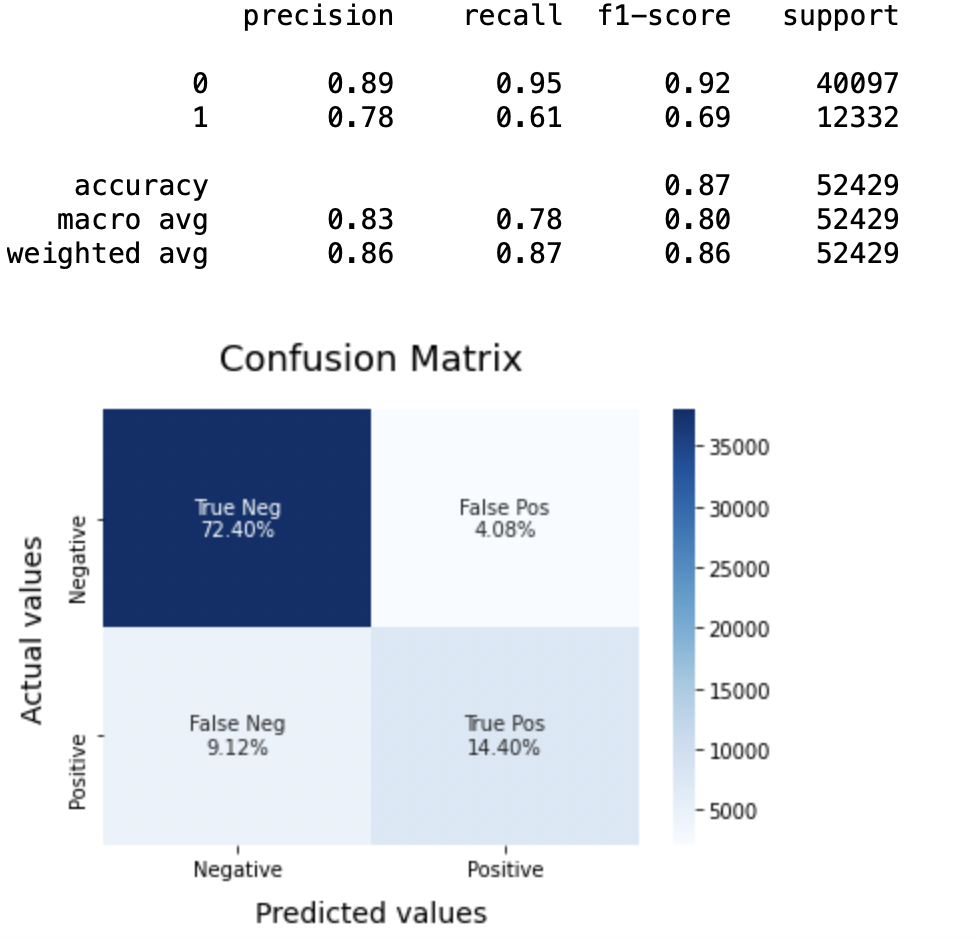
8.5: Modelo-3
LRmodel = LogisticRegression(C = 2, max_iter = 1000, n_jobs=-1) LRmodel.fit(X_train, y_train) model_Evaluate(LRmodel) y_pred3 = LRmodel.predict(X_test)
Producción:
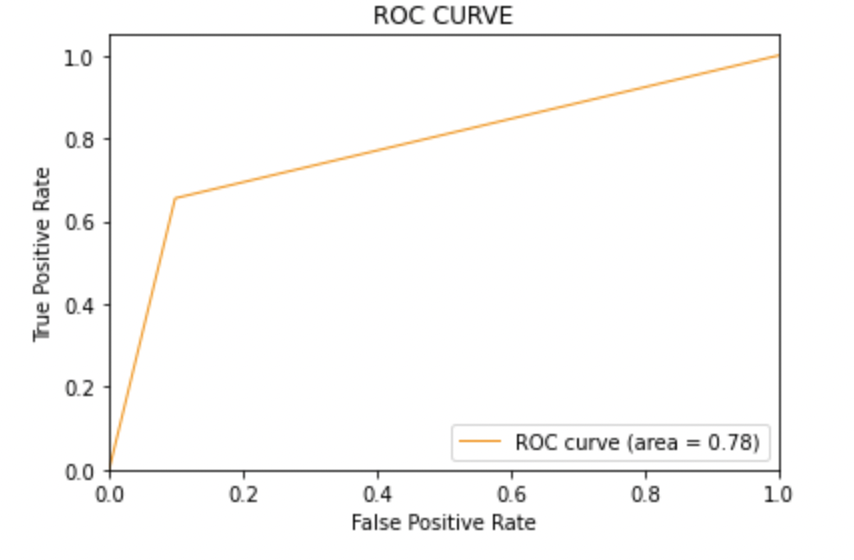
8.6: Trace la curva ROC-AUC para el modelo 3
from sklearn.metrics import roc_curve, auc
fpr, tpr, thresholds = roc_curve(y_test, y_pred3)
roc_auc = auc(fpr, tpr)
plt.figure()
plt.plot(fpr, tpr, color="darkorange", lw=1, label="ROC curve (area = %0.2f)" % roc_auc)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('ROC CURVE')
plt.legend(loc="lower right")
plt.show()
Producción:
Paso 10: Conclusión
Al evaluar todos los modelos podemos concluir los siguientes detalles es decir
Precisión: En lo que respecta a la precisión del modelo, la regresión logística funciona mejor que SVM, que a su vez funciona mejor que Bernoulli Naive Bayes.
Puntuación F1: Las puntuaciones F1 para la clase 0 y la clase 1 son:
(a) Para la clase 0: Bernoulli Naive Bayes (precisión = 0,90) <SVM (precisión = 0,91) <Regresión logística (precisión = 0,92)
(b) Para la clase 1: Bernoulli Naive Bayes (precisión = 0,66) <SVM (precisión = 0,68) <Regresión logística (precisión = 0,69)
Puntaje AUC: Los tres modelos tienen la misma puntuación ROC-AUC.
Por lo tanto, llegamos a la conclusión de que la regresión logística es el mejor modelo para el conjunto de datos anterior.
En nuestra declaración de problema, Regresión logística está siguiendo el principio de La navaja de Occam que define que para un enunciado de problema en particular, si los datos no tienen suposiciones, entonces el modelo más simple funciona mejor. Dado que nuestro conjunto de datos no tiene suposiciones y la Regresión logística es un modelo simple, el concepto es válido para el conjunto de datos mencionado anteriormente.
Notas finales
Espero que hayas disfrutado el artículo.
Si quieres conectarte conmigo, no dudes en ponerte en contacto conmigo. sobre Correo electrónico
Tus sugerencias y dudas son bienvenidas aquí en la sección de comentarios. ¡Gracias por leer mi artículo!
Los medios que se muestran en este artículo no son propiedad de Analytics Vidhya y se utilizan a discreción del autor.





