Este artículo fue publicado como parte del Blogatón de ciencia de datos
Introducción
El objetivo final de este blog es predecir el sentimiento de un texto dado usando python, donde usamos NLTK, también conocido como Natural Language Processing Toolkit, un paquete en Python creado especialmente para el análisis basado en texto. Entonces, con unas pocas líneas de código, podemos predecir fácilmente si una oración o una reseña (utilizada en el blog) es una reseña positiva o negativa.
Antes de pasar directamente a la implementación, permítame brevemente los pasos involucrados para tener una idea del enfoque de análisis. Estos son a saber:
1. Importación de módulos necesarios
2. Importación de conjunto de datos
3. Preprocesamiento y visualización de datos
4. Construcción de modelos
5. Predicción
Así que vamos a centrarnos en cada paso en detalle.
1. Importación de módulos necesarios:
Entonces, como todos sabemos, es necesario importar todos los módulos que vamos a utilizar inicialmente. Así que hagámoslo como el primer paso de nuestra práctica.
import numpy as np #linear algebra import pandas as pd # data processing, CSV file I/O (e.g. pd.read_csv) import matplotlib.pyplot as plt #For Visualisation %matplotlib inline import seaborn as sns #For better Visualisation from bs4 import BeautifulSoup #For Text Parsing
Aquí estamos importando todos los módulos de importación básicos necesarios, a saber, numpy, pandas, matplotlib, seaborn y beautiful soup, cada uno con su propio caso de uso. Aunque vamos a utilizar algunos otros módulos, excluyéndolos, vamos a entenderlos mientras los usamos.
2. Importación de conjunto de datos:
De hecho, había descargado el conjunto de datos de Kaggle hace bastante tiempo, por lo que no tengo el enlace al conjunto de datos. Entonces, para obtener el conjunto de datos y el código, colocaré el enlace del repositorio de Github para que todos tengan acceso a él. Ahora, para importar el conjunto de datos, tenemos que usar el método pandas ‘read_csv’ seguido de la ruta del archivo.
data = pd.read_csv('Reviews.csv')
Si imprimimos el conjunto de datos, podríamos ver que hay ‘568454 filas × 10 columnas’, que es bastante grande.
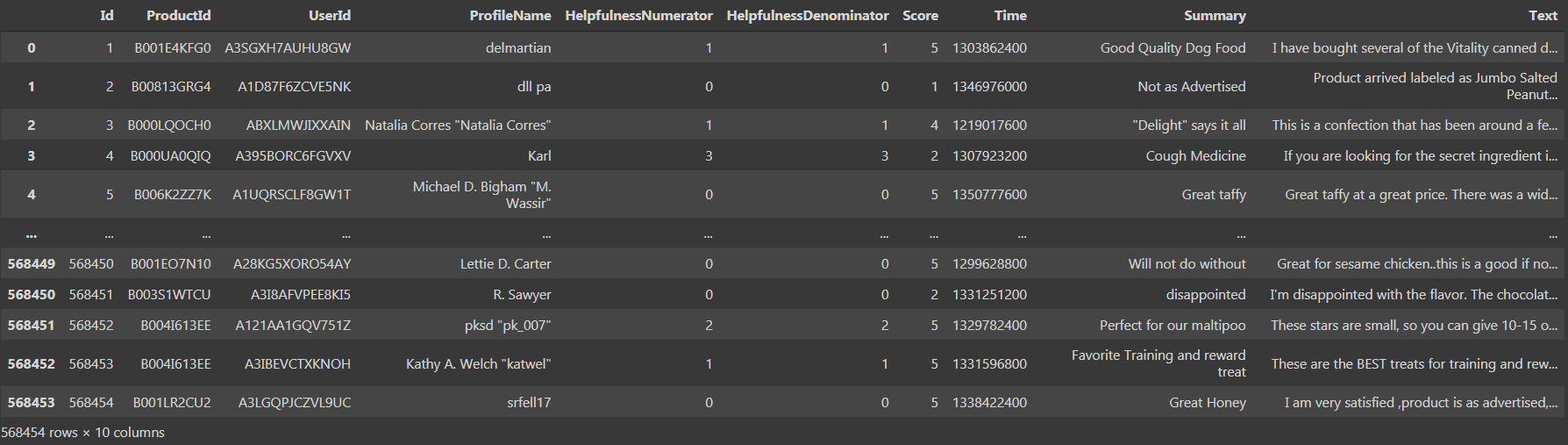
Vemos que hay 10 columnas, a saber, ‘Id’, ‘Numerador de utilidad’, ‘Denominador de utilidad’, ‘Puntaje’ y ‘Tiempo’ como tipo de datos int64 y ‘ProductId’, ‘UserId’, ‘ProfileName’, ‘Resumen’, ‘Texto’ como tipo de datos de objeto. Ahora pasemos al tercer paso, es decir, preprocesamiento y visualización de datos.
3. Preprocesamiento y visualización de datos:
Ahora tenemos acceso a los datos y luego los limpiamos. Usando el método ‘isnull (). Sum ()’ podríamos encontrar fácilmente el número total de valores faltantes en el conjunto de datos.
data.isnull().sum()
Si ejecutamos el código anterior como una celda, encontramos que hay 16 y 27 valores nulos en las columnas ‘ProfileName’ y ‘Summary’ respectivamente. Ahora, tenemos que reemplazar los valores nulos con la tendencia central o eliminar las respectivas filas que contienen los valores nulos. Con una cantidad tan grande de filas, la eliminación de solo 43 filas que contienen los valores nulos no afectaría la precisión general del modelo. Por lo tanto, es aconsejable eliminar las 43 filas utilizando el método ‘dropna’.
data = data.dropna()
Ahora, he actualizado el marco de datos antiguo en lugar de crear una nueva variableEn estadística y matemáticas, una "variable" es un símbolo que representa un valor que puede cambiar o variar. Existen diferentes tipos de variables, como las cualitativas, que describen características no numéricas, y las cuantitativas, que representan cantidades numéricas. Las variables son fundamentales en experimentos y estudios, ya que permiten analizar relaciones y patrones entre diferentes elementos, facilitando la comprensión de fenómenos complejos.... y almacenar el nuevo marco de datos con los valores limpios. Ahora, de nuevo, cuando comprobamos el marco de datos, encontramos que hay 568411 filas y las mismas 10 columnas, lo que significa que las 43 filas que tenían los valores nulos se han eliminado y ahora se limpia nuestro conjunto de datos. Continuando, tenemos que hacer un preprocesamiento de los datos de tal manera que el modelo los pueda usar directamente.
Para preprocesar, usamos la columna ‘Puntaje’ en el marco de datos para tener puntajes que van de ‘1’ a ‘5’, donde ‘1’ significa una revisión negativa y ‘5’ significa una revisión positiva. Pero es mejor tener la puntuación inicialmente en un rango de ‘0’ a ‘2’ donde ‘0’ significa una revisión negativa, ‘1’ significa una revisión neutral y ‘2’ significa una revisión positiva. Es similar a la codificación en Python, pero aquí no usamos ninguna función incorporada, pero ejecutamos explícitamente un bucle for where"WHERE" es un término en inglés que se traduce como "dónde" en español. Se utiliza para hacer preguntas sobre la ubicación de personas, objetos o eventos. En contextos gramaticales, puede funcionar como adverbio de lugar y es fundamental en la formación de preguntas. Su correcta aplicación es esencial en la comunicación cotidiana y en la enseñanza de idiomas, facilitando la comprensión y el intercambio de información sobre posiciones y direcciones.... y creamos una nueva lista y agregamos los valores a la lista.
a=[]
for i in data['Score']:
if i <3:
a.append(0)
if i==3:
a.append(1)
if i>3:
a.append(2)
Suponiendo que la ‘Puntuación’ se encuentra en el rango de ‘0’ a ‘2’, las consideramos críticas negativas y las agregamos a la lista con una puntuación de ‘0’, que significa revisión negativa. Ahora, si graficamos los valores de las puntuaciones presentes en la lista ‘a’ como la nomenclatura utilizada anteriormente, encontramos que hay 82007 revisiones negativas, 42638 revisiones neutrales y 443766 revisiones positivas. Podemos encontrar claramente que aproximadamente el 85% de las revisiones en el conjunto de datos tienen revisiones positivas y el resto son revisiones negativas o neutrales. Esto podría visualizarse y entenderse más claramente con la ayuda de una trama de conteo en la biblioteca de seaborn.
sns.countplot(a)
plt.xlabel('Reviews', color="red")
plt.ylabel('Count', color="red")
plt.xticks([0,1,2],['Negative','Neutral','Positive'])
plt.title('COUNT PLOT', color="r")
plt.show()
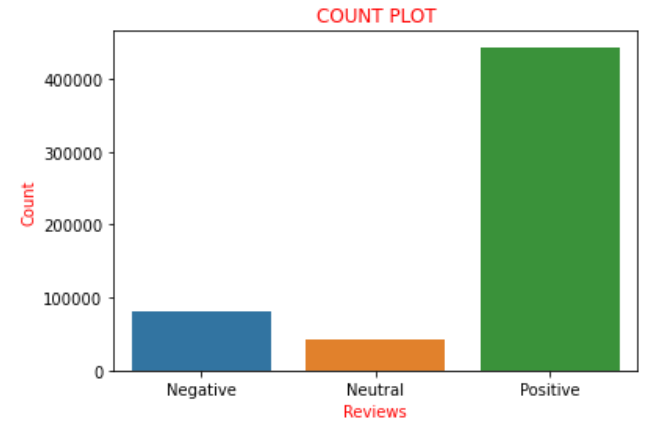
Por lo tanto, la trama anterior retrata claramente todas las oraciones descritas anteriormente pictóricamente. Ahora convierto la lista ‘a’ que habíamos codificado anteriormente en una nueva columna llamada ‘sentimiento’ al marco de datos, es decir, ‘datos’. Ahora viene un giro en el que creamos una nueva variable, digamos ‘final_dataset’ donde considero solo la columna ‘Sentimiento’ y ‘texto’ del marco de datos, que es el nuevo marco de datos en el que vamos a trabajar para la próxima parte. La razón detrás de esto es que todas las columnas restantes se consideran aquellas que no contribuyen al análisis de sentimiento, por lo tanto, sin descartarlas, consideramos que el marco de datos excluye esas columnas. Por lo tanto, esa es la razón para elegir solo las columnas ‘Texto’ y ‘Sentimiento’. Codificamos lo mismo que a continuación:
data['sentiment']=a final_dataset = data[['Text','sentiment']] final_dataset
Ahora, si imprimimos el ‘final_dataset’ y encontramos la forma, llegamos a saber que hay 568411 filas y solo 2 columnas. Desde el final_dataset, si descubrimos que el número de comentarios positivos es 443766 entradas y el número de comentarios negativos es 82007. Por lo tanto, hay una gran diferencia entre los comentarios positivos y negativos. Por lo tanto, hay más posibilidades de que los datos se ajusten demasiado si intentamos construir el modelo directamente. Por lo tanto, tenemos que elegir solo unas pocas entradas del final_datset para evitar el sobreajuste. Entonces, a partir de varios ensayos, he encontrado que el valor óptimo para el número de revisiones a considerar es 5000. Por lo tanto, creo dos nuevas variables ‘datap’ y ‘datan’ y almaceno aleatoriamente 5000 críticas positivas y negativas en las variables respectivamente. El código que implementa el mismo se encuentra a continuación:
datap = data_p.iloc[np.random.randint(1,443766,5000), :] datan = data_n.iloc[np.random.randint(1, 82007,5000), :] len(datan), len(datap)
Ahora creo una nueva variable llamada datos y concateno los valores en ‘datap’ y ‘datan’.
data = pd.concat([datap,datan]) len(data)
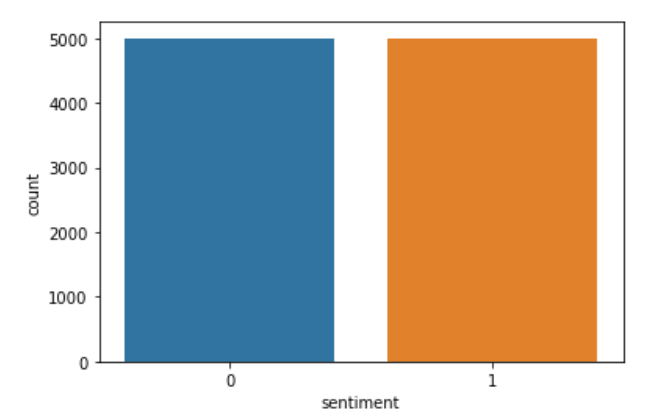
Ahora creo una nueva lista llamada ‘c’ y lo que hago es similar a la codificación pero explícitamente. Guardo las críticas negativas «0» como «0» y las críticas positivas «2» antes como «1» en «c». Luego, nuevamente reemplazo los valores del sentimiento almacenados en ‘c’ en los datos de la columna. Luego, para ver si el código se ha ejecutado correctamente, trazo la columna ‘sentimiento’. El código que implementa lo mismo es:
c=[]
for i in data['sentiment']:
if i==0:
c.append(0)
if i==2:
c.append(1)
data['sentiment']=c
sns.countplot(data['sentiment'])
plt.show()
Si vemos los datos, podemos encontrar que hay algunas etiquetas HTML, ya que los datos se obtuvieron originalmente de sitios de comercio electrónico reales. Por lo tanto, podemos encontrar que hay etiquetas presentes que deben eliminarse, ya que no son necesarias para el análisis de sentimientos. Por lo tanto, usamos la función BeautifulSoup que usa el ‘html.parser’ y podemos eliminar fácilmente las etiquetas no deseadas de las revisiones. Para realizar la tarea, creo una nueva columna llamada ‘revisión’ que almacena el texto analizado y dejo caer la columna llamada ‘sentimiento’ para evitar la redundancia. He realizado la tarea anterior usando una función llamada ‘strip_html’. El código para realizar lo mismo es el siguiente:
def strip_html(text):
soup = BeautifulSoup(text, "html.parser")
return soup.get_text()
data['review'] = data['Text'].apply(strip_html)
data=data.drop('Text',axis=1)
data.head()
Ahora hemos llegado al final de un tedioso proceso de preprocesamiento y visualización de datos. Por lo tanto, ahora podemos continuar con el siguiente paso, es decir, la construcción de modelos.
4. Modelo de construcción:
Antes directamente saltamos a construir el modelo que necesitamos, para hacer una pequeña tarea. Sabemos que para que los humanos clasifiquemos el sentimiento necesitamos artículos, determinantes, conjunciones, signos de puntuación, etc, ya que podemos entender claramente y luego clasificar la reseña. Pero este no es el caso de las máquinas, por lo que en realidad no las necesitan para clasificar el sentimiento, sino que se confunden literalmente si están presentes. Entonces, para realizar esta tarea como cualquier otro análisis de sentimientos, necesitamos usar la biblioteca ‘nltk’. NLTK son las siglas de ‘Natural Language Processing Toolkit’. Esta es una de las bibliotecas principales para realizar análisis de opinión o cualquier proyecto de aprendizaje automático basado en texto. Entonces, con la ayuda de esta biblioteca, primero eliminaré los signos de puntuación y luego eliminaré las palabras que no agregan un sentimiento al texto. Primero utilizo una función llamada ‘punc_clean’ que elimina los signos de puntuación de cada reseña. El código para implementar el mismo es el siguiente:
import nltk
def punc_clean(text):
import string as st
a=[w for w in text if w not in st.punctuation]
return ''.join(a)
data['review'] = data['review'].apply(punc_clean)
data.head(2)
Por lo tanto, el código anterior elimina los signos de puntuación. Ahora, a continuación, tenemos que eliminar las palabras que no agregan un sentimiento a la oración. Estas palabras se denominan «palabras vacías». Se pudo encontrar la lista de casi todas las palabras vacías aquí. A continuación, si revisamos la lista de palabras vacías, podemos encontrar que también contiene la palabra «no». Por lo tanto, es necesario que no eliminemos el «no» de la «revisión», ya que agrega algo de valor al sentimiento porque contribuye al sentimiento negativo. Por lo tanto, tenemos que escribir el código de tal manera que eliminemos otras palabras excepto el «no». El código para implementar el mismo es:
def remove_stopword(text):
stopword=nltk.corpus.stopwords.words('english')
stopword.remove('not')
a=[w for w in nltk.word_tokenize(text) if w not in stopword]
return ' '.join(a)
data['review'] = data['review'].apply(remove_stopword)
Por lo tanto, ahora solo tenemos un paso detrás de la construcción de modelos. El siguiente motivo es asignar cada palabra en cada reseña con una puntuación de sentimiento. Entonces, para implementarlo, necesitamos usar otra biblioteca del módulo ‘sklearn’ que es el ‘TfidVectorizer’ que está presente dentro de ‘feature_extraction.text’. Se recomienda encarecidamente pasar por el ‘TfidVectorizer’ docs para obtener una comprensión clara de la biblioteca. Tiene muchos parámetrosLos "parámetros" son variables o criterios que se utilizan para definir, medir o evaluar un fenómeno o sistema. En diversos campos como la estadística, la informática y la investigación científica, los parámetros son fundamentales para establecer normas y estándares que guían el análisis y la interpretación de datos. Su adecuada selección y manejo son cruciales para obtener resultados precisos y relevantes en cualquier estudio o proyecto.... como entrada, codificación, min_df, max_df, ngram_range, binary, dtype, use_idf y muchos más parámetros, cada uno con su propio caso de uso. Por lo tanto, se recomienda pasar por este Blog para obtener una comprensión clara del funcionamiento de ‘TfidVectorizer’. El código que implementa el mismo es:
from sklearn.feature_extraction.text import TfidfVectorizer vectr = TfidfVectorizer(ngram_range=(1,2),min_df=1) vectr.fit(data['review']) vect_X = vectr.transform(data['review'])
Ahora es el momento de construir el modelo. Dado que es un análisis de sentimiento de clasificación de clase binaria, es decir, ‘1’ se refiere a una revisión positiva y ‘0’ se refiere a una revisión negativa. Entonces, está claro que necesitamos usar cualquiera de los algoritmos de clasificación. El que se utiliza aquí es la regresión logística. Por lo tanto, necesitamos importar ‘LogisticRegression’ para usarlo como nuestro modelo. Luego, debemos ajustar todos los datos como tales porque sentí que es bueno probar los datos a partir de datos completamente nuevos en lugar del conjunto de datos disponible. Así que he ajustado todo el conjunto de datos. Luego uso la función ‘.score ()’ para predecir la puntuación del modelo. El código que implementa las tareas mencionadas anteriormente es el siguiente:
from sklearn.linear_model import LogisticRegression model = LogisticRegression() clf=model.fit(vect_X,data['sentiment']) clf.score(vect_X,data['sentiment'])*100
Si ejecutamos el fragmento de código anterior y verificamos la puntuación del modelo, obtenemos entre 96 y 97%, ya que el conjunto de datos cambia cada vez que ejecutamos el código, ya que consideramos los datos de forma aleatoria. Por lo tanto, hemos construido con éxito nuestro modelo que también con una buena puntuación. Entonces, ¿por qué esperar para probar cómo funciona nuestro modelo en el escenario del mundo real? Así que ahora pasamos al último y último paso de la ‘Predicción’ para probar el rendimiento de nuestro modelo.
5. Predicción:
Entonces, para aclarar el desempeño del modelo, he usado dos oraciones simples “Me encanta el helado” y “Odio el helado” que claramente se refieren a sentimientos positivos y negativos. El resultado es el siguiente:

Aquí el ‘1’ y el ‘0’ se refieren al sentimiento positivo y negativo respectivamente. ¿Por qué no se prueban algunas reseñas del mundo real? Les pido como lectores que verifiquen y prueben lo mismo. La mayoría de las veces obtendría la salida deseada, pero si eso no funciona, le solicito que intente cambiar los parámetros del ‘TfidVectorizer’ y ajuste el modelo a ‘LogisticRegression’ para obtener la salida requerida. Entonces, para lo cual he adjuntado el enlace al código y al conjunto de datos aquí.
Te conectas conmigo a través de linkedin. Espero que este blog sea útil para comprender cómo se realiza un análisis de sentimiento prácticamente con la ayuda de los códigos de Python. Gracias por ver el blog.
Los medios que se muestran en este artículo no son propiedad de DataPeaker y se utilizan a discreción del autor.





